官网发表的文章地址:RISC-V Optimization Guide
B站有人做过解读视频,这篇文章也是看视频时做的笔记:视频地址
一、标量整数优化
1.1 常量的具体化
使用lui/addiw将立即数加载至寄存器,当立即数低12位的最高位为1时,需要特殊处理,提前补值0x800。
具体的推导过程见:https://zhuanlan.zhihu.com/p/374235855
1.2 有效使用x0寄存器
1)将目标寄存器置0
正确做法如下:
mv x10, x0
or
li x10, 0
不要使用下面方法,因为会有一个读寄存器x10额外的开销。
xor x10, x10, x10
and x10, x10, x0
andi x10, x10, 0
sub x10, x10, x10
2)善于将x0作为指令的源操作数
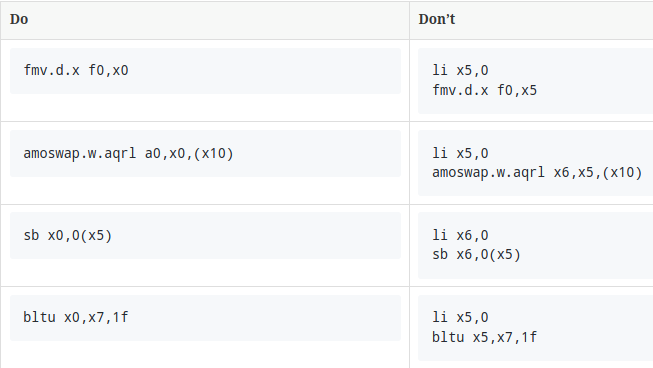
x0可以折叠到任何指令中作为源操作数(有些情况还可以用作目的操作数),所以避免使用额外指令将0先加载到寄存器中。 下表列出了可以通过谨慎使用 x0 来消除临时寄存器的情况。
1.3 有效利用指令的立即数域
尽量将范围符合立即数域编码的常量编码到立即数域,而不是通过额外的指令加载到寄存器再使用。
比如访问一个数组,a0存放的是数组基地址,8是offset。应该用:
ld t0, 8(a0)
而不是:
addi a1, a0, 8
ld t0, (a1)
这部分的扩展资料:https://www.bilibili.com/video/BV1pN411H7Y3
1.4 善于利用常量池
对64bit的立即数常量,使用常量池。如果该常量在程序中用到多次,收益则会更大。
将一个64bit的数加载至寄存器:
li a0, 0x123456789abcde1
其背后的逻辑可能是,要耗费32byte:
lui a0,0x92
addiw a0,a0,-1493
slli a0,a0,0xc
addi a0,a0,965
slli a0,a0,0xd
addi a0,a0,-1347
slli a0,a0,0xc
addi a0,a0,-543
如果我们使用常量池,常量可以在16个字节中加载,8个字节用于常量,8个字节用于加载它所需的指令。
1:
auipc a0, %pcrel_hi(large_constant)
ld a0, %pcrel_lo(1b)(a0)
...
.section .rodata
.p2align 3
large_constant:
.dword 0x123456789abcde1
1.5 使用典型的mov指令
使用汇编器 MV 助记符(可转换为 ADDI rd, rs1, 0)将值从一个寄存器复制到另一个寄存器。 例如使用:
mv x10, x11
优先于以下任何指令:
or x10, x11, x0
ori x10, x11, 0
xor x10, x11, x0
xori x10, x11, 0
1.6 使用条件mov代替分支指令
处理器进行分支预测的代价是很高的,一旦分支预测错误,就需要清空流水线,重新开始读取。通过把分支指令替换成条件move是编译器的常见优化,实际上是将控制流的依赖转换成数据流的依赖。而这种转换通常会用到zicond 扩展,也就是czero.eqz 和 czero.nez指令。
czero.eqz rd, rs1, rs2 // if rs2==0 then rd=rs1 else rd=0
czero.nez rd, rs1, rs2 // if rs2!=0 then rd=rs1 else rd=0
原始分支指令版本:
beqz a0, 1f
li a0, constant1
j 2f
1:
li a0, constant2
2:
初步优化后的指令版本:
li t2, constant1
li t3, (constant2 - constant1)
czero.nez t3, t3, a0
add a0, t3, t2
如果能确定constant1在12bit范围,还持续优化:
li t3, (constant2 - constant1)
czero.nez t3, t3, a0
addi a0, t3, constant1
如果没有zicond 扩展指令,还可以使用seqz和逻辑组合来达成条件move:
li t2, constant1
li t3, constant2
seqz t0, a0 // if a0==0 then t0=1 else t0=0
addi t0, t0, -1 // if t0==1 then t0置为全0 else t0置为全1
xor t1, t2, t3
and t1, t1, t0
xor a0, t1, t3 // if t1是全0 then result=t3 else result=t2
1.7 代码段的Padding
分支跳转的目标或者函数地址的起始能够Padding在一个Cache行的开头地址上,对于整个跳转来说都是比较好的操作。所以在编译一个函数时,会在其结束的时候进行Padding从而占满Cache行,或者在函数的开头Padding让其位于Cache行的开头地址。
- 函数之间对齐padding使用0 (illegal instruction)
- 函数内部对齐padding使用Nop或C.Nop
- 因为在函数内部的执行频率高,乱序执行情况下,流水线在遇见非法指令后可能就不执行后续指令了
- 而控制流如果传递到函数之间,极有可能是程序出错了,非法指令反而会帮助debug
1.8 将字符数组对齐到更大的对齐单位
如果CPU不支持快速非对齐访问,那么在连续访问字符数组(元素大小8bit)时,lw/sw指令从4字节边界访问,ld/sd从8字节边界访问,效率会高很多。
1.9 使用移位指令取出前导位和末尾位(leading/trailing bits)
如将x5的低12位取出:
slli x6, x5, 20
srli x7, x6, 20
而不是:
lui x6, 1
addi x7, x6, -1
and x8, x7, x5
二、标量浮点优化
2.1 与整数优化相似的部分
- 尽量使用尽可能短的代码序列实现同样的功能。
- 加载立即数0的折叠。
- 内存访问对齐。
2.2 高效控制舍入模式
为什么要舍入? 因为单精度浮点数只取23位尾数(除去隐藏位),而一些运算不可避免的得到的尾数会超过23位,因此需要考虑舍入。
RISC-V的浮点计算舍入模式有两种:静态模式和动态模式。
- 静态舍入模式:浮点指令的编码中有
3位作为舍入模式域,RISC-V架构支持如下五种合法的舍入模式。除此之外,如果舍入模式编码为101或者110,则为非法模式;如果舍入模式编码111,则意味着使用动态舍入模式。
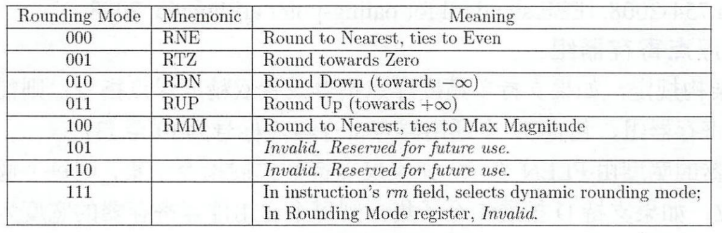
并不是所有的指令都有舍入模式,根据指令编码格式,以下的指令存在舍入模式的浮点运算指令:fadd fsub fmul fdiv fsqrt 浮点乘加指令:fmadd fmsub fnmadd fnmsub 浮点转换指令:fcvt.w.s fcvt.s.w fcvt.uw.s fcvt.s.uw - 动态舍入模式:如果使用动态舍入模式,则使用
fcsr寄存器中的舍入模式域。fcsr寄存器包含舍入模式域。不同的舍入模式编码同样如上图所示,仅支持五种合法的舍入模式。如果 fcsr 寄存器中的舍入模式域指定为非法的舍入模式,则后续浮点指令会产生非法指令异常。
浮点优化,尽可能使用静态模式:
fadd.s f10, f10, f11, rtz
而不是通过csr读写指令来设置FPCSR.FRM:
csrrwi t0, frm, 1 ; 1 = rtz
fadd.s f10, f10, f11
fsrm t0