1、 引言
在大数据时代,网络上的信息犹如海洋般浩瀚。想要在这片海洋里挖掘宝藏,一款强大的工具必不可少。今天我们要带大家深入探索的就是Python界鼎鼎大名的爬虫框架——Scrapy。无论你是数据分析师、研究员还是开发者,学会利用Scrapy来自动化地抓取网页数据,都将极大地提升你的工作效率和数据获取能力!
第一步:安装Scrapy
在开始我们的“寻宝之旅”前,确保已安装好Python及pip环境。打开命令行工具,以管理员权限运行,并键入魔法般的命令:
pip install scrapy
如果一切顺利,只需片刻,Scrapy就会乖乖待在你的Python环境中啦!但若遇到报错提示缺少依赖,别担心,依据提示信息,去官方网站或其他可靠渠道下载对应库手动安装就好。
第二步:快速创建第一个Scrapy项目
假设我们想创建一个名为“web_scraper”的爬虫项目,只需几步简单的命令:
scrapy startproject web_scraper
cd web_scraper
接下来,在项目内创建一个爬虫模块:
scrapy genspider example www.example.com
现在,你已经有了一个基础的Scrapy爬虫骨架,准备好进一步定制和优化!
💡 小技巧:
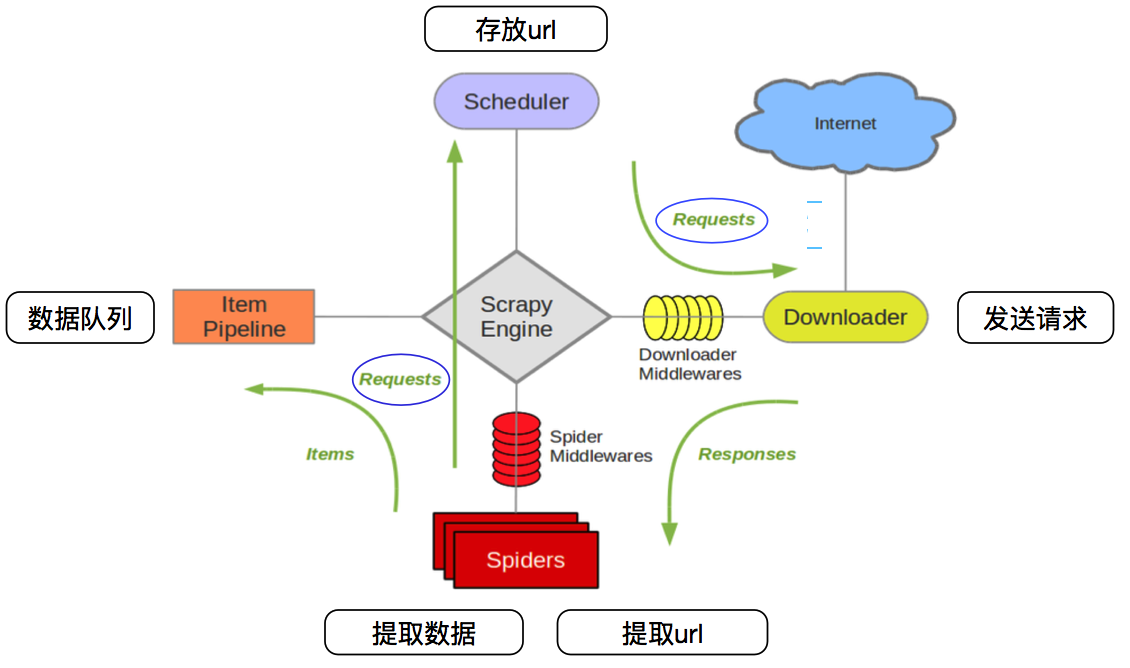
别忘了Scrapy的强大之处在于其组件化设计,你可以通过自定义Downloader Middlewares、Spider Middlewares和Item Pipelines来应对更复杂的爬取场景,如模拟登录、动态加载页面解析等。
2、应用案例
由于法律和道德规范限制,直接针对百度图片进行爬取可能违反其服务条款,并且不鼓励未经许可的大规模爬取任何网站的内容。然而,我可以为您提供一个基本的Scrapy爬虫框架,用于爬取图片类网站(假设它们允许爬取)。以下是一个简化的Scrapy爬虫模板,展示了如何设置项目结构以便爬取并存储图片。为了遵守法规和尊重版权,请确保您的爬虫仅用于合法授权的用途,并且在实施之前检查目标网站的服务条款和robots.txt文件。
下面以爬取百度图片为例供大家参考:
1. 创建Scrapy项目并定义Item
# 创建Scrapy项目
scrapy startproject baidu_image_crawler
cd baidu_image_crawler
scrapy genspider baidupic baidu.com
2. 修改items.py
# baidu_image_crawler/items.py
import scrapy
class BaiduImageItem(scrapy.Item):
image_urls = scrapy.Field() # 图片链接列表
images = scrapy.Field() # 图片文件对象列表
3. 编写爬虫(spiders/baidupic.py)
# spiders/baidupic.py
import scrapy
from baidu_image_crawler.items import BaiduImageItem
class BaidupicSpider(scrapy.Spider):
name = 'baidupic'
allowed_domains = ['www.baidu.com'] # 替换成实际图片所在域名
start_urls = ['https://example.com/search_result_page'] # 替换成实际搜索结果页URL
def parse(self, response):
# 根据百度图片实际网页结构解析图片链接
# 这里仅做示范,实际情况下需要分析百度图片搜索结果页HTML结构
for img_src in response.css('img.image-source::attr(src)').getall():
item = BaiduImageItem()
item['image_urls'] = [img_src]
yield item
# 使用ImagesPipeline处理下载图片
4. 设置并启用ImagesPipeline
# baidu_image_crawler/settings.py
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': None,
# 如果需要处理重定向,则需替换为自定义中间件或重新启用默认中间件
}
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1, # 启用图片管道
}
IMAGES_STORE = 'path/to/your/image_storage' # 图片存储路径
5. 可能需要自定义ImagesPipeline
如果百度图片的链接需要额外处理才能下载原始图片,可能需要扩展ImagesPipeline。例如:
# pipelines.py
from scrapy.pipelines.images import ImagesPipeline
class CustomImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
def file_path(self, request, response=None, info=None, *, item=None):
# 定义图片存储路径和文件名
# 根据实际情况编写,这里只是一个示例
image_guid = request.url.split('/')[-1]
filename = f'{image_guid}.jpg'
return 'full/{filename}'.format(filename=filename)
然后在ITEM_PIPELINES中使用自定义的CustomImagesPipeline。
实际抓取需要进一步考虑百度图片搜索的具体实现细节。在实际应用中,你需要分析百度图片搜索结果页面的HTML结构以正确提取图片链接,并且要遵守网站的使用规定。此外,百度图片搜索可能会有反爬机制,因此在编写爬虫时要注意合理规避,并尽可能减少对服务器的压力。
更多精彩文章请关注微信公众号:手把手PythonAI编程

关注后回复【教程】领取50本优质Python编程、人工智能电子书籍
往期推荐:
精通Python数据处理:掌握Agate,解锁数据分析新境界
掌握Python图像处理艺术:Pillow库入门实践与案例解析