提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
1.聚合(aggregations)
- 聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值max、平均值avg等等。
基本概念
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫 桶,一个叫 度量:
桶(bucket)

度量(metrics)

案例 1
1. 接下来按price字段进行分组:
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"aggs":{//聚合操作
"price_group":{//名称,随意起名
"terms":{//分组
"field":"price"//分组字段
}
}
}
}
返回结果如下:
{
"took": 63,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 1,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 1,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 1,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
},
"aggregations": {
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 1999,
"doc_count": 5
},
{
"key": 3999,
"doc_count": 1
}
]
}
}
}
上面返回结果会附带原始数据的。若不想要不附带原始数据的结果, 设置"size":0,
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下
{
"aggs":{
"price_group":{
"terms":{
"field":"price"
}
}
},
"size":0
}
返回结果如下:
{
"took": 60,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 1999,
"doc_count": 5
},
{
"key": 3999,
"doc_count": 1
}
]
}
}
}
2. 若想对所有手机价格求平均值。
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"aggs":{
"price_avg":{//名称,随意起名
"avg":{//求平均
"field":"price"
}
}
},
"size":0
}
返回结果如下:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"price_avg": {
"value": 2332.3333333333335
}
}
}
案例 2
1. 搜索address中包含mill的所有人的年龄分布以及平均年龄
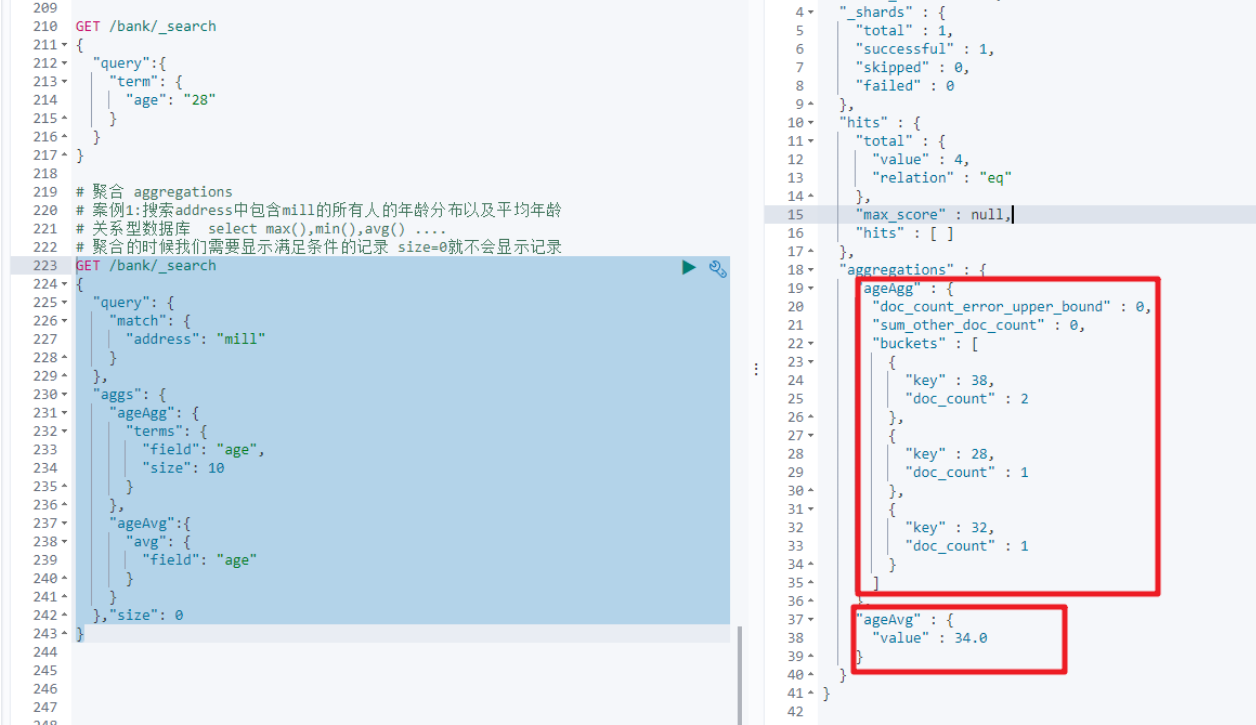
2. 按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
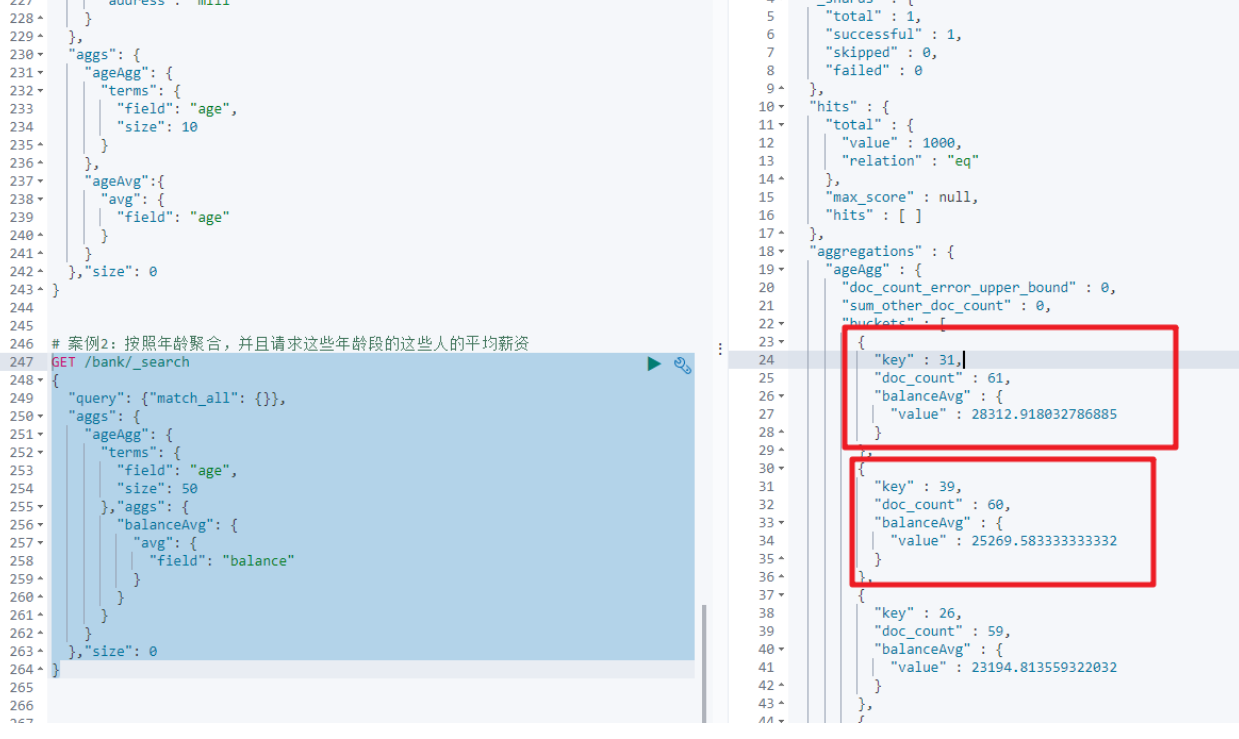
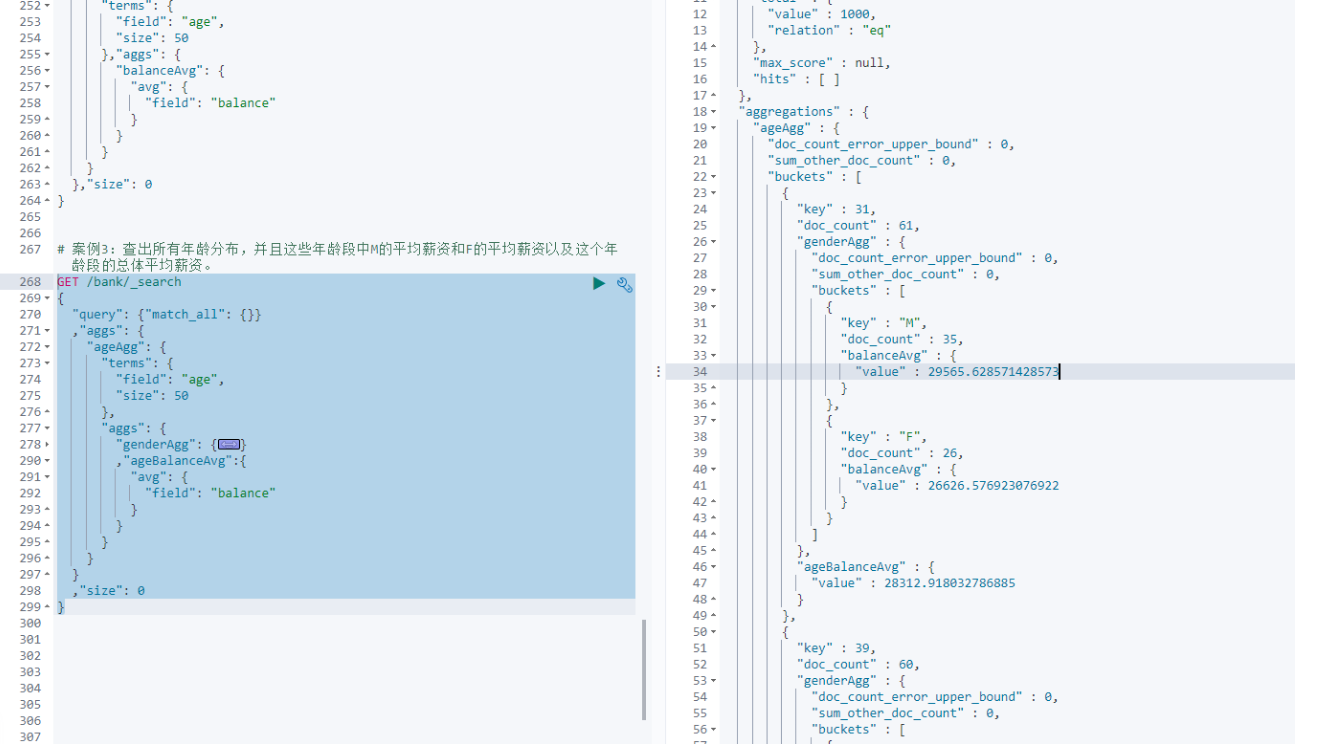
3. 查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资
2.映射配置(_mapping)
ElasticSearch7-去掉type概念:
Elasticsearch 7.x
- URL中的type参数为可选。比如,索引一个文档不再要求提供文档类型。
Elasticsearch 8.x
不再支持URL中的type参数。
解决:将索引从多类型迁移到单类型,每种类型文档一个独立索引

2.1 什么是映射?
有了索引库,等于有了数据库中的 database。接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。
- 创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)
映射是定义文档的过程,文档包含哪些字段,这些字段是否保存,是否索引,是否分词等
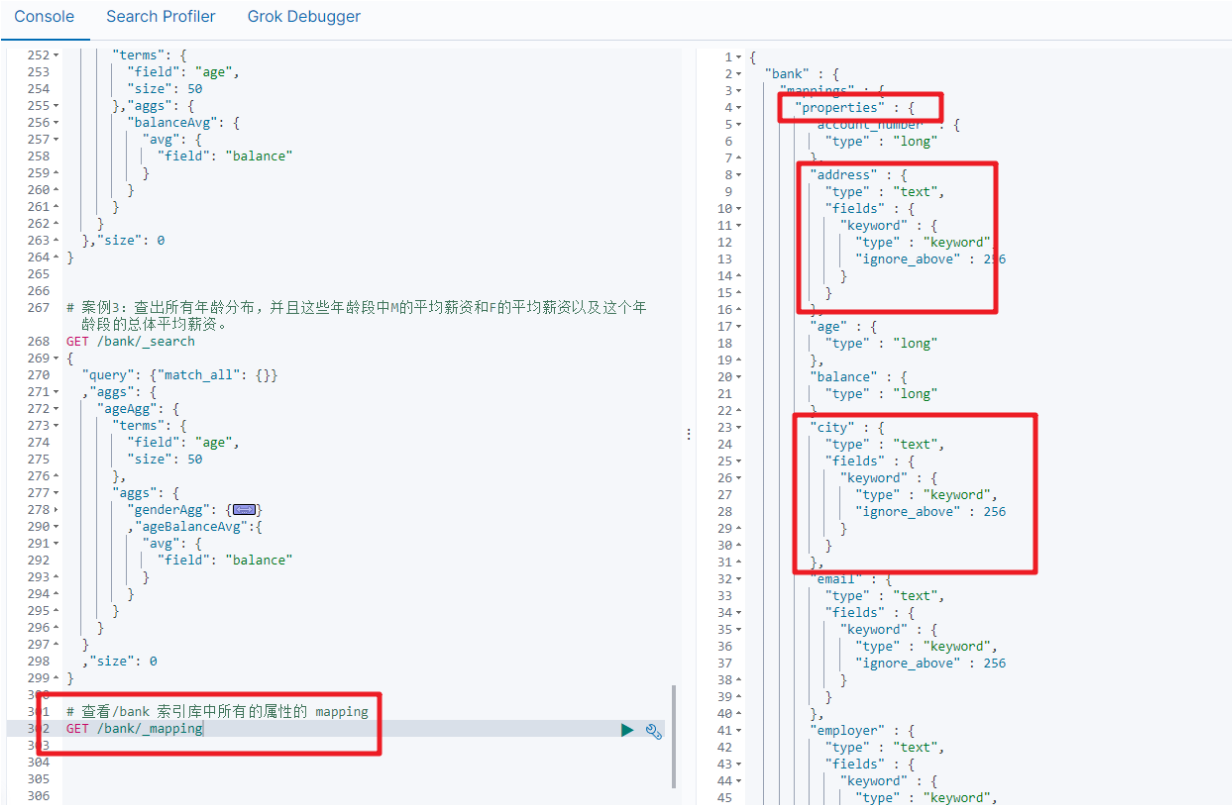
2.2 查看索引库中所有的属性的_mapping
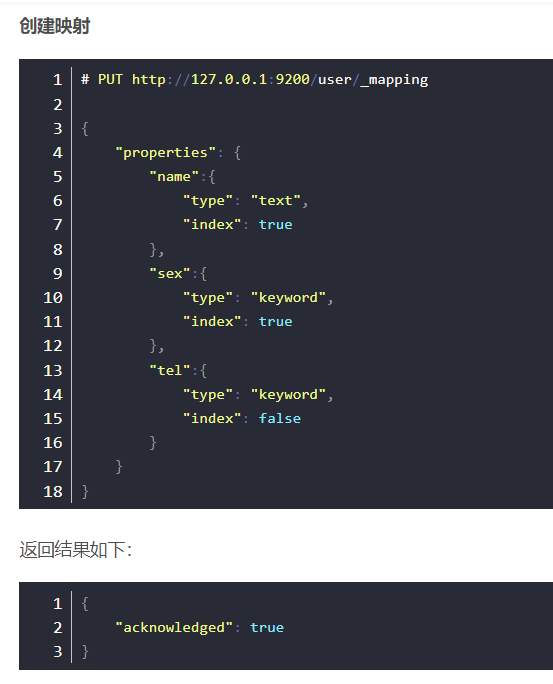
2.3 创建映射字段

类型名称:就是前面将的type的概念,类似于数据库中的不同表
字段名:类似于列名,properties下可以指定许多字段。
每个字段可以有很多属性。例如:
- type:类型,可以是text、long、short、date、integer、object等
- index:是否索引,默认为true
- store:是否存储,默认为false
- analyzer:分词器,这里使用ik分词器:
ik_max_word或者ik_smart
新增映射字段
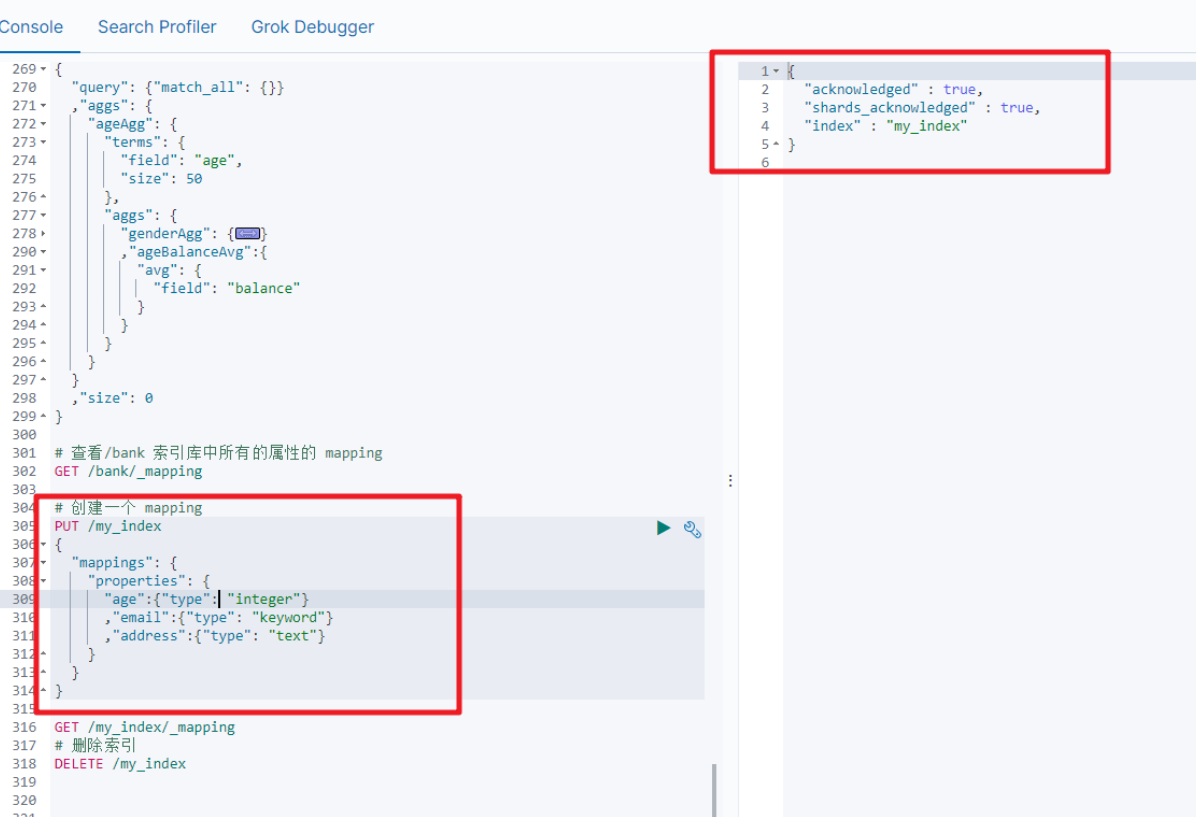
如果我们创建完成索引的映射关系后,又要添加新的字段的映射,这时怎么办?第一个就是先删除索引,然后调整后再新建索引映射,还有一个方式就在已有的基础上新增。
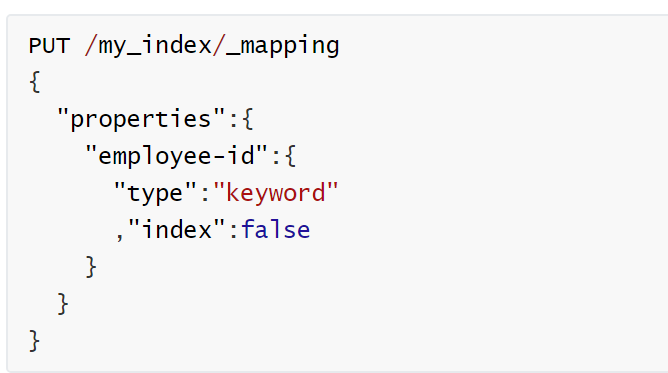
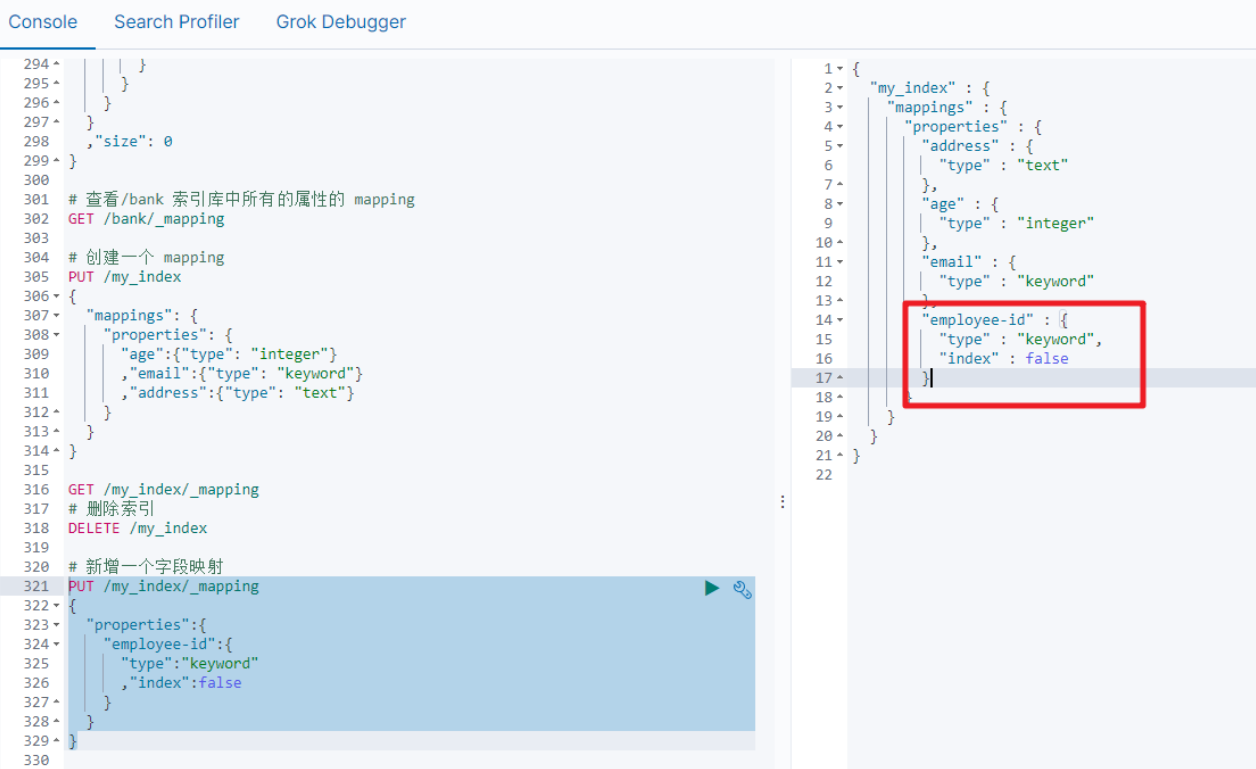
2.4 更新映射
- 对于存在的映射字段,我们不能更新,更新必须创建新的索引进行数据迁移
2.5 数据迁移
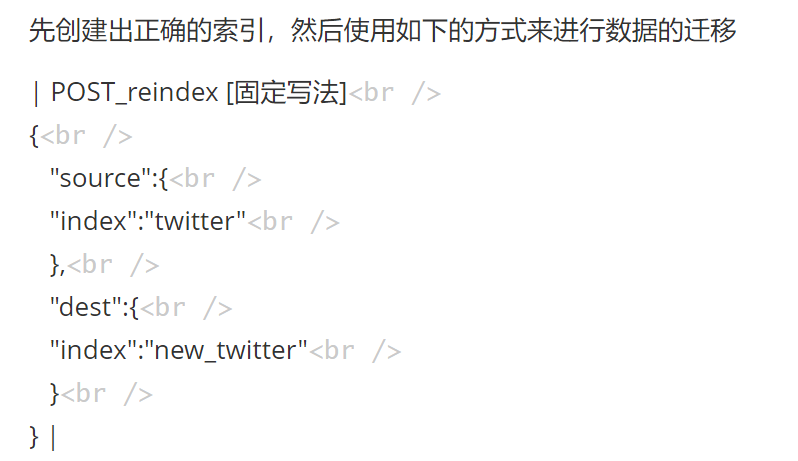
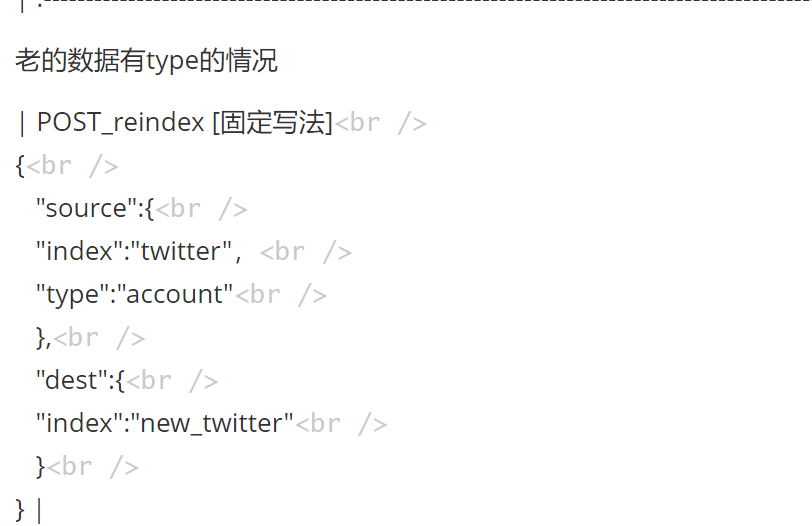
案例:新创建了索引,并指定了映射属性
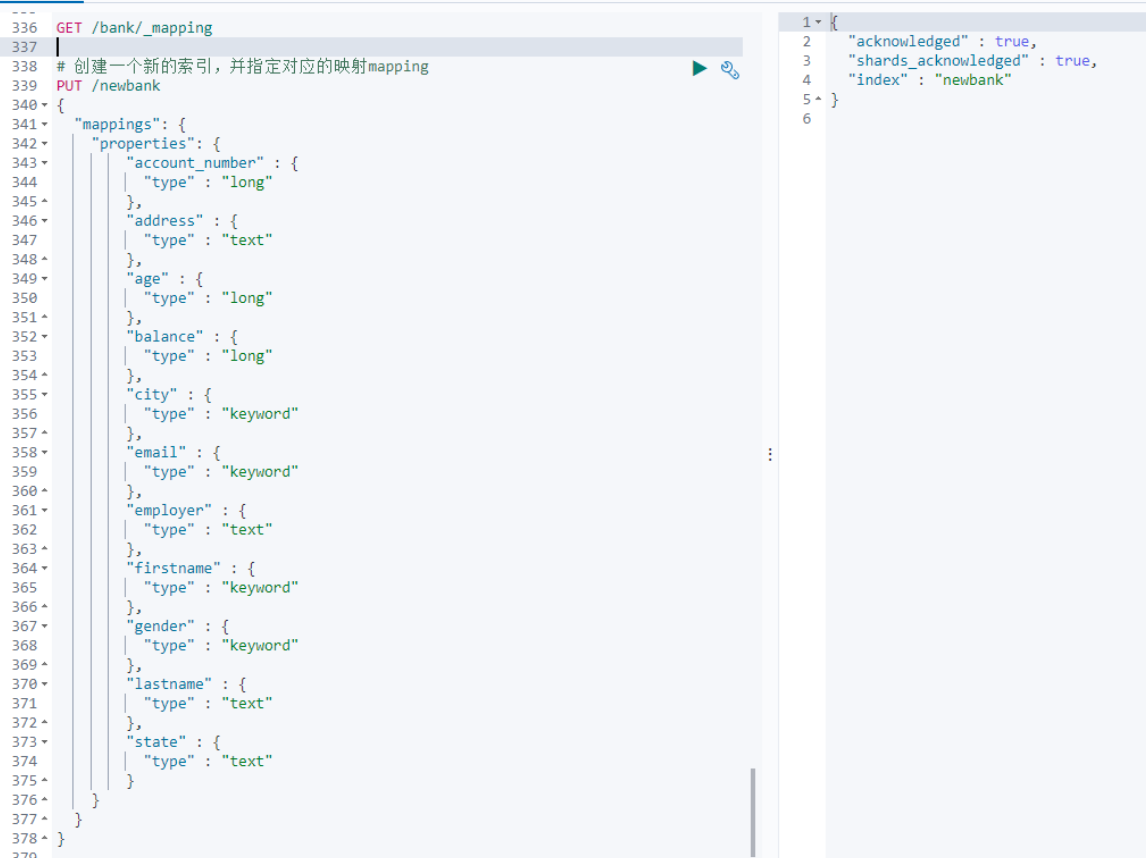
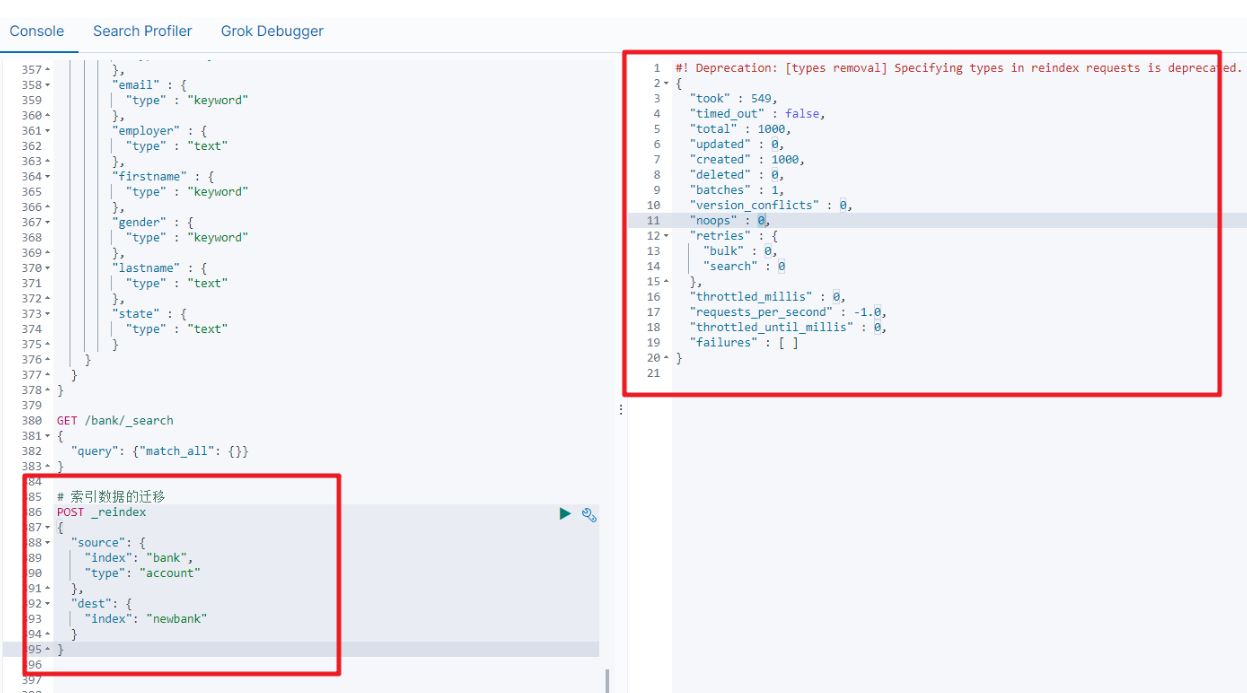
2.6 映射案例
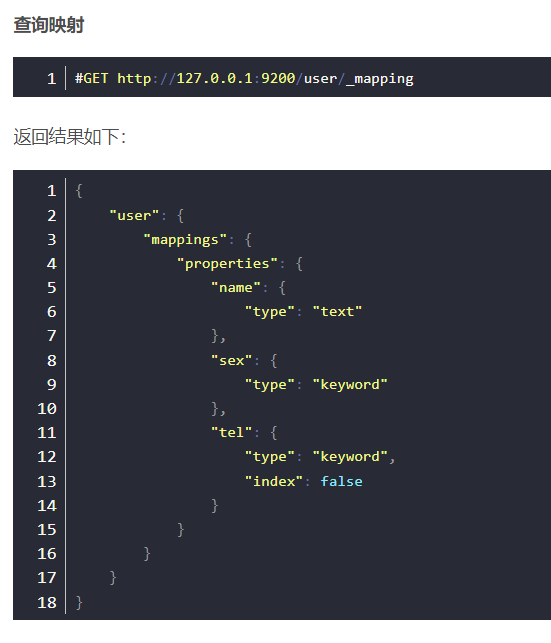
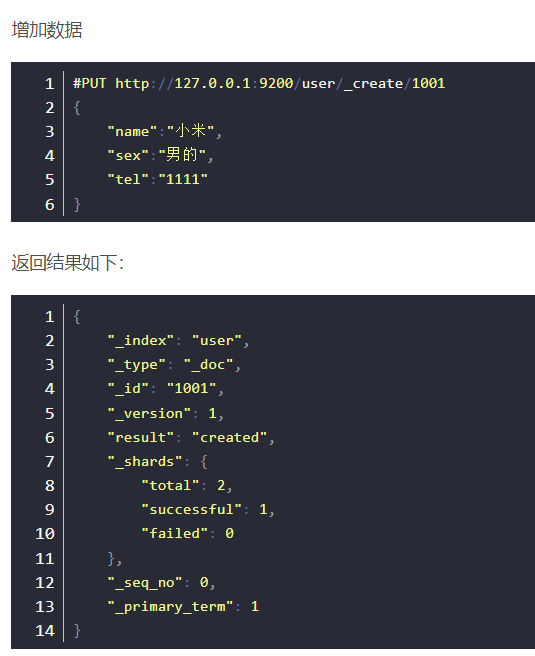
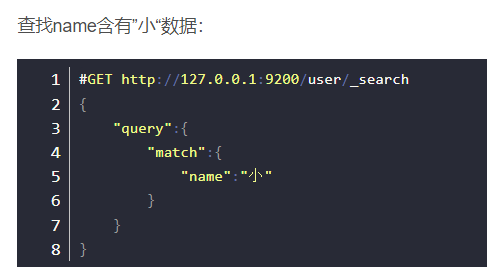
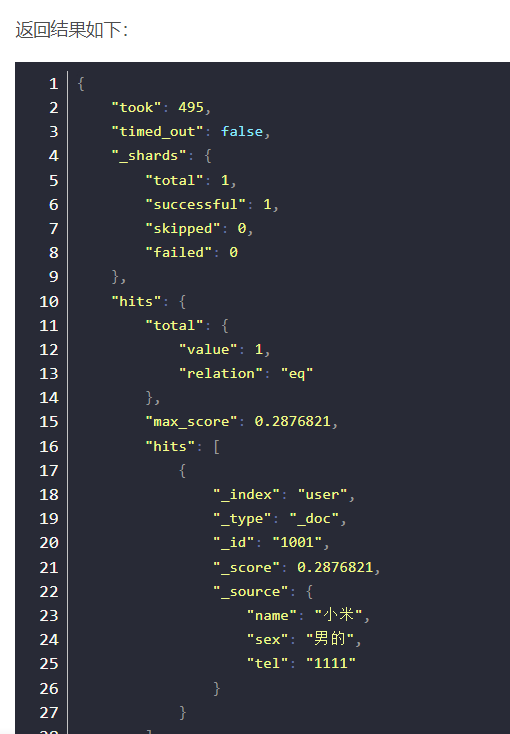
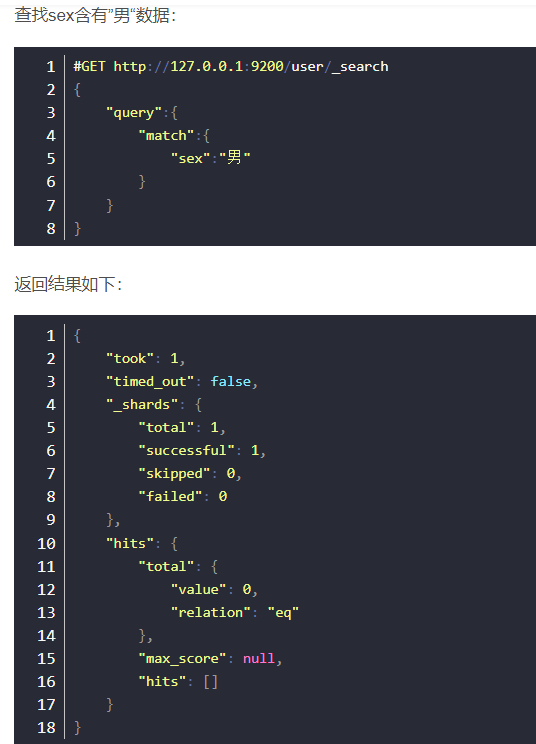
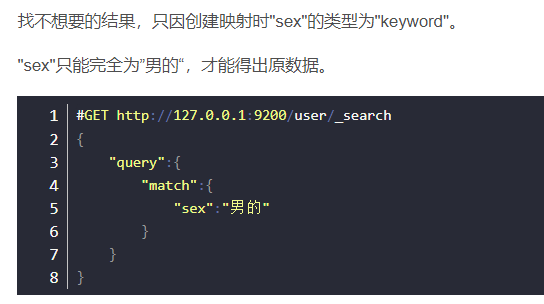
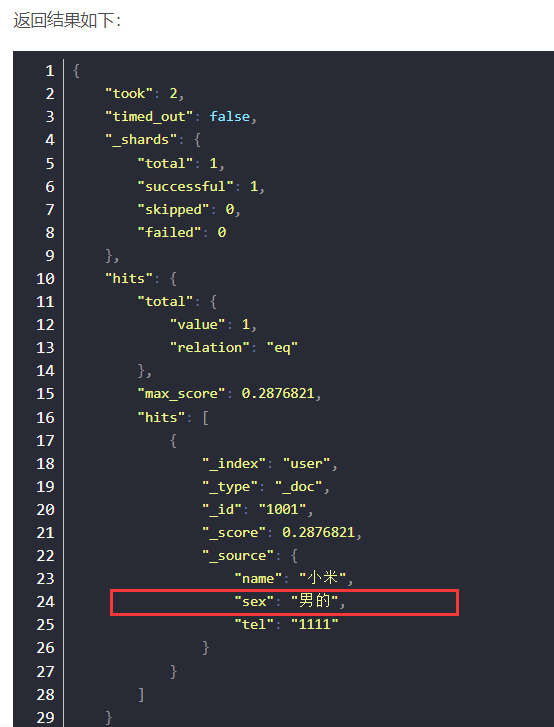
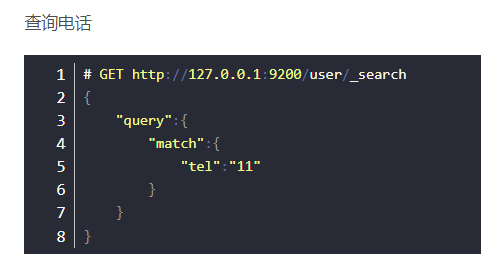
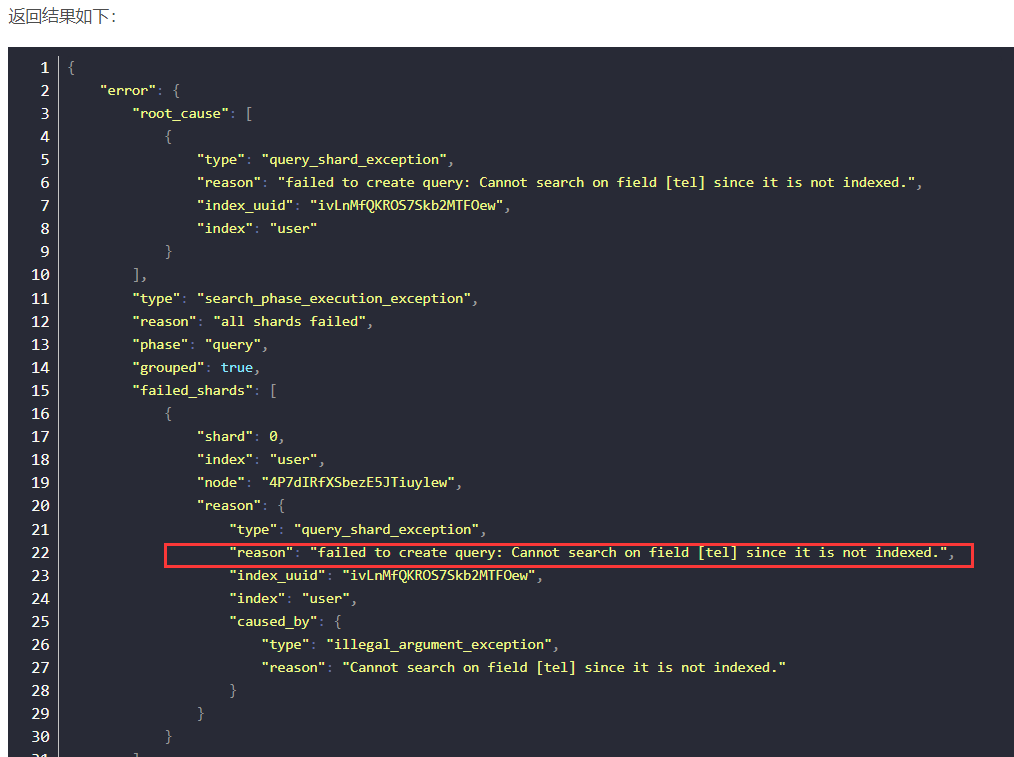
报错只因创建映射时"tel"的"index"为false。