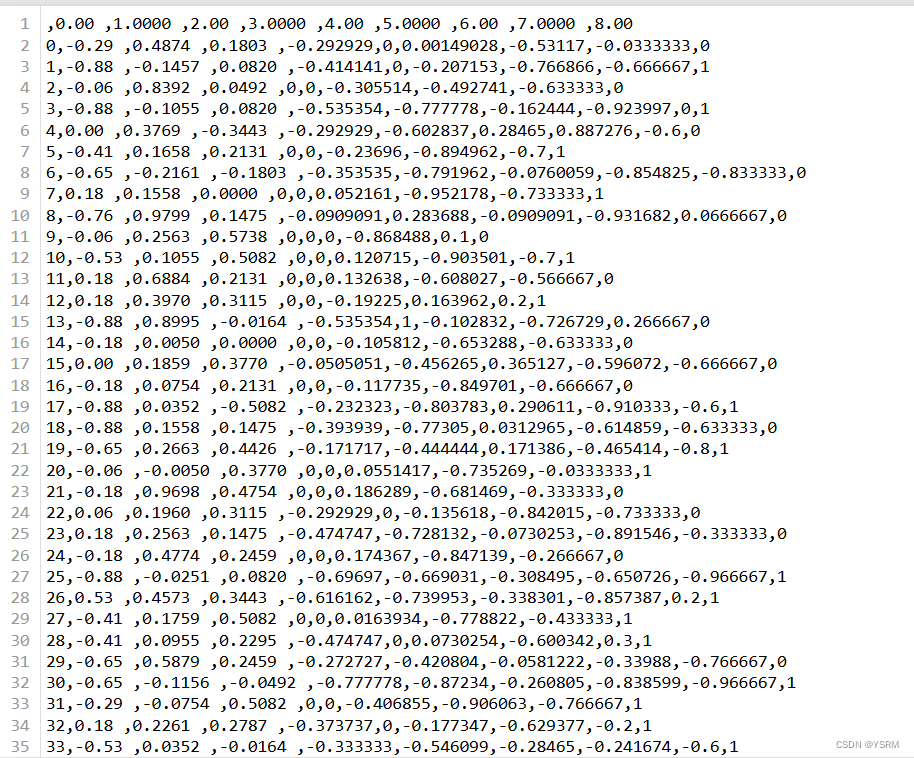
搭建之前的基础与思考
构建模型的基本思想:
构建深度学习的过程:产生idea,将idea转化成code,最后进行experiment,之后根据结果修改idea,继续idea–>code–>experiment的循环,直到最终训练到表现不错的深度学习网络模型。
BP网络的搭建
BPNN v-0.1
目标:搭建一个有学习能力的BP神经网络。
目标完成情况:
●局限:只能计算固定大小的数据尺寸
●局限:只有一层,即为感知机或单层神经网络
有一定了解的可以直接看到代码,代码注释有思路。
idea
●神经元(单层感知机):接收n维列向量x(特征维度为n),输出y的估计。 y ^ = σ ( W T ⋅ x + b ) \widehat y = \sigma(W^T · x + b) y
=σ(WT⋅x+b)
(多组输入x,可以按列堆叠形成矩阵。)
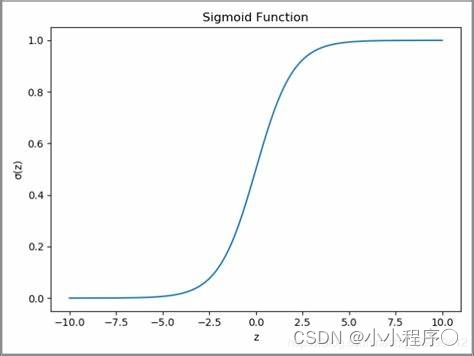
●激活函数:Sigmoid、ReLU等
S i g m o i d 激活函数 σ ( z ) = 1 1 + e − z Sigmoid激活函数 \sigma (z) = \frac 1 {1 + e^{-z}} Sigmoid激活函数σ(z)=1+e−z1
σ , ( z ) = σ ( z ) ( 1 − σ ( z ) ) \sigma^,(z) = \sigma(z)(1 - \sigma(z)) σ,(z)=σ(z)(1−σ(z))
●损失函数:量化模型预测值与真实值的偏差,模型训练的目的是让Loss尽可能小。
例如: L ( y ^ , y ) = − ( y log y ^ + ( 1 − y ) log ( 1 − y ^ ) ) L(\widehat y, y) = -(y\log{\widehat y} + (1-y)\log{(1-\widehat y)}) L(y
,y)=−(ylogy
+(1−y)log(1−y
))
成本函数就是所有训练样本损失函数的平均。
●反向传播时的复合求导
d y d x = d y d u d u d v d v d x \frac{dy}{dx} = \frac{dy}{du}\frac{du}{dv}\frac{dv}{dx} dxdy=dudydvdudxdv
反向传播时只需要计算每一层的导数,最后乘积即可。
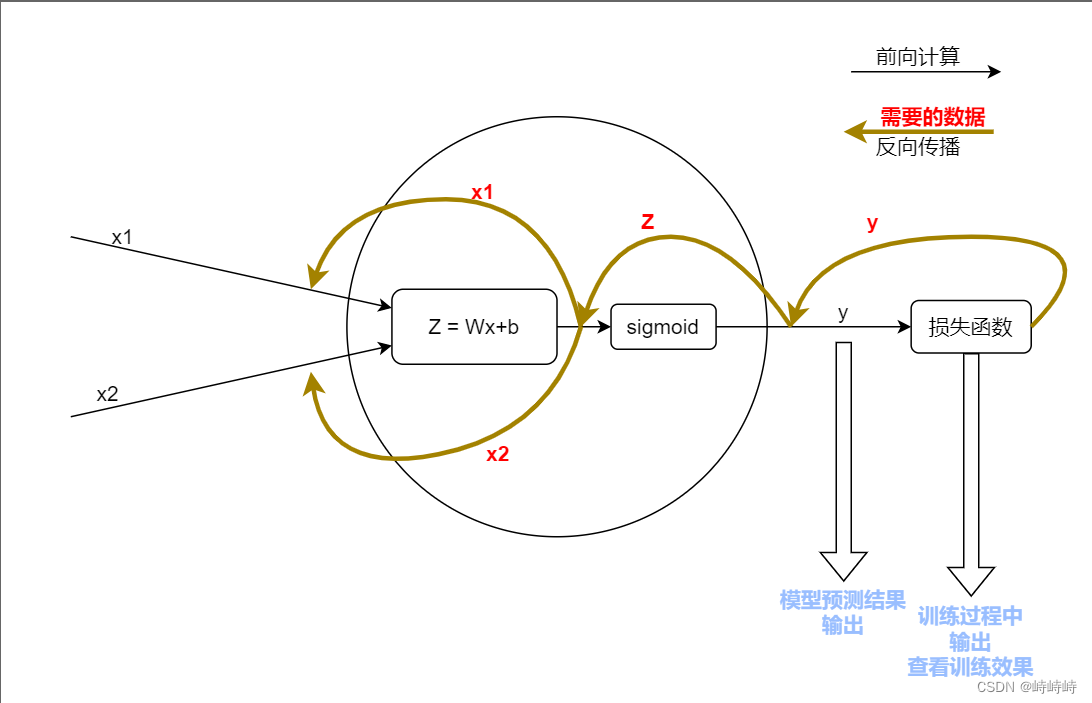
整体复盘以及数据流向图
code
根据面向对象编程思想,有两种实现思路,以神经元为最小类或以神经网络为最小类。
这里为了有更清晰的层次选择以神经元为最小类。
自己造数据,假设数据是学生的身高体重,根据此二者预测学生性别。
# Define dataset,已经经过预处理,保留特征
data = np.array([
[-2, -1], # Alice
[25, 6], # Bob
[17, 4], # Charlie
[-15, -6], # Diana
])
all_y_trues = np.array([
1, # Alice
0, # Bob
0, # Charlie
1, # Diana
])
#输入输出关系很明显,方便出问题时跟踪计算过程进行调试
代码:
import numpy as np
# 激活函数与激活函数的求导
def sigmoid(x):
return 1/(1 + np.exp(-x))
def d_sigomid(x):
return sigmoid(x) * (1 - sigmoid(x))
# 神经元
class Neuron:
'''
-神经元基本属性包括权重和偏置量
-神经元方法前向计算和反向传递
-神经元默认接收二维的输入
'''
#初始化,针对特定尺寸的数据集
def __init__(self):
self.weights = np.random.normal(size=(1, 2))
self.bias = np.random.normal()
#前向计算过程集成化,用于训练完成后一步输出预测值
def feedforward(self, inputs):
Z = np.dot(self.weights, inputs) + self.bias
return sigmoid(Z)
#训练函数
def train_epoch(self, x_data, true_value):
'''
-迭代目的是更新权重参数和偏置参数,为了得到梯度需要知道导数
为了计算导数需要知道前向计算过程中的一些值。
训练时按照这个思路去计算需要的值,再更新权重就可以。
'''
#准备工作
learn_rate = 0.1
epochs = 100
for epoch in range(epoch):
for x, y_true in zip(x_data, ture_value):
#前向计算
z = np.dot(self.weight, inputs) + self.bias
y = sigmoid(z)
#损失函数采用平方差计算,求导较为容易
#l = (y - true_value) ** 2
#只有需要查看效果的轮次才计算输出
#一般只需要知道l关于y的导数即可,并不需要计算l的值
#反向传播
d_L_d_y = -2 * (y_true - y)
d_y_d_z = d_sigmod(z)
d_z_d_w1 = x1
d_z_d_w2 = x2
#实际计算可以合并很多步骤,这里分开写为了使过程更清晰
dw1 = d_L_d_y * d_y_d_z * d_z_d_w1
dw2 = d_L_d_y * d_y_d_z * d_z_d_w2
db = d_L_d_y * d_y_d_z
#体现了反向计算的复合过程
#更新
self.w[0] -= learn_rate * dw1
self.w[1] -= learn_rate * dw2
self.b -= learn_rate * db
if epoch % 10 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = ((y_preds - y_true) ** 2).mean()
print("Epoch %d loss %.3f" % (epoch, loss))
BPNN = Neuron()
BPNN.train(data, all_y_trues)
experiment
记录1
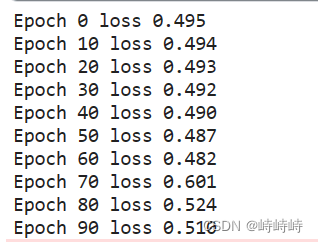

尝试调参,没有效果
尝试输出一些中间值,发现预测结果是没问题的,只是loss的计算有问题
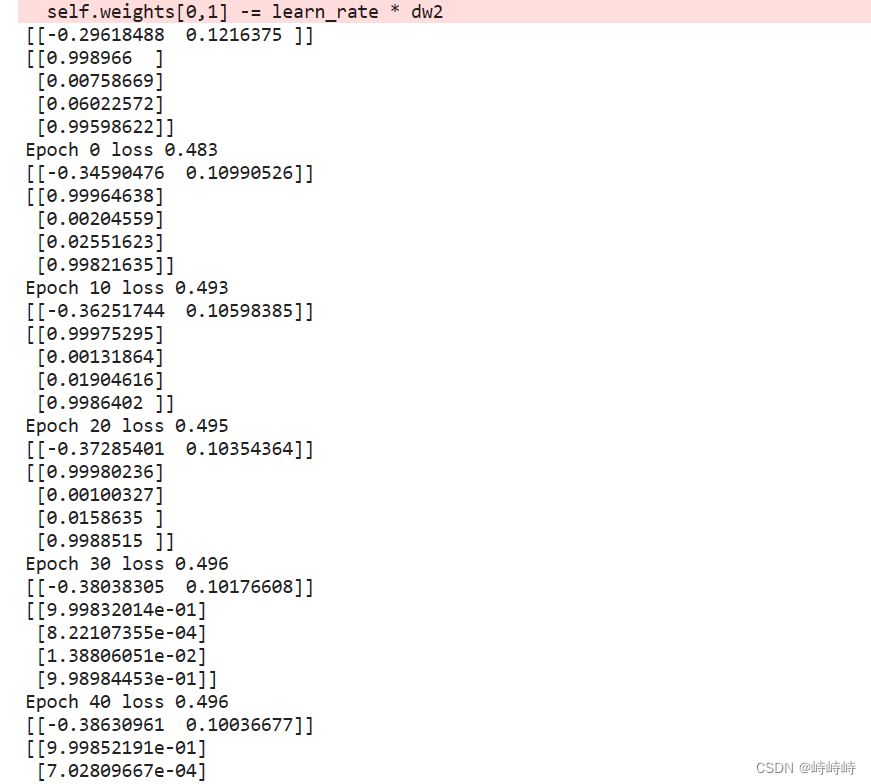
预测值是二维的列,真实值是一维的行,np广播相减直接出来一个4*4的矩阵。做减法时加一个转置就OK
记录2
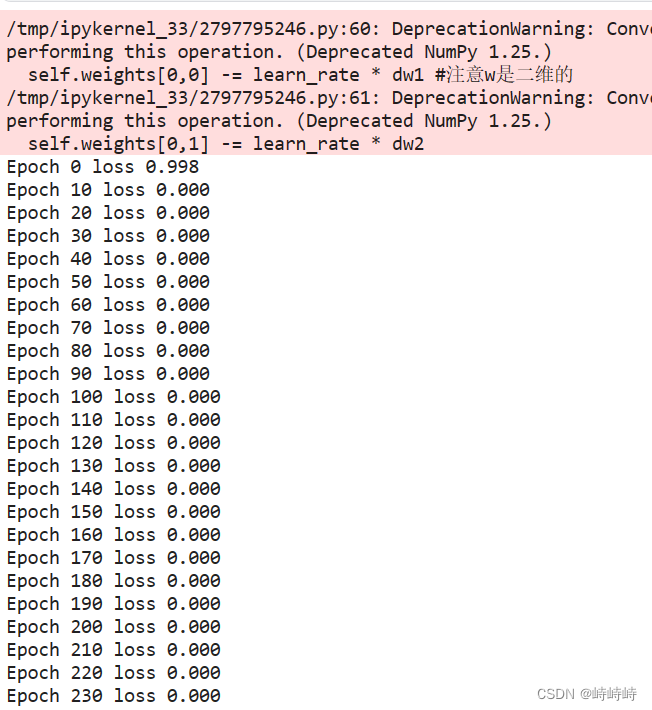
原因很明显,问题过于简单且没有噪音。
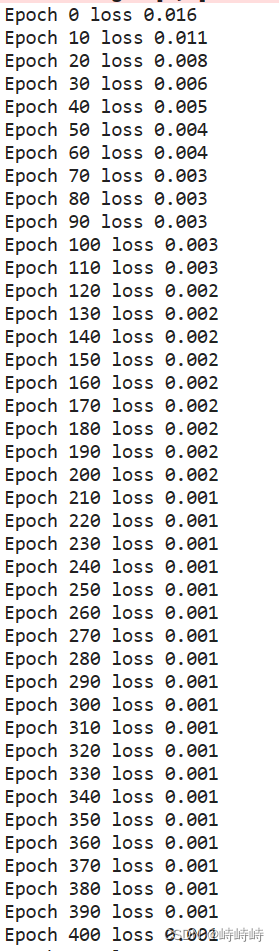
增加了一些数据并加入少量噪音。

能明显看到loss的下降过程,说明实验成功。
BPNN v-0.2层次加深,维度可选(向量化)
idea
实现可用于含隐藏层的通用神经元。
参考下图,构建可用于神经网络的通用神经元,需要能完成反向传播,神经元只要能记住每一次训练的输入数据即可。
在神经元类的基础上,创建层类,神经网络类,通过可选参数实现规模的自由选择。
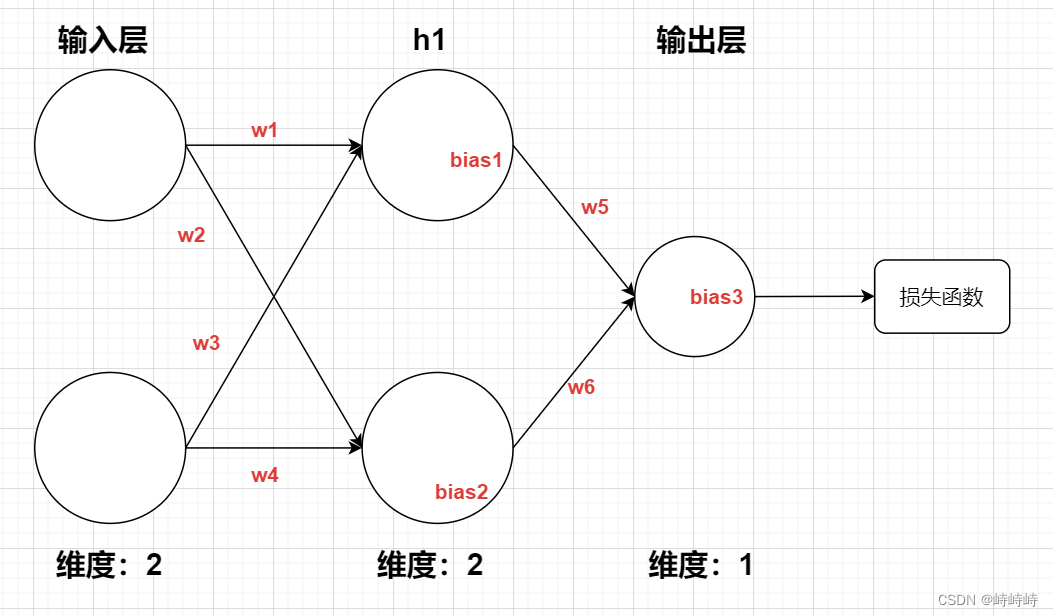
- 分析:同一层中的神经元输入输出维度相同
- 除输入层外,第
n层前向计算时接收(n-1)层维度输入值,输出1维值。 - 除输入层外,第
n层反向传播时接收(n-1)层维度输入值,输出(n-1)层维度权重梯度和1维偏置梯度。
code
先实现前向计算
#激活函数与激活函数的求导
def sigmoid(x):
return 1/(1 + np.exp(-x))
def d_sigmoid(x):
return sigmoid(x) * (1 - sigmoid(x))
#损失函数与损失函数的求导
def mse_loss(y_pre, y_true):
return (y_pre - y_true) ** 2
def d_mse_loss(y_pre, y_true):
return 2 * (y_pre - y_true) #这里减的方向要注意 ##求导方式
#神经元类
class Neuron:
'''
-属性:权重向量,偏置量
-记录上一次的输入向量。上一层维度
-记录下一层传输的梯度。下一层维度
-方法:前向计算,反向传播
'''
#初始化,需要输入上一层维度
def __init__(self, dim_before):
self.weights = np.random.normal(size=(1, dim_before))
self.bias = np.random.normal()
self.inputs = [] #待定属性
#前向计算,输入向量dim_before维,输出值
def feedforward(self, inputs):
self.inputs = inputs
z = np.dot(self.weights, self.inputs)
return sigmoid(z)
#层类
class Layer:
'''
-属性,本层神经元数量,上一层神经元数量 #可省略?
-方法:前向计算
'''
def __init__(self, dim, dim_before):
self.dim = dim #前向计算时要用
# self.dim_before = dim_before #可省略?
self.neuron = []
for i in range(dim):
# self.neuron[i] = Neuron(dim_before)
self.neuron.append(Neuron(dim_before))
def feedforward(self, inputs):
out_put = []
for i in range(self.dim):
out_put.append(self.neuron[i].feedforward(inputs))
return out_put
#网络类
class network:
'''
-属性:层维度属性,层数
-激活函数选用sigmoid
-损失函数选用mse
'''
def __init__(self, layer_need, input_dim):
self.lay_num = len(layer_need)
self.layer = []
layer_need.insert(0, input_dim)
for i in range(self.lay_num):
# self.layer[i] = Layer(layer_need[i+1], layer_need[i])
self.layer.append(Layer(layer_need[i+1], layer_need[i]))
def feedforward(self, inputs):
input_n = inputs
output = []
for i in range(self.lay_num):
output = (self.layer[i].feedforward(input_n))
print("layer", i, ':', output)
input_n = output
return output[0]
def train(self, x_data, true_value):
learn_rate = 0.1
epochs = 1
for epoch in range(epochs):
for x, y_true in zip(x_data, true_value):
# 前向计算
pass
#反向传播
#更新参数
#定期查看损失函数
if epoch % 10 == 0:
print()
x = [1, 1]
BPNN = network([2, 1], 2)
# y = BPNN.feedforward(x)
# print(y)
![[pytorch] 7. <span style='color:red;'>神经</span><span style='color:red;'>网络</span><span style='color:red;'>搭</span><span style='color:red;'>建</span>实例](https://img-blog.csdnimg.cn/direct/85c28e9b9abc403c8c41d73735ef8696.png)



























![[云原生] K8s之pod控制器详解](https://img-blog.csdnimg.cn/direct/19d754c9799a4ceb9eef41775f08d1b0.png)