【八股】2024春招八股复习笔记1(搜索推荐、AIGC)
文章目录
JD描述
校招:
蚂蚁集团-支付宝事业群-支付宝技术部-用户技术部-算法工程师-搜索推荐
职位描述
你是搜索推荐领域的专家,用搜索推荐算法给用户提供贴心的内容推荐, 在这里,你可以:
参与并负责支付宝核心内容场景的各类算法,包括个性化推荐系统、内容生态构建、内容理解等核心算法能力;
深度参与内容分发算法设计,提升流量匹配的效率和用户粘性;
建设包括召回、粗排、精排、重排、混排等推荐算法,打造业界一流的内容算法;
参与设计多模态内容理解和推荐分发系统,推动解决内容的一致性和标准化问题。 一段全新、有趣的旅程正待开启。
必须具备的:
计算机、统计等相关专业本科及以上学历;
熟练掌握Java/C++/Python中至少一门语言,熟悉tensorflow或者pytorch至少一种机器学习常用框架;
有相关推荐系统、机器学习、计算机视觉、数据挖掘等相关领域研究及实践经验。
可以加分的:
有顶级会议论文发表(发布顶刊顶会至少一篇,担当一作/并列/二作);
作为重要角色参与领域内有含金量的比赛并取得成绩(比如ACM)。
社招(同岗位):
1、参与和负责蚂蚁财富核心场景推荐算法,通过深度个性化召回排序算法、机制与策略、结合金融业务特性,提升流量效率;
2、参与财经内容信息流feed与理财社区个性化推荐,并建设内容创作者生态,提升平台用户体验和时长;
3、持续关注搜推广技术前沿进展和业界先进应用,不断探索创新,为亿万理财用户创造更多价值。
职位描述
1. 两年以上机器学习应用经验,有搜索、推荐、广告等领域丰富的实战经验,在召回排序模型、机制设计等一个或多个领域有深入实践;
2、熟练掌握机器学习算法原理,能熟练运用深度学习、运筹优化、强化学习、等技术解决有挑战性的问题;
3、正能量、乐观、自驱,善于沟通、合作、推动算法在业务中的落地,有金融知识优先。
其他:
岗位职责
【岗位信息有延迟,具体情况,以官网为准。】你是搜索推荐领域的专家,
用搜索推荐算法给用户提供贴心的内容推荐,
在这里,你可以:
参与并负责支付宝核心内容场景的各类算法,包括个性化推荐系统、内容生态构建、内容理解等核心算法能力;
深度参与内容分发算法设计,提升流量匹配的效率和用户粘性;
建设包括召回、粗排、精排、重排、混排等推荐算法,打造业界一流的内容算法;
参与设计多模态内容理解和推荐分发系统,推动解决内容的一致性和标准化问题。
一段全新、有趣的旅程正待开启。
岗位要求
【岗位信息有延迟,具体情况,以官网为准。】必须具备的:
计算机、统计等相关专业本科及以上学历;
熟练掌握Java/C++/Python中至少一门语言,熟悉tensorflow或者pytorch至少一种机器学习常用框架;
有相关推荐系统、机器学习、计算机视觉、数据挖掘等相关领域研究及实践经验。
可以加分的:
有顶级会议论文发表(发布顶刊顶会至少一篇,担当一作/并列/二作);
作为重要角色参与领域内有含金量的比赛并取得成绩(比如ACM)。
准备方向:
1、基础算法(ACM)+应用算法(传统深度学习,机器学习)
2、算法机器学习相关的,ai热点
3、方向:用户算法
4、常用框架:tansformer tenserflow 用法和原理
5、搜索推荐相关的
1、推荐系统
1.1 推荐系统流程
介绍下推荐系统的流程?面经1
推荐系统的流程主要包含一下几个阶段。
召回 -> 精排 -> 多目标混排
索引&特征: 会根据内容特性提前建立若干种类型的索引。
召回阶段: 用户请求时会从各种索引种取出千/万 条item。
粗排阶段: 针对这上千/万条item,进行第一遍打分,再筛选出几百条或者千条。这个阶段的排序模型一般都比较简单,能够过滤掉一些与用户兴趣明显不相关的。
精排阶段: 得到几百条item后,精排阶段会建立相对精细的模型,根据用户的画像,偏好,上下文,结
合业务目标进行排序。一般精排后返回50-100条给到engine侧。
重排阶段: engine 侧拿到精排的50条item。还会做很多的人工干预和产品逻辑,比如item之间的多样性,产品策略逻辑,比如热门,置顶,多种内容之间的位置混合等等。最终会返回5-10条左右的item,曝光给客户端。根据业务特性,在线流程还有许多比较细的模块,比如去重服务,避免给用户推荐重复的内容。特征预处理,特征抽取等模块。
召回和排序的差异?
- **召回比较简单,要快。精排需要精确排序。**面试官说有的召回策略也比较复杂,比如双塔模型,有了解吗?
- 有了解,分为用户塔和物品塔。这块我了解到**用户塔和物品塔,**可以做到根据用户的行为进行实时更新。
- 查询塔负责处理查询**(用户输入的信息**),将其转化为查询向量表示。通常,查询塔会使用一些自然语言处理技术,如词嵌入、循环神经网络(RNN)或卷积神经网络(CNN),将查询转化为固定维度的向量表示。
- 候选塔负责处理候选项(例如文档、商品或用户),将其转化为候选向量表示。候选塔通常使用类似的技术,将候选项转化为向量表示。
- 一旦查询和候选项都被转化为向量表示,双塔模型会计算它们之间的相似度得分。这可以通过计算查询向量和候选向量之间的余弦相似度或其他相似度度量来实现。
- 最后,根据相似度得分,可以选择排名前几个最相关的候选项作为召回结果,以供后续的排序或推荐处理。
- 召回的目的在于减少候选的数量(尽量控制在1000以内),方便后续排序环节使用复杂模型精准排序
- 因为在短时间内评估海量候选,所以召回的关键点是个快字,受限与此与排序相比,召回的算法模型相对简单,使用的特征比较少。
- 而排序模型相对更加复杂,更追求准确性,使用的特征也会较多。
- 像是滤网,一层一层往下率,越到后面就越少。 开始的时候数据量会相差很多很多。
- **召回比较简单,要快。精排需要精确排序。**面试官说有的召回策略也比较复杂,比如双塔模型,有了解吗?
结果 f1 提升的 1% 怎么保证有效性,如何保证置信呢?
- 实验过程中固定随机种子、多次实验取平均
固定随机种子后,多次实验结果相同吗?
- 还是会有细微差别,因为在梯度传播过程,梯度(浮点数)精度有差异,随着神经网络层数的增加,梯度差异会从小数后面的位置往前跑。只能设置浮点数精度增加来缓解这个问题。
召回主流的做法?
主流的召回做法包括:规则召回,协同召回,基于内容语义的 I2I 召回,向量召回(基于embedding),树召回和图召回。
召回主流的做法
- embedding 召回, 局部敏感哈希
介绍下 embedding 召回?
主要分为两类,分别是是否考虑文本上下文,比如bert,GPT会考虑,传统word2vector不考虑。
- TF-IDF不考虑上下文,甚至不考虑词序
举一个文本类embedding的例子。
文本类的Embedding可以分为两种,一种是比较传统的word2vector、fasttext、glove这些算法的方案,叫做词向量固定表征类算法,这些算法主要是通过分析词的出现频率来进行Embedding生成,不考虑文本上下文。
而另一种文本Embedding方法,也是目前最流行的方案是动态词表征算法,比如Bert、ELMo、GPT,这类算法会考虑文本上下文。
推荐系统冷启动问题,怎么解决?
- 提供非个性化的推荐
- 最简单的例子就是热门排行榜,我们可以给用户推荐热门排行榜,然后等到用户数据收集到一定的时候,再切换为个性化推荐。
- 利用用户注册信息
- 用户注册时提供包括用户的年龄、性别、职业、民族、学历和居住地等数据,做粗粒度的个性化。有一些网站还会让用户用文字描述他们的兴趣。
- 利用社交网络信息
- 引导用户通过社交网络账号登录(需要用户授权),导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的物品。可以去买,就是很贵。
- 提供非个性化的推荐
为啥排序会比召回的结果要准呢??
- 排序的模型更复杂,用到的特征更多。我了解到的召回策略,协同过滤,关键词召回
召回的目的是什么,推荐系统一定需要召回吗?
- 优化工程耗时,候选池很大的时候,一定需要做召回,跟精排所用的算法无关。
- 推荐系统最大的工程耗时是在倒排索引环节
embedding是什么?
- 在自然语言处理(NLP)和机器学习中,嵌入(Embedding)是一种将离散的符号或对象(如单词、句子、图像等)映射到连续向量空间的技术。嵌入向量是一种表示,它将符号化的数据转化为实数向量,使得计算机可以更好地理解和处理这些数据。
- 嵌入的目标是将高维的离散数据转化为低维的连续向量表示,同时保留数据之间的语义和关系。通过嵌入,我们可以将符号化的数据转化为计算机可以处理的数值形式,从而进行各种机器学习和深度学习任务,如文本分类、情感分析、机器翻译等。
- 在NLP中,最常见的嵌入技术是词嵌入(Word Embedding),它将单词映射到连续的向量空间。词嵌入可以捕捉单词之间的语义和语法关系,使得计算机可以更好地理解和处理文本数据。
- 嵌入技术还可以应用于其他领域,如图像处理中的图像嵌入(Image Embedding),将图像映射到向量空间,以便进行图像检索、分类等任务。
- 总之,嵌入是一种将离散的符号或对象映射到连续向量空间的技术,它在NLP和机器学习中被广泛应用,使得计算机可以更好地理解和处理符号化的数据。
- 词嵌入
介绍下 embedding 召回
- 简单说下了 wode2vec, user 的 embedding 通过平均该 user 的浏览记录的 embedding 来获得。 user 的 embedding 有啥改进吗?用注意力机制来做
现在主要研究是 NLP 吗?未来是希望做 NLP 还是 做推荐,实验有做推荐的吗?NLP和推荐系统的区别?
- 虽然NLP和推荐系统是不同的领域,但它们可以在推荐系统中结合使用。
- 例如,在推荐系统中,可以使用NLP技术来处理和分析用户的文本反馈、评论或社交媒体数据,以更好地理解用户的偏好和意图,从而提供更准确的个性化推荐。
- NLP关注于处理和理解自然语言,而推荐系统关注于根据用户的兴趣和偏好提供个性化的推荐内容。它们在不同的应用场景中有着各自的重要性和应用价值。
怎么解决排序结果都是之前电影相似电影的结果
- 热门电影的排序结果不参与精排,直接随机插入到最终结果中
星球推荐系统2
推荐系统的作用?
- 用户角度:推荐系统解决在“信息过载”的情况下,用户如何高效获得感兴趣信息的问题。
- 公司角度:推荐系统解决产品能够最大限度地吸引用户、留存用户、增加用户黏性、提高用户转化率的问题,从而达到公司商业目标连续增长的目的。
- 用户体验的优化;满足公司的商业利益;
- 推荐系统要解决的“用户痛点”是用户如何在“信息过载”的情况下高效地获得感兴趣的信息。
推荐系统算法工程师日常解决问题?
- 数据和信息相关的问题:即“用户信息”“物品信息”“场景信息”分别是什么?如何存储、更新和处理?
- 推荐系统算法和模型相关的问题:推荐模型如何训练、如何预测、如何达成更好的推荐效果?
推荐系统算法工程师 处理的数据部分有哪些,最后得到什么数据?
- 数据入口:负责“用户”“物品”“场景”的信息收集与处理;
- 数据出口:
- 生成推荐模型所需的样本数据,用于算法模型的训练和评估;
- 生成推荐模型服务(model serving)所需的“特征”,用于推荐系统的线上推断;
- 生成系统监控、商业智能(Business Intelligence,BI)系统所需的统计型数据;
推荐系统算法工程师 处理的模型部分有哪些,最后得到什么数据?
- “召回层”:利用高效的召回规则、算法或简单的模型,快速从海量的候选集中召回用户可能感兴趣的物品。
- “排序层”:利用排序模型对初筛的候选集进行精排序。
- “补充策略与算法层”(再排序层):在将推荐列表返回用户之前,为兼顾结果的**“多样性”“流行度”“新鲜度”等指标**,结合一些补充的策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表
模型训练的方式?
- 离线训练:可以利用全量样本和特征,使模型逼近全局最优点;
- 在线更新:可以准实时地“消化”新的数据样本,更快地反映新的数据变化趋势,满足模型实时性的需求。
推荐系统 的 流程是什么?
- 本质:信息过滤系统;
- 流程:召回->排序->重排序
- 目标:每个环节逐层过滤,最终从海量的物料库中筛选出几十个用户可能感兴趣的物品推荐给用户
推荐系统 与 搜索、广告 的 异同?
- 搜索:有明确的搜索意图,搜索出来的结果和用户的搜索词相关;
- 推荐:不具有目的性,依赖用户的历史行为和画像数据进行个性化推荐;
- 广告:借助搜索和推荐技术实现广告的精准投放,可以将广告理解成搜索推荐的一种应用场景,技术方案更复杂,涉及到智能预算控制、广告竞价等;
1.2 协同过滤 、 矩阵分解
- 太理论了,暂时先不看
- 搜索、推荐、广告、用增等工业界实践文章收集
- 标签: 主要是改进推荐、搜索,冷启动、召回、CTR预估、粗排准确性,Query推荐、多场景排序,重排,CXR预估,因果推断、广告,工程、理解,等模型的各个环节
网上的付费面试题,没有更新完,我用GPT回答学习一下
什么是协同过滤?
- 协同过滤是一种推荐系统算法,用于预测用户可能喜欢的物品或内容。
- **它基于用户的历史行为和与其他用户的相似性来进行预测。**协同过滤算法主要有两种类型:基于用户的协同过滤和基于物品的协同过滤。
- 基于用户的协同过滤算法通过比较用户之间的行为模式和兴趣来进行预测。例如,如果用户A和用户B在过去都喜欢相似的物品,那么当用户A喜欢一个新物品时,系统可以推荐给用户B。
- 基于物品的协同过滤算法则通过比较物品之间的相似性来进行预测。例如,如果用户A喜欢物品X,而物品Y与X相似,那么系统可以推荐给用户A物品Y。
协同过滤的推荐流程是怎么样?
- 数据收集:首先,需要收集用户的历史行为数据,例如用户对物品的评分、购买记录、点击记录等。同时,还需要收集物品的属性信息,如电影的类型、商品的特征等。
- 相似度计算:接下来,需要计算用户之间或物品之间的相似度。对于基于用户的协同过滤,可以使用相似度度量方法(如余弦相似度)来计算用户之间的相似度。对于基于物品的协同过滤,可以计算物品之间的相似度。
- 预测生成:根据用户的历史行为和相似度计算结果,可以进行预测生成。对于基于用户的协同过滤,可以找到与目标用户相似的其他用户,并根据这些用户的行为来预测目标用户对未评价的物品的喜好程度。对于基于物品的协同过滤,可以找到与目标物品相似的其他物品,并根据用户对这些相似物品的评价来预测目标用户对目标物品的喜好程度。
- 推荐结果生成:根据预测生成的结果,可以生成推荐列表。可以根据预测的评分或喜好程度对物品进行排序,然后将排名靠前的物品推荐给用户。
- 评估和优化:最后,需要对推荐结果进行评估和优化。可以使用一些评估指标(如准确率、召回率、覆盖率等)来评估推荐系统的性能,并根据评估结果进行算法的优化和改进。
基于用户的协同过滤是什么?(先 “找到相似用户”,再“找到他们喜欢的物品”。 注重 大众化)
基于用户的协同过滤是一种推荐系统算法,它通过比较用户之间的行为模式和兴趣来进行预测和推荐。该算法的核心思想是找到与目标用户兴趣相似的其他用户,并根据这些用户的行为来预测目标用户对未评价的物品的喜好程度。
基于用户的协同过滤算法的推荐流程如下:
- 相似度计算:首先,需要计算用户之间的相似度。常用的相似度度量方法包括余弦相似度、皮尔逊相关系数等。相似度计算可以基于用户的历史行为数据,比如用户对物品的评分、购买记录、点击记录等。
- 相似用户选择:根据计算得到的相似度,选择与目标用户最相似的一些用户作为邻居用户。可以设定一个阈值,只选择相似度高于该阈值的用户。
- 预测生成:根据邻居用户的行为,预测目标用户对未评价的物品的喜好程度。常用的预测方法包括加权平均、加权求和等。可以根据邻居用户对物品的评分或行为来进行加权计算,得到目标用户对未评价物品的预测评分。
- 推荐结果生成:根据预测生成的评分,对未评价的物品进行排序,将评分高的物品推荐给目标用户。
基于用户的协同过滤算法的优点是简单且易于理解,它利用用户之间的相似性来进行推荐,不需要事先了解物品的详细信息。然而,该算法也存在一些挑战,如数据稀疏性、冷启动问题和推荐偏好的漂移等。
具备更强的社交特性:用户能够快速得知与自己兴趣相似的人最近喜欢的是什么
- 适用于:物品》用户的场景 (新闻推荐场景)
- 因为新闻本身的兴趣点往往是分散的,相比用户对不同新闻的兴趣偏好,新闻的及时性、热点性往往是其更重要的属性,而UserCF正适用于发现热点,以及跟踪热点的趋势
缺点:
- 在互联网应用的场景下,用户数往往远大于物品数,而 UserCF 需要维护用户相似度矩阵以便快速找出 TopN 相似用户。
- 用户的历史数据向量往往非常稀疏,对于只有几次购买或者点击行为的用户来说,找到相似用户的准确度是非常低的,这导致 UserCF 不适用于那些正反馈获取较困难的应用场景(如酒店预定、大件商品购买等低频应用)。
基于物品的协同过滤? (先 “找到用户喜欢的物品”,再“找到喜欢的物品的相似物品”。 注重 个性化)
- 适用于:用户》物品 的场景 适用于兴趣变化较为稳定的应用
- 基于物品的协同过滤是一种推荐系统算法,**它通过比较物品之间的相似性来进行预测和推荐。**该算法的核心思想是找到与目标物品相似的其他物品,并根据用户对这些相似物品的评价来预测目标用户对目标物品的喜好程度。
基于用户的协同过滤,与基于物品的协同过滤对比?
- 焦点不同: 相似度计算对象不同: 一个是找用户,一个是找物品。
- 邻居选择不同:基于用户的协同过滤算法选择与目标用户相似的其他用户作为邻居用户,而基于物品的协同过滤算法选择与目标物品相似的其他物品作为邻居物品。
- 预测生成方法不同:基于用户的协同过滤算法根据邻居用户的行为来预测目标用户对未评价的物品的喜好程度,而基于物品的协同过滤算法根据用户对邻居物品的评价来预测目标用户对目标物品的喜好程度。
- 推荐结果生成不同:基于用户的协同过滤算法根据预测生成的评分对未评价的物品进行排序,将评分高的物品推荐给目标用户。而基于物品的协同过滤算法根据预测生成的评分对目标用户未评价的物品进行排序,将评分高的物品推荐给目标用户。
什么是 隐语义模型?
隐语义模型(Latent Semantic Model)是一种用于处理文本数据的统计模型。它基于假设,即文本中的语义信息可以通过潜在的隐含变量来表示。这些隐含变量可以捕捉到文本中的主题、语义关系和语义相似性等信息。
隐语义模型通常用于文本挖掘、信息检索和推荐系统等任务。它的基本思想是将文本表示为一个高维的向量空间,其中每个维度对应一个隐含变量。通过对大量文本数据进行训练,模型可以学习到这些隐含变量的分布和关系,从而能够对新的文本进行语义分析和推断。
隐语义模型的一个常见应用是主题模型,如潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)。LDA可以**将文本表示为多个主题的混合,**每个主题由一组相关的词语表示。这种模型可以帮助我们理解文本中的主题结构,从而进行文本分类、主题推断和信息检索等任务。
矩阵分解与隐语义模型的关系?
- 矩阵分解是一种常用的数学方法,用于将一个矩阵分解为多个较低维度的矩阵的乘积。在隐语义模型中,矩阵分解被广泛应用来捕捉文本数据中的隐含语义信息。
- 具体来说,矩阵分解在隐语义模型中通常用于处理文本-词语矩阵或文本-文本矩阵。这些矩阵的行表示文本,列表示词语或文本之间的关系。通过将这些矩阵分解为两个或多个较低维度的矩阵,我们可以得到文本和词语之间的隐含关系。
- 例如,在基于矩阵分解的协同过滤推荐系统中,用户-物品评分矩阵可以被分解为用户矩阵和物品矩阵的乘积。这样的分解可以帮助我们发现用户和物品之间的隐含关系,从而进行个性化的推荐。
- 在隐语义模型中,矩阵分解可以帮助我们降低数据的维度,并捕捉到数据中的潜在语义信息。这些潜在语义信息可以用于文本分类、主题建模、推荐系统等任务,从而提高模型的性能和效果。
User-CF-Based 与 Item-CF-Based 问题篇
- 数据稀疏性。**尾部的物品由于特征向量稀疏,很少与其他物品产生相似性,**导致很少被推荐。
- 缺乏泛化性。
- 算法扩展性。基于用户的协同过滤需要维护用户相似度矩阵以便快速的找出Topn相似用户, 该矩阵的存储开销非常大,存储空间随着用户数量的增加而增加,不适合用户数据量大的情况使用;
- 没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,比较简单高效, 但这也是它的一个短板所在, 由于无法有效的引入用户年龄, 性别,商品描述,商品分类,当前时间,地点等一系列用户特征、物品特征和上下文特征, 这就造成了有效信息的遗漏,不能充分利用其它特征数据。
- 马太效应。热门的物品具有很强的头部效应,容易跟大量物品产生相似性
矩阵分解 存在什么问题?
- 优点:
- 泛化能力强: 一定程度上解决了稀疏问题
- 空间复杂度低: 由于用户和物品都用隐向量的形式存放, 少了用户和物品相似度矩阵, 空间复杂度由n2降到了(n+m)∗f
- 更好的扩展性和灵活性:矩阵分解的最终产物是用户和物品隐向量, 这个深度学习的embedding思想不谋而合, 因此矩阵分解的结果非常便于与其他特征进行组合和拼接, 并可以与深度学习无缝结合。
- 缺点:
- 矩阵分解算法依然是只用到了评分矩阵, 没有考虑到用户特征, 物品特征和上下文特征, 这使得矩阵分解丧失了利用很多有效信息的机会;
- 在缺乏用户历史行为的时候, 无法进行有效的推荐。 所以为了解决这个问题, 逻辑回归模型及后续的因子分解机模型, 凭借其天然的融合不同特征的能力, 逐渐在推荐系统领域得到了更广泛的应用。
如何 利用 矩阵分解 计算 用户 u 对 物品 v 的 评分?
- 基于用户矩阵 U和物品矩阵 V,用户 u对物品 i的预估评分
1.3 逻辑回归
1.1 为什么 需要 逻辑回归?
- 协同过滤:仅利用用户与商品的相互行为信息进行推荐
- 协同过滤 和 矩阵分解:利用 用户与商品的“相似度”进行推荐
逻辑回归 如何解决 上述问题?
- 协同过滤:仅利用用户与商品的相互行为信息进行推荐
- 解决方法:逻辑回归:能够综合利用用户、物品、上下文等多种不同的特征,生成较为“全面”的推荐结果。
- 协同过滤 和 矩阵分解:利用 用户与商品的“相似度”进行推荐
- 逻辑回归:将推荐问题看成一个分类问题,通过预测正样本的概率对物品进行排序。
什么是逻辑回归?
- 本质上是线性回归,特殊之处在于特征到结果的映射中加入了一层逻辑函数g(z),即先把特征线性求和,然后使用函数g(z)作为假设函数来预测。g(z)可以将连续值映射到0 和1。逻辑回归使用的g(z)函数是sigmoid函数。因此逻辑回归=线性回归 + sigmoid。
逻辑回归 推荐流程?
- 数值型特征向量:将用户年龄、性别、物品属性、物品描述、当前时间、当前地点等特征转换成数值型特征向量。
- 确定逻辑回归模型的优化目标:(以优化“点击率”为例),利用已有样本数据对逻辑回归模型进行训练,确定逻辑回归模型的内部参数。
- 点击概率预测:在模型服务阶段,将特征向量输入逻辑回归模型,经过逻辑回归模型的推断,得到用户“点击”(这里用点击作为推荐系统正反馈行为的例子)物品的概率。
- 排序:利用“点击”概率对所有候选物品进行排序,得到推荐列表。
逻辑回归 有哪些优点?
- 数字含义上的支撑
- 可解释性强
- 工程化的需要 : 其易于并行化、模型简单、训练开销小等特点
逻辑回归 缺点:
- 表达能力不强, 无法进行特征交叉, 特征筛选等一系列“高级“操作(这些工作都得人工来干, 这样就需要一定的经验, 否则会走一些弯路), 因此可能造成信息的损失
- 准确率并不是很高。因为这毕竟是一个线性模型加了个sigmoid, 形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布
2、算法常识(应用算法)
2.1 重点复习 xgboost
transformer原理?
- 基于自注意力机制(self-attention mechanism)和多层前馈神经网络。
- 通过自注意力机制来捕捉输入序列中不同位置之间的依赖关系。自注意力机制允许模型在处理每个位置时,根据其他位置的信息来加权组合输入序列的不同部分。这种机制使得模型能够同时**考虑到全局和局部的上下文信息,**从而更好地理解序列中的语义和结构。
- Transformer模型由编码器(encoder)和解码器(decoder)组成。编码器负责将输入序列转换为一系列高维表示,而解码器则根据编码器的输出和之前的预测来生成输出序列。
- 自注意力机制通过计算每个位置与其他位置之间的相关性得到一个权重向量,然后将输入序列与该权重向量进行加权求和,得到每个位置的表示。前馈神经网络则对每个位置的表示进行非线性变换。
- 在解码器中,除了自注意力机制和前馈神经网络,还引入了另一种注意力机制,称为“编码-解码注意力”。该注意力机制允许解码器在生成每个位置的输出时,根据编码器的输出来关注输入序列的不同部分。
- 通过多层的编码器和解码器,Transformer模型能够学习输入序列和输出序列之间的映射关系,从而实现序列到序列的任务,如机器翻译、文本摘要等。由于Transformer模型能够并行计算,它在处理长序列和大规模数据时具有较高的效率和性能。
encoder decoder attention机制?
- 编码器-解码器注意力机制是Transformer模型中的一种关键机制,用于在解码器生成输出时,将编码器的输出与当前位置的输入进行关联。
- 在编码器-解码器注意力机制中,解码器的每个位置都会计算一个注意力权重向量,该向量表示该位置应该关注编码器的哪些部分。这个注意力权重向量是通过计算解码器当前位置的表示与编码器所有位置的表示之间的相关性得到的。
- 这种注意力机制的好处是,解码器可以根据编码器的输出来关注输入序列的不同部分,从而更好地理解输入序列的语义和结构。这对于序列到序列的任务非常重要,例如机器翻译,解码器需要根据输入句子的不同部分来生成正确的翻译结果。
- 还有自注意力机制(self-attention)用于编码器和解码器内部的位置之间的关联。自注意力机制允许模型在处理每个位置时,根据其他位置的信息来加权组合输入序列的不同部分,从而更好地捕捉序列中的依赖关系。编码器-解码器注意力机制则是在解码器中引入的一种额外的注意力机制,用于关联编码器和解码器的表示。
cnn & rnn的区别?
- CNN(卷积神经网络)和RNN(循环神经网络)是两种常见的神经网络架构,用于处理不同类型的数据。
- CNN主要用于处理具有空间结构的数据,例如图像。它通过卷积层和池化层来提取图像中的特征,并通过全连接层进行分类或回归。CNN的卷积操作可以有效地捕捉到图像中的局部模式和空间关系,使其在图像识别和计算机视觉任务中表现出色。
- RNN则主要用于处理序列数据,例如文本、语音或时间序列数据。RNN通过循环连接来处理序列中的每个元素,并在每个时间步骤中传递隐藏状态。这种循环结构使得RNN能够捕捉到序列中的上下文信息,对于处理具有时序关系的数据非常有效。RNN的变体,如LSTM(长短期记忆网络)和GRU(门控循环单元),还能够解决长期依赖问题,使其在自然语言处理和语音识别等任务中表现出色。
- 因此,CNN适用于处理空间结构数据,而RNN适用于处理序列数据。它们在网络结构和处理不同类型数据的方式上有所不同,因此在不同的应用场景中选择合适的网络架构非常重要。
xgboost是什么?
- 它是一种梯度提升树算法,用于解决分类和回归问题。XGBoost结合了梯度提升算法和决策树模型的优点,具有高效性和准确性。
- XGBoost通过迭代地训练多个决策树模型,并将它们组合成一个强大的集成模型。在每一轮迭代中,XGBoost根据之前模型的预测结果来调整样本的权重,使得下一轮模型能够更好地拟合残差。这种迭代的过程使得XGBoost能够逐步减小预测误差,提高模型的性能。
- XGBoost具有很多优点,包括高效性、可扩展性、准确性和灵活性。它在许多机器学习竞赛和实际应用中都取得了很好的效果,成为了一种流行的机器学习算法。
你用到Bert,你能不能介绍一下 BERT和GPT的训练方式(预训练任务训练细节)的区别?
elmo、GPT、bert三者之间有什么区别?
之前介绍词向量均是静态的词向量,无法解决一次多义等问题。
下面介绍三种elmo、GPT、bert词向量,它们都是基于语言模型的动态词向量。下面从几个方面对这三者进行对比:
(1)特征提取器:elmo采用LSTM进行提取,GPT和bert则采用Transformer进行提取。很多任务表明Transformer特征提取能力强于LSTM,elmo采用1层静态向量+2层LSTM,多层提取能力有限,而GPT和bert中的Transformer可采用多层,并行计算能力强。
(2)单/双向语言模型:
- GPT采用单向语言模型,elmo和bert采用双向语言模型。但是elmo实际上是两个单向语言模型(方向相反)的拼接,这种融合特征的能力比bert一体化融合特征方式弱。
- GPT和bert都采用Transformer,Transformer是encoder-decoder结构,GPT的单向语言模型采用decoder部分,decoder的部分见到的都是不完整的句子;bert的双向语言模型则采用encoder部分,采用了完整句子。
NLP 面无不过
四、NLP 学习算法 常见面试篇
4.1 信息抽取 常见面试篇
4.1.1 命名实体识别 常见面试篇
4.1.2 关系抽取 常见面试篇
4.1.3 事件抽取 常见面试篇
4.2 NLP 预训练算法 常见面试篇
4.3 Bert 常见面试篇
4.3.1 Bert 模型压缩 常见面试篇
4.3.2 Bert 模型系列 常见面试篇
4.4 文本分类 常见面试篇
4.5 文本匹配 常见面试篇
4.6 问答系统 常见面试篇
4.6.1 FAQ 检索式问答系统 常见面试篇
4.6.2 问答系统工具篇 常见面试篇
4.7 对话系统 常见面试篇
4.8 知识图谱 常见面试篇
4.8.1 知识图谱 常见面试篇
4.8.2 KBQA 常见面试篇
4.8.3 Neo4j 常见面试篇
4.9 文本摘要 常见面试篇
4.10 文本纠错篇 常见面试篇
4.11 文本摘要 常见面试篇
4.12 文本生成 常见面试篇
三、深度学习算法篇 常见面试篇
3.1 Transformer 常见面试篇
五、NLP 技巧面
5.1 少样本问题面
5.1.1 数据增强(EDA) 面试篇
5.1.2 主动学习 面试篇
5.1.3 数据增强 之 对抗训练 面试篇
5.2 “脏数据”处理 面试篇
5.3 batch_size设置 面试篇
5.4 早停法 EarlyStopping 面试篇
5.5 标签平滑法 LabelSmoothing 面试篇
5.6 Bert Trick 面试篇
5.6.1 Bert 未登录词处理 面试篇
5.6.2 BERT在输入层引入额外特征 面试篇
5.6.3 关于BERT 继续预训练 面试篇
5.6.4 BERT如何处理篇章级长文本 面试篇
六、 Prompt Tuning 面试篇
6.1 Prompt 面试篇
6.2 Prompt 文本生成 面试篇
6.3 LoRA 面试篇
6.4 PEFT(State-of-the-art Parameter-Efficient Fine-Tuning)面试篇
七、LLMs 面试篇
7.1 【现在达模型LLM,微调方式有哪些?各有什么优缺点?
7.2 GLM:ChatGLM的基座模型 常见面试题
一、基础算法 常见面试篇
二、机器学习算法篇 常见面试篇
九、【关于 Python 】那些你不知道的事
十、【关于 Tensorflow 】那些你不知道的事
2.2 大模型 transform
几种主流大模型的 loss 了解过吗? 有哪些异同?
- 交叉熵损失(Cross-Entropy Loss):交叉熵损失是一种常用于分类任务的损失函数。它通过计算模型输出的概率分布与真实标签的概率分布之间的交叉熵来衡量模型的性能。交叉熵损失在训练过程中可以帮助模型更好地拟合数据。
- 均方误差损失(Mean Squared Error Loss):**均方误差损失是一种常用于回归任务的损失函数。**它通过计算模型输出与真实标签之间的差的平方来衡量模型的性能。均方误差损失在训练过程中可以帮助模型更好地拟合数据。
- 对比损失(Contrastive Loss):对比损失通常用于学习具有相似性度量的嵌入空间。它通过最小化同类样本之间的距离,同时最大化不同类样本之间的距离来训练模型。对比损失在训练过程中可以帮助模型学习到更好的特征表示。
对位置编码熟悉吗?讲讲几种位置编码的异同
- 是的,我对位置编码比较熟悉。位置编码是一种用于在自然语言处理和计算机视觉任务中为序列数据引入位置信息的技术。以下是几种常见的位置编码方法及其异同点:
- 绝对位置编码(Absolute Positional Encoding):绝对位置编码是一种基于固定位置信息的编码方法。它通过为序列中的每个位置分配一个唯一的编码向量来表示位置信息。常见的绝对位置编码方法包括正弦编码和余弦编码,它们根据位置的奇偶性来生成不同的编码向量。
- 相对位置编码(Relative Positional Encoding):相对位置编码是一种**基于相对位置关系的编码方法。**它通过计算序列中每个位置与其他位置之间的相对距离来表示位置信息。相对位置编码可以捕捉到序列中不同位置之间的相对顺序和距离关系。
- 自注意力机制(Self-Attention):自注意力机制是一种无需显式位置编码的方法。它通过在注意力机制中引入位置信息来捕捉序列中不同位置之间的关系。自注意力机制可以根据输入序列的内容自动学习到位置信息的表示。
- 是的,我对位置编码比较熟悉。位置编码是一种用于在自然语言处理和计算机视觉任务中为序列数据引入位置信息的技术。以下是几种常见的位置编码方法及其异同点:
介绍一下 记忆(Memory)?
- 短期记忆:上下文学习即是利用模型的短期记忆学习
- 长期记忆:为agent提供保留和召回长期信息的能力,通常利用外部向量存储和检索实现
大模型:一般指1亿以上参数的模型,但是这个标准一直在升级,目前万亿参数以上的模型也有了。大语言模型(Large Language Model,LLM)是针对语言的大模型。
大模型【LLMs】后面跟的 175B、60B、540B等 指什么?
- 175B、60B、540B等:这些一般指参数的个数,B是Billion/十亿的意思,175B是1750亿参数,这是ChatGPT大约的参数规模。
大模型【LLMs】具有什么优点?
- 可以利用大量的无标注数据来训练一个通用的模型,然后再用少量的有标注数据来微调模型,以适应特定的任务。这种预训练和微调的方法可以减少数据标注的成本和时间,提高模型的泛化能力;
- 可以利用生成式人工智能技术来产生新颖和有价值的内容,例如图像、文本、音乐等。这种生成能力可以帮助用户在创意、娱乐、教育等领域获得更好的体验和效果;
- 可以利用涌现能力(Emergent Capabilities)来完成一些之前无法完成或者很难完成的任务,例如数学应用题、常识推理、符号操作等。这种涌现能力可以反映模型的智能水平和推理能力。
大模型LLM的 训练目标 是什么?
语言模型:根据 已有词 预测下一个词,训练目标为最大似然函数:
去噪自编码器:随机替换掉一些文本段,训练语言模型去恢复被打乱的文本段。
去噪自编码器的实现难度更高。采用去噪自编码器作为训练目标的任务有GLM-130B
BART、llama、gpt、t5、palm等主流模型异同点?
- BART (bi Encoder+casual Decoder,类bert的方法预训练)
- T5 (Encoder+Decoder,text2text预训练)
- GPT(Decoder主打zero-shot)
- GLM (mask的输入部分是双向注意力,在生成预测的是单向注意力)
流行的大模型架构?
- BART (bi Encoder+casual Decoder,类bert的方法预训练)
- T5 (Encoder+Decoder,text2text预训练)
- GPT(Decoder主打zero-shot)
- GLM (mask的输入部分是双向注意力,在生成预测的是单向注意力)
transform
传统的 attention 结构
- 注意力机制是什么呢?
- 就是将精力集中于某一个点上
- 举个例子:
- 你在超市买东西,突然一个美女从你身边走过,这个时候你会做什么呢?
- 没错,就是将视线【也就是注意力】集中于这个美女身上,而周围环境怎么样,你都不关注。
attention 的核心 就是从 大量信息中 筛选出少量的 重要信息;
- 具体操作:每个 value 的 权值系数,代表 其 重要度;
传统的 attention 流程
- 具体流程介绍
- step 1:计算权值系数
- 采用 不同的函数或计算方式,对 query 和 key 进行计算,求出相似度或相关性
存在问题
- 忽略了 源端或目标端 词与词间 的依赖关系【以上面栗子为例,就是把注意力集中于美女身上,而没看自己周围环境,结果可能就扑街了!】
为什么 会有self-attention?
学习句子内部的词依赖关系,捕获句子的内部结构。
- CNN 所存在的长距离依赖问题;
- RNN 所存在的无法并行化问题【虽然能够在一定长度上缓解 长距离依赖问题】;
传统 Attention
方法:基于源端和目标端的隐向量计算Attention,
结果:源端每个词与目标端每个词间的依赖关系 【源端->目标端】
问题:忽略了 远端或目标端 词与词间 的依赖关系
核心思想:self-attention的结构在计算每个token时,总是会考虑整个序列其他token的表达;
举例:“我爱中国”这个序列,在计算"我"这个词的时候,不但会考虑词本身的embedding,也同时会考虑其他词对这个词的影响
self-attention 结构图
- 一句话概述:每个位置的embedding对应 Q,K,V 三个向量,这三个向量分别是embedding点乘 WQ,WK,WV 矩阵得来的。每个位置的Q向量去乘上所有位置的K向量,其结果经过softmax变成attention score,以此作为权重对所有V向量做加权求和即可。
2.3 torch等
Tensors (张量)
Tensors (张量):类似于 NumPy 的 ndarrays ,同时 Tensors 可以使用 GPU 进行计算。
1、cuda安装,调试
2、用torch写过vgg,参考
PyTorch 作为库主要包含以下组件:
- Torch:类似于 NumPy 的张量库,带有强大的 GPU 支持
- torch.autograd:一个基于 tape 的自动微分库,支持 torch 中的所有的微分张量运算
- torch.nn:一个专为最大灵活性而设计、与 autograd 深度整合的神经网络库
- torch.multiprocessing:Python 多运算,但在运算中带有惊人的 torch 张量内存共享。这对数据加载和 Hogwild 训练很有帮助。
- torch.utils:数据加载器、训练器以及其他便利的实用功能
- torch.legacy(.nn/.optim):出于后向兼容性原因而从 torch 移植而来的旧代码
人们使用 PyTorch 一般出于两个目的:
代替 NumPy 从而可以使用强大的 GPU
PyTorch 作为深度学习研究平台提供了最大的灵活性与速度
3、理论算法(ICPC复健)
3.1 基础力扣(部分面试题)
编程题
- 最长无重复子数组,leetcode 原题,用滑动窗口来做
- 被围绕的区域, 牛客上的原题,考场上题目理解错了,写完后经面试官提示后发现是 DFS 或者 BFS
LeetCode101—对称二叉树
class Solution(object):
def isSymmetric(self, root):
"""
:type root: TreeNode
:rtype: bool
"""
if not root:
return []
def dfs(left, right):
if not left and not right:
return True
if not left or not right:
return False
if left.val != right.val:
return False
return dfs(left.left, right.right) and dfs(left.right, right.left)
return dfs(root.left, root.right)
LeetCode3—无重复字符的最长子串
class Solution(object):
def lengthOfLongestSubstring(self, s):
"""
:type s: str
:rtype: int
"""
start = 0
dic = {}
res = 0
for end in range(len(s)):
if s[end] in dic:
start = max(start, dic[s[end]] + 1)
dic[s[end]] = end
res = max(res, end - start + 1)
return res
LeetcCode130—被围绕的区域
class Solution:
def solve(self, board: List[List[str]]) -> None:
if not board:
return
n, m = len(board), len(board[0])
def dfs(x, y):
if not 0 <= x < n or not 0 <= y < m or board[x][y] != 'O':
return
board[x][y] = "A"
dfs(x + 1, y)
dfs(x - 1, y)
dfs(x, y + 1)
dfs(x, y - 1)
for i in range(n):
dfs(i, 0)
dfs(i, m - 1)
for i in range(m - 1):
dfs(0, i)
dfs(n - 1, i)
for i in range(n):
for j in range(m):
if board[i][j] == "A":
board[i][j] = "O"
elif board[i][j] == "O":
board[i][j] = "X"
3.2 其他
剑指 Offer(第 2 版)完整题解笔记 & C++代码实现(LeetCode版)
LeetCode 热题 HOT 100 完整题解笔记&知识点分类 C++代码实现
4、面经专项
4.1 蚂蚁算法岗
面经
nowcoder.com/discuss/353156401243561984
lr的损失函数是什么?lr为什么不用min square loss?
kkt的推导过程
使用hinge loss的意义,为什么linear svm的bound要设为1?
什么是kernel trick?对应无限维空间可以使用哪种kernel function?
lstm的原理知道吗?lstm与传统rnn相比有什么优势?
为什么lstm可以解决梯度消失的问题?lstm可以解决梯度爆炸吗?
cnn可以用来处理文本问题吗?为什么cnn可以用来处理文本问题?
nowcoder.com/discuss/524663737748414464
1、 数仓项目
2、 维度模型
3、 星型模型和雪花模型?
4、 雪花模型比星型模型的优势?
5、 缓慢变化维?
6、 比如科目(数学、语文)这种不变的维度你怎么处理?
7、 那你为什么还同步都不变化的了?
8、 你平常开发多啊还是数据处理多啊?
9、 数仓为什么分层?
10、 数据倾斜?举例子,平常碰到过没?
11、 一个reduce是一个服务器吗?
12、 Flink的窗口机制和滑动机制?
13、 Spark和Flink的区别?
14、 Set和List区别?
15、 HashMap是否并发的?
16、 GC原理?
17、 Finally是否一定执行?
18、 强制退出虚拟机是否能同时运行我们的代码?
19、 团队如何配合?
20、 你如何讲PPT?
21、 对不同的人是否会做不同版本的PPT?
22、 怎么把算法用到我们数仓构建中?
链接:nowcoder.com/discuss/524663737748414464
nowcoder.com/discuss/490656922484346880
自我介绍
是保研的吗
实习做了哪些工作
为什么想做数据开发
研究生的方向
本科学过哪些计算机专业课
栈和队列的区别,应用场景
二叉树了解吗, 平衡二叉树了解吗
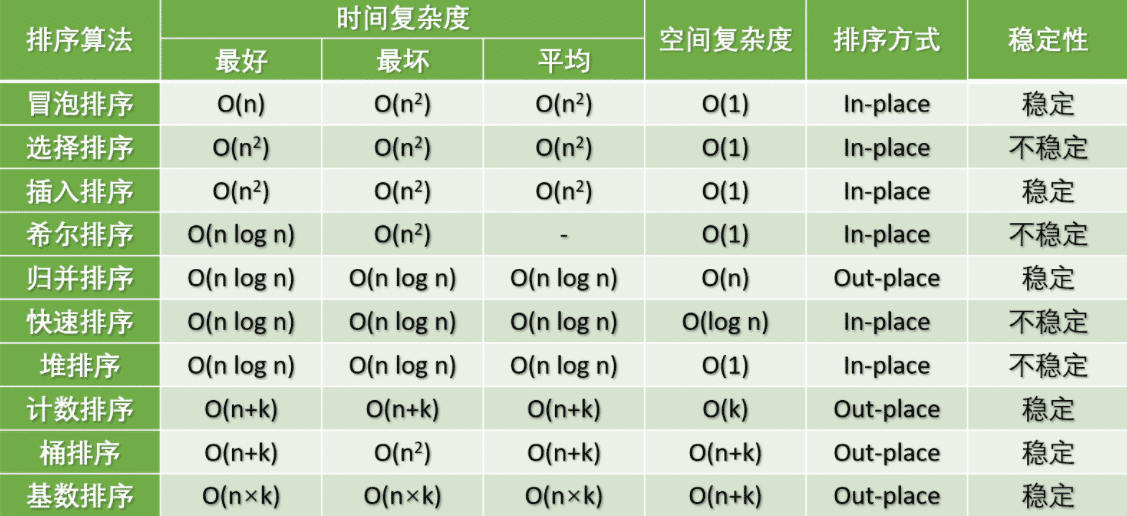
了解哪些排序算法, 分别说下原理和时间复杂度
快排的最差时间复杂度, 为什么,怎么优化
TCP三次握手, 为什么不是两次
MapReduce运行流程说一下
udf,udaf,udtf区别
spark的作业提交流程,说一下和MR的区别
数仓分层, 为什么分5层,每层作用
如果工作中和同事有意见分歧怎么解决, 怎么沟通
工作中遇到的最大的挑战
1周能来几天
反问:改进的地方,岗位职责
自我介绍
实习做了什么
大表join大表怎么优化
事实表设计的原则有哪些
hive分桶知道吗,有什么优势
你觉得你相比其他候选人的优势是什么
平时写代码吗,用的什么语言
逻辑回归l1,l2的区别
kmeans的过程
nowcoder.com/discuss/502779175359479808
4.2 其他算法岗
nowcoder.com/discuss/530222729648164864
nowcoder.com/feed/main/detail/c64ad6f358f04455b639e7952cb3b494
蔚来:
1. 解释一下lora的原理
2. lora有没有激活函数,为什么有or没有
3. 延续第3问,如果给lora加激活函数,你觉得用什么比较好,用了能不能收敛,为什么
4. lora微调的感悟(对不同参数的理解)
5. 对prompt设置的一些感悟,在什么情况下怎么设置是最好的
6. SAM效果好的原因?
7. SAM的prompt有哪些,可以怎么运用
8. recall和precision的区别(强调不要背公式,讲自己的理解)
9. 代码环节:手搓multi-head attn
百度:
1. SD的结构(VAE,DDPM,U-Net,Text Encoder几个模块)
2. DDPM和DDIM有什么区别(两种用于图像生成和图像去噪的模型,主要区别在于建模方式和训练过程。DDPM是一种概率模型,通过迭代扩散过程来建模图像的概率分布;而DDIM是一种隐式模型,通过学习一个映射函数来进行图像去噪。)
3. 为什么DDIM解决了DDPM的不足(从数学上分析),他两谁是子集谁是母集
4. L1和L2有什么区别,各自的优缺点?
(L1正则化(Lasso正则化)通过将模型参数的绝对值之和添加到损失函数中。
L2正则化(岭回归)通过将模型参数的平方和添加到损失函数中。相比于L1正则化,L2正则化更倾向于将参数的权重均匀分布在不为零的值上。
L1正则化适用于特征选择和稀疏性问题,而L2正则化适用于减少过拟合风险和提高模型的泛化能力。)
5. 开放性问答:你觉得SD的VAE可以替换成什么,为什么
6. 简述一下ControlNet,DreamBooth,LoRA的原理,各自的优缺点
7. U-Net的skip-connection意义是什么
8. 口述将一张图片实现90度旋转的思路
9. 代码环节:一面基于numpy手搓卷积过程,二面求连通岛屿数量
二面表现一般,HC也不充足,遗憾离场了
nowcoder.com/discuss/595574221514821632
字节跳动数据科学面经
一面:
自我介绍
机器学习中常见的回归和分类算法
AB实验:全流程、两类错误、p值、样本量、中心极限定理、Z检验&t检验、卡方检验,绝对值指标以及比值指标各自适用的检验
线性回归共线性、过拟合、正则化
针对实习经历问了常用的时序模型以及评价标准
对DS和DA的理解
二面:
自我介绍
逻辑回归的损失函数
随机森林和XGBoost的区别
主成分分析的原理
sql窗口函数以及区别
中心极限定理和大数定律
三面:
自我介绍
介绍一个实习中的项目
客户留存率下降怎么分析?
58算法
nowcoder.com/feed/main/detail/2d5e9f74c8b44821858e32ae1de048cc
问学校的nlp相关项目,解释的算细
问bert是什么结构,问还有什么类似模型。(基于Transformer架构的预训练语言模型,还有GPT)
问链表找环,回答的快慢指针直接说错,说这样找不到环。(快慢指针)
多个文件中找一个词怎么快。
代码题 三元组找和为0,正常解题速度一直催,最后说了思路结束
百度
2.项目介绍和深挖
3.bert/t5的区别(BERT是一种预训练的语言模型,可以用于各种下游任务。而T5是一种通用的文本到文本转换模型,可以通过微调适应多种NLP任务)
4.bert参数量计算(参数量 = (输入维度 × 隐藏层维度) + (隐藏层维度 × 4 × 注意力头数) + (隐藏层维度 × 2 × 前馈神经网络维度) + (隐藏层维度 × 2)
其中,输入维度是指输入词向量的维度,隐藏层维度是指Transformer模型中隐藏层的维度,注意力头数是指多头注意力机制中的注意力头数,前馈神经网络维度是指Transformer模型中前馈神经网络的维度。
)
nowcoder.com/feed/main/detail/f1cf76a27c4248378303dadcd0d810de
简历有写大模型微调 问了目前的大模型微调方法你觉得哪一个最好?
+ 全部微调(Full Fine-tuning):将预训练的大模型的所有参数都进行微调。这种方法通常在目标任务的数据集较大且与预训练数据相似时效果较好。
冻结部分层(Layer Freezing):将预训练模型的一部分层参数固定,只微调模型的部分层。这种方法适用于目标任务的数+ 据集较小,或者与预训练数据差异较大的情况。通过冻结一部分层,可以减少微调过程中的参数量,从而降低过拟合的风险。
+ 逐层微调(Layer-wise Fine-tuning):逐层微调是一种渐进式微调方法,从模型的底层开始逐渐解冻和微调更高层的参数。这种方法可以在初始阶段保留预训练模型的较低层的特征提取能力,同时在后续阶段逐渐适应目标任务的特征。
+ 动态掩码微调(Dynamic Masking Fine-tuning):在微调过程中,通过动态掩码机制对输入进行遮盖,以增强模型对目标任务的关注。这种方法可以提高模型对目标任务的适应性,并减少对预训练数据的依赖。
最好的微调方法取决于具体的任务和数据集。通常,全部微调在数据集相似且规模较大时效果较好,而冻结部分层或逐层微调适用于数据集较小或与预训练数据差异较大的情况。动态掩码微调可以在目标任务的关注点不同或需要增强模型的适应性时提供一定的优势。
链接:nowcoder.com/discuss/502779175359479808
知乎-推荐算法
一面
python基础:深拷贝、浅拷贝、多线程、生成器迭代器
分类和回归常用loss、优化器、激活函数区别
聊实习
代码题:lc213
介绍一下WDL,各自作用,去掉Wide可以吗
介绍一下召回排序链路,哪一个最重要
二面
随便聊聊论文
了解排序算法吗,时间复杂度,python排序库函数原理是什么
了解重混排吗,介绍一下
代码:检验二叉搜索树
后来面完和二面ld聊了很久,ld人很好诚意很足,可惜最后还是没去
链接:nowcoder.com/discuss/502779175359479808
快手-ytech推荐算法
一面
自我介绍,先写两道题,两个栈实现队列、二叉树根节点到叶子节点的路径(自己建树)
写代码时间有点长,后面没多少时间了,就问了下实习和论文,有点赶,叫我挑重要的说
然后八股,问了个梯度消失、梯度爆炸咋办。
二面
问实习和代码问了好久,感觉确实是比较有水平的,拷打了很久我的论文
代码题:删除数组中重复的数字
反问:面试官好能讲。。。。
三面
被拷打了实习,聊什么是自监督,自监督的做法、为什么有用,最新的趋势是什么
假设面试官是个从来不懂计算机的外行人,该怎么解释自监督的原理和做法?
从有监督、到无监督怎么做的,一步一步说的。举猫狗的例子,然后自监督是否能应用到这个任务中?然后我举了个文本生成的例子:完形填空,模型怎么设计,输入输出是什么(其实就是word2vec的原理)。讲了很多,讲完这部分面试就到四十多分钟了,还给面试官画了图。
链接:nowcoder.com/discuss/502779175359479808
b站-搜索
一面
实习项目、论文
冷启动怎么做、线上配额等等
介绍一下transformer、BERT、GPT
介绍一下FM、WDL、DIN
当谈到推荐系统时,FM(Factorization Machines)、WDL(Wide & Deep Learning)和DIN(Deep Interest Network)是三种常见的模型。
+ FM是一种基于矩阵分解的模型,用于解决稀疏数据下的推荐问题。它通过将特征向量进行组合,学习特征之间的交互关系,从而预测用户对物品的喜好程度。FM模型在处理高维稀疏数据时表现出色,尤其适用于处理具有大量类别特征的推荐问题。
+ WDL是一种结合了广度和深度学习的模型,旨在充分利用广度模型的记忆能力和深度模型的泛化能力。广度部分通过学习特征之间的交叉关系来捕捉用户的历史行为模式,而深度部分则通过多层神经网络学习更高级别的特征表示。WDL模型在处理具有丰富特征的推荐问题时表现出色,能够同时考虑用户的历史行为和物品的特征。
+ DIN是一种基于注意力机制的模型,旨在解决推荐系统中的兴趣漂移问题。它通过动态地计算用户对不同物品的兴趣权重,将用户的兴趣引导到更相关的物品上。DIN模型通过学习用户的兴趣演化过程,能够更好地适应用户的个性化需求。
代码题:移掉k位数字,lc402
二面
自我介绍、论文、实习
两道题:lc141、lc40
三面
论文、实习,然后引申问了些问题
无代码
5、项目准备
相关推荐系统、机器学习、计算机视觉、数据挖掘等相关领域研究及实践经验。
项目1,研究,nlp
sci二区一作,加密搜索
项目2,调参
科大讯飞GLM训练,bert训练,vgg+cnn,SD调参,gpt学术_GLM调参
项目3,应用,搜索推荐
计算机设计国二,ei,推荐搜索项目,协同过滤
项目1:算法研究、TF-IDF、倒排索引
one-hot 篇
- 用一个很长的向量来表示一个词,向量长度为词典的大小N,每个向量只有一个维度为1,其余维度全部为0,为1的位置表示该词语在词典的位置。
- 维度长:向量的维度为 词典大小;一一其零:每个向量只有一个维度为1,其余维度全部为0,为1的位置表示该词语在词典的位置;
- 维度灾难:容易受维数灾难的困扰,每个词语的维度就是语料库字典的长度;
- 离散、稀疏问题:因为 one-Hot 中,句子向量,如果词出现则为1,没出现则为0,但是由于维度远大于句子长度,所以句子中的1远小于0的个数;
- 维度鸿沟问题:词语的编码往往是随机的,导致不能很好地刻画词与词之间的相似性。
TF-IDF
TF-IDF 是一种统计方法,用以评估句子中的某一个词(字)对于整个文档的重要程度。
对于 句子中的某一个词(字)随着其在整个句子中的出现次数的增加,其重要性也随着增加;(正比关系)【体现词在句子中频繁性】
对于 句子中的某一个词(字)随着其在整个文档中的出现频率的增加,其重要性也随着减少;(反比关系)【体现词在文档中的唯一性】
如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类;
TF-IDF 怎么描述?
- 某一特定句子内的高词语频率,以及该词语在整个文档集合中的低文档频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
优点:容易理解;容易实现;
缺点:其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
应用:搜索引擎;关键词提取;文本相似性;文本摘要
倒排索引
- 对于每个单词,记录包含该单词的文档列表。这个过程可以使用哈希表或者树等数据结构来实现。
“脏数据” 怎么处理呢?
- 如何寻找“脏数据”?
- 人工清洗? 【眼瞎】
- 重标? 【标注人员和平相处五项原则】
- 自己改? 【外号 “算法工程师” 的 “标注工程师”】
- 那有没有好点的方法呢?
置信学习方法
- 置信学习方法 其实就是 计算 每一个样本的 标签的置信度,以识别标签错误、表征标签噪声并应用于带噪学习(noisy label learning)。【注:模型找出的置信度低的样本,并不一定就是错误样本,而只是一种不确定估计的选择方法】
- 举例说明:在某些场景下,对训练集通过交叉验证来找出一些可能存在错误标注的样本,然后交给人工去纠正。
- 置信学习方法 优点?
- 发现 “可能错误的样本” 【注:这个只能说是相对的,因为模型找出的置信度低的样本,并不一定就是错误样本,而只是一种不确定估计的选择方法】;
- 置信学习开源工具 cleanlab
- 可直接估计噪声标签与真实标签的联合分布,具有理论合理性。
- 不需要超参数,只需使用交叉验证来获得样本外的预测概率。
- 不需要做随机均匀的标签噪声的假设(这种假设在实践中通常不现实)。
- 与模型无关,可以使用任意模型,不像众多带噪学习与模型和训练过程强耦合。
- 置信学习方法 主要是通过 寻找出 标注数据中的 “脏数据”,然后抛弃掉这些数据后重新训练,也就是直接估计噪声标签和真实标签的联合分布,而不是修复噪声标签或者修改损失权重。
搜索排序和系统推荐还是有区别的,因为搜素有输入,推荐没有
不过有可以类比和参考的点
项目2:算法调参,大模型应用,GLM/Bert训练
1、调过SD,stable diff,图像八股1, 做过自动驾驶,3D点云分析,看过相关论文
2、用GLM训练过NLP,bert原理,transform
3、GLM调参
Bert 三个关键点?
- 1、基于 transformer 结构,【预训练】+【微调】
- 2、大量语料预训练:
- 介绍:在包含整个维基百科的无标签号文本的大语料库中(足足有25亿字!) 和图书语料库(有8亿字)中进行预训练;
- 优点:大语料 能够 覆盖 更多 的 信息;
- 3、双向模型:BERT是一个“深度双向”的模型。双向意味着BERT在训练阶段从所选文本的左右上下文中汲取信息,举例:
- BERT同时捕获左右上下文,如果仅取左上下文或右上下文来预测单词“bank”的性质,那么在两个给定示例中,至少有一个会出错;
- 解决方法:在做出预测之前同时考虑左上下文和右上下文
GPT和BERT有什么不同?
- 模块选择:
- GPT-2 是使用「transformer 解码器模块」构建的
- BERT 则是通过「transformer 编码器」模块构建的。
- GPT是单向的体现:如果我们重点关注位置单词及其前续路径,模型只允许注意当前计算的单词以及之前的单词:
- Bert 是双向的; Bert是双向的体现:Bert的自注意力模块允许一个位置看到它左右侧单词的信息,为了 避免 当前位置经过多层之后看到自己
- GPT-2 自回归(auto-regression):效果好因为是在每个新单词产生后,该单词就被添加在之前生成的单词序列后面,这个序列会成为模型下一步的新输入
- BERT在训练中加入了下一个句子预测任务,所以它也有 segment嵌入;
为什么 elmo、GPT、Bert能够解决多义词问题?
- 因为预训练过程中,emlo 中 的 lstm 能够学习到 每个词 对应的 上下文信息,并保存在网络中,在 fine-turning 时,下游任务 能够对 该 网络进行 fine-turning,使其 学习到新特征;
文本表示和各词向量间的对比?
- 基于one-hot、tf-idf、textrank等的bag-of-words;
- 主题模型:LSA(SVD)、pLSA、LDA;
- 基于词向量的固定表征:word2vec、fastText、glove
- 基于词向量的动态表征:elmo、GPT、bert
Transformer
RNN:能够捕获长距离依赖信息,但是无法并行;
CNN: 能够并行, ** 无法捕获长距离依赖信息(需要通过层叠 or 扩张卷积核 来 增大感受**野);
传统 Attention
- 方法:基于源端和目标端的隐向量计算Attention,
- 结果:源端每个词与目标端每个词间的依赖关系 【源端->目标端】
- 问题:忽略了 远端或目标端 词与词间 的依赖关系
基于Transformer的架构主要用于建模语言理解任务,它避免了在神经网络中使用递归,而是完全依赖于self-attention机制来绘制输入和输出之间的全局依赖关系。
具体介绍:
左边是一个 Encoder;
右边是一个 Decoder;
可以知道 Transformer 是一个 encoder-decoder 结构,但是 encoder 和 decoder 又包含什么内容呢?
- Encoder 结构:
- 内部包含6层小encoder 每一层里面有2个子层;
- Decoder 结构:
- 内部也是包含6层小decoder ,每一层里面有3个子层
self-attention 如何解决长距离依赖问题?
- CNN 主要采用 卷积核 的 方式捕获 句子内的局部信息,你可以把他理解为 基于 n-gram 的局部编码方式捕获局部信息。类似于 人的 视觉范围,人的视觉范围 在每一时刻 只能 捕获 一定 范围内 的信息,比如,你在看前面的时候,你是不可能注意到背后发生了什么,除非你转过身往后看。
- RNN 主要 通过 循环 的方式学习(记忆) 之前的信息xt;RNN 的学习模式好比于 人类 的记忆力,人类可能会对 短距离内发生的 事情特别清楚,但是随着时间的推移,人类开始 会对 好久之前所发生的事情变得印象模糊,比如,你对小时候发生的事情,印象模糊一样。
- 针对该问题,后期也提出了很多 RNN 变体,比如 LSTM、 GRU,这些变体 通过引入 门控的机制 来 有选择性 的记忆 一些 重要的信息,但是这种方法 也只能在 一定程度上缓解 长距离依赖问题,但是并不能 从根本上解决问题。
- self-attention 是如何 解决 长距离依赖问题的呢?
- 利用注意力机制来**“动态”地生成不同连接的权重**,从而处理变长的信息序列。对于 当前query,你需要 与 句子中 所有 key 进行点乘后再 Softmax ,以获得 句子中 所有 key 对于 当前query 的 score(可以理解为 贡献度),然后与 所有词 的 value 向量进行加权融合之后,就能使 当前 yt 学习到句子中 其他词xt−k的信息;
self-attention 如何并行化?
- 在上一个问题中,我们主要讨论了 CNN 和 RNN 在处理长序列时,都存在 长距离依赖问题,以及 Transformer 是 如何解决 长距离依赖问题,但是对于 RNN ,还存在另外一个问题:
- Transformer 如何进行并行化?
- 为什么 RNN 不能并行化:
- 原因:RNN 在 计算 xi 的时候,需要考虑到 x1 xi−1 的 信息,使得 RNN 只能 从 x1 计算到 xi;
- 思路:在 self-attention 能够 并行的 计算 句子中不同 的 query,因为每个 query 之间并不存在 先后依赖关系,也使得 transformer 能够并行化;
Position encoding和 Position embedding的区别?
- Position encoding 构造简单直接无需额外的学习参数;能兼容预训练阶段的最大文本长度和训练阶段的最大文本长度不一致;
- Position embedding 构造也简单直接但是需要额外的学习参数;训练阶段的最大文本长度不能超过预训练阶段的最大文本长度(因为没学过这么长的,不知道如何表示);但是Position embedding 的潜力在直觉上会比 Position encoding 大,因为毕竟是自己学出来的,只有自己才知道自己想要什么(前提是数据量得足够大)。
既然 Transformer 怎么牛逼,是否还存在一些问题?
- 问题一:Transformer 不能很好的处理超长输入问题;
- 问题二:方向信息以及相对位置 的 缺失 问题【这个问题在 NER 任务上表现明显,这也是为什么 Transformer 在 NER 任务上,效果要 差于 BiLSTM-CRF 和 IDCNN-CRF 的原因】;
- 问题三:缺少Recurrent Inductive Bias;
- 问题四:Transformer是非图灵完备的: 非图灵完备通俗的理解,就是无法解决所有的问题;
- 问题五:transformer缺少conditional computation;
- 问题六:transformer 时间复杂度 和 空间复杂度 过大问题;
介绍:Transformer 固定了句子长度
- 举例:
- 例如 :在 Bert 里面,输入句子的默认长度 为 512;
- 对于 短于 512:填充句子方式;
- 长于 512:会采用不同的方式进行处理
Transformer 固定了句子长度 的目的是什么?
- 考虑了计算与运行效率综合做出的限制:
- GPU memory:由于 self-attention 的计算开销 为 O(n^2),如果序列长度太长,资源消耗大;
- word piece tokenizer会把句子拆解成很细碎的token,远超过之前句子的长度。所以512其实不是很大的数字。
项目3:算法应用,搜索推荐,协同过滤
用户可以自己决定喜好内容,我们通过jieba中文分词框架搭建TF-IDF模型,将新闻中的词进行词向量化,并赋予对应权重,提取到新闻关键字。系统再根据用户的喜好、用户行为、新闻的特征进行计算得到用户评分矩阵,用户评分矩阵分解得到用户和新闻画像,将这两项相乘得到近似矩阵,从而实现首页的智能推荐。
该系统还使用了本地差分隐私技术,为了避免攻击者根据推荐结果反推出推荐依据,侵犯用户隐私,我们在综合评分上加入符合LDP约束限制的噪声,使攻击者难以通过推荐结果辨识出这些用户隐私数据的真实值,实现对用户隐私的保护。
- 本地差分隐私的基本原理是在个体数据上引入随机性,使得对于任何一个个体来说,其贡献到最终结果的影响是不可区分的。这样可以防止通过分析结果来推断个体的敏感信息。