文章介绍
Qualcomm® AI Hub能够帮助开发者能够快速的针对AI模型进行验证,优化以及部署到设备端。通过Qualcomm AI Hub上的Profile任务能够收集到在AI模型再不同的物理设备上运行所需的资源,基于这些关键指标,可以判断出目标的机器是否能够提供AI模型运行需要资源,目前机器的推理时间是否能够达标。本文主要介绍Qualcomm AI Hub的Profile任务收集的关键指标,以及这些指标的意义。
概述
Profile的任务主要收集目标模型四个不同时间段所需要的资源。
- 模型编译时Compilation – 模型在物理设备上编译时候所需要的相关资源。
- 模型第一次加载时(First App Load ),操作系统可能会进一步运行时优化,这些优化针对执行模型推理的硬件平台。例如,Qualcomm® Hexagon™ Processor的神经网络处理器(NPU),模型第一次加载时候会对模型做预处理和缓存,为下来的模型推理准备。
- 模型后续加载时(Subsequent App Load) ,从第二次以及后续模型加载,利用之前缓存优化过的模型,可以减少硬件开销。
- 模型推理时Inference – 模型加载完成后,Hub执行推理。Profiling 任务准备随机数据,并在一个紧密的循环中多次执行模型推理。
如下图所示,这个Yolov8在Snapdragon® 8 Gen 2 | SM8550上Profiling的结果
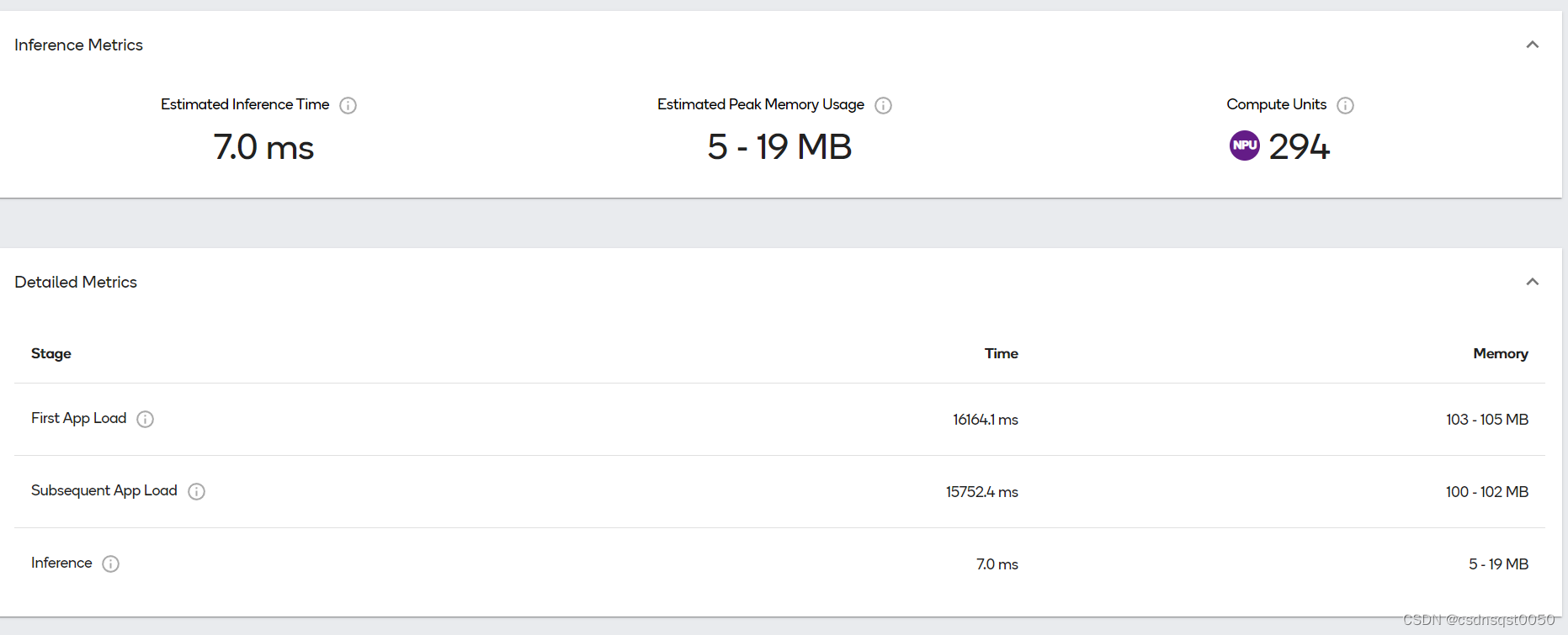
如上图所示,每一个阶段的Profiling有两个关键的指标Time和Memory 下来阐述下这两个指标的意义。
Time 耗时
- First App Load-Time 模型首次加载完成后的时间
- Subsequent App Load 模型多次迭代加载过程所需的时间,成本仅包括对推理框架的调用成本和少量开销
- Inference-Time 推理时间是纯推理耗时。每个只生成一次输入,并在多次迭代中重复使用。Hub记录观察到的最短时间
Memory 内存
有很多方法可以描述应用程序的内存使用情况。然而,大多数开发人员从操作系统的角度解读他们的应用程序的内存时候。这决定了应用程序是被kill掉还是被要求回收内存。Hub提供的是内存使用区间而不是单个数字,为什么我们认为提供内存区间比单个数字更有指标的意义呢?
参考我们的文档How it works — qai-hub documentation 里面阐述了虚拟内存基本工作原理,这也是为什么我们认为统计内存使用范围更有意义
Peak vs Increase
用于完成任务的内存通常会超过结果的大小。考虑一个场景,我们正在编译一个模型;假设编译器中没有内存泄漏,将设备上的模型转换为已编译的模型将需要一定的内存,从而在磁盘上留下工件,而在内存中没有对象。如果编译器占用了40 MB,我们可以说它的峰值(Peak)使用量是40 MB,但内存使用量的稳态增长(Increase)是0字节。

表1:大型CNN模型的内存指标。
Stage |
Peak |
Increase |
Compilation |
162.7 - 163.4 MB |
0.0 - 0.7 MB |
First App Load |
1.7 - 2.8 MB |
0.6 - 1.7 MB |
Subsequent App Load |
1.8 - 2.5 MB |
0.8 - 1.6 MB |
Inference |
629.6 - 630.6 MB |
378.7 - 379.6 MB |
所以在Profiling结果中,我们展示了峰值范围,它突出了您的模型对内存压力的最重要贡献,内存压力可能会导致操作系统终止您的应用程序。我们的AI-Hub 的Python客户端库中提供了这些和所有其他度量。完整的内存和时序度量如表2所示。
表2:ProfileJob.download_profile的结果execution_summary中返回的度量。
Key |
Type |
Units |
compile_memory_increase_range |
(int, int) |
Bytes |
compile_memory_peak_range |
(int, int) |
Bytes |
first_load_memory_increase_range |
(int, int) |
Bytes |
first_load_memory_peak_range |
(int, int) |
Bytes |
warm_load_memory_increase_range |
(int, int) |
Bytes |
warm_load_memory_peak_range |
(int, int) |
Bytes |
inference_memory_increase_range |
(int, int) |
Bytes |
inference_memory_peak_range |
(int, int) |
Bytes |
compile_time |
int |
Microseconds |
first_load_time |
int |
Microseconds |
warm_load_time |
int |
Microseconds |
estimated_inference_time |
int |
Microseconds |
作者:高通工程师,戴忠忠(Zhongzhong Dai)