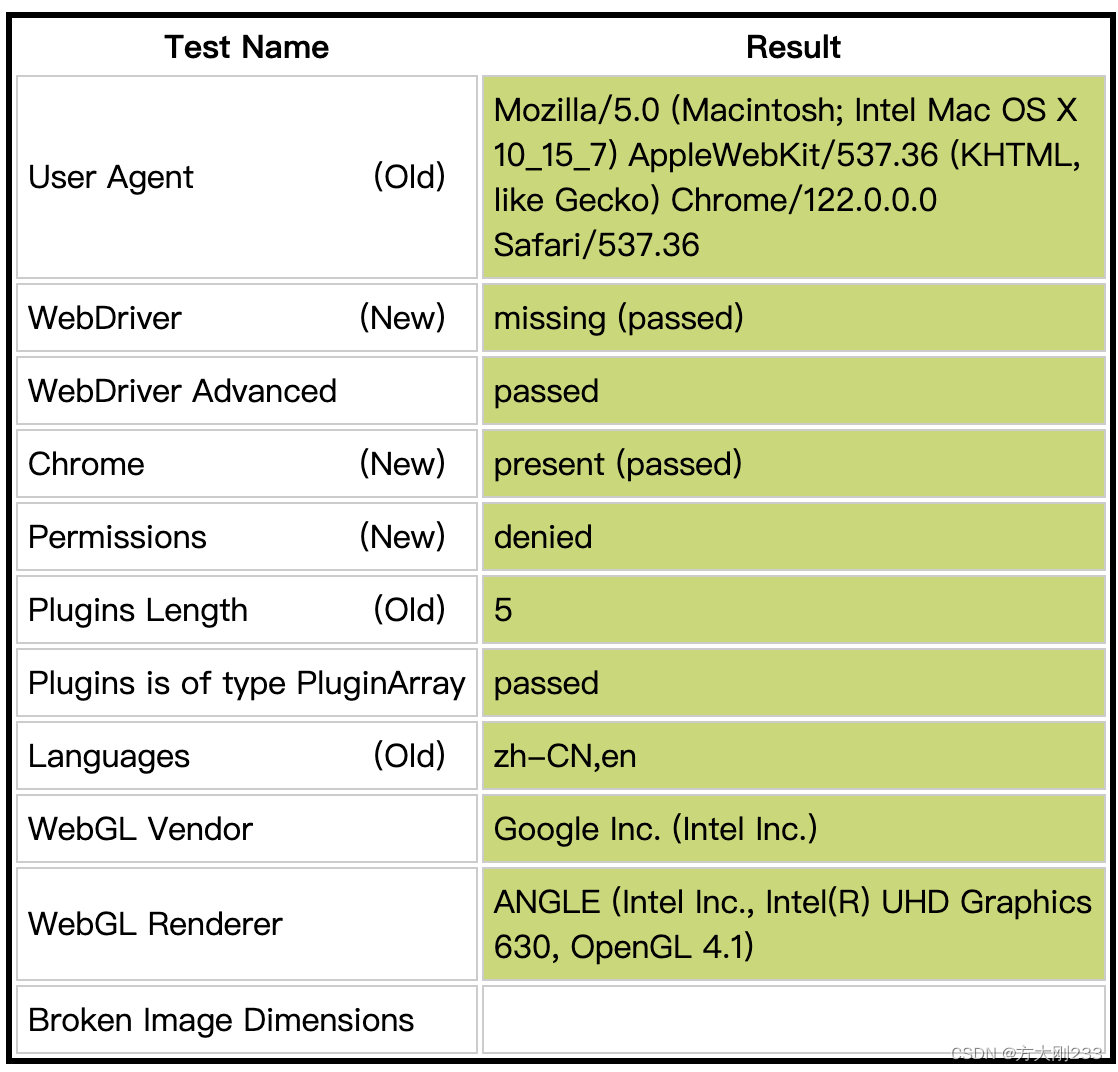
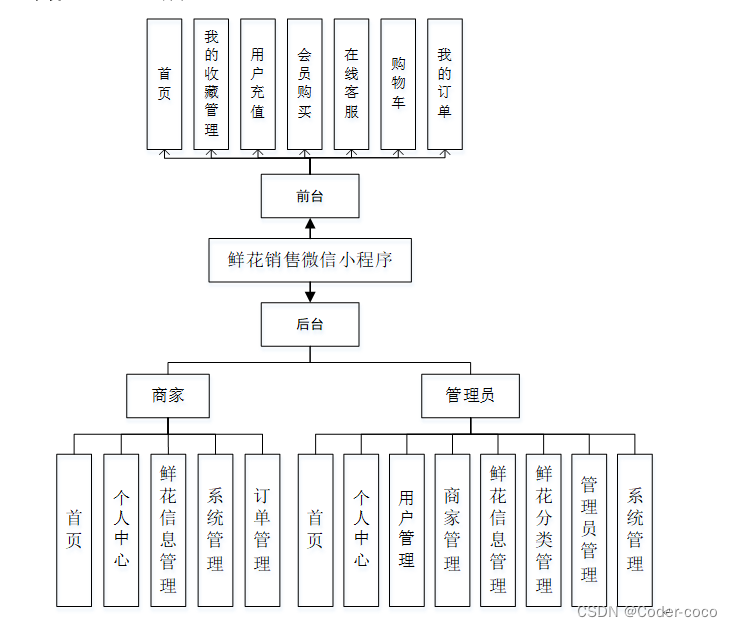
在机器学习中,特征缩放是训练模型前数据预处理阶段的一个关键步骤。不同的缩放器被用来规范化或标准化特征。这里简要概述了您提到的几种缩放器:
StandardScaler
`StandardScaler` 通过去除均值并缩放至单位方差来标准化特征。这种缩放器假设特征分布是正态的,并将它们缩放为均值为零和标准差为一。用于缩放特征 `X` 的公式是:

其中 `μ` 是特征值的平均值,`σ` 是标准差。
MinMaxScaler
`MinMaxScaler` 将特征缩放到给定范围,通常在零和一之间,或者使最小和最大值与某个特定范围对齐。转换公式为:

其中 `X_min` 和 `X_max` 分别是特征的最小值和最大值。这种缩放将所有内点压缩到 [0, 1] 范围内。
RobustScaler
`RobustScaler` 使用类似于 `StandardScaler` 的方法,但它使用中位数和四分位数范围而不是均值和方差。这使得 `RobustScaler` 对异常值的敏感度较低。公式是:
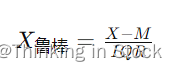
其中 `M` 是中位数,`IQR` 是特征值的四分位数范围。
何时使用每种缩放器:
- **StandardScaler**:当您的特征大致呈正态分布,并且您希望假设您的特征具有高斯分布时。
- **MinMaxScaler**:当您知道特征的边界并希望将特征转换为在这些边界之间缩放时。
- **RobustScaler**:当您的特征中有异常值并希望减少其影响时。
需要注意的是,特征缩放可能会影响您的机器学习模型的性能,特别是对于那些计算数据点之间距离的算法,比如 SVM 或 k-NN,或者那些对特征缩放敏感的基于梯度下降的算法。对于基于树的算法,特征缩放则不那么重要,因为它们是尺度不变的。