递归神经网络(RNN, Recurrent Neural Networks)是一类用于处理序列数据的神经网络,特别适合于时间序列数据、语音、文本等连续数据的处理。RNN之所以独特,是因为它们在模型内部维持一个隐藏状态,该状态理论上可以捕获到目前为止所观察到的所有信息。然而,标准RNN在处理长序列时面临梯度消失或梯度爆炸的问题,这限制了它们捕获长期依赖的能力。为了克服这些限制,提出了两种主要的RNN变体:长短期记忆网络(LSTM)和门控循环单元(GRU)。
递归神经网络(RNN)
基本原理
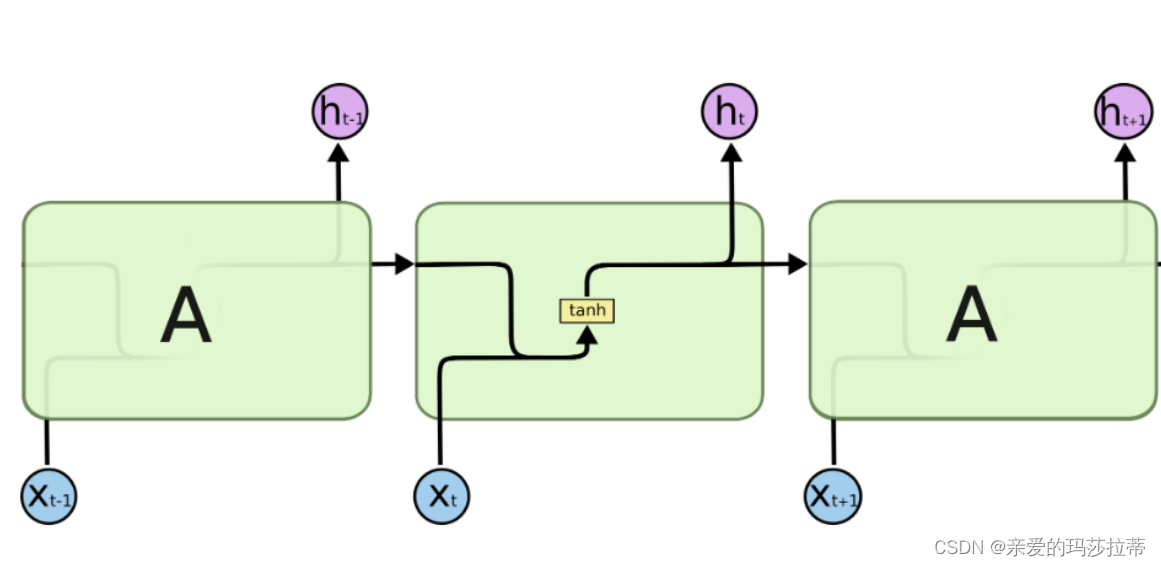
RNN通过在每一个时间步上接收输入并更新其内部状态来工作,这个内部状态是对之前步骤的记忆。基本RNN有一个非常简单的结构,包括一个隐藏层和一个输出层。隐藏层在不同时间步上对同一输入进行处理时,会保留一个状态向量,这个状态向量包含了之前时间步的信息。
问题
虽然RNN理论上可以处理任何长度的序列,但在实践中,当处理长序列数据时,会遇到梯度消失或梯度爆炸的问题,这使得模型难以学习和保持长期的依赖关系。
长短期记忆网络(LSTM)
设计
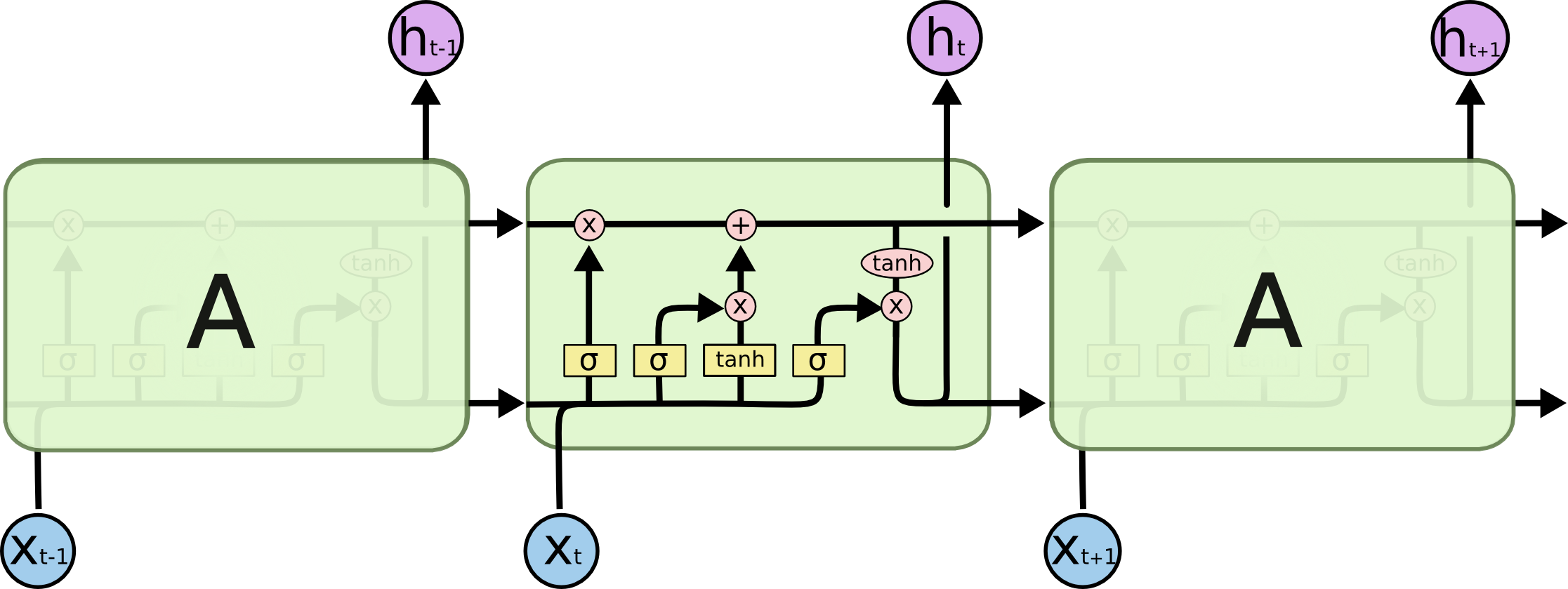
LSTM是一种特殊的RNN,旨在解决标准RNN无法处理长期依赖的问题。LSTM引入了三个门(输入门、遗忘门和输出门)和一个细胞状态,这些机制帮助它在长序列中保持和更新记忆。
- 输入门:决定哪些新的信息被添加到细胞状态中。
- 遗忘门:决定哪些旧的信息需要从细胞状态中丢弃。
- 输出门:决定细胞状态的哪一部分将被用在输出中。
优势
LSTM通过这些门结构有效地保持和更新长期和短期的记忆,使其能够捕获长距离的依赖关系。
门控循环单元(GRU)
设计
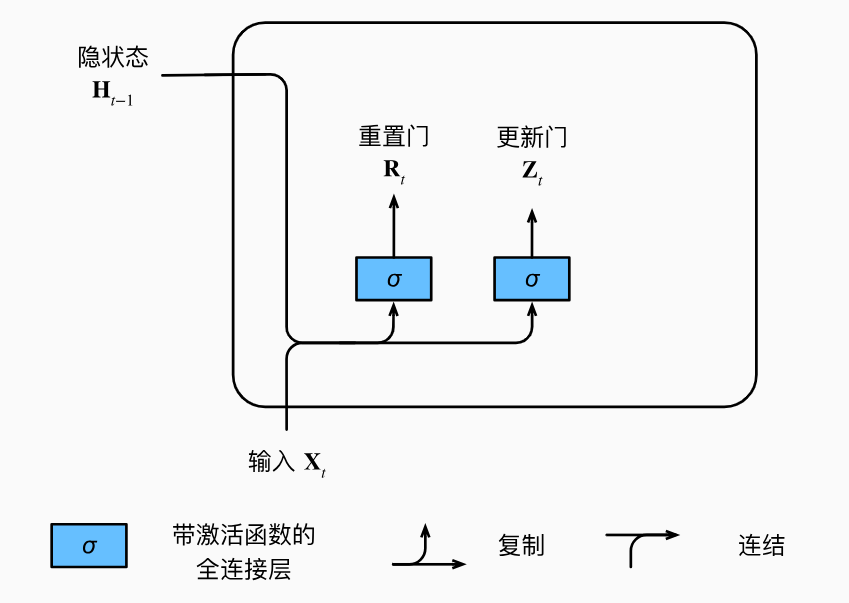
GRU是LSTM的一个变体,旨在简化LSTM的模型结构,同时保持LSTM处理长期依赖的能力。GRU合并了LSTM的遗忘门和输入门成为一个单独的更新门,并且将细胞状态和隐藏状态合并。
- 更新门:决定保留多少之前的记忆信息。
- 重置门:决定如何结合新的输入信息和之前的记忆信息。
优势
GRU相对于LSTM有更简单的结构,计算效率更高,训练时间更短,在很多任务中,GRU的表现与LSTM相似,有时甚至更好。
应用
RNN及其变体广泛应用于自然语言处理(NLP)、语音识别、时间序列预测等领域。它们能够处理和生成序列数据,使得它们非常适合于语言翻译、情感分析、文本生成、股票价格预测等任务。
总结而言,RNN及其变体LSTM和GRU是深度学习中处理序列数据的强大工具,通过引入记忆机制,它们能够学习到数据中的长期依赖关系,解决了传统RNN面临的挑战,为复杂序列任务的解决提供了有效的方法。