〇、让我们准备一些训练数据
| id | x0 | x1 | x2 | x3 | x4 | y |
| 0 | 4.3 | 4.9 | 4.1 | 4.7 | 5.5 | 0 |
| 1 | 3.9 | 6.1 | 5.9 | 5.5 | 5.9 | 0 |
| 2 | 2.7 | 4.8 | 4.1 | 5.0 | 5.6 | 0 |
| 3 | 6.6 | 4.4 | 4.5 | 3.9 | 5.9 | 1 |
| 4 | 6.5 | 2.9 | 4.7 | 4.6 | 6.1 | 1 |
| 5 | 2.7 | 6.7 | 4.2 | 5.3 | 4.8 | 1 |
表格中的x0到x4一共有5个特征,y是目标值只有0,1两个值说明是一个二分类问题。
关于决策树相关的前置知识,我这里还写了几篇文章,大家可以配合本文一起读读哦!
【机器学习300问】28、什么是决策树?![]() http://t.csdnimg.cn/COF05【机器学习300问】33、决策树是如何进行特征选择的?
http://t.csdnimg.cn/COF05【机器学习300问】33、决策树是如何进行特征选择的?![]() http://t.csdnimg.cn/iPcwT【机器学习300问】34、决策树对于数值型特征如果确定阈值?
http://t.csdnimg.cn/iPcwT【机器学习300问】34、决策树对于数值型特征如果确定阈值?![]() http://t.csdnimg.cn/AvJZl
http://t.csdnimg.cn/AvJZl
一、决策树的局限性
决策树算法是一种直观且易于理解的机器学习算法,通过一系列的特征测试将数据划分到不同的类别或预测结果中去,尽管他在解释性上具有优势,但存在一些的局限性。
(1)容易过拟合且不稳定
决策树容易产生复杂的模型结构,尤其是在没有剪枝或者设置最大深度的时候,很容易导致过拟合现象,无法在新数据上得到泛化能力。
决策树的构建过程对输入数据的微小变化非常敏感,可能会导致生成完全不同的决策边界,这意味着模型可能不稳定,无法很好的处理噪声。
(2)决策路径单一且容易忽略冗余特征
单一决策树依赖于构建过程中选择的特征顺序和分割阈值,这会忽视其他重要的特征无法充分利用所有信息。
当多个特征高度相关的时候,决策树可能无法有效平衡这些冗余特征的重要性,从而导致过分依赖某个特征,忽视其他同样重要的特征。
二、什么是随机森林?
随机森林是一种集成学习方法,他就像是一个由多个决策树组成的森林,每个决策树都是一个独立的分类(或者回归)模型。让我们用一个校园活动的比喻来解释它:
假设有个才艺比赛,评委要决定哪个班级的表演最出色。每个评审只能观看少数几个班级的表演,并且每个评审只专注于表演中的特定方面(例如舞蹈技巧、原创性或服装)。最终,所有评审齐聚一堂,通过投票来决定哪个班级的整体表现最优秀。
在这个任务中每个评审代表一个决策树,他们的部分观察(基于随机子集的数据和特征)就像单棵决策树的预测,而评审们的投票过程则类似于森林中所有树的预测结果的集成。通过这种方式,随机森林利用整体的智慧和多样性来提升预测的准确性,并且通常比单个决策树更加稳健。
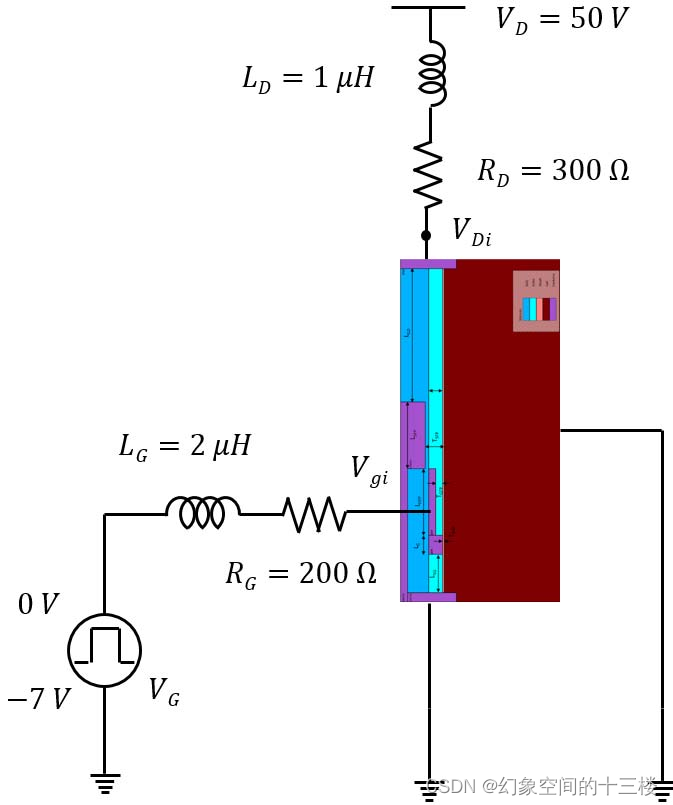
(1)随机森林长什么样子?
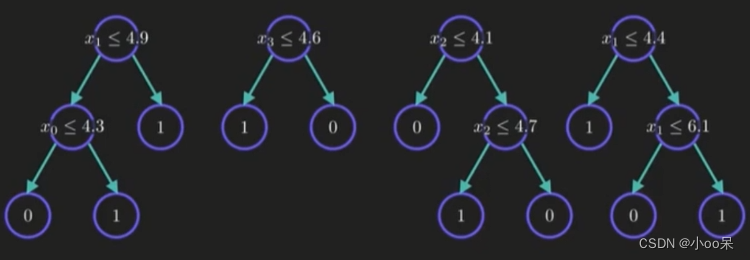
这就是一个随机森林的长相,可以清楚的看到它是由多个(这里是4个)决策树构成的。
(2)随机森林的工作原理
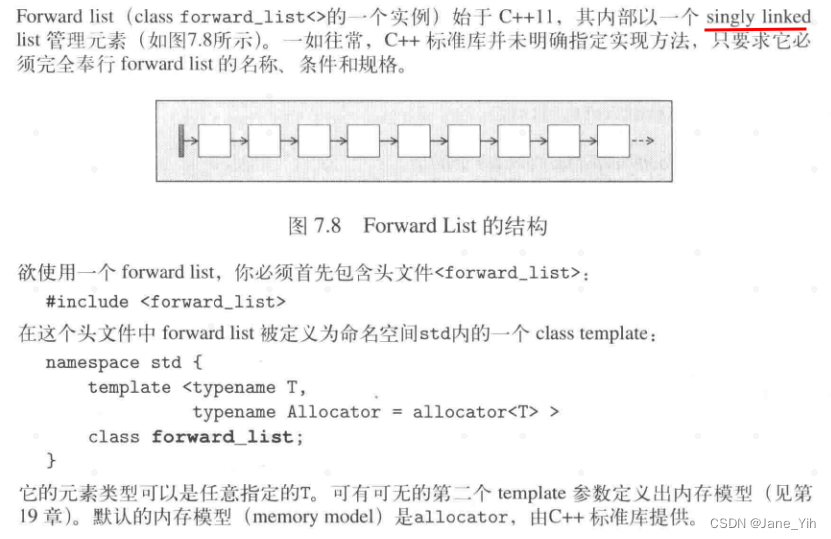
① 每个树的训练样本随机【随机样本抽取】
在构建每棵决策树时,不是使用全部的训练数据集,而是通过自助采样(bootstrap sampling)创建多个不同的训练数据子集。这样每棵树都是基于不同的训练子集来训练的。
这样做的好处是:通过随机抽样得到的样本能够较好地代表整个总体。随机抽样允许量化抽样误差,提高估计的精确度和预测的准确性。还能降低统计样本的难度,节省资源。
上图中我们就随机抽取了四个样本来构建4个不同的决策树:

② 每个树的特征选择随机【随机特征选择】
在决策树的每次分裂时,不是从所有的特征中选择最佳分裂特征,而是从一个随机选择的特征子集中选择。然后在该子集中找到最优的特征来进行划分。
这样做的好处是:降低了单个特征对决策树生成的影响,使得模型更加鲁棒,并且能够有效利用大量冗余或相关特征带来的信息。
上图中我们就随机抽取了不同的特征形成特征子集来构建决策树:

③ 选择合适的方式集成并获得最终结果
- 分类问题:在预测新样本类别时,每棵决策树都会给出一个预测结果。随机森林采用投票机制来确定最终类别,即多数表决原则——得票最多的类别作为最终预测结果。
- 回归问题:每棵树输出一个数值预测,最后取这些预测值的平均值作为最终回归预测结果。
三、特征子集的大小怎么选择?
在随机森林算法中,特征子集的大小,也就是在每次分裂节点时考虑的特征数量,会对模型的性能产生显著影响。选择这个参数的常见方法有两种:
(1)经验法
很多随机森林实现(例如scikit-learn库)有默认的启发式规则。这些默认设置通常还不错。
- 对于分类任务,默认设置是总特征数的平方根
- 对于回归任务,默认设置是总特征数的三分之一
(2)交叉验证法
利用交叉验证来寻找最佳的特征子集,你可以在一系列值中测试算法性能,选择出最优化模型准确性的特征数量。
更多集成学习的知识,我还写了另一篇文章,希望你能喜欢~