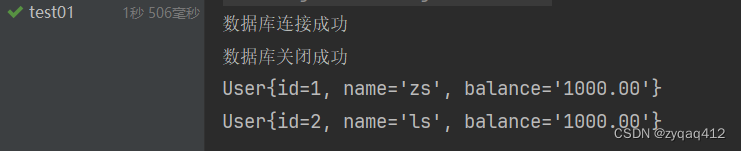
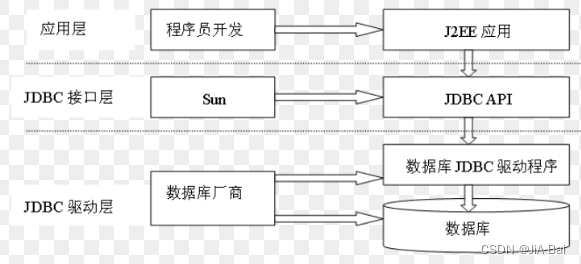
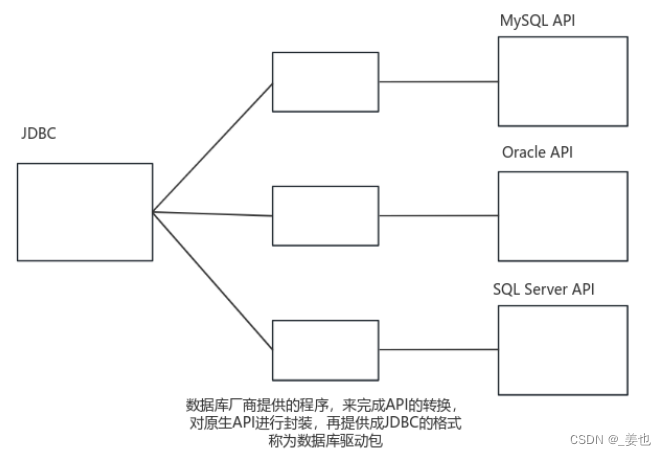
一.驱动加载和核心原理
在数据库编程中,驱动加载是一个关键的步骤,它使得应用程序能够与数据库进行交互。不同的数据库管理系统(DBMS)有其各自的驱动,这些驱动通常作为库文件或插件提供,用于实现应用程序与数据库之间的通信。
驱动加载的过程
- 获取驱动:应用程序首先需要获取数据库驱动。这通常通过加载特定的库文件或插件来完成。例如,在Java中,可以使用
Class.forName()方法来加载JDBC驱动。 - 创建连接:一旦驱动加载成功,应用程序就可以使用驱动提供的API来创建与数据库的连接。这通常涉及到指定数据库的地址、端口、用户名和密码等连接信息。
- 执行查询:通过连接对象,应用程序可以执行SQL查询、更新或删除操作。这些操作由驱动负责转换为数据库可以理解的格式,并发送到数据库服务器执行。
- 处理结果:执行查询后,驱动会接收数据库服务器的响应,并将其转换为应用程序可以处理的数据格式。例如,查询结果可能以结果集(ResultSet)的形式返回给应用程序。
核心原理
驱动的核心原理在于实现应用程序与数据库之间的通信协议。这涉及到以下几个关键方面:
- 协议转换:驱动负责将应用程序使用的API调用转换为数据库可以理解的协议格式。同样地,驱动也需要将数据库服务器的响应转换为应用程序可以理解的格式。
- 资源管理:驱动负责管理数据库连接、语句和结果集等资源。这包括创建、使用和释放这些资源,以确保资源的有效利用和避免资源泄漏。
- 错误处理:在通信过程中,如果发生错误(如连接失败、查询语法错误等),驱动需要能够捕获这些错误,并将其转换为应用程序可以理解的异常或错误码。
- 性能优化:为了提高性能,驱动可能会实现一些优化策略,如连接池管理、批量操作、预编译语句等。
示例(以Java JDBC为例)
在Java中,使用JDBC(Java Database Connectivity)来与数据库交互是一种常见的做法。以下是一个简单的JDBC示例,展示了驱动加载和数据库交互的基本过程:
import java.sql.*;
public class DatabaseExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/mydatabase";
String user = "username";
String password = "password";
try {
// 加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 创建连接
Connection conn = DriverManager.getConnection(url, user, password);
// 创建语句并执行查询
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM mytable");
// 处理查询结果
while (rs.next()) {
String columnValue = rs.getString("column_name");
System.out.println(columnValue);
}
// 关闭资源
rs.close();
stmt.close();
conn.close();
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
}
}
}在这个示例中,我们首先加载了MySQL的JDBC驱动,然后创建了与数据库的连接,并执行了一个简单的查询操作。最后,我们处理了查询结果并关闭了相关资源。
二.PreparedStatement
在数据库编程中,PreparedStatement 是 JDBC(Java Database Connectivity)API 中的一个关键接口,它代表一个预编译的 SQL 语句。使用 PreparedStatement 相对于使用普通的 Statement 对象有诸多优势,包括提高性能、防止 SQL 注入攻击以及更好的类型安全性。
PreparedStatement 的优势
性能提升:
PreparedStatement对象是预编译的,这意味着 SQL 语句只会被数据库编译一次,并在随后的执行中重用。相比之下,使用Statement每次执行 SQL 时都需要重新编译,这在处理大量相同结构的 SQL 语句时会造成不必要的性能开销。防止 SQL 注入:
PreparedStatement使用占位符(通常是问号?)来代表参数,并通过setXXX()方法设置参数值。这种方式可以有效防止 SQL 注入攻击,因为数据库会正确地转义或处理参数值,而不是将它们作为 SQL 代码的一部分来解析。类型安全性:
PreparedStatement提供了类型特定的setXXX()方法来设置参数值,这有助于确保传递给数据库的数据类型是正确的。可重用性:由于
PreparedStatement对象可以被重复使用多次(只需要为每次执行设置新的参数值),因此在处理循环或批量操作时特别有用。
使用示例
以下是一个简单的示例,演示了如何在 Java 中使用 PreparedStatement:
import java.sql.*;
public class PreparedStatementExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/mydatabase";
String user = "username";
String password = "password";
try (Connection conn = DriverManager.getConnection(url, user, password)) {
// 创建 PreparedStatement 对象
String sql = "INSERT INTO mytable (column1, column2) VALUES (?, ?)";
PreparedStatement pstmt = conn.prepareStatement(sql);
// 设置参数值
pstmt.setString(1, "value1");
pstmt.setInt(2, 123);
// 执行语句
int rowsAffected = pstmt.executeUpdate();
System.out.println(rowsAffected + " rows inserted.");
// 如果需要查询,可以使用相同的 PreparedStatement 对象,并设置新的参数值
// ...
} catch (SQLException e) {
e.printStackTrace();
}
}
}在这个示例中,我们首先创建了一个 PreparedStatement 对象,并为其提供了 SQL 插入语句。然后,我们使用 setString() 和 setInt() 方法为语句中的占位符设置具体的参数值。最后,我们调用 executeUpdate() 方法来执行插入操作。
请注意,在使用完 PreparedStatement 后,不需要显式地关闭它,因为我们在 try 语句中使用了 Java 7 引入的 try-with-resources 语句,它会自动关闭实现了 AutoCloseable 或 Closeable 接口的资源,包括 Connection、Statement 和 ResultSet。
通过使用 PreparedStatement,我们可以编写更安全、更高效且更易于维护的数据库代码。
三.ResultSet
在数据库编程中,ResultSet 是 JDBC(Java Database Connectivity)API 的一个重要组成部分,用于表示从数据库查询操作中获取的结果集。当你执行一个查询(如 SELECT 语句)时,数据库服务器会返回一个结果集,这个结果集包含了查询结果的所有行和列。在 Java 中,这个结果集是通过 ResultSet 对象来表示的。
ResultSet 的主要特点
遍历性:
ResultSet对象可以通过游标(cursor)来遍历查询结果中的每一行。你可以使用next()方法来移动到下一行,并通过getXxx()方法(如getString(),getInt()等)来获取当前行的列值。可滚动和可更新:某些类型的
ResultSet(如TYPE_SCROLL_INSENSITIVE或TYPE_SCROLL_SENSITIVE)支持滚动操作,这意味着你可以向前或向后移动游标来访问结果集中的任意行。此外,某些ResultSet实现还支持更新操作,允许你修改结果集中的数据并将其写回数据库。只读与可写:默认情况下,
ResultSet是只读的,这意味着你不能通过它修改数据库中的数据。但是,当你创建Statement或PreparedStatement对象时,可以通过指定适当的参数来创建一个可写的ResultSet。元数据访问:
ResultSet对象还提供了访问其元数据的方法,如getMetaData(),这可以让你查询结果集的结构信息,如列名、列类型等。
使用示例
下面是一个简单的示例,演示了如何在 Java 中使用 ResultSet 来处理查询结果:
import java.sql.*;
public class ResultSetExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/mydatabase";
String user = "username";
String password = "password";
try (Connection conn = DriverManager.getConnection(url, user, password);
Statement stmt = conn.createStatement()) {
// 执行查询
String sql = "SELECT column1, column2 FROM mytable";
ResultSet rs = stmt.executeQuery(sql);
// 遍历结果集
while (rs.next()) {
String column1Value = rs.getString("column1");
int column2Value = rs.getInt("column2");
System.out.println("Column 1: " + column1Value + ", Column 2: " + column2Value);
}
// 关闭 ResultSet(实际上在这个 try-with-resources 语句中会自动关闭)
} catch (SQLException e) {
e.printStackTrace();
}
}
}
在这个示例中,我们首先建立了一个到数据库的连接,然后创建了一个 Statement 对象来执行 SQL 查询。查询的结果被封装在一个 ResultSet 对象中,我们使用 while 循环和 next() 方法来遍历结果集中的每一行,并使用 getXxx() 方法来获取每一行的列值。最后,当 try-with-resources 语句结束时,ResultSet、Statement 和 Connection 对象都会被自动关闭。
请注意,处理数据库时应该始终注意异常处理和资源管理,以确保程序的健壮性和性能。在这个示例中,我们使用了 try-with-resources 语句来自动管理资源,这是一个很好的实践。
四.事务处理
在数据库编程中,事务处理是一个至关重要的概念,它确保了一系列数据库操作要么全部完成,要么全部不完成,从而维护数据的完整性和一致性。事务处理在涉及多个步骤的复杂数据库操作中特别有用,例如银行转账、订单处理等。
事务处理通常具有以下四个关键属性,也被称为ACID特性:
- 原子性(Atomicity):
- 事务被视为一个不可分割的工作单元。事务中的操作要么全部提交成功,要么全部回滚(撤销),不会处于中间状态。
- 如果事务中的某个操作失败,整个事务会回滚到起始状态,确保数据库的一致性。
- 一致性(Consistency):
- 事务必须确保数据库从一个一致性状态转变到另一个一致性状态。
- 一致性是通过在事务开始时设置检查点,并在事务结束时验证状态来实现的。
- 如果事务不能保持一致性,它将被回滚。
- 隔离性(Isolation):
- 在事务执行期间,它所做的修改对其他事务是不可见的,直到该事务提交。
- 这确保了并发执行的事务不会相互干扰,从而避免了数据不一致和冲突。
- 数据库管理系统(DBMS)使用锁或其他机制来实现隔离性。
- 持久性(Durability):
- 一旦事务提交,其对数据库的修改就是永久的,即使系统崩溃也不会丢失。
- DBMS通常使用日志和恢复机制来确保事务的持久性。
在数据库编程中,你可以使用多种语言和技术来管理事务,如SQL、JDBC(Java)、ADO.NET(.NET)等。以下是一个使用SQL进行事务处理的简单示例:
BEGIN TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE name = 'Alice';
UPDATE accounts SET balance = balance + 100 WHERE name = 'Bob';
-- 检查是否发生了错误,如果有则回滚事务
IF (some_error_condition) THEN
ROLLBACK;
ELSE
COMMIT;
END IF;在上面的示例中,我们首先开始一个事务,然后执行两个更新操作(从Alice的账户中扣款并给Bob的账户存款)。如果在执行过程中发生错误,我们回滚事务以撤销所有更改。如果没有错误,我们提交事务以永久保存更改。
在应用程序代码中,使用特定于编程语言的数据库API,你可以以类似的方式管理事务。例如,在Java中使用JDBC时,你可以使用Connection对象的setAutoCommit(false)方法来禁用自动提交,然后执行一系列操作,最后使用commit()或rollback()方法来提交或回滚事务。
事务处理是数据库编程中的关键概念,它确保了数据的完整性和一致性,并允许在复杂操作中管理并发和错误情况。
五.程序分层开发
在数据库编程中,程序分层开发是一种重要的架构设计模式,它通过将应用程序划分为不同的逻辑层来提高代码的可维护性、可扩展性和可重用性。这种分层结构有助于将业务逻辑、数据访问和用户界面分离,使得每一层可以独立地开发和测试。
以下是在数据库编程中常见的程序分层结构:
- 表示层(Presentation Layer):
- 负责与用户进行交互,显示信息和接收用户输入。
- 在Web应用程序中,这通常涉及HTML、CSS和JavaScript的使用,而在桌面应用程序中可能涉及图形用户界面(GUI)库。
- 表示层通常不直接处理业务逻辑或数据访问,而是通过与业务逻辑层交互来实现功能。
- 业务逻辑层(Business Logic Layer):
- 包含应用程序的核心功能和业务规则。
- 处理表示层发送的请求,并根据业务规则执行相应的操作。
- 与数据访问层交互以获取或存储数据,但不直接处理数据访问的细节。
- 业务逻辑层通常包含服务类或领域模型,用于封装业务逻辑和验证规则。
- 数据访问层(Data Access Layer):
- 负责与数据库进行交互,执行CRUD(创建、读取、更新、删除)操作。
- 包含数据访问对象(DAO)或仓储(Repository),这些对象封装了与数据库交互的具体实现。
- 数据访问层隐藏了数据库连接、查询构建和结果映射的复杂性,使得业务逻辑层可以专注于业务逻辑的实现。
- 通常使用ORM(对象关系映射)工具来简化数据访问层的开发,如Hibernate、Entity Framework等。
除了以上三个主要层次外,根据应用程序的复杂性和需求,还可以引入其他辅助层次,如验证层、服务层、安全层等。
程序分层开发的好处包括:
- 可维护性:每层之间的低耦合度使得对某一层的修改不会影响到其他层,降低了维护成本。
- 可扩展性:通过添加新的层或修改现有层的实现,可以轻松地扩展应用程序的功能。
- 可重用性:各层之间的独立性使得某些层可以在其他项目中被重用,提高了代码利用率。
- 团队协作:不同的团队或开发人员可以专注于不同的层次进行开发,提高了开发效率。
在实际开发中,为了保持层次之间的清晰界限和降低耦合度,通常使用接口或抽象类来定义层之间的交互方式。这样,每一层都可以依赖于定义的接口或抽象类,而不是直接依赖于具体的实现类。这有助于实现依赖倒置原则和开闭原则,提高代码的可维护性和可扩展性。