数据
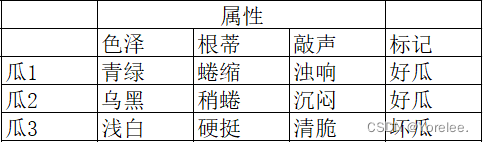
数据是机器学习的基础,包括训练数据和测试数据。训练数据是机器学习模型用来学习的“案例”,而测试数据则是用来检验模型性能的数据。这些数据可以是数字、文本、图像或视频等多种形式
模型
模型是机器学习的核心,可以理解为模拟现实世界的一个统计模型,用来描述数据之间的关系和规律。机器学习算法从数据中学习“经验”,并将这些经验转化为模型。常见的机器学习模型有线性回归、逻辑回归、支持向量机、决策树、随机森林和神经网络等。
算法
算法是机器学习的基础框架,它是指运用数据和模型进行推理和预测的一系列数学方法。这些算法通过优化模型参数,实现对未知数据的分类、聚类、回归、降维等操作。
特征
特征是从数据中提取出来的有用信息,用于描述数据的属性和特点。机器学习算法通过分析和学习这些特征,来发现数据中的规律和模式。
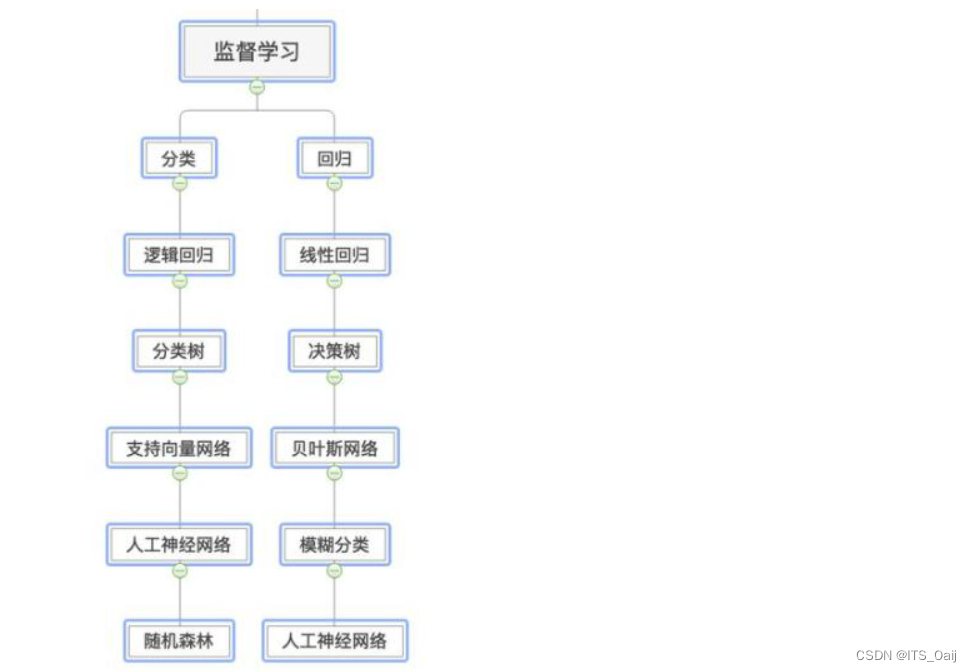
监督学习
监督学习是机器学习中最常见且应用最广泛的学习方法之一。在监督学习中,我们有一组带有已知标签的训练数据。这些数据通常是以输入-输出对的形式呈现,其中输入是特征向量,输出是对应的标签或目标值。模型通过学习这些输入-输出对之间的关系,试图预测新数据的输出。常见的监督学习算法包括线性回归、逻辑回归、支持向量机、决策树和神经网络等。监督学习广泛应用于分类、回归和预测任务,如图像识别、语音识别、股票价格预测等。
无监督学习
与监督学习不同,无监督学习处理的是没有标签的数据。无监督学习的目标是从数据中发现内在的结构或模式。聚类是无监督学习的一个典型应用,它将相似的对象组织在一起形成不同的群组。此外,无监督学习还包括降维技术,如主成分分析(PCA),用于减少数据的维度并提取关键特征。无监督学习在数据探索、异常检测、图像分割等方面有广泛应用,如社交网络分析、客户细分和图像预处理等。
半监督学习
半监督学习是介于监督学习和无监督学习之间的一种学习方法。在实际情况中,标记数据的获取成本可能很高,而无标记数据则相对容易获取。半监督学习旨在利用少量的标记数据和大量的未标记数据来提高模型的性能。它结合了监督学习和无监督学习的思想,通过利用未标记数据中的信息来辅助模型的训练。半监督学习在标记数据有限或获取标签成本较高的情况下特别有用,如图像标注和文本分类等任务。
强化学习
强化学习是一种通过智能体与环境交互来学习策略的方法。在强化学习中,智能体通过观察环境并执行动作来收集奖励信号,然后根据这些信号调整其策略以最大化长期回报或达到特定目标。强化学习不依赖于静态的标记数据,而是通过不断的试错和反馈来学习。它广泛应用于序列决策问题,如机器人控制、游戏AI和自动驾驶等。强化学习使智能体能够在复杂和不确定的环境中自主地进行决策,并适应不断变化的条件。
假设空间
是机器学习算法可以生成的所有函数的集合,通俗来说,就是样本所有可能性的集合。具体来说,机器学习中的监督学习任务是学习一个模型,使模型能够对任意给定的输入,对其相应的输出做出一个好的预测。这个模型属于由输入空间到输出空间的映射的集合,这个集合就是假设空间。
版本空间
版本空间(Version Space)是概念学习中与已知数据集一致的所有假设(Hypothesis)的子集集合。
通俗来说,版本空间是机器学习过程中,与已知数据集相匹配的一系列可能假设的集合。在机器学习中,我们通常有一个已知的数据集,这个数据集包含了一系列的输入和对应的输出。我们的目标是找到一个模型或函数,能够准确地根据输入预测输出。
版本空间就是这样一个“模型或函数的候选名单”。这个名单上的每一个“候选人”(即假设)都能很好地解释或预测数据集里的数据。换句话说,当我们用这些假设去预测数据集中的输出时,预测结果和实际结果是一致的。
归纳偏好
归纳偏好(inductive bias)是指算法在学习过程中对某种类型假设的偏好。换句话说,当机器学习算法面临多种可能的模型或假设时,归纳偏好帮助算法确定选择哪一个假设作为最终的模型。
在机器学习中,算法需要在众多的假设中选择一个最优的模型。这些假设构成了假设空间,而归纳偏好就是算法在假设空间中选择模型的一种倾向性。例如,有的算法可能偏好尽可能特殊的模型,而有的算法则可能偏好尽可能一般的模型。这种偏好可以帮助算法在面对新数据时,做出更准确的预测或分类。
免费的午餐定理
免费的午餐定理(No Free Lunch Theorem,简称NFL定理),NFL定理的核心思想是:在所有可能的问题实例上,所有优化算法在平均情况下都具有相同的性能。换句话说,没有一种通用的优化算法能在所有问题上表现得比其他算法更好。
通俗地说,NFL定理证明了任何模型在所有问题上的性能都是相同的,其总误差和模型本身是没有关系的。每一种问题出现的概率是均等的,每个模型用于解决所有问题时,其平均意义上的性能是一样的。
因此,在机器学习中,没有一种“免费的午餐”算法,即没有一种算法可以无需关注问题的特性而在所有问题上都表现得很好。这个定理强调了选择适当的算法和问题建模方法的重要性。