前言
大家好,我是jiantaoyab,这是我作为学习笔记的第12篇,这篇文章主要讲超线程(Hyper-Threading)技术和单指令多数据流(SIMD)技术
超标量(Superscalar)技术能够让取指令以及指令译码也并行进行;在编译的过程,超长指令字(VLIW)技术可以搞定指令先后的依赖关系,使得一次可以取一个指令包
除了上面2个,还有能提升CPU性能架构的是超线程(Hyper-Threading)技术,以及单指令多数据流(SIMD)技术
超线程
当流水线很深的时候,我们需要解决冒险问题,而解决这些冒险问题,本质上都是一种指令级并行的方案,也就是说CPU 想要在同一个时间,去并行地执行两条指令。
而这两条指令呢,原本在我们的代码里,是有先后顺序的。无论是流水线架构、分支预测以及乱序执行,还是超标量和超长指令字,都是想要通过同一时间执行两条指令,来提升 CPU 的吞吐率。
什么是超线程技术呢?
既然 CPU 同时运行那些在代码层面有前后依赖关系的指令,会遇到各种冒险问题,不如去找一些和这些指令完全独立,没有依赖关系的指令来运行好了。
但是无论是多个 CPU 核心运行不同的程序,还是在单个 CPU 核心里面切换运行不同线程的任务,在同一时间点上,一个物理的 CPU 核心只会运行一个线程的指令,所以其实我们并没有真正地做到指令的并行运行。
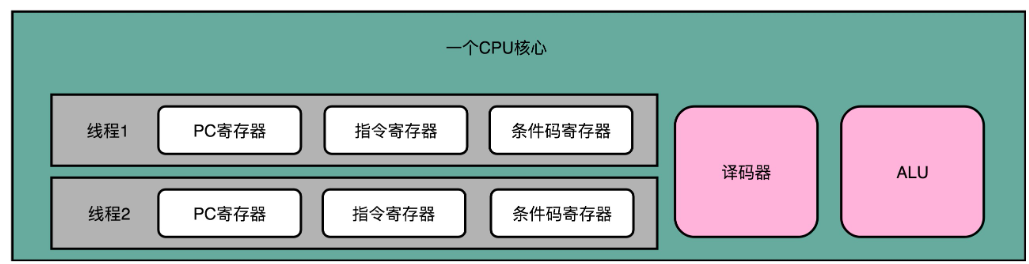
超线程可不是这样
超线程的 CPU,其实是把一个物理层面 CPU 核心,“伪装”成两个逻辑层面的 CPU 核心,使得 CPU 可以同时运行两个不同线程的指令。这个 CPU,会在硬件层面增加很多电路,使得我们可以在一个 CPU 核心内部,维护两个不同线程的指令的状态信息。
如,在一个物理 CPU 核心内部,会有双份的 PC 寄存器、指令寄存器乃至条件码寄存器。这样,这个 CPU 核心就可以维护两条并行的指令的状态。在外面看起来,似乎有两个逻辑层面的 CPU 在同时运行。所以,超线程技术一般也被叫作同时多线程(Simultaneous Multi-Threading,简称 SMT)技术**。**
不过,在 CPU 的其他功能组件上,Intel 可不会提供双份。无论是指令译码器还是 ALU,一个 CPU 核心仍然只有一份。因为超线程并不是真的去同时运行两个指令,那就真的变成物理多核了。超线程的目的,是在一个线程 A 的指令,在流水线里停顿的时候,让另外一个线程去执行指令。因为这个时候,CPU 的译码器和 ALU 就空出来了,那么另外一个线程 B,就可以拿来干自己需要的事情。这个线程 B 可没有对于线程 A 里面指令的关联和依赖。
这样,CPU 通过很小的代价,就能实现“同时”运行多个线程的效果。通常我们只要在 CPU 核心的添加 10% 左右的逻辑功能,增加可以忽略不计的晶体管数量,就能做到这一点。
超线程应用场景
超线程只在特定的应用场景下效果比较好。一般是在那些各个线程“等待”时间比较长的应用场景下。比如,我们需要应对很多请求的数据库应用,就很适合使用超线程。各个指令都要等待访问内存数据,但是并不需要做太多计算。于是,我们就可以利用好超线程。我们的 CPU 计算并没有跑满,但是往往当前的指令要停顿在流水线上,等待内存里面的数据返回。这个时候,让 CPU 里的各个功能单元,去处理另外一个数据库连接的查询请求就是一个很好的应用案例。
单指令多数据流
SIMD 技术,是一种“指令级并行”的加速方案,或者我们可以说,它是一种“数据并行”的加速方案。在处理向量计算的情况下,同一个向量的不同维度之间的计算是相互独立的。
而我们的 CPU 里的寄存器,又能放得下多条数据。
于是,我们可以一次性取出多条数据,交给 CPU 并行计算。
假如采用循环一步一步来计算的算法,一般被称为SISD,也就是单指令单数据(Single Instruction Single Data)的处理方式。如果你手头的是一个多核 CPU 呢,那么它同时处理多个指令的方式可以叫作MIMD,也就是多指令多数据(Multiple Instruction Multiple Dataa)。
$ python
>>> import numpy as np
>>> import timeit
>>> a = list(range(1000))
>>> b = np.array(range(1000))
>>> timeit.timeit("[i + 1 for i in a]", setup="from __main__ import a", number=1000000)
32.82800309999993
>>> timeit.timeit("np.add(1, b)", setup="from __main__ import np, b", number=1000000)
0.9787889999997788
>>>
为什么 SIMD 指令能快那么多呢?
SIMD 在获取数据和执行指令的时候,都做到了并行。
一方面,在从内存里面读取数据的时候,SIMD 是一次性读取多个数据。
数组里面的每一项都是一个 integer,也就是需要 4 Bytes 的内存空间。Intel 在引入 SSE 指令集的时候,在 CPU 里面添上了 8 个 128 Bits 的寄存器。128 Bits 也就是 16 Bytes ,也就是说,一个寄存器一次性可以加载 4 个整数。比起循环分别读取 4 次对应的数据,时间就省下来了。
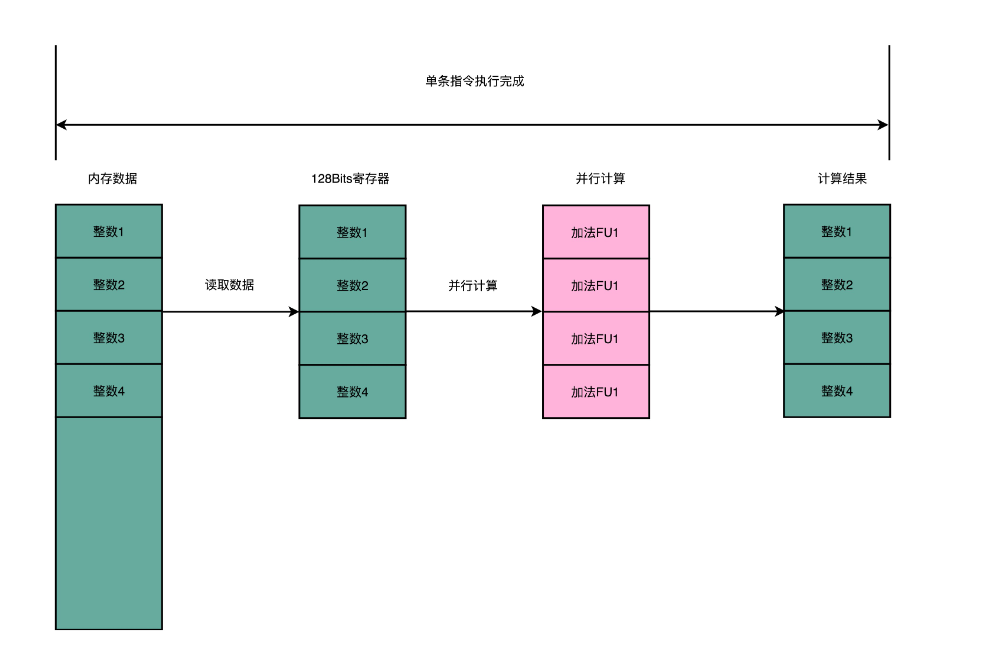
在数据读取到了之后,在指令的执行层面,SIMD 也是可以并行进行的。4 个整数各自加 1,互相之前完全没有依赖,也就没有冒险问题需要处理。只要 CPU 里有足够多的功能单元,能够同时进行这些计算,这个加法就是 4 路同时并行的,自然也省下了时间。
对于那些在计算层面存在大量“数据并行”(Data Parallelism)的计算中,使用 SIMD 是一个很划算的办法。在这个大量的“数据并行”,其实通常就是实践当中的向量运算或者矩阵运算。在实际的程序开发过程中,过去通常是在进行图片、视频、音频的处理。最近则通常是在进行各种机器学习算法的计算。























![中间件 | RabbitMq - [AMQP 模型]](https://img-blog.csdnimg.cn/direct/01c09f995c1a4d17a8e384fbc40200da.png)