团结就是力量!
Ensemble Learning
兼听则明,偏信则暗。
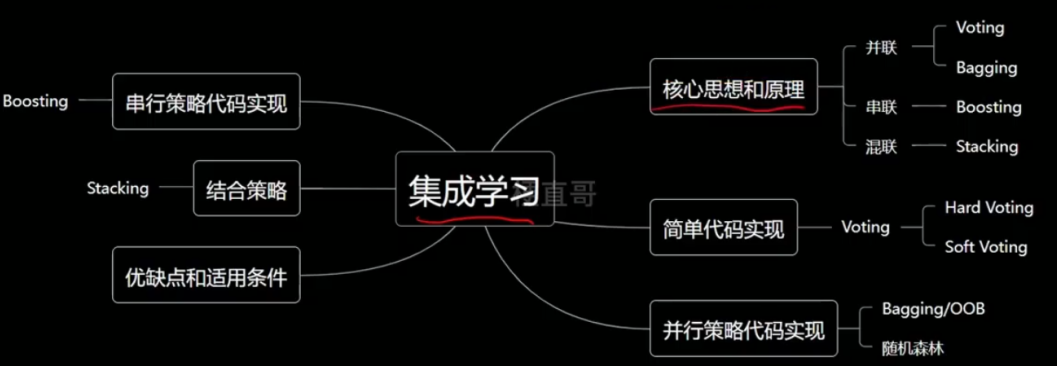
集成学习既是一种思想也是一类算法,它是建立在其他机器学习的算法之上,研究怎么让不同的算法之间进行协同。
既可以监督学习,也可以无监督学习。
集成学习用机器学习的术语来讲,就是采用多个学习器对数据集进行预测,从而提高整体学习器的泛化能力。
1、核心思想和原理
集成学习按照 所使用的单个子模型是不是同一种 分为同质的方法和异质的方法。
按照 子模型的连接方式 可以分为串行策略、并行策略和串并结合的策略。
其中并联最常见。
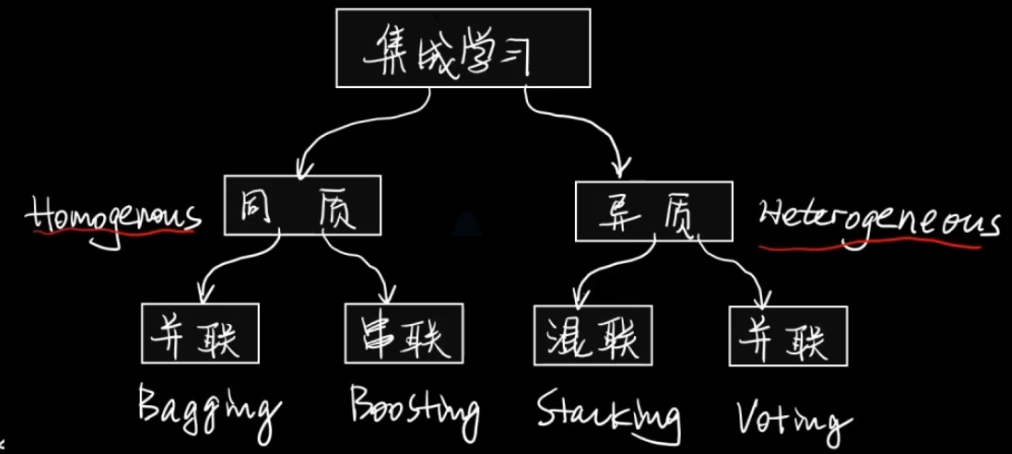
并联策略 —— Voting
少数服从多数。

并联策略 —— Bagging
数据组织方式不同,从总的数据集中抽样组成新的子集。
所有支路使用同样的算法。
分类还是使用投票的方式集成,回归任务则是使用平均的方式集成。

串行策略 —— Boosting
训练一系列的弱学习器,弱学习器是指仅比随机猜测好一点点的模型,例如较小的决策树。
训练的方式使用加权的数据,在训练的早期,对于错分的数据给予较大的权重。
对于训练好的弱分类器,如果是分类任务则按照权重进行投票,如果是回归任务则进行加权,然后再进行预测。
最常用的一种优化算法AdaBoosting。

混联策略 —— Stacking
其实是一个二次学习的过程。

2、并行策略
2.1、Voting
基于Voting的集成学习分类器代码实现
import numpy as np
import matplotlib.pyplot as pltfrom sklearn.datasets import make_moonsx, y = make_moons(
n_samples=1000,
noise=0.4,
random_state=20
)
x.shape, y.shape((1000, 2), (1000,))
plt.scatter(x[:, 0], x[:, 1], c = y, s = 10)
plt.show()
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state = 0)手动实现集成学习
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNBclf = [
KNeighborsClassifier(n_neighbors=3),
LogisticRegression(),
GaussianNB()
]for i in range(len(clf)):
clf[i].fit(x_train, y_train)
print(clf[i].score(x_test, y_test))0.832 0.848 0.848
y_pred = np.zeros_like(y_test)
for i in range(len(clf)):
y_pred += clf[i].predict(x_test)
y_pred[y_pred < 2] = 0
y_pred[y_pred >= 2] = 1
y_predarray([0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0,
1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0,
1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0,
1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1,
0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1,
0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1,
0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0,
0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1,
1, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1,
0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1,
0, 0, 1, 0, 1, 1, 0, 1])
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)0.852
sklearn中的集成学习
from sklearn.ensemble import VotingClassifierclf = [
KNeighborsClassifier(n_neighbors=3),
LogisticRegression(),
GaussianNB()
]vclf = VotingClassifier(
estimators=[
('knn', clf[0]),
('lr', clf[1]),
('gnb', clf[2])
],
voting='hard',
n_jobs=-1
)
vclf.fit(x_train, y_train)
vclf.score(x_test, y_test)0.852
vclf = VotingClassifier(
estimators=[
('knn', clf[0]),
('lr', clf[1]),
('gnb', clf[2])
],
voting='soft',
n_jobs=-1
)
vclf.fit(x_train, y_train)
vclf.score(x_test, y_test)0.868
针对分类问题,硬投票和软投票会导致结果的不同。回归问题不涉及。

2.2、Bagging
针对2.1中的集成学习,发现使用的不行还是不够多,差异不明显。
解决:
使用同一种模型。
随机抽取训练集进行训练。
单个模型准确率略有影响 ——

数据抽取策略 —— 有放回Bagging √ 一般使用 ~
—— 无放回Pasting
对于有放回取样:
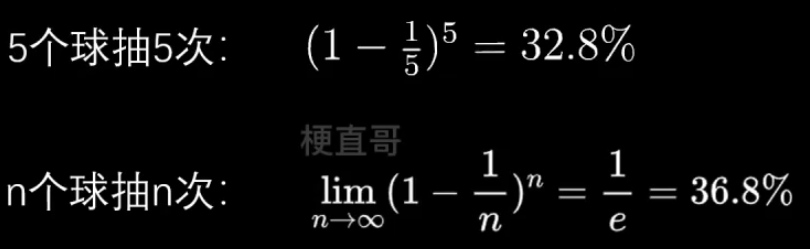
OOB(out-of-bag)
针对上面出现的问题,有36.8%的样本没被抽到,那么:
不区分训练、测试集,用没被取到的作为测试集。
代码实现:
import numpy as np
import matplotlib.pyplot as pltfrom sklearn.datasets import make_moons
x, y = make_moons(
n_samples=1000,
noise=0.4,
random_state=20
)
x.shape, y.shape((1000, 2), (1000,))
plt.scatter(x[:, 0], x[:, 1], c = y, s = 10)
plt.show()
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state = 0)Bagging
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifierbagging = BaggingClassifier(
base_estimator=DecisionTreeClassifier(),
n_estimators=100,
bootstrap=True,
max_samples=500,
n_jobs=-1,
random_state=20
)
bagging.fit(x_train, y_train)
bagging.score(x_test, y_test)0.848
OOB
bagging = BaggingClassifier(
base_estimator=DecisionTreeClassifier(),
n_estimators=100,
bootstrap=True,
max_samples=500,
oob_score=True,
n_jobs=-1,
random_state=20
)
bagging.fit(x, y)
bagging.oob_score_0.84
最后再讲一下 参数是特征相关的:
前面讲的都是数据抽取的内容,本质上是想训练多个不同的模型进行集成
那么对于高维样本,是不是也可以对特征列进行抽取呢?
bagging = BaggingClassifier(
base_estimator=DecisionTreeClassifier(),
n_estimators=100,
bootstrap=True,
max_samples=500,
oob_score=True,
bootstrap_features=True,########有放回无放回
max_features=1,
n_jobs=-1,
random_state=20
)
bagging.fit(x, y)
bagging.oob_score_0.78
2.3、随机森林
Bagging的拓展变体。
Bagging+ Base Estimator (Decision Tree
构建决策树时,提供了更多的随机性,他在节点划分时是在随机的特征子集上寻找最优的划分,并不是在每一个节点的所有特征上寻找最优化分。
子模型的随机性越强。集成效果越好。

代码实现:
import numpy as np
import matplotlib.pyplot as pltfrom sklearn.datasets import make_moons
x, y = make_moons(
n_samples=1000,
noise=0.4,
random_state=20
)plt.scatter(x[:, 0], x[:, 1], c = y, s = 10)
plt.show()
Bagging
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(
base_estimator=DecisionTreeClassifier(),
n_estimators=100,
bootstrap=True,
max_samples=500,
oob_score=True,
n_jobs=-1,
random_state=20
)
bagging.fit(x, y)
bagging.oob_score_0.84
Random Forest Trees
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(n_estimators=100,max_samples=500,max_leaf_nodes=16,oob_score=True, n_jobs=-1, random_state=20)
rf_clf.fit(x,y)
rf_clf.oob_score_提取特征的重要性 feature_importances_
rf_clf.feature_importances_array([0.45660686, 0.54339314])
from sklearn import datasets
iris = datasets.load_iris()
data_X = iris.data
data_y = iris.target
rf_clf = RandomForestClassifier(n_estimators=100,max_leaf_nodes=16,oob_score=True, n_jobs=-1, random_state=20)
rf_clf.fit(data_X,data_y)
rf_clf.feature_importances_array([0.09674332, 0.02771735, 0.43857879, 0.43696054])
iris.feature_names['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
labels = np.array(iris.feature_names)
importances = rf_clf.feature_importances_
indices = np.argsort(importances)[::-1]
plt.bar(range(data_X.shape[1]), importances[indices], color='lightblue',align='center')
plt.xticks(range(data_X.shape[1]), labels[indices], rotation=70)
plt.xlim([-1,data_X.shape[1]])
plt.tight_layout()
plt.show()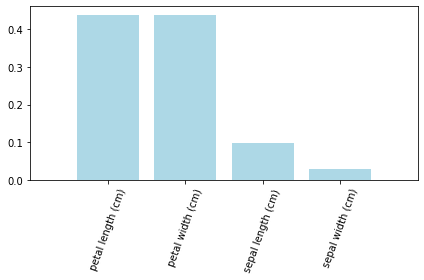
Extra-Trees
随机森林的一个扩展变体。
随机森林是在随机选取的特征子集选取最优的特征和阈值上进行节点划分,而Extra-trees使用随机的特征和随机的闯值进行节点划分。
进一步提高模型随机性,有效抑制过拟合。
不需额外计算,训练速度更快。
from sklearn.ensemble import ExtraTreesClassifier
et_clf = ExtraTreesClassifier(n_estimators=100, max_samples=500,bootstrap=True, oob_score=True, n_jobs=-1,random_state=20)
et_clf.fit(x,y)
et_clf.oob_score_0.834
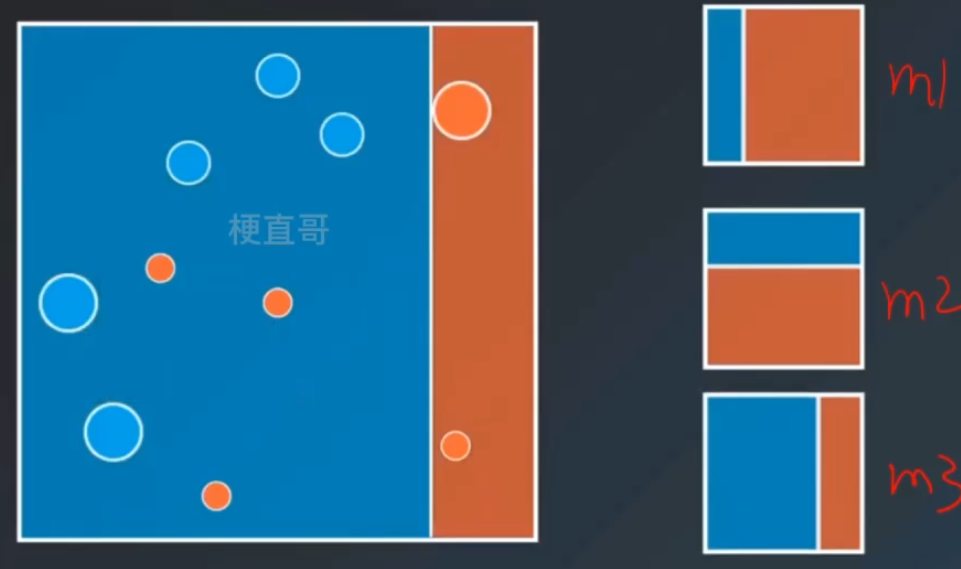
3、串行策略 Boosting
每个子模型在训练过程中更加关注上一个模型中表现不好的样本点,以此来提高模型效果。
3.1、 Adaboost

代码实现:
import numpy as np
import matplotlib.pyplot as pltfrom sklearn.datasets import make_moons
x, y = make_moons(
n_samples=1000,
noise=0.4,
random_state=20
)plt.scatter(x[:, 0], x[:, 1], c = y, s = 10)
plt.show()
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state = 0)AdaBoost
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
ada_clf = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_leaf_nodes=16), n_estimators=100)
ada_clf.fit(x_train, y_train)AdaBoostClassifier
AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_leaf_nodes=16),
n_estimators=100)
base_estimator: DecisionTreeClassifier
DecisionTreeClassifier(max_leaf_nodes=16)
DecisionTreeClassifier
DecisionTreeClassifier(max_leaf_nodes=16)
ada_clf.score(x_test, y_test)0.808
3.2、Gradient Boosting
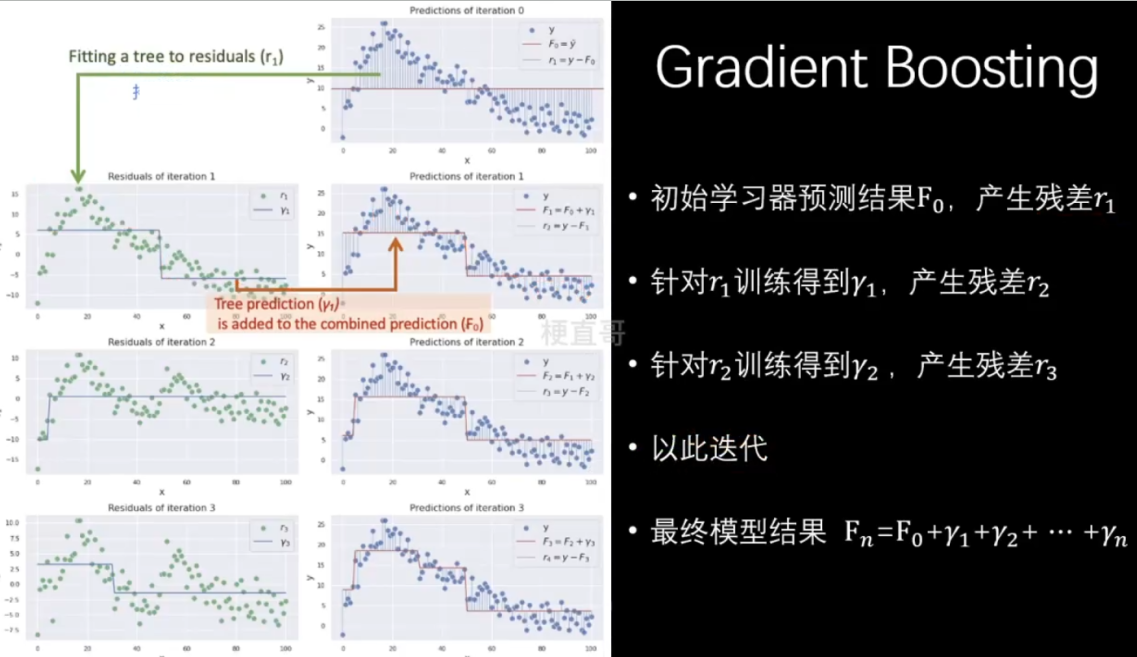
from sklearn.ensemble import GradientBoostingClassifier
gb_clf = GradientBoostingClassifier(n_estimators=100)
gb_clf.fit(x_train,y_train)注意:GradientBoostingClassifier 已经指定了基学习器就是决策树。
GradientBoostingClassifier
GradientBoostingClassifier()
gb_clf.score(x_test,y_test)0.86
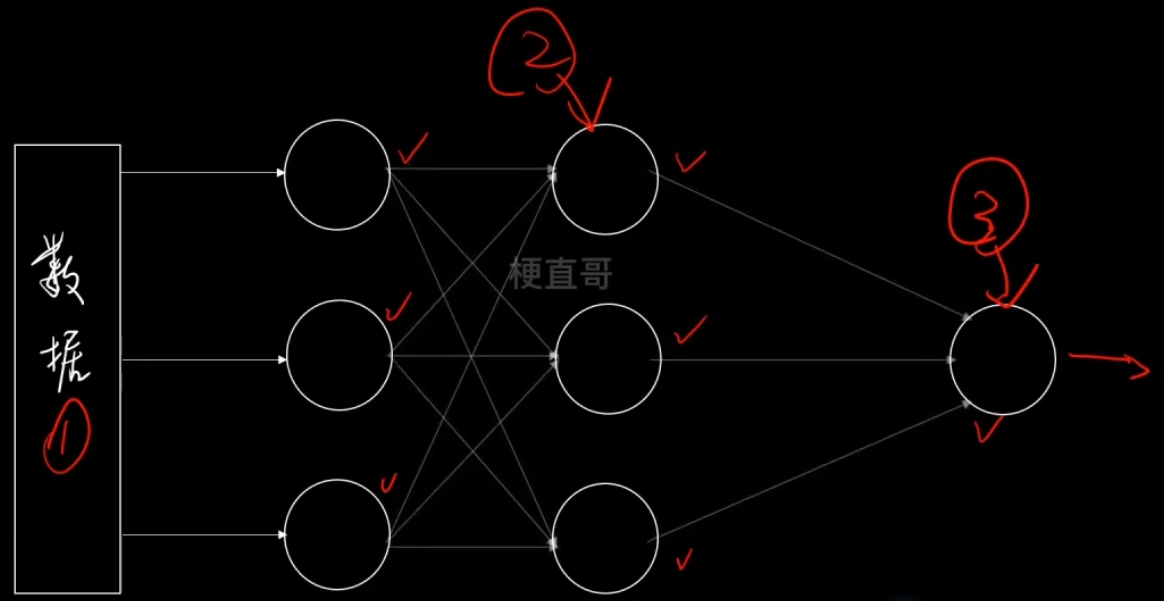
4、结合策略 Stacking
先用第一份数据 训练这三个模型,
再用第二份数据 经过这三个模型输出之后训练第二级的模型4。
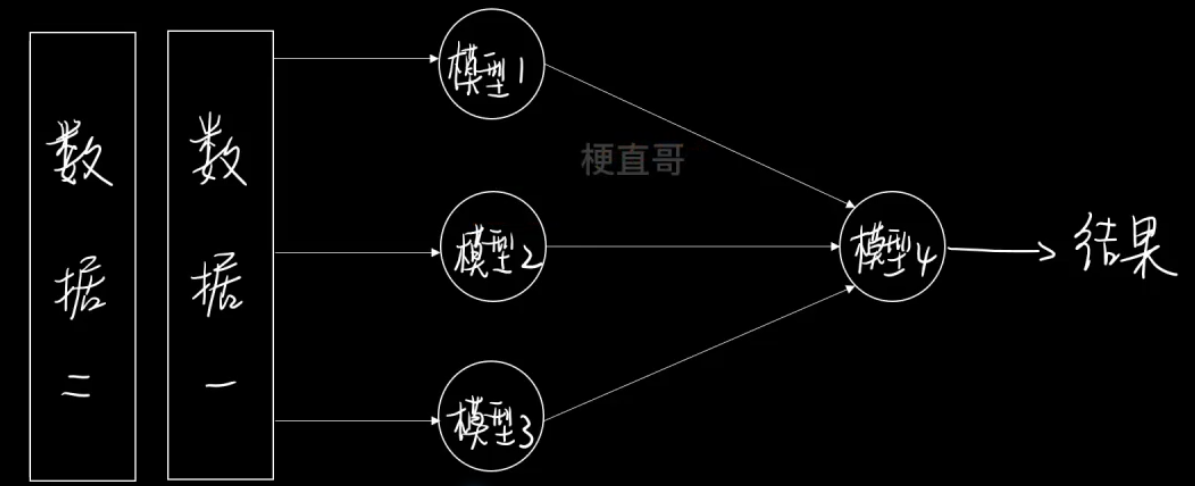
复杂,容易过拟合。
5、优缺点及适用条件
Voting方法
优点
少数服从多数,简单高效。
通过模型集成,降低方差,提高鲁棒性。
缺点
软投票法(类别概率)与硬投票法(清晰类别标签)结果可能不一致。
所有子模型对预测贡献均等。
Bagging方法
优点
可以减少误差中的方差项。从而降低模型预测误差。(举例 早读)
缺点
增加了时间开销。
需要模型具备多样性。
并行训练需要较大计算资源。
随机森林
优点
准确率高。
不容易过拟合,抗噪能力强。
能够处理高维数据,并且不用做特征选择,既能处理离散数据也能处理连续数据。
数据集无需归一化,还可以得到变量重要性的排序。容易实现并行化。
缺点
噪声较大时容易过拟合
取值划分较多的属性影响大,在这种数据上产出的权值不可信。
黑盒模型。
Boosting方法
优点
更加巧妙鲁棒。
减少偏差bias。
缺点
容易过拟合。
Adaboost方法
优点
二分类或多分类场景。
灵活、简单,不易过拟合。
精度高,无需调参。
缺点
弱分类器数目不太好设定,可以使用交叉验证。
数据不平衡分类精度下降。
训练比较耗时,易受干扰。
Stacking方法
优点
效果好、鲁棒性高。
有可能讲集成的知识迁移。
有效对抗过拟合。
缺点
二次学习更加复杂。
注意leak情况。
参考





























![[ CTF ]【天格】战队WriteUp-第七届“强网杯”全国安全挑战赛](https://img-blog.csdnimg.cn/direct/fea28a8ed9a940fbaba43b5b8df60785.png#pic_center)