图像识别三大任务
- 目标识别:或者说分类,定性目标,确定目标是什么
- 目标检测:定位目标,确定目标是什么以及位置
- 目标分割:像素级的对前景与背景进行分类,将背景剔除
目标检测定义
识别图片中有哪些物体以及物体的位置
目标检测中能检测出来的物体取决于当前任务(数据集)需要检测的物体有哪些。
目标检测的位置信息一般由两种格式:
- 极坐标表示:(xmin, ymin, xmax, ymax)
- xmin,ymin:x,y坐标的最小值
- xmin,ymin:x,y坐标的最大值
- 中心点坐标:(x_center, y_center, w, h)
- x_center, y_center:目标检测框的中心点坐标
- w,h:目标检测框的宽、高
应用:
- 道路检测
动物检测
商品检测
车牌检测
菜品检测
- 车型检测
虚拟环境安装
pip3 install virtualenv配置参数
export WORKON_HOME=$HOME/virtualenv
source /usr/local/bin/virtualenvwrapper.sh新建虚拟环境
mkvirtualenv + -p /user/bin/python(python版本所在位置) + test(虚拟环境名称)进入虚拟环境
workon test安装环境包
pip install -r requirements.txt目标检测算法分类:
两步走的目标检测:先进行区域推荐,而后进行目标分类
- 代表:R-CNN、SPP-net、Fast R-CNN、Faster R-CNN
端到端的目标检测:采用一个网络一步到位
- 代表:YOLO、SSD
输入一张图片,经过其中卷积、激活、池化相关层,最后加入全连接层达到分类概率的效果
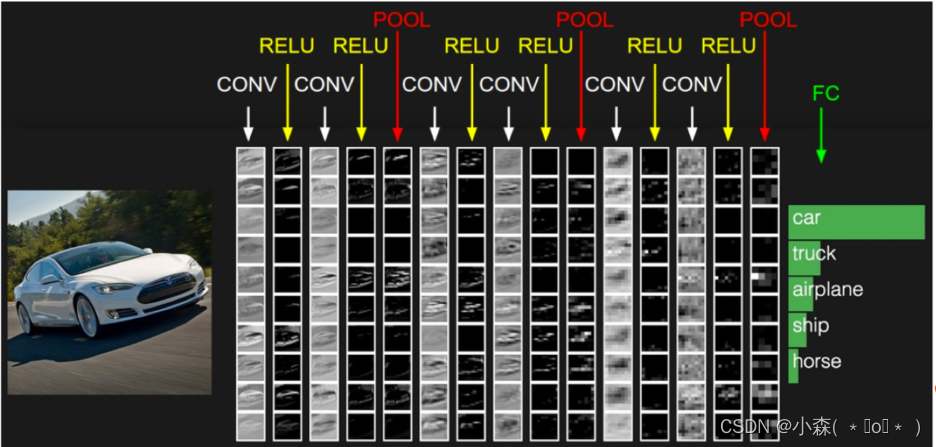
- 分类的损失与优化
在训练的时候需要计算每个样本的损失,那么CNN做分类的时候使用softmax函数计算结果,损失为交叉熵损失

- 常见CNN模型

检测的任务:
- 分类:
- N个类别
- 输入:图片
- 输出:类别标签
- 评估指标:Accuracy

- 定位:
- N个类别
- 输入:图片
- 输出:物体的位置坐标
- 主要评估指标:IOU

(x,y,w,h)有一个专业的名词,叫做bounding box。
在目标检测当中,对bbox主要由两种类别。
- Ground-truth bounding box:图片当中真实标记的框
- Predicted bounding box:预测的时候标记的框

检测的评价指标
| 任务 | description | 输入 | 输出 | 评价标准 |
|---|---|---|---|---|
| 检测和定位 | 在输入图片中找出存在的物体类别和位置 | 图片 | 类别标签(categories)和 位置(bbox(x,y,w,h)) | IoU (Intersection over Union) mAP |
定位的简单实现
增加一个全连接层,即为FC1、FC2
FC1:作为类别的输出
FC2:作为这个物体位置数值的输出

假设有10个类别,输出[p1,p2,p3,...,p10],然后输出这一个对象的四个位置信息[x,y,w,h]。
- 对于分类的概率,还是使用交叉熵损失
- 位置信息具体的数值,可使用MSE均方误差损失(L2损失)
对于输出的位置信息是四个比较大的像素大小值,在回归的时候不适合。目前统一的做法是,每个位置除以图片本身像素大小。
R-CNN网络
Overfeat模型
Overfeat方法使用滑动窗口进行目标检测,也就是使用滑动窗口和神经网络来检测目标。滑动窗口使用固定宽度和高度的矩形区域,在图像上“滑动”,并将扫描结果送入到神经网络中进行分类和回归。
- 例如要检测汽车,就使用下图中红色滑动窗口进行扫描,将所有的扫描结果送入网络中进行分类和回归,得到最终的汽车的检测结果。这种方法类似一种暴力穷举的方式,会消耗大量的计算力,并且由于窗口大小问题可能会造成效果不准确。
RCNN模型
RCNN模型是一种结合了候选区域(Region Proposal)方法和卷积神经网络(CNN)的目标检测模型。
- 候选区域(Region Proposal):这部分的作用是确定图像中可能包含目标物体的区域,即解决定位问题。定位可以通过多种方法实现,例如暴力取框,即使用各种大小的框来遍历整张图片,或者看作一个回归问题,通过预测(x, y, w, h)四个参数的值来确定方框的位置。
- 卷积神经网络(CNN):CNN用于识别候选区域内的内容,即解决识别问题。通过训练一个CNN来识别图像中的物体,并对其进行分类。

- 使用选择性搜索(Selective Search)的方法找出图片中可能存在目标的侯选区域。
- 选取预训练卷积神经网网络用于进行特征提取。
- 训练支持向量机(SVM)来辨别目标物体和背景,对每个类别,都要训练一个二元SVM。
- 训练一个线性回归模型,为每个辨识到的物体生成更精确的边界框。
CNN网络提取特征
采用预训练模型在生成的候选区域上进行特征提取,将提取好的特征保存在磁盘中,用于后续步骤的分类和回归。
目标分类(SVM)
假设我们要检测猫狗两个类别,那我们需要训练猫和狗两个不同类别的SVM分类器,然后使用训练好的分类器对一幅图像中2000个候选区域的特征向量分别判断一次,这样得出[2000, 2]的得分矩阵。
对于N个类别的检测任务,需要训练N(目标类别数目)个SVM分类器。
目标定位
通过训练一个回归器来对候选区域的范围进行一个调整,这些候选区域最开始只是用选择性搜索的方法粗略得到的,通过调整之后得到更精确的位置。
使用选择性搜索的方法从一张图片中提取2000个候选区域,将每个区域送入CNN网络中进行特征提取,然后送入到SVM中进行分类,并使用候选框回归器,计算出每个候选区域的位置。 候选区域较多,有2000个,需要剔除掉部分检测结果。 针对每个类,通过计算IOU,采取非最大值抑制NMS的方法,保留比较好的检测结果。