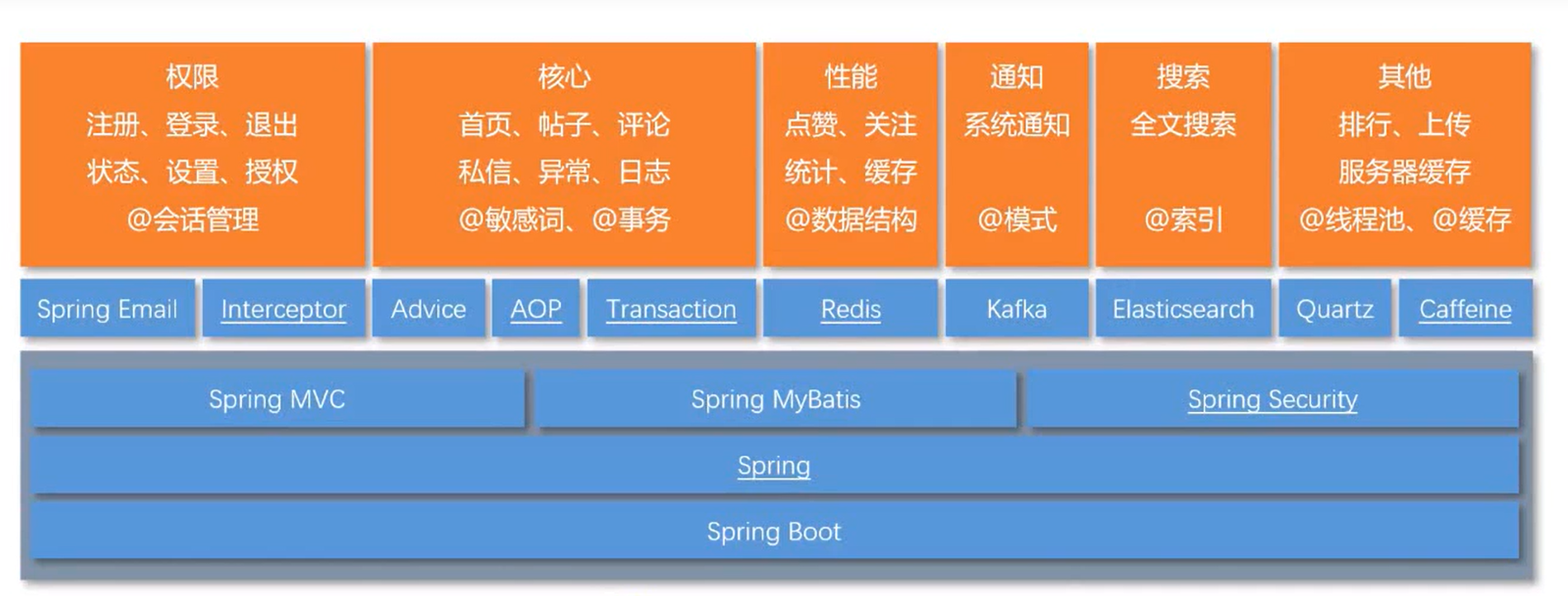
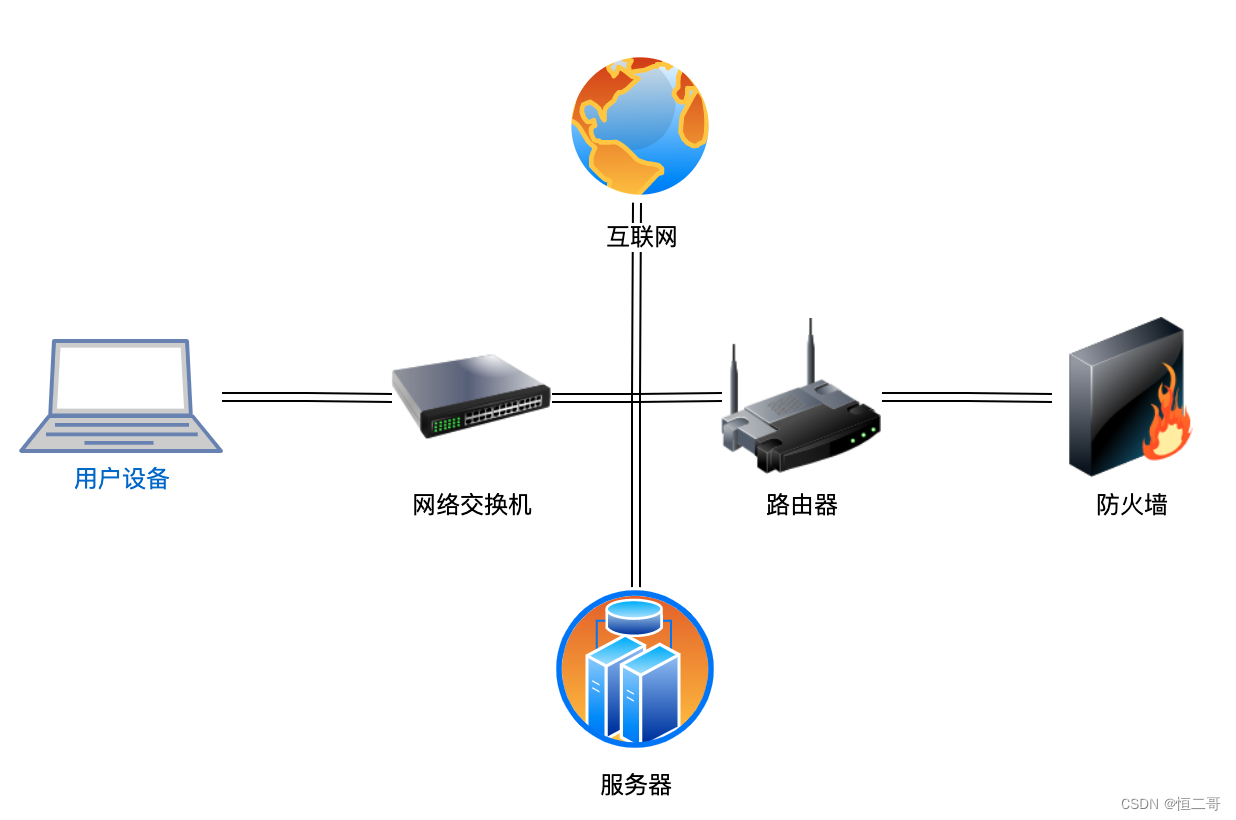
1.什么是ElasticSearch分布式搜索引擎?
Elasticsearch是一个开源的分布式搜索引擎,提供实时的、高可用性的搜索和分析解决方案。它支持快速索引和搜索大规模数据,具有分布式架构、RESTful API、基于JSON的查询语言等功能,适用于各种应用场景,如全文搜索。
比如说现在,我拥有一个电子商务网站,然后我需要一个搜索引擎来让用户能够快速地搜索和找到他们感兴趣的商品。这时候,我就可以使用Elasticsearch作为你的分布式搜索引擎。
假设现在我的电子商务网站有几百万个商品,并且我希望用户可以根据商品的名称、描述、价格、品牌等信息进行搜索。
首先,我会使用Elasticsearch的API将商品数据索引到Elasticsearch集群中。每个商品将被表示为一个文档,包含属性如商品名称、描述、价格等。
当用户在我的网站上进行搜索时,我就可以使用Elasticsearch的搜索API发送一个搜索请求。比如,用户搜索关键词"手机"。
Elasticsearch将会在索引中查找包含关键词"手机"的所有文档,并返回匹配的结果。
2.项目中的搜索功能实现

在Dao层中新建Elasticsearch文件,添加Elasticsearch接口,用于连接数据库(只需要继承接口即可)。
@Repository
public interface DiscussPostRepository extends ElasticsearchRepository<DiscussPost, Integer> {
}上面的代码其实是用Elasticsearch创建一个帖子的仓库接口,以便在应用程序中访问和操作Elasticsearch中的帖子数据。这个相对而言比较简单。

service层写一个ElasticsearchService文件。
@Service
public class ElasticsearchService {
@Autowired
private DiscussPostRepository discussRepository;
@Autowired
private ElasticsearchTemplate elasticTemplate;
public void saveDiscussPost(DiscussPost post) {
discussRepository.save(post);
}
public void deleteDiscussPost(int id) {
discussRepository.deleteById(id);
}
public Page<DiscussPost> searchDiscussPost(String keyword, int current, int limit) {
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery(keyword, "title", "content"))
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))
.withPageable(PageRequest.of(current, limit))
.withHighlightFields(
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")
).build();
return elasticTemplate.queryForPage(searchQuery, DiscussPost.class, new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> aClass, Pageable pageable) {
SearchHits hits = response.getHits();
if (hits.getTotalHits() <= 0) {
return null;
}
List<DiscussPost> list = new ArrayList<>();
for (SearchHit hit : hits) {
DiscussPost post = new DiscussPost();
String id = hit.getSourceAsMap().get("id").toString();
post.setId(Integer.valueOf(id));
String userId = hit.getSourceAsMap().get("userId").toString();
post.setUserId(Integer.valueOf(userId));
String title = hit.getSourceAsMap().get("title").toString();
post.setTitle(title);
String content = hit.getSourceAsMap().get("content").toString();
post.setContent(content);
String status = hit.getSourceAsMap().get("status").toString();
post.setStatus(Integer.valueOf(status));
String createTime = hit.getSourceAsMap().get("createTime").toString();
post.setCreateTime(new Date(Long.valueOf(createTime)));
String commentCount = hit.getSourceAsMap().get("commentCount").toString();
post.setCommentCount(Integer.valueOf(commentCount));
// 处理高亮显示的结果
HighlightField titleField = hit.getHighlightFields().get("title");
if (titleField != null) {
post.setTitle(titleField.getFragments()[0].toString());
}
HighlightField contentField = hit.getHighlightFields().get("content");
if (contentField != null) {
post.setContent(contentField.getFragments()[0].toString());
}
list.add(post);
}
return new AggregatedPageImpl(list, pageable,
hits.getTotalHits(), response.getAggregations(), response.getScrollId(), hits.getMaxScore());
}
});
}
}上述代码展示了一个名为 ElasticsearchService 的服务类,它提供了以下功能:
saveDiscussPost方法用于将帖子数据保存到 Elasticsearch 中。它接收一个DiscussPost对象作为参数,并调用discussRepository的save方法将数据保存到 Elasticsearch 中。deleteDiscussPost方法用于从 Elasticsearch 中删除指定 ID 的数据。它接收一个整数类型的 ID 参数,并调用discussRepository的deleteById方法来删除数据。searchDiscussPost方法用于在 Elasticsearch 中搜索帖子数据。它接收关键字、当前页码和每页显示数量作为参数,并执行一个复杂的搜索查询。将查询结果封装成一个Page<DiscussPost>对象返回。
上面说了很多,其实你只要知道这段代码作用就是这样的,ElasticsearchService 提供了对 Elasticsearch 中讨论帖子数据的保存、删除和搜索功能。它充分利用了 Spring Data Elasticsearch 和 ElasticsearchTemplate 提供的功能和方法,简化了与 Elasticsearch 的交互和操作。该服务类可以被其他组件或业务逻辑调用,以实现对 Elasticsearch 数据的管理和检索。
在Controller层写一个SearchController文件。
@Controller
public class SearchController implements CommunityConstant {
@Autowired
private ElasticsearchService elasticsearchService;
@Autowired
private UserService userService;
@Autowired
private LikeService likeService;
// search?keyword=xxx
@RequestMapping(path = "/search", method = RequestMethod.GET)
public String search(String keyword, Page page, Model model) {
// 搜索帖子
org.springframework.data.domain.Page<DiscussPost> searchResult =
elasticsearchService.searchDiscussPost(keyword, page.getCurrent() - 1, page.getLimit());
// 聚合数据
List<Map<String, Object>> discussPosts = new ArrayList<>();
if (searchResult != null) {
for (DiscussPost post : searchResult) {
Map<String, Object> map = new HashMap<>();
// 帖子
map.put("post", post);
// 作者
map.put("user", userService.findUserById(post.getUserId()));
// 点赞数量
map.put("likeCount", likeService.findEntityLikeCount(ENTITY_TYPE_POST, post.getId()));
discussPosts.add(map);
}
}
model.addAttribute("discussPosts", discussPosts);
model.addAttribute("keyword", keyword);
// 分页信息
page.setPath("/search?keyword=" + keyword);
page.setRows(searchResult == null ? 0 : (int) searchResult.getTotalElements());
return "/site/search";
}
}这段代码的作用是展示了一个名为 SearchController 的控制器类,用于处理搜索功能的请求。
接收用户输入的关键字
keyword、分页信息page和模型对象model。调用
elasticsearchService的searchDiscussPost方法,传递关键字、当前页码和每页显示数量,以执行搜索操作。将搜索结果
searchResult中的每个帖子,以及帖子的作者和点赞数量等信息,存储在discussPosts列表中的Map对象中。将
discussPosts、关键字keyword和分页信息page添加到模型对象model中,以便在视图中进行展示。
看了这么多,反正你要知道的就是SearchController 控制器类负责接收用户的搜索请求,调用 ElasticsearchService 执行搜索操作,获取搜索结果,并将结果和相关信息传递给视图进行展示。通过这个控制器类,用户可以在前端页面输入关键字进行搜索,然后获取搜索结果并在页面上显示。