文章目录
-
- 前言
- 参考目录
- 学习笔记
-
- 1:介绍
- 1.1:有向图简介
- 1.2:应用举例
- 1.3:相关问题
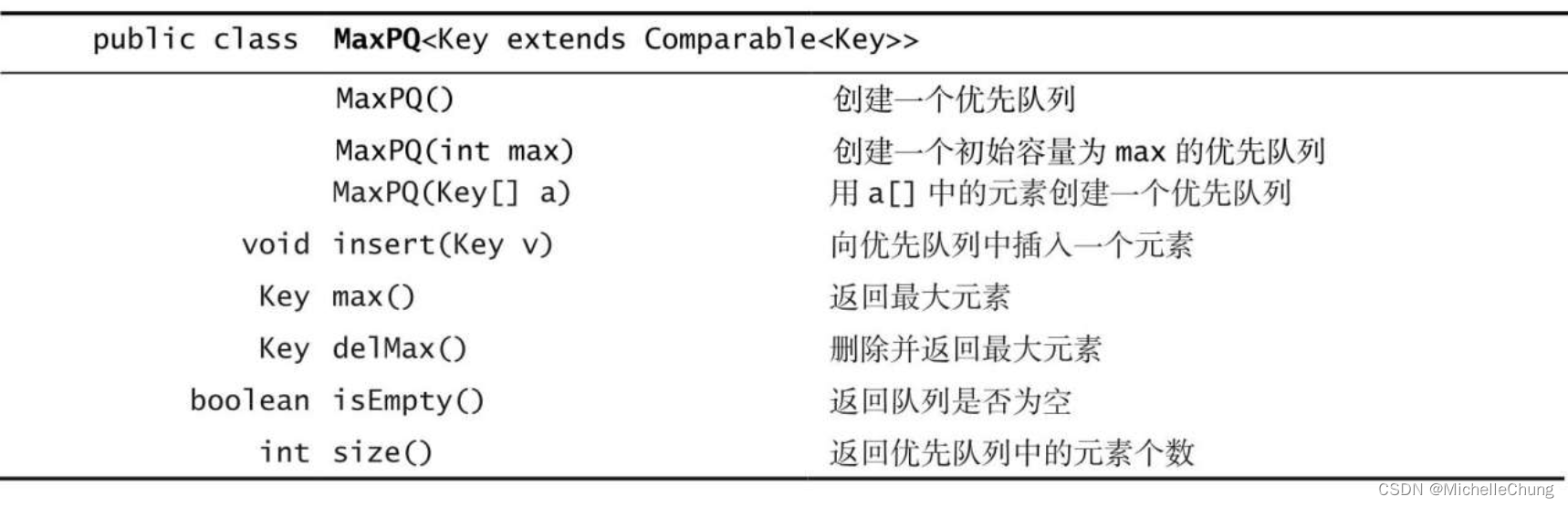
- 2:有向图 API
- 2.1:有向图表示
- 2.1.1:邻接表数组 Adjacency-list
- 2.1.2:Java 实现:邻接表数组
- 2.2:实际应用
- 2.3:小结
- 3:有向图搜索
- 3.1:可达性
- 3.2:深度优先搜索 depth-first search
- 3.2.1:demo 演示
- 3.2.2:Java 实现
- 3.3:可达性应用
- 3.3.1:程序控制流分析
- 3.3.2:标记-清除垃圾回收
- 3.4:小结
- 3.5:广度优先搜索 breadth-first search
- 3.5.1:demo 演示
- 3.5.2:多源最短路径
- 3.6:BFS 应用
- 3.6.1:网络爬虫
- 3.6.2:Java 实现
- 4:拓扑排序 topological sort
- 4.1:定义
- 4.2:demo 演示
- 4.3:Java 实现:DFS 排序
- 4.4:DAG 拓扑排序证明
- 4.5:有向循环检测
- 5:强连通分量 strong components
- 5.1:定义
- 5.2:无向图连通分量 vs. 有向图强连通分量
- 5.3:强连通分量算法简史
- 5.4:Kosaraju-Sharir 算法
- 5.4.1:直觉
- 5.4.2:demo 演示
- 5.4.2.1:第一阶段
- 5.4.2.2:第二阶段
- 5.4.3:过程小结
- 5.4.4:证明
- 5.4.5:Java 实现
- 6:有向图处理小结
前言
本篇主要内容包括:有向图 API、有向图搜索、拓扑排序 以及 强连通分量。
强烈建议在学习本篇之前先行学习或回顾上一篇无向图的内容。
参考目录
- B站 普林斯顿大学《Algorithms》视频课
(请自行搜索。主要以该视频课顺序来进行笔记整理,课程讲述的教授本人是该书原版作者之一 Robert Sedgewick。) - 微信读书《算法(第4版)》
(本文主要内容来自《4.2 有向图》) - 官方网站
(有书本配套的内容以及代码)
学习笔记
注1:下面引用内容如无注明出处,均是书中摘录。
注2:所有 demo 演示均为视频 PPT demo 截图。
注3:如果 PPT 截图中没有翻译,会在下面进行汉化翻译,因为内容比较多,本文不再一一说明。
1:介绍
1.1:有向图简介
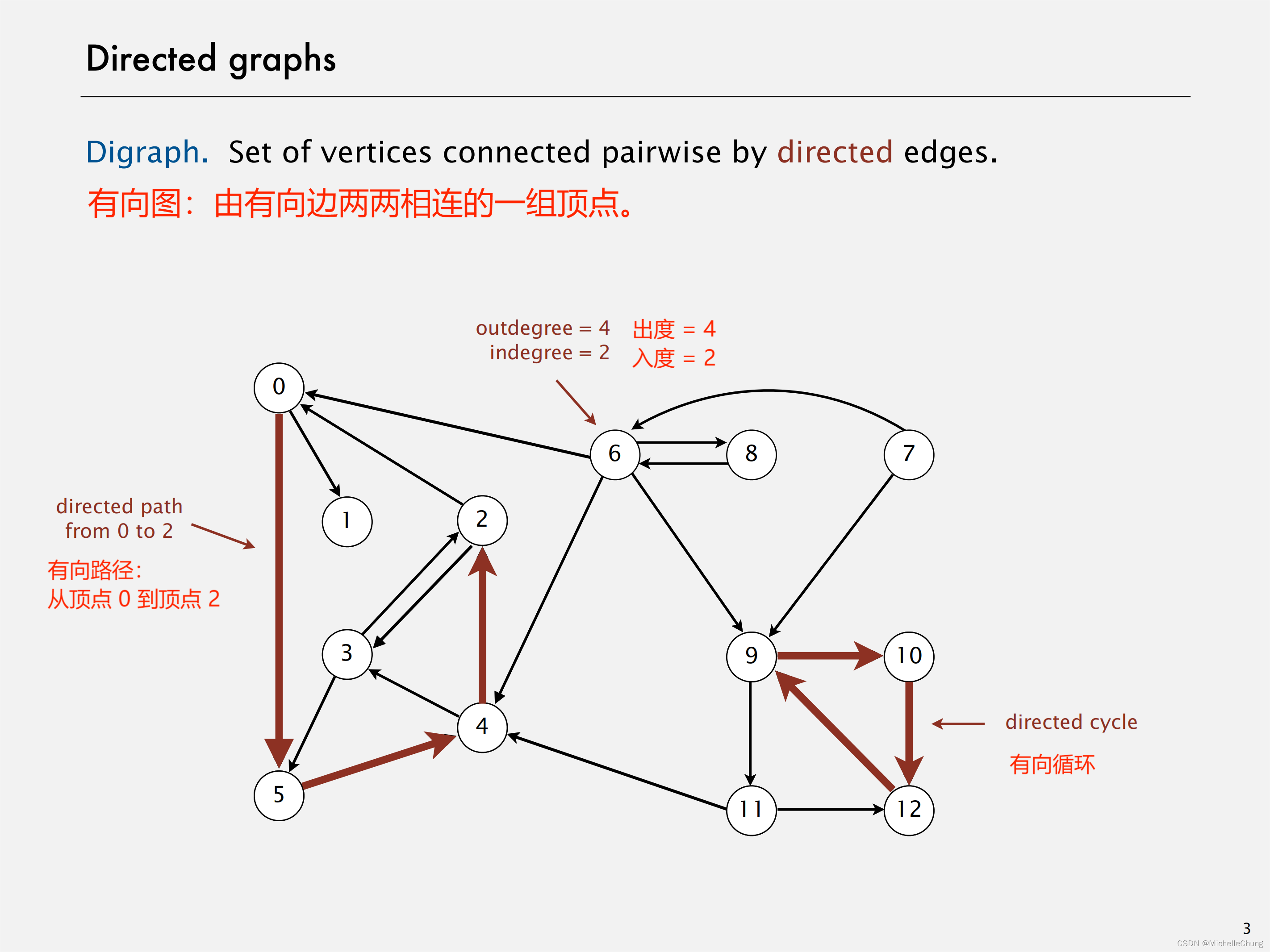
书中有向图图解:
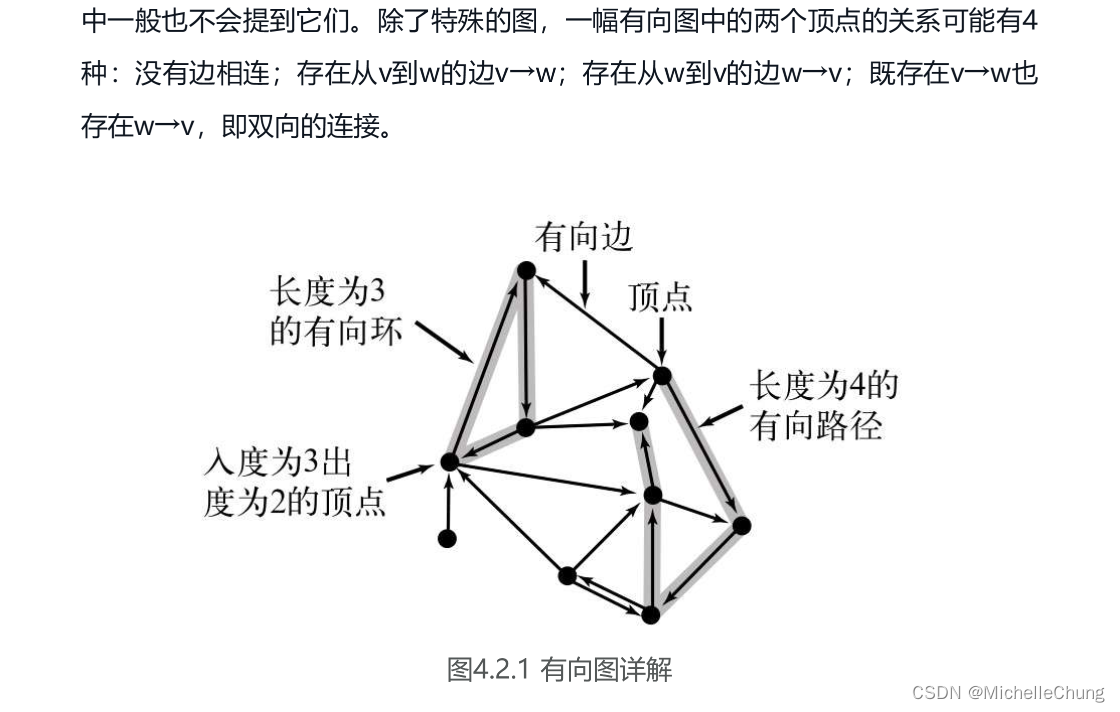
1.2:应用举例

1.3:相关问题
![![L13-42DirectedGraphs_11]](https://img-blog.csdnimg.cn/direct/3b381717da7342d3b7fa4e6677ca339e.png)
| 问题 | 描述 |
|---|---|
| s → t path | 从 s 到 t 的路径是否存在? |
| shortest s → t path | 从 s 到 t 的最短路径是什么? |
| directed cycle | 图中是否存在有向环? |
| topological sort (拓扑排序) | 能否将有向图绘制为所有边都指向上的拓扑排序形式? |
| strong connectivity (强连通性) | 图中任意两点之间是否存在方向任意的有向路径? |
| transitive closure (传递闭包) | 对于哪些顶点 v 和 w,存在从 v 到 w 的有向路径? |
| PageRank (页面排名算法) | 网页的重要性是什么? |
2:有向图 API
![![image-20240307091117855]](https://img-blog.csdnimg.cn/direct/eea54e6dac1741c6af1b1139b5dcfee0.png)
2.1:有向图表示
2.1.1:邻接表数组 Adjacency-list
![![L13-42DirectedGraphs_15]](https://img-blog.csdnimg.cn/direct/22b546abcd6640388bcf9059ea06c132.png)
2.1.2:Java 实现:邻接表数组
(可参考对比无向图 Graph 实现)
edu.princeton.cs.algs4.Digraph
![![image-20240307095043211]](https://img-blog.csdnimg.cn/direct/527962343b014b7da6b73805bf306dc8.png)
edu.princeton.cs.algs4.Digraph#Digraph
![![image-20240307095141935]](https://img-blog.csdnimg.cn/direct/0342f2ec45d64e8f928df73993b59db0.png)
edu.princeton.cs.algs4.Digraph#addEdge
![![image-20240307095232234]](https://img-blog.csdnimg.cn/direct/52b9d2d38e88474bb5e0b2a575975e4a.png)
edu.princeton.cs.algs4.Digraph#adj
![![image-20240307095333624]](https://img-blog.csdnimg.cn/direct/37fd8c7af3cd4e7997dc80e69a246d6b.png)
2.2:实际应用
![![image-20240307095644883]](https://img-blog.csdnimg.cn/direct/89b3c10b9207482dbc920df0e10a8db8.png)
**在实际应用中:**我们采用邻接表的方式来表示图结构。
- 许多算法都是基于从顶点 v 出发逐个遍历其指向的所有其他顶点。
- 实际应用中的有向图数据结构往往具有稀疏特性。(虽然顶点数量可能非常庞大,但平均每个顶点所连接的边数相对较少。)
2.3:小结
![![image-20240307100306896]](https://img-blog.csdnimg.cn/direct/42d25bcd8e08405193e1e8b1dd89ed29.png)
注:边的数组 list of edges 以及 邻接矩阵 adjacency matrix 没有详细说明,可以参考无向图 #2.4 相关内容。
3:有向图搜索
3.1:可达性
![![L13-42DirectedGraphs_20]](https://img-blog.csdnimg.cn/direct/52676e60d04441c3bdfc9b6cad2e62a7.png)
3.2:深度优先搜索 depth-first search
![![L13-42DirectedGraphs_21]](https://img-blog.csdnimg.cn/direct/c849f2c5027e4f20a9f4dd347824381d.png)
与无向图方法相同:
- 每一个无向图都可以视为一个有向图(每条边都有两个方向)。
- 深度优先搜索(DFS)是一个应用于有向图的算法。
3.2.1:demo 演示
![![image-20240308083822573]](https://img-blog.csdnimg.cn/direct/a86f5e8eb72345418e3bc7cef8d1ac60.png)
访问一个顶点 v 时:
- 将顶点 v 标记为已访问状态。
- 递归地访问从顶点 v 出发的所有未标记的顶点。
初始状态:
![![image-20240308084052618]](https://img-blog.csdnimg.cn/direct/cc23ab1aa7b64820b0663dc4c56cce0d.png)
同样地,v 代表顶点,marked[] 保存标记状态,edgeTo[] 保存边信息。
访问第一个顶点 0:
![![image-20240308084405582]](https://img-blog.csdnimg.cn/direct/2be7b5bcd90c4ce0a488046c54edb479.png)
依次检查 与顶点 0 相邻且由此出发所指向的 顶点:分别是 5、1。
检查顶点 5:
![![image-20240308084715158]](https://img-blog.csdnimg.cn/direct/0972b381ae9f4c05b25c4e7ac82ca3c8.png)
检查与顶点 5 相邻且由此出发所指向的顶点:4。
检查顶点 4:
![![image-20240308084900765]](https://img-blog.csdnimg.cn/direct/5e0ddd1608894dea8bf91b7db55fb75b.png)
检查与顶点 4 相邻且由此出发所指向的顶点:分别是 3、2。
检查顶点 3:
![![image-20240308085020730]](https://img-blog.csdnimg.cn/direct/a8a8554dc6034b9ebebf41797483bf80.png)
检查与顶点 3 相邻且由此出发所指向的顶点:分别是 5、2。
检查顶点 5,已经被标记。
检查顶点 2:
![![image-20240308085202510]](https://img-blog.csdnimg.cn/direct/5d7db592a54c43d095be6ccbe0a33c57.png)
检查与顶点 2 相邻且由此出发所指向的顶点:分别是 0、3。
检查顶点 0,已经被标记。
检查顶点 3,已经被标记。
完成顶点 2 的搜索:
![![image-20240308085351466]](https://img-blog.csdnimg.cn/direct/1abdde2697384ffdba521434cdd56abd.png)
返回顶点 3,完成顶点 3 的搜索:
![![image-20240308085516067]](https://img-blog.csdnimg.cn/direct/9173ed2d5bbb42fab47cecced2c10e22.png)
返回顶点 4 继续搜索:
检查顶点 2,已经被标记。
完成顶点 4 的搜索:
![![image-20240308085731886]](https://img-blog.csdnimg.cn/direct/7c6dec08b4f143059e3a48f2a514ab82.png)
返回顶点 5,完成顶点 5 的搜索:
![![image-20240308085811186]](https://img-blog.csdnimg.cn/direct/9eea23d39c824591a9d8ffcfa7295a15.png)
返回顶点 0 继续搜索:
搜索顶点 1,没有需要搜索的相邻节点,完成顶点 1 的搜索:
![![image-20240308085939969]](https://img-blog.csdnimg.cn/direct/61a64d3561964c058770e70f695ee457.png)
完成顶点 0 的搜索:
![![image-20240308090119040]](https://img-blog.csdnimg.cn/direct/9a8699a336e04d82bf07211740107de0.png)
完成了所有顶点 0 可达的顶点搜索:
![![image-20240308090233915]](https://img-blog.csdnimg.cn/direct/361bd81964c545ac87690df87dcd2c3f.png)
3.2.2:Java 实现
(与无向图完全相同,只是替换了方法名称以及对象类型)
edu.princeton.cs.algs4.DirectedDFS
![![image-20240308090856191]](https://img-blog.csdnimg.cn/direct/51d7d7520ba8416680fdf005d6c3fc64.png)
edu.princeton.cs.algs4.DirectedDFS#dfs
![![image-20240308090914605]](https://img-blog.csdnimg.cn/direct/45b40cc35b584bfb911b3a9609b35b90.png)
edu.princeton.cs.algs4.DirectedDFS#marked
![![image-20240308090928992]](https://img-blog.csdnimg.cn/direct/0dec46e783f5436e85cabbe04adced91.png)
3.3:可达性应用
3.3.1:程序控制流分析
![![image-20240308092044359]](https://img-blog.csdnimg.cn/direct/4a5510152e1e427e8ca48953c0cb259b.png)
每个程序都可以表示为一个有向图。
- 顶点(Vertex):表示一组连续执行的指令集(基本块)。
- 边(Edge):表示程序控制流中的跳转关系。
死代码消除。
寻找并移除不可达(永远不会被执行)的代码。
无限循环检测。
判断程序是否存在无法到达退出点的情况。
3.3.2:标记-清除垃圾回收
![![image-20240308092832284]](https://img-blog.csdnimg.cn/direct/b4e6840acb5f419db4f3604c6ced280f.png)
每种数据结构都可以表示为一个有向图。
- 顶点(Vertex):表示对象(Object)。
- 边(Edge):表示引用(Reference)。
根对象(Roots)。
指那些可以直接被程序访问的对象(例如,栈中的对象)。
可达对象(Reachable objects)。
指那些通过程序可以从根对象间接访问到的对象(从某个根开始,沿着一系列指针链进行跟踪)。
![![image-20240308093117066]](https://img-blog.csdnimg.cn/direct/f2605d191170400397bfff93477ee321.png)
标记-清除算法(由麦卡锡于 1960 年提出):
- 标记阶段(Mark):标记所有能够被程序访问到的对象。
- 清除阶段(Sweep):若对象未被标记,则判定其为垃圾对象(从而将它加入到空闲列表中释放)。
内存成本:
该算法对每个对象需要额外占用 1 个标记位,并且还需要使用深度优先搜索栈(这会增加一定的内存开销)。
标记-清除算法 是学习 JVM 的时候一个很重要的算法。
3.4:小结
![![L13-42DirectedGraphs_29]](https://img-blog.csdnimg.cn/direct/94357c1ded9e4b7fb51b99d8fbc96557.png)
深度优先搜索(DFS)能够直接解决一些简单的有向图问题。
- 可达性(判断图中两个顶点间是否存在可达路径。)
- 路径查找(找到一条从起点到终点的路径。)
- 拓扑排序(对有向无环图中的顶点进行排序,使得对于任意指向顶点 u 的边,顶点 u 都在顶点 v 之前。)
- 有向循环检测(判断有向图中是否存在环路。)
深度优先搜索是解决复杂有向图问题的基础方法。
- 二元可满足性问题求解(在逻辑运算中判断给定的布尔公式是否能通过真值赋值使其结果为真的问题。)
- 有向欧拉路径(在有向图中寻找一条经过每条边恰好一次的路径。)
- 强连通分量(识别出有向图中互相可达的所有顶点集合,这些集合内的顶点两两之间都存在可达路径。)
3.5:广度优先搜索 breadth-first search
![![L13-42DirectedGraphs_30]](https://img-blog.csdnimg.cn/direct/0589398baf7a43608e6ef6fd19549058.png)
同样的方法也适用于无向图。
- 每个无向图都可以看作是有向图(每条边都是双向的)。
- 广度优先搜索(BFS)是一种有向图算法。
**命题:**在有向图中,广度优先搜索(BFS)可以在时间复杂度为 O(E+V) 的时间内,计算出从顶点 s 到其他所有顶点的最短路径(即最少边数的路径)。
3.5.1:demo 演示
![![image-20240308112651220]](https://img-blog.csdnimg.cn/direct/fedb6696e12f489fb916180fa0ee056d.png)
重复执行以下操作,直到队列为空:
- 从队列中移除顶点 v。
- 将从顶点 v 出发的所有未标记的顶点加入队列,并将它们标记为已访问。
初始状态:
![![image-20240308112814925]](https://img-blog.csdnimg.cn/direct/e0f0005799104448be72f46cd10363d2.png)
将顶点 0 添加到队列:
![![image-20240308113008940]](https://img-blog.csdnimg.cn/direct/edfdef477d254483b72ea2ca2975c8dd.png)
queue 代表队列,v 代表顶点,edgeTo[] 保存边信息,distTo[] 保存路径长度信息。
顶点 0 出队:
![![image-20240308113155176]](https://img-blog.csdnimg.cn/direct/401dadd3eab14f88b5d090a6950ba85f.png)
需要依次检查 与顶点 0 相邻且由此出发所指向的 顶点:分别是 2、1。
![![image-20240308113313544]](https://img-blog.csdnimg.cn/direct/c4cdd12b293a49719174d9cdfd5adcf1.png)
检查顶点 2:
![![image-20240308113440038]](https://img-blog.csdnimg.cn/direct/451280cd334e4a6caea268e05ee6a803.png)
顶点 2 没有被标记,添加到队列中。
检查顶点 1:
![![image-20240308113515785]](https://img-blog.csdnimg.cn/direct/8a8a64d74a994e3d91aa57ac19a95dc2.png)
顶点 1 没有被标记,添加到队列中。
完成顶点 0 搜索:
![![image-20240308113622358]](https://img-blog.csdnimg.cn/direct/5099e360d87149ef979976b494a6dea7.png)
顶点 2 出队:
![![image-20240308113912866]](https://img-blog.csdnimg.cn/direct/cb9f20678feb4d52aa7e1172ecfa2781.png)
依次检查与顶点 2 相邻且由此出发所指向的顶点:4。
![![image-20240308114040848]](https://img-blog.csdnimg.cn/direct/9f867615789f42059e011356f68e4310.png)
检查顶点 4:
![![image-20240308114137636]](https://img-blog.csdnimg.cn/direct/2180574ef80d489c88577798c501c82a.png)
顶点 4 没有被标记,添加到队列中。
完成顶点 2 搜索:
![![image-20240308114213642]](https://img-blog.csdnimg.cn/direct/d221364c498d4abd84e516d8b2564376.png)
顶点 1 出队:
![![image-20240308114303032]](https://img-blog.csdnimg.cn/direct/cd36420e8ce9476899a97a83ecc1f292.png)
依次检查与顶点 1 相邻且由此出发所指向的顶点:2。
检查顶点 2,已经被标记。
完成顶点 1 搜索:
![![image-20240308114433307]](https://img-blog.csdnimg.cn/direct/22df73111b9a42dd9814f74dc43ffa39.png)
顶点 4 出队:
![![image-20240308114539272]](https://img-blog.csdnimg.cn/direct/e979851300154b62b5b00ac429838afc.png)
依次检查与顶点 4 相邻且由此出发所指向的顶点:3。
![![image-20240308114807806]](https://img-blog.csdnimg.cn/direct/42feca2e13654f70b225107e3031db46.png)
检查顶点 3:
![![image-20240308114855110]](https://img-blog.csdnimg.cn/direct/948d47bf815f4bc6899f4797e8cbf061.png)
顶点 3 没有被标记,添加到队列中。
完成顶点 4 搜索:
![![image-20240308114932405]](https://img-blog.csdnimg.cn/direct/c5808861ff4f4999af3d7e0f59575803.png)
顶点 3 出队:
![![image-20240308115007828]](https://img-blog.csdnimg.cn/direct/10191cdb37034942af30492f4466fe3e.png)
依次检查与顶点 3 相邻且由此出发所指向的顶点:分别是 5、2。
![![image-20240308115112474]](https://img-blog.csdnimg.cn/direct/5f708c7dd6594ebc943262c90112abf8.png)
检查顶点 5:
![![image-20240308115323083]](https://img-blog.csdnimg.cn/direct/cd9af418d8c24ffc9c56fe44bacc0960.png)
顶点 5 没有被标记,添加到队列中。
检查顶点 2,已经被标记。
完成顶点 3 搜索:
![![image-20240308115343655]](https://img-blog.csdnimg.cn/direct/9394f030bea94ffaab947fb37d581d30.png)
顶点 5 出队:
![![image-20240308115449300]](https://img-blog.csdnimg.cn/direct/596f1ad61b554ac88dac59e514c1f908.png)
依次检查与顶点 5 相邻且由此出发所指向的顶点:0。
![![image-20240308115429564]](https://img-blog.csdnimg.cn/direct/31d278047a8d44f899f81d0e84f09715.png)
检查顶点 0,已经被标记。
完成顶点 5 搜索:
![![image-20240308115515870]](https://img-blog.csdnimg.cn/direct/119019c6516c44c9960139b18a3a6246.png)
完成所有搜索:
![![image-20240308115548973]](https://img-blog.csdnimg.cn/direct/e191c7ab068944ac9db45bda654a25fe.png)
3.5.2:多源最短路径
![![L13-42DirectedGraphs_33]](https://img-blog.csdnimg.cn/direct/83b6613e1de04645b7999b9e5c7cbd30.png)
多源最短路径
给定一个有向图和一组起点顶点,找出从该组任意起点顶点到图中其他所有顶点的最短路径。
Q. 如何实现多源最短路径算法?
A. 可以使用广度优先搜索(BFS),但是在初始化时,将所有源顶点都入队列。 (具体做法是首先将所有指定的源顶点放入队列中作为搜索的起点,然后按照广度优先搜索的规则依次遍历图中的其他顶点,逐步计算出从各个源顶点到图中所有其他顶点的最短路径。)
3.6:BFS 应用
3.6.1:网络爬虫
![![L13-42DirectedGraphs_34]](https://img-blog.csdnimg.cn/direct/b3e81dadc0da42a18cb9b79b0674a1b2.png)
**目标:**从某一指定的根网页(例如www.princeton.edu)出发爬取整个网站。
**解决方案:**使用 广度优先搜索(BFS) 算法隐式构建的有向图 进行爬取。
步骤如下:
- 将根网页设为源节点
s。 - 维护一个用于存储待探索网站的 队列(Queue)。
- 维护一个记录已发现网站的 集合(SET),用于去重。
- 从队列中取出下一个网站,并检查其指向的所有链接所对应的网站(前提是这些网站尚未被添加进队列或集合中)。
- 如果某个链接指向的网站还未被发现,则将其加入队列。
- 同时将新发现的网站添加到已发现网站的集合中,确保不会重复抓取同一网站。
Q. 为什么不用 DFS 实现?
(利用通义千问总结一下) 网络爬虫的实现通常首选广度优先搜索(BFS)而不是深度优先搜索(DFS)的原因在于以下几个关键因素:
- 短路径优先:
- BFS 保证爬虫首先遍历到的是离起始网页最近的网页,因此对于寻找最短路径的情况非常有利。在网络爬虫场景下,如果目的是快速抓取到尽可能接近种子 URL 的网页,BFS 能够找到从起始网页到任意页面的最短跳转路径。
- 更全面的初始层级覆盖:
- BFS 逐层遍历,能更均匀地抓取同一层级上的所有链接,这对于初步建立网站的拓扑结构、索引和导航结构的初步构建十分有效,能够迅速获取到一个网站的第一层链接资源。
- 避免过深探索:
- DFS 可能会导致爬虫陷入深层次且可能不是特别重要的链接结构中,而忽视了其他重要性较高的较浅层次页面。尤其是在没有合理剪枝策略的情况下,DFS 可能导致爬虫在某一分支上耗费过多资源,而忽略了其他可能更重要的部分。
- 减少重复爬取:
- BFS 通过维护一个已经访问过的网页集合(通常是哈希表),能够有效地避免爬虫反复进入同一个网页的多个入口,减少了不必要的重复抓取。
- 反映网页的重要性:
- 在某些基于链接流行度的评价体系中,入链数量往往代表了一定程度上的网页重要性。BFS 倾向于先抓取那些有更多的入链(即被更多网页链接到的网页),这在一定程度上符合优先抓取重要网页的需求。
综上所述,网络爬虫采用 BFS 作为基础遍历策略,能够更好地满足实际应用中的需求,如高效地获取范围广泛的链接、平衡地抓取不同层次的内容以及减少不必要开销等。当然,具体实现时根据任务的具体要求,有时候也会结合 DFS 或其他策略来优化爬虫的行为。
3.6.2:Java 实现
![![L13-42DirectedGraphs_35]](https://img-blog.csdnimg.cn/direct/9b8d0e14fa594b7f80aa1c31c7e48c69.png)
4:拓扑排序 topological sort
4.1:定义
![![L13-42DirectedGraphs_39]](https://img-blog.csdnimg.cn/direct/8953297396bb4365b97e0196f81761f4.png)
4.2:demo 演示
![![image-20240309124401947]](https://img-blog.csdnimg.cn/direct/64154c0fd58e4c609d68c8cec17333b8.png)
- 执行深度优先搜索
- 按逆后序返回顶点
初始状态:
![![image-20240309124627112]](https://img-blog.csdnimg.cn/direct/26b9246358304918a87bd490f7144daf.png)
访问第一个顶点 0:
![![image-20240309124957020]](https://img-blog.csdnimg.cn/direct/b3b89b0527be4664ad6fd1be1864fe97.png)
依次检查相邻顶点:1、2、5。
检查顶点 1:
![![image-20240309125144970]](https://img-blog.csdnimg.cn/direct/00f1e1717fe24be3b1d6340db71b3908.png)
检查相邻顶点:4。
检查顶点 4:
![![image-20240309125252832]](https://img-blog.csdnimg.cn/direct/bc868c05c4414f839443a72de511a063.png)
顶点 4 没有出度,完成搜索并加入堆栈(后序 postorder):
![![image-20240309125515783]](https://img-blog.csdnimg.cn/direct/d732132fd2994bccb3b008e6a6fcb1db.png)
返回顶点 1,完成搜索并加入后序:
![![image-20240309125720202]](https://img-blog.csdnimg.cn/direct/4a41939c6cc34d4190f9d39814c86d4b.png)
返回顶点 0 继续搜索。
检查顶点 2:
![![image-20240309132239841]](https://img-blog.csdnimg.cn/direct/bc06a9f356ec442f8baee6acfbc78a42.png)
顶点 2 没有出度,完成搜索并加入后序:
![![image-20240309132322686]](https://img-blog.csdnimg.cn/direct/2e4131b1d77e4b1c9d1c8d18b0c0ede3.png)
返回顶点 0 继续搜索。
检查顶点 5:
![![image-20240309132404455]](https://img-blog.csdnimg.cn/direct/343b1aa8cd434cb09fe71dee72d9e39a.png)
检查顶点 2,已经被标记。
顶点 5 完成搜索并加入后序:
![![image-20240309132510999]](https://img-blog.csdnimg.cn/direct/6b54e72d58574b33b9328cf932020002.png)
完成顶点 0 的搜索并加入后序:
![![image-20240309132602881]](https://img-blog.csdnimg.cn/direct/14916de564204fa9bdf217ac042c4e1e.png)
按顺序检查其他未标记顶点。
顶点 1、2 已经被标记,检查顶点 3:
![![image-20240309132929427]](https://img-blog.csdnimg.cn/direct/edb32f6248304d08b109a0c0fa425ad0.png)
依次检查相邻顶点:2、4、5、6。
检查顶点 2,已经被标记。
检查顶点 4,已经被标记。
检查顶点 5,已经被标记。
检查顶点 6:
![![image-20240309133145225]](https://img-blog.csdnimg.cn/direct/7e2e49b0e2a548df96d4eca17b39aad6.png)
检查相邻顶点:0、4。
检查顶点 0,已经被标记。
检查顶点 4,已经被标记。
完成顶点 6 的搜索并加入后序:
![![image-20240309133254279]](https://img-blog.csdnimg.cn/direct/b920121477ce47a5976a5da4023ab744.png)
完成顶点 3 的搜索并加入后序:
![![image-20240309133329349]](https://img-blog.csdnimg.cn/direct/5c19db1c853a400da64b64108c5cd5cb.png)
完成所有顶点搜索。
4.3:Java 实现:DFS 排序
edu.princeton.cs.algs4.DepthFirstOrder
![![image-20240309134132609]](https://img-blog.csdnimg.cn/direct/7c38e5d433b64d198bfc1376953baea8.png)
edu.princeton.cs.algs4.DepthFirstOrder#dfs
![![image-20240309134209810]](https://img-blog.csdnimg.cn/direct/58a1f385a70341ce9a904b495f0dbea8.png)
edu.princeton.cs.algs4.DepthFirstOrder#reversePost
![![image-20240309134249391]](https://img-blog.csdnimg.cn/direct/158b3b28c62f4b0d97b8be8953d22bb2.png)
4.4:DAG 拓扑排序证明
![![L13-42DirectedGraphs_44]](https://img-blog.csdnimg.cn/direct/a44ab28460ca46ed82a48562894fb8f2.png)
对应书本命题 F:
图4.2.11 有向无环图的逆后序是拓扑排序
![![image-20240309134810658]](https://img-blog.csdnimg.cn/direct/46f4167b07354ecca730e6da02234893.png)
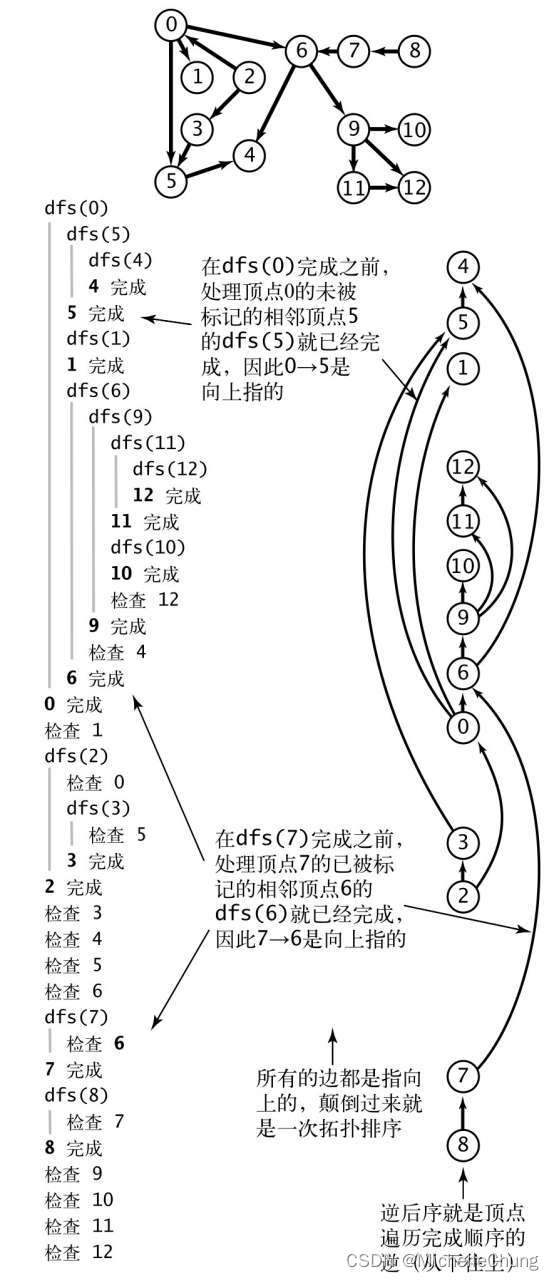
4.5:有向循环检测
![![L13-42DirectedGraphs_45]](https://img-blog.csdnimg.cn/direct/abff636783794a979e5ea5c252c9626b.png)
**命题:**一个有向图存在拓扑排序当且仅当它不含任何有向环。
证明:
- 若存在有向环,则无法构造拓扑排序。
- 若不存在有向环,则基于深度优先搜索(DFS)的算法能够找到一个拓扑排序。
5:强连通分量 strong components
5.1:定义
(PPT 和书本内容一致,直接把书本的内容贴出来)
定义:
![![image-20240309141811365]](https://img-blog.csdnimg.cn/direct/bc8956429aa14cbdab10f0d54b7ccd78.png)
性质:
![![image-20240309141859632]](https://img-blog.csdnimg.cn/direct/373c91f388994358ae539dc080bd5962.png)
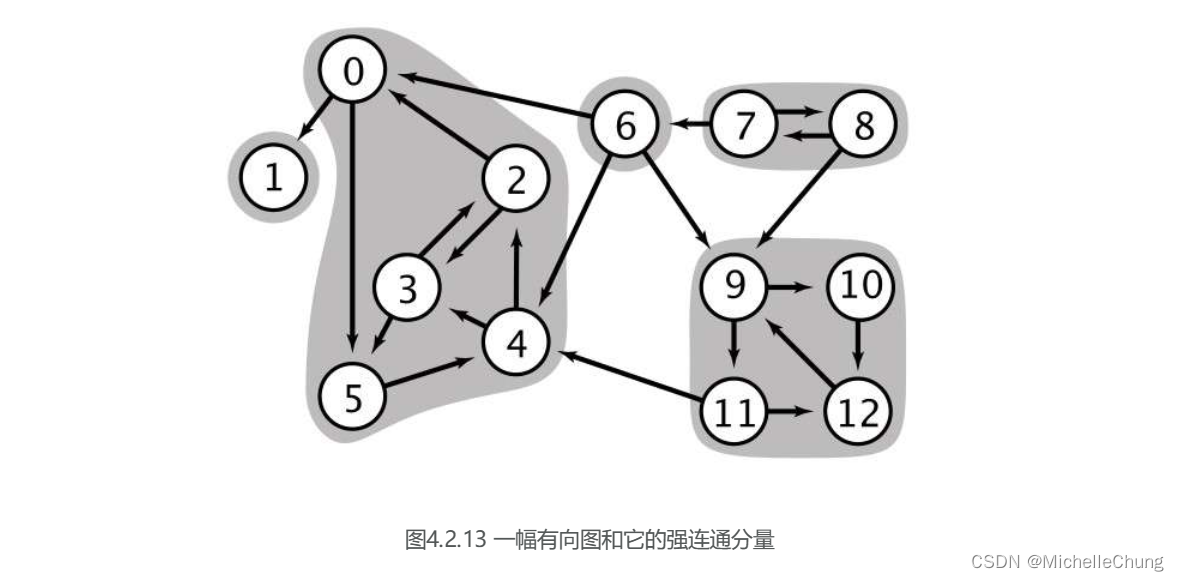
5.2:无向图连通分量 vs. 有向图强连通分量
![![L13-42DirectedGraphs_52]](https://img-blog.csdnimg.cn/direct/68c93db2bf8540faa926f65b040113c3.png)
5.3:强连通分量算法简史
![![L13-42DirectedGraphs_55]](https://img-blog.csdnimg.cn/direct/af14101d4abe4716bddf2ba3c01e3878.png)
1960年代:核心运筹学问题。
- 广泛研究,出现了一些实用算法。
- 其复杂性尚未被充分理解。
1972年:线性时间的深度优先搜索(DFS)算法(由 Tarjan 提出)。
- 经典算法,在算法领域占有重要地位。
- 算法难度级别相当于“Algs4 进阶版”。
- 显示了深度优先搜索在广泛应用场景下的重要性和实用性。
1980年代:简易两遍线性时间算法(Kosaraju-Sharir 算法)。
- 教授课程时忘记带讲义,为了授课临时开发出该算法!
- 后来发现该算法实际上在 1972 年的俄罗斯科学文献中已有记载。
1990年代:更多简易的线性时间算法出现。
- Gabow 改进了原有的运筹学算法。
- Cheriyan 和 Mehlhorn 设计了一种单遍线性时间算法,这是 LEDA 项目所需的关键技术。
Prof. Sedgewick 总结:
So this story indicates, even from fundamental problems in graph processing, there’s algorithms out there still waiting to be discovered. And this algorithm is a good example of that.
因此,这个故事表明,即使在图形处理的基本问题中,仍然存在有待发现的算法。而上述提到的算法恰好是一个很好的例子。
5.4:Kosaraju-Sharir 算法
5.4.1:直觉
![![L13-42DirectedGraphs_56]](https://img-blog.csdnimg.cn/direct/29dfded9321f4624ba6cd574a78645bb.png)
**反向图:**原图 G 中的强连通分量与反向图 GR 中的相同。
**核 DAG(Kernel DAG):**将每个强连通分量收缩成单个顶点。
思路:
- 在核 DAG 中计算拓扑排序(采用逆后序)。
- 以逆拓扑顺序考虑顶点,并运行深度优先搜索(DFS)。
书中的描述:
![![image-20240309145233298]](https://img-blog.csdnimg.cn/direct/ec072239499f4576929ec33dd4f51c78.png)
5.4.2:demo 演示
![![image-20240309145412029]](https://img-blog.csdnimg.cn/direct/ec1fc5b473324727bf885e91481fa6e6.png)
阶段1: 在 GR 图中计算逆后序排列。
阶段2: 在 G 图中运行深度优先搜索,按照 GR 图中的逆后序排列顺序访问未标记的顶点。
初始状态:
![![image-20240309145554570]](https://img-blog.csdnimg.cn/direct/b62078d676134026a4a56a3b8287a195.png)
5.4.2.1:第一阶段
在反向图 GR 图中计算逆后序排列。
反向图 GR:
![![image-20240309150628583]](https://img-blog.csdnimg.cn/direct/3d14a061c0c845f5b2d7e078ab7cf62b.png)
逆后序排列演示在前面拓扑排序刚说完,就不一一截图了,大致搜索过程如下(* 粗体 代表搜索完成放入后序):
0 —— 6 —— 8
8 —— 6 —— 7
7 —— 6
6 —— 0 —— 2 —— 4 —— 11 —— 9 —— 12 —— 10
10 —— 12
12 —— 9
9 —— 11
11 —— 4 —— 5 —— 3
3 —— 5
5 —— 4
4 —— 2
2 —— 0
1
检查确保所有顶点都已经被标记。
第一阶段结束后的结果:
![![L13-42DirectedGraphs_58]](https://img-blog.csdnimg.cn/direct/ab552340992244958971d3675b7f312e.png)
5.4.2.2:第二阶段
在 G 图中运行深度优先搜索,按照 GR 图中的逆后序排列顺序访问未标记的顶点。
原始图 G:
![![image-20240309151559229]](https://img-blog.csdnimg.cn/direct/b5663f5f82be40a48ec5e5fabb8bb930.png)
以第一阶段结果 1 0 2 4 5 3 11 9 12 10 6 7 8 进行搜索。
搜索顶点 1:
![![image-20240309151936900]](https://img-blog.csdnimg.cn/direct/e588efcc80d443a8ab8a9a43466bc0c6.png)
没有其他顶点,强连通分量编号标记为 0,完成搜索。
![![image-20240309152114934]](https://img-blog.csdnimg.cn/direct/1236d12cb20c417ca1d35e2cf6e01a5b.png)
同理,搜索其他分量,大致过程如下:
0 —— 5 —— 4 —— 3 —— 2
![![image-20240309152415181]](https://img-blog.csdnimg.cn/direct/d3305864e248474a952b9456678e4e04.png)
顶点 0、2、3、4、5 为强连通分量,标记为 1。
11 —— 12 —— 9 —— 10
![![image-20240309152706706]](https://img-blog.csdnimg.cn/direct/94b8c4a2a52a420a8d02d372a8d4d638.png)
顶点 9、10、11、12 为强连通分量,标记为 2。
6 —— 8
![![image-20240309153115846]](https://img-blog.csdnimg.cn/direct/c4d8ba6c188546b7b9f7ecb14d285912.png)
顶点 6、8 为强连通分量,标记为 3。
7
![![image-20240309153139893]](https://img-blog.csdnimg.cn/direct/81c9c90a81db4fd5a9f7b051631c47d2.png)
顶点 7 为强连通分量,标记为 4。
完成所有的连通分量查询:
![![L13-42DirectedGraphs_59]](https://img-blog.csdnimg.cn/direct/749998d1cdc04dbca91d4594edb2b24d.png)
5.4.3:过程小结
Kosaraju-Sharir 算法:计算强连通分量的简单(但神秘)算法。
![![L13-42DirectedGraphs_60]](https://img-blog.csdnimg.cn/direct/be7234a8d1774992bf6b0d3d70f76c74.png)
![![L13-42DirectedGraphs_61]](https://img-blog.csdnimg.cn/direct/794e0ec4ca9a450cb971ea61c9734947.png)
5.4.4:证明
![![image-20240309153852150]](https://img-blog.csdnimg.cn/direct/709ed95d201a422fb25414fd99fd8db9.png)
证明具有一定的数学复杂性,但编码实现非常简单。
5.4.5:Java 实现
edu.princeton.cs.algs4.KosarajuSharirSCC
![![image-20240309154159062]](https://img-blog.csdnimg.cn/direct/085ebfe773064282874399543d2f055e.png)
![![image-20240309154252073]](https://img-blog.csdnimg.cn/direct/0bde7b57b5ce4636a04c8b9938c07188.png)
edu.princeton.cs.algs4.KosarajuSharirSCC#dfs
![![image-20240309154328483]](https://img-blog.csdnimg.cn/direct/6983f1121dee40babcf29529001a54d7.png)
edu.princeton.cs.algs4.KosarajuSharirSCC#stronglyConnected
![![image-20240309154408874]](https://img-blog.csdnimg.cn/direct/529ef8c6b7cf4f3b801dca6b1a8e3204.png)
6:有向图处理小结
![![L13-42DirectedGraphs_65]](https://img-blog.csdnimg.cn/direct/fc3c8bed19144a958d71739ec72bb2c0.png)
(完)































![[R] Underline your idea with ggplot2](https://img-blog.csdnimg.cn/direct/5314ed386de044c09348425c59ec15e3.png)



