目录
一、Beautiful Soup 的简介
网页结构 / 字符串 数据解析工具。
要学习Beautiful Soup,请确保已经正确安装好了 Beautiful Soup 和 lxml 第三方库。
二、解析器
Beautiful Soup 在解析时实际上依赖解析器,它除了支持 Python 标准库中的 HTML 解析器外,还支持一些第三方解析器(比如 lxml)。如下图列出了 Beautiful Soup 支持的解析器:
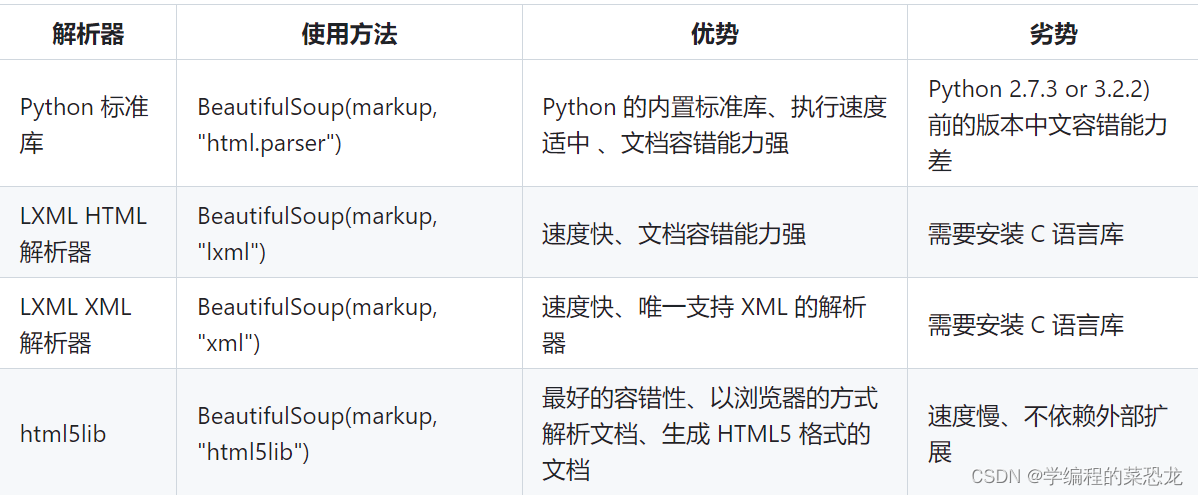
通过以上对比可以看出,lxml 解析器有解析 HTML 和 XML 的功能,而且速度快,容错能力强,所以推荐使用它。
如果使用 lxml,那么在初始化 Beautiful Soup 时,可以把第二个参数改为 lxml 即可:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello</p>', 'lxml')
print(soup.p.string) # 输出: Hello三、基本使用
Beautiful Soup 的使用是基于 Soup 对象,可以使用 BeautifulSoup() 方法来获得这个对象。
现在用实例来看看 Beautiful Soup 的基本用法:
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup.prettify()) # 标准缩进
print(soup.title.string) # 输出title中内容<html>
<head>
<title>
The Dormouse's story
</title>
</head>
</html> # Beautiful Soup自动修正
The Dormouse's story首先要有一个字符串对象,之后 BeautifulSoup() 方法赋值得到 Soup 对象,方法中第一个参数为字符串,第二个参数是解析器。然后就可以对 Soup 进行操作。
四、节点选择器
上述 soup.节点名称 就是直接调用节点的名称,其可以选择节点元素,再调用 string 属性就是得到节点内的文本,这种选择方式速度非常快。如果单个节点结构层次非常清晰,可以选用这种方式来解析。
1 选择元素
下面用一个例子详细说明选择元素的方法:
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/tillie" class="sister" id="link2">Tillie</a>;
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.title) # 也可以嵌套选择 soup.head.title
print(type(soup.title))
print(soup.title.string)
print(soup.head)
print(soup.p)# 输出:
<title>The Dormouse's story</title>
<class 'bs4.element.Tag'> # bs4.element.Tag 类型
The Dormouse's story
<head><title>The Dormouse's story</title></head>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>可以看到 怕节点有两个,其只返回了一个,所以当有多个节点时,这种选择方式只会选择到第一个匹配的节点,其他的后面节点都会忽略。
上面演示了调用 string 属性来获取文本的值,那么如何获取节点属性的值呢?如何获取节点名呢?下面我们来统一梳理一下信息的提取方式。
2 获取名称、属性、文本内容
可以利用 name 属性获取节点的名称。以上面的文本为例:
print(soup.title.name)
# 输出:title每个节点可能有多个属性,比如 id 和 class 等,选择这个节点元素后,可以调用 attrs 获取所有属性:
print(soup.p.attrs)
print(soup.p.attrs['name'])
# 等同:print(soup.p['name']),不用attrs
print(soup.p['class'])输出:
{'class': ['title'], 'name': 'dromouse'}
dromouse
['title']这里需要注意的是,有的返回结果是字符串,有的返回结果是字符串组成的列表。比如,name 属性的值是唯一的,返回的结果就是单个字符串。而对于 class,一个节点元素可能有多个 class,所以返回的是列表。在实际处理过程中,我们要注意判断类型。
获取文本内容: .string 即可
五、方法选择器
1 find_all
find_all,就是查询所有符合条件的元素,可以给它传入一些属性或文本来得到符合条件的元素,返回列表类型,列表中的元素都是 Tag 类型,所以依然可以进行嵌套查询。它的 API 如下:
find_all(name , attrs , recursive , text , **kwargs)下面我们用一个实例来感受一下:
传入 name 节点名
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
# name 节点名
print(soup.find_all(name='ul'))
print(type(soup.find_all(name='ul')[0]))传入 attrs 属性
print(soup.find_all(attrs={'id': 'list-1'}))
print(soup.find_all(attrs={'name': 'elements'}))
# id、class属性比较常见 attrs={'id': 'list-1'} 也可以不要 attrs
# 换成:id='list-1'
print(soup.find_all(class_='element'))注意 class ,由于 class 在 Python 里是一个关键字,所以后面需要加一个下划线,即 class_='element',返回的结果依然还是 Tag 组成的列表。
传入 text
text 参数可用来匹配节点的文本,传入的形式可以是字符串,可以是正则表达式对象,示例如下:
import re
html='''
<div class="panel">
<div class="panel-body">
<a>Hello, this is a link</a>
<a>Hello, this is a link, too</a>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(text=re.compile('link')))['Hello, this is a link', 'Hello, this is a link, too']2 find
find 方法返回的是单个元素,也就是第一个匹配的元素,而 find_all 返回的是所有匹配的元素组成的列表。示例如下:
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find(class_='element'))
print(type(soup.find(class_='element')))
<li class="element">Foo</li>
<class 'bs4.element.Tag'>六、CSS 选择器
如果对 Web 开发熟悉的话,那么对 CSS 选择器肯定也不陌生。如果不熟悉的话,可以参考 CSS 选择器参考手册 了解。
1 实例
使用 CSS 选择器,只需要调用 select 方法,传入相应的 CSS 选择器即可,我们用一个实例来感受一下:
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.select('.panel .panel-heading'))
print(soup.select('ul li'))
print(soup.select('#list-2 .element'))
print(type(soup.select('ul')[0]))[<div class="panel-heading">
<h4>Hello</h4>
</div>]
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo</li>, <li class="element">Bar</li>]
[<li class="element">Foo</li>, <li class="element">Bar</li>]
<class 'bs4.element.Tag'>这里我们用了 3 次 CSS 选择器,返回的结果均是符合 CSS 选择器的节点组成的列表。例如,select('ul li') 则是选择所有 ul 节点下面的所有 li 节点,结果便是所有的 li 节点组成的列表。最后一句我们打印输出了列表中元素的类型,可以看到类型依然是 Tag 类型。
2 获取属性
我们知道节点类型是 Tag 类型,所以获取属性还可以用原来的方法。仍然是上面的 HTML 文本,这里尝试获取每个 ul 节点的 id 属性:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
for ul in soup.select('ul'):
print(ul['id'])
print(ul.attrs['id'])3 获取文本
要获取文本,当然也可以用前面所讲的 string 属性。此外,还有一个方法,那就是 get_text,示例如下:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
for li in soup.select('li'):
print('Get Text:', li.get_text())
print('String:', li.string)七、结语
- 推荐使用 LXML 解析库,必要时使用 html.parser。
- 节点选择筛选功能弱但是速度快。
- 建议使用 find、find_all 方法查询匹配单个结果或者多个结果。
- 如果对 CSS 选择器熟悉的话可以使用 select 选择法。
文章到此结束,本人新手,若有错误,欢迎指正;若有疑问,欢迎讨论。若文章对你有用,点个小赞鼓励一下,谢谢大家,一起加油吧!