
一、写作动机:
虽然从头开始训练大型语言模型(LLMs)可以生成具有独特功能和优势的模型,但这种方法成本高昂,而且可能导致功能冗余。
二、主要贡献:
入了 LLMs 知识融合的概念,旨在结合现有 LLMs 的能力,并将它们转移到一个 LLM 中。通过利用源 LLM 的生成分布,将它们的集体知识和独特优势外部化,从而有可能提升目标模型的能力,使其超越任何独立源 LLM 的能力。
三、大模型知识融合:
3.1预备知识:
让t表示从语料库C中采样的长度为N的文本序列,t<i = (t1, t2, . . . , ti−1)表示第i个toekn之前的序列。对于由θ参数化的语言模型的因果语言建模(CLM)目标,定义为最小化负对数似然:
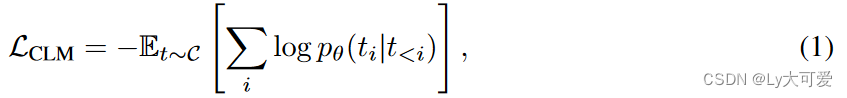
具体来说,对于文本序列t,我们聚合token级别的预测,并创建一个概率分布矩阵Ptθ ∈ RN×V,其中第i行表示模型对于大小为V的词汇表中第i个token的预测分布。然后,CLM目标可以解释为减小Ptθ和独热标签矩阵Ot ∈ {0, 1}N×V之间的差异,其中每一行是相应golden token的独热表示。形式上,CLM目标转换为以下表示:

3.2模型融合
应用提供的K个源LLMs并获得一组概率分布矩阵 ——> 对齐概率矩阵(源LLMs之间词汇表会有差异)——>矩阵融合
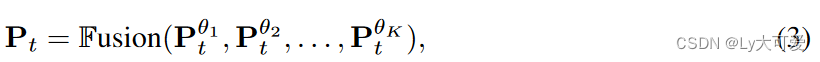
融合后的目标函数转变为如下式子:
![]()
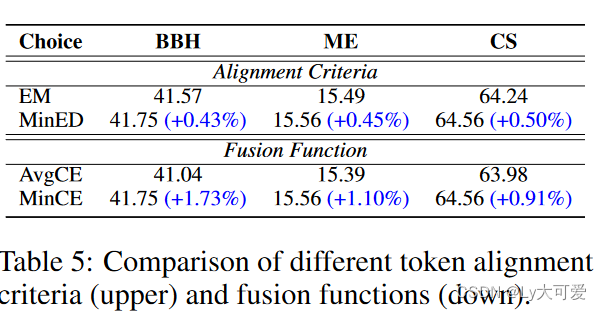
PS:两种融合函数:(1)MinCE:该函数输出交叉熵得分最低的分布矩阵;(2)AvgCE:该函数基于交叉熵得分产生分布矩阵的加权平均。
持续训练的总体目标包括因果语言建模目标LCLM和融合目标LFusion的加权组合:
![]()

四、实验:
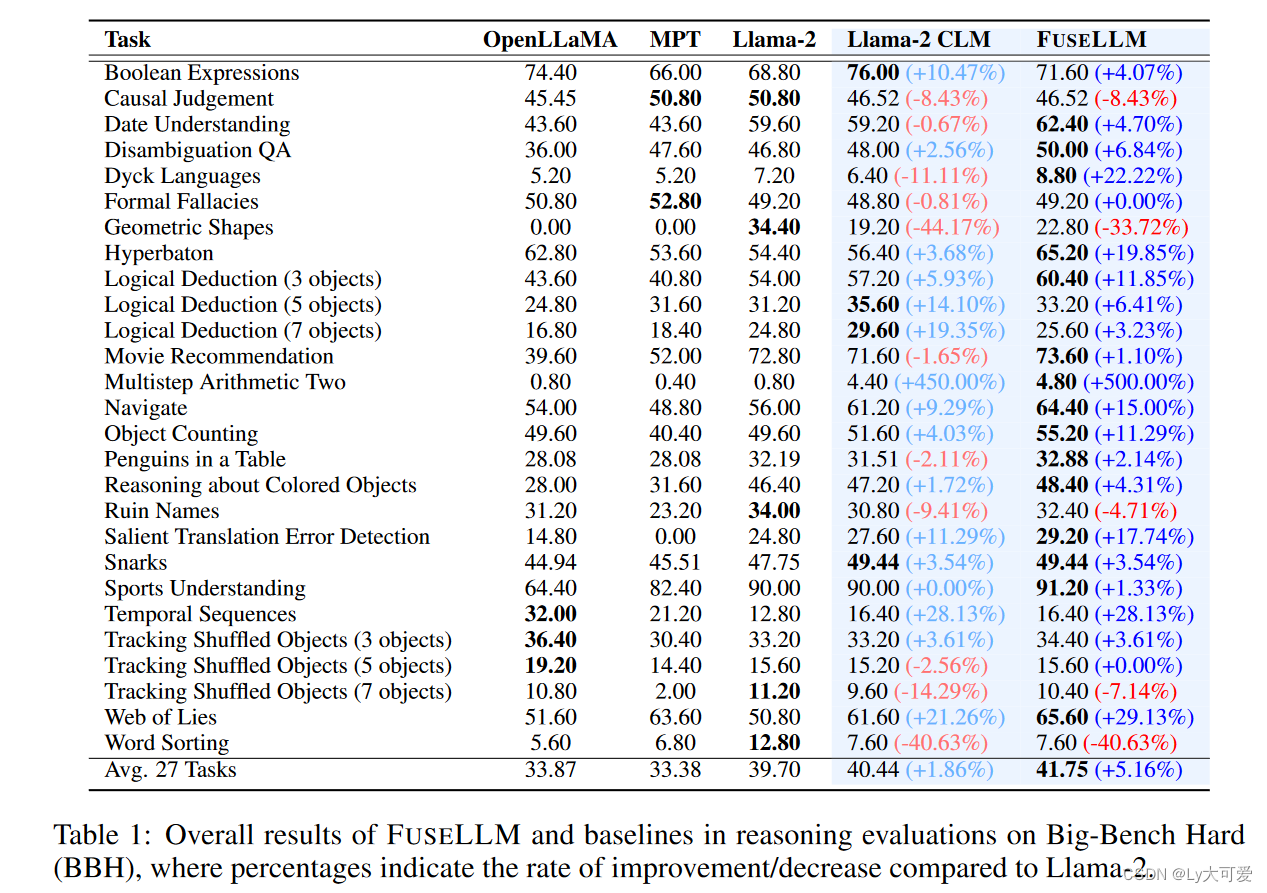
模型:三个代表性的开源模型:Llama-2、OpenLLaMA和MPT作为融合的源LLMs。关于目标LLM,选择另一个Llama-2 7B,通常是这三个源LLMs中最强大的一个。目标LLM从与其源对应物相同的预训练权重开始,但不同之处在于它在训练过程中更新参数。
数据集:MiniPile包括大约100万份来自22个领域的文档和18亿个token。
评估基准:推理、常识、代码生成。
Baseline:原始LLMs,包括Llama-2 7B、OpenLLaMA 7B和MPT 7B;以及(2)Llama-2 CLM:仅使用Casual Language Modeling目标在MiniPile上持续训练Llama-2 7B。
实验结果:



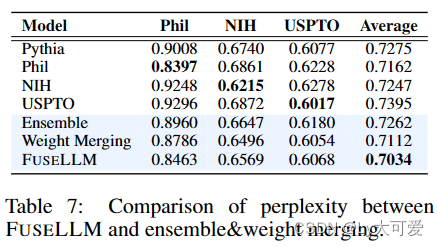



























![[Flutter]自定义等待转圈和Toast提示](https://img-blog.csdnimg.cn/direct/d6a78fd5b9c34efb914be952ff9c08c1.png)






