目录
两个对象的hashcode一样那么equals一定一样吗?&& 两个对象的equals一样那么hashcode一定一样吗?
HashMap m = new HashMap<>底层数组多大?
HashMap m = new HashMap<25>底层数组多大?
一、概念
哈希算法与哈希表
- 哈希算法就是把任意长度的输入通过散列算法变为固定长度的输出,这个输出的结果就是散列值。
- 哈希表也叫做散列表,他是通过key直接访问在内存存储位置的数据结构,在具体实现上,我们通过哈希函数把key映射到表中的某个位置,来获取这个位置的数据从而加快查询速度
- 哈希冲突是由于哈希算法被计算的数据是无限的,而计算后的结果范围有限,所以会出现不同数据经过计算后得到的散列值相同
二、哈希碰撞与解决
解决哈希冲突的四种方法
- 开发地址法:也叫线性探测法,就是从发生哈希冲突的位置开始按照一定的顺序依次此功能哈希表中找到一个空闲位置将该元素存储。
- 链式寻址法:将存在哈希冲突的key,以单向链表的方式来存储。
- 再哈希法:当通过某个哈希函数计算出现冲突后,再使用另一个哈希函数计算散列值,直到不出现冲突为止。这种方法会增加计算时间,性能影响比较大
- 建立公共溢出区:将哈希表分为基本表与溢出表两个部分,出现哈希冲突的元素一律存放到溢出表中
HashMap解决哈希冲突
在jdk1.8版本中他是使用链式寻址法+红黑树解决哈希冲突问题的,其中红黑树是为了优化由于链表过长导致查询时间复杂度增加的问题,当数组长度超过64且单链表元素大于等于8时就会转变为红黑树
三、代码实现
public class HashMap <K, V>{
// 节点
static class Node<K, V> {
K key;
V val;
public Node<K, V> next;
public Node(K key, V val) {
this.key = key;
this.val = val;
}
}
// 底层数组
private Node<K, V>[] elem = new Node[16];
// 元素个数
private int size;
// 负载因子
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
public boolean put(K key, V data) {
// 计算所在哈希桶
int index = key.hashCode() % this.elem.length;
// 遍历该哈希桶内链表
Node<K, V> cur = this.elem[index];
while (cur != null) {
// 如果已经存在key,就替换
if (cur.key.equals(key)) {
cur.val = data;
return false;
}
cur = cur.next;
}
// 如果没有就进行头插
Node<K, V> node = new Node<>(key, data);
node.next = this.elem[index];
this.elem[index] = node;
this.size++;
// 计算是否需要扩容
if (this.size >= this.elem.length * DEFAULT_LOAD_FACTOR) grow();
return true;
}
public V get(K key) {
// 计算下标
int index = key.hashCode() % this.elem.length;
// 开始遍历寻找
Node<K, V> cur = this.elem[index];
while (cur != null) {
if (cur.key.equals(key)) {
return cur.val;
}
cur = cur.next;
}
return null;
}
private void grow() {
// 扩容
Node<K, V>[] nodes = new Node[this.elem.length * 2];
// 遍历原哈希表,由于计算元素所在哈希桶的规则随着数组长度变化而发生了改变所以将数据进行重新哈希
for (int i = 0; i < this.size; i++) {
Node<K, V> cur = this.elem[i];
while (cur != null) {
int index = cur.key.hashCode() % nodes.length;
Node<K, V> next = cur.next;
cur.next = nodes[index];
nodes[index] = cur;
cur = next;
}
}
// 完成扩容
this.elem = nodes;
}
public static void main(String[] args) {
HashMap<Integer, Integer> map = new HashMap<>();
map.put(1,1);
map.put(222,1);
map.put(333,1);
map.put(1,111111111);
map.put(22222,12);
System.out.println(map.get(1));
}
}
四、HashMap面试题
两个对象的hashcode一样那么equals一定一样吗?&& 两个对象的equals一样那么hashcode一定一样吗?
两个对象的hashCode相同,并不意味着它们的equals方法返回值一定相同。具体分析如下:
- hashCode的设计初衷:是为了提高哈希表等数据结构的性能,而equals方法则是用来比较两个对象是否在逻辑上相等。在Java中,如果两个对象通过equals()方法比较结果为true,那么这两个对象的hashCode()方法必须返回相同的值;反之,如果两个对象的hashCode()相同,并不意味着这两个对象就一定是相等的。
- 重写equals和hashCode的影响:当开发者在自定义类时重写了equals()方法和hashCode()方法,并且没有遵循正确的契约(即equals()为true时,hashCode()必须相同),就可能导致hashCode相同但equals不相同的情况出现。这通常是因为重写的方法中比较了不同的属性或使用了不同的逻辑。
- hashCode的冲突:即便是两个不相等的对象,它们的hashCode也可能会相同,这种情况称为哈希冲突。哈希冲突发生时,即使两个对象的hashCode一样,它们的equals方法也会返回false,因为它们实际上是不同的对象。
综上所述,虽然两个对象的hashCode相同不保证其equals结果一定相同,但是若两个对象equals方法返回true,则它们的hashCode必定相同。在Java编程实践中,正确重写equals和hashCode方法是非常重要的,以确保符合其契约并维持哈希表等相关数据结构的正确性。
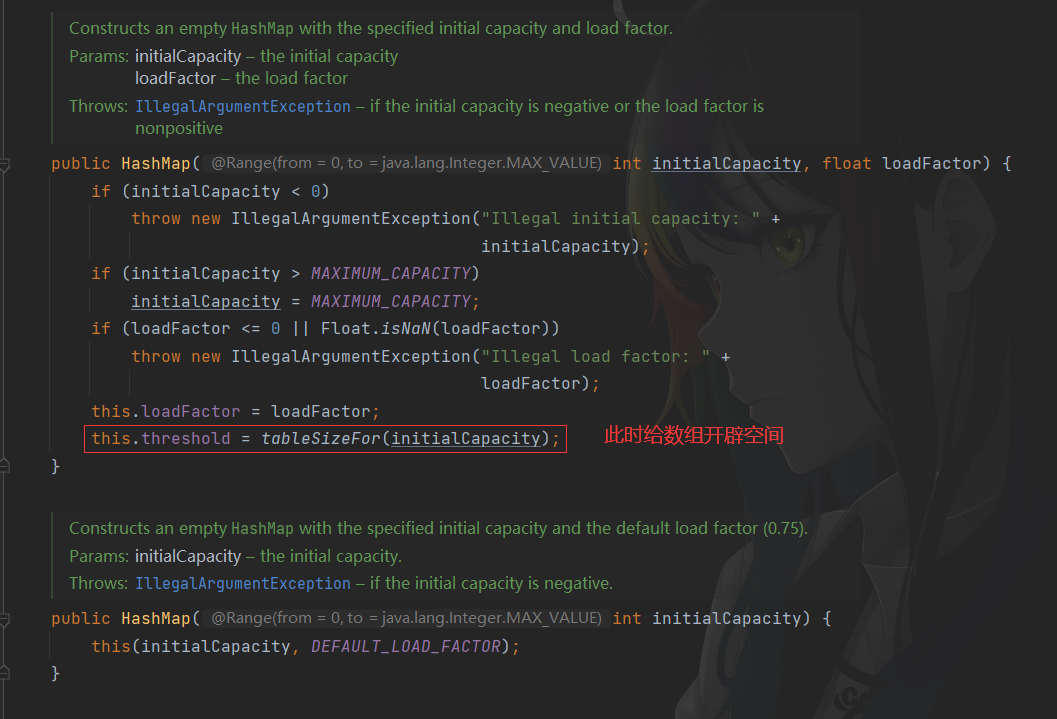
HashMap m = new HashMap<>底层数组多大?

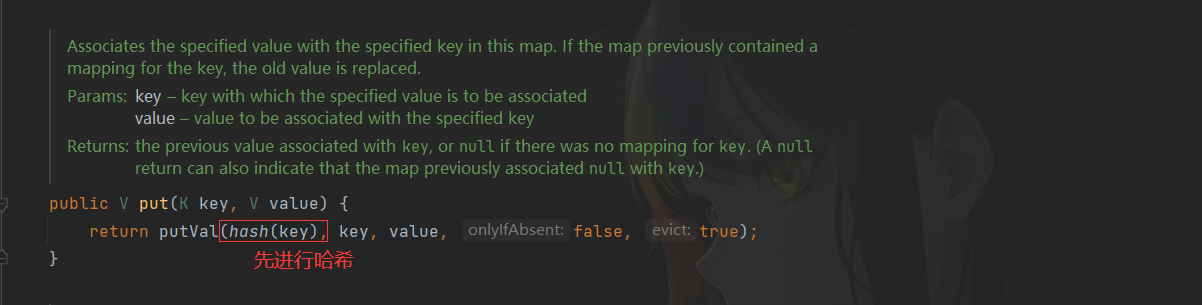
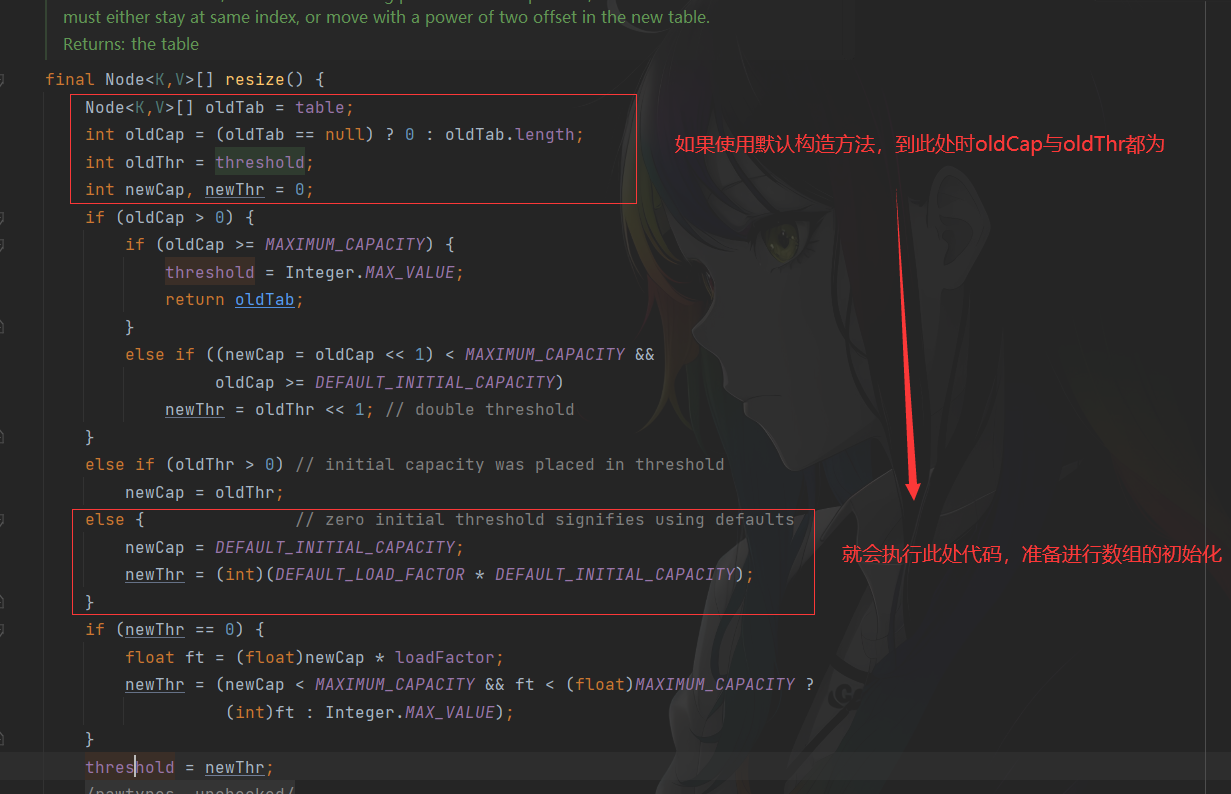
此时没有给数组开辟空间。当进行第一次put时会被初始化为16,详见下面Put流程
HashMap m = new HashMap<25>底层数组多大?
查看对应的构造方法
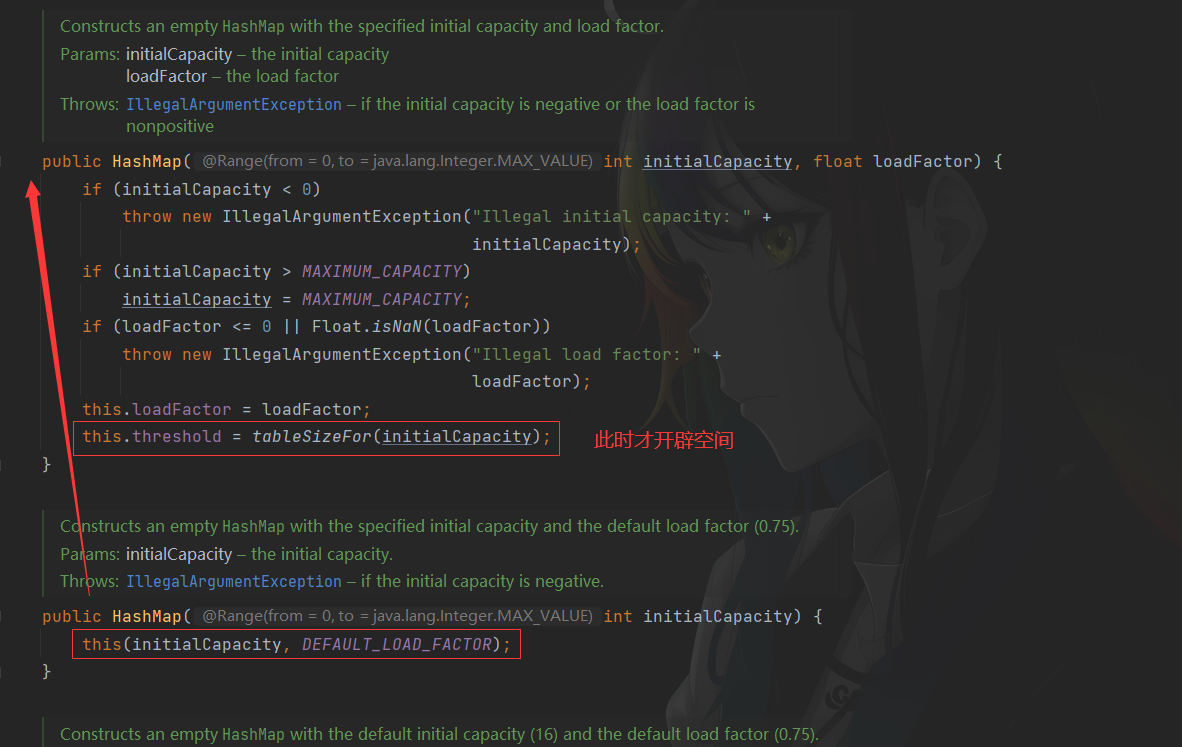
查看tableSizeFor方法

所以当我们构造方法传入25时,在开辟空间时会初始化为32
扩容需要注意什么
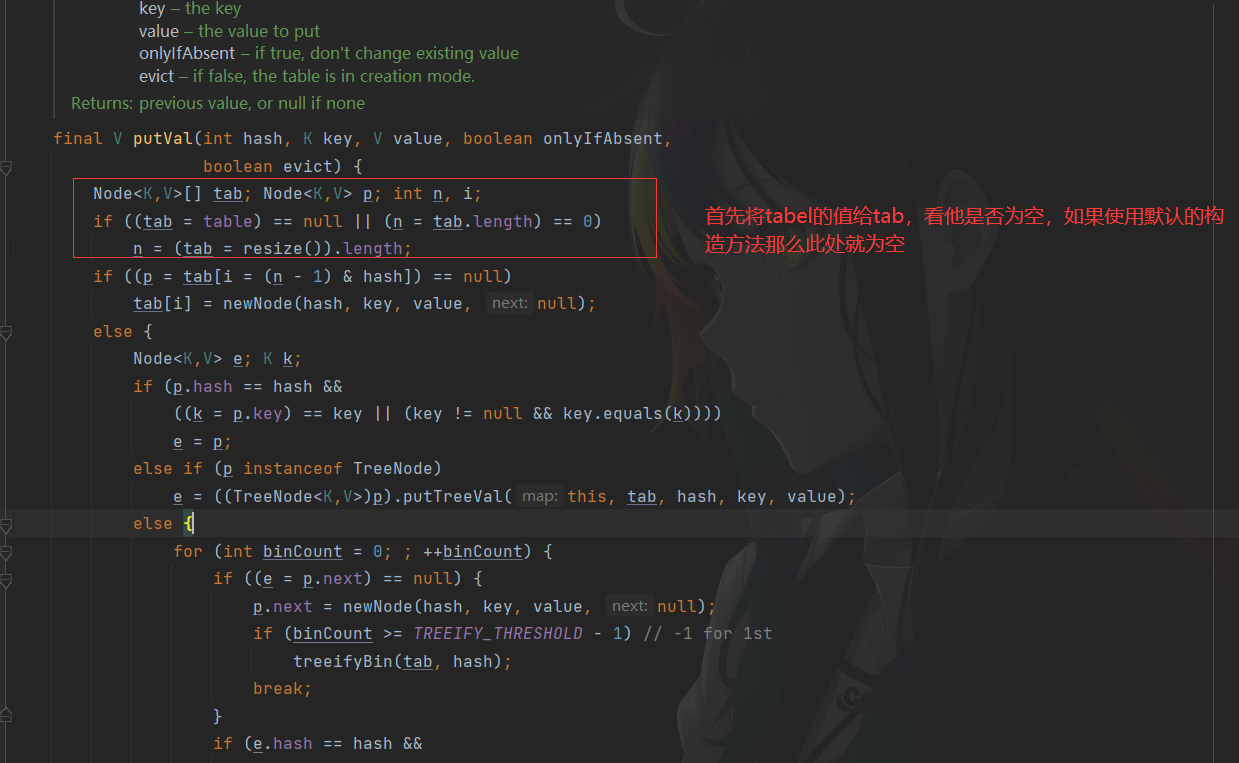
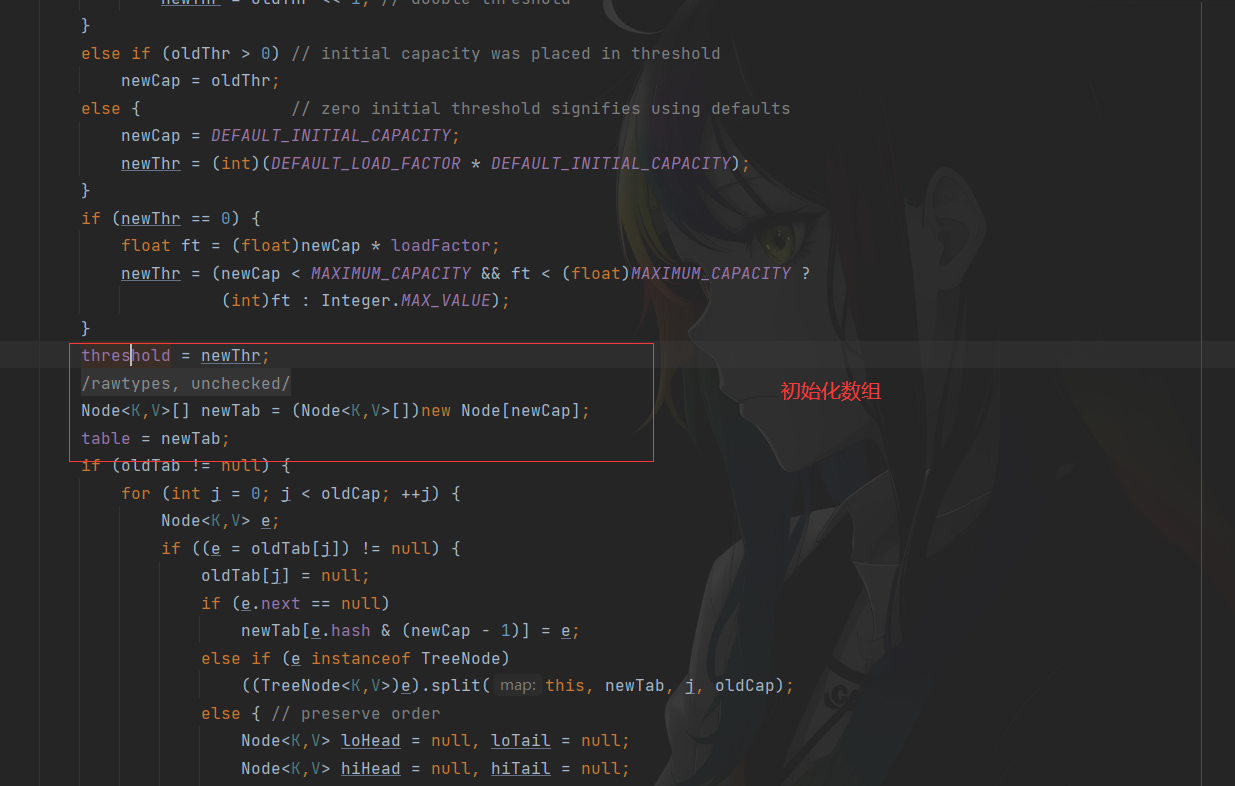
由于扩容使得哈希表的长度发生了改变,也意味着插入与获取元素的规则发生了改变,在寻找下标时我们使用key的哈希值与数组长度进行取模运算,扩容使得数组长度发生了变化,所以我们在进行扩容时需要对原有哈希表的元素进行重新哈希,让其满足新的规则
讲一下你了解的HashMap
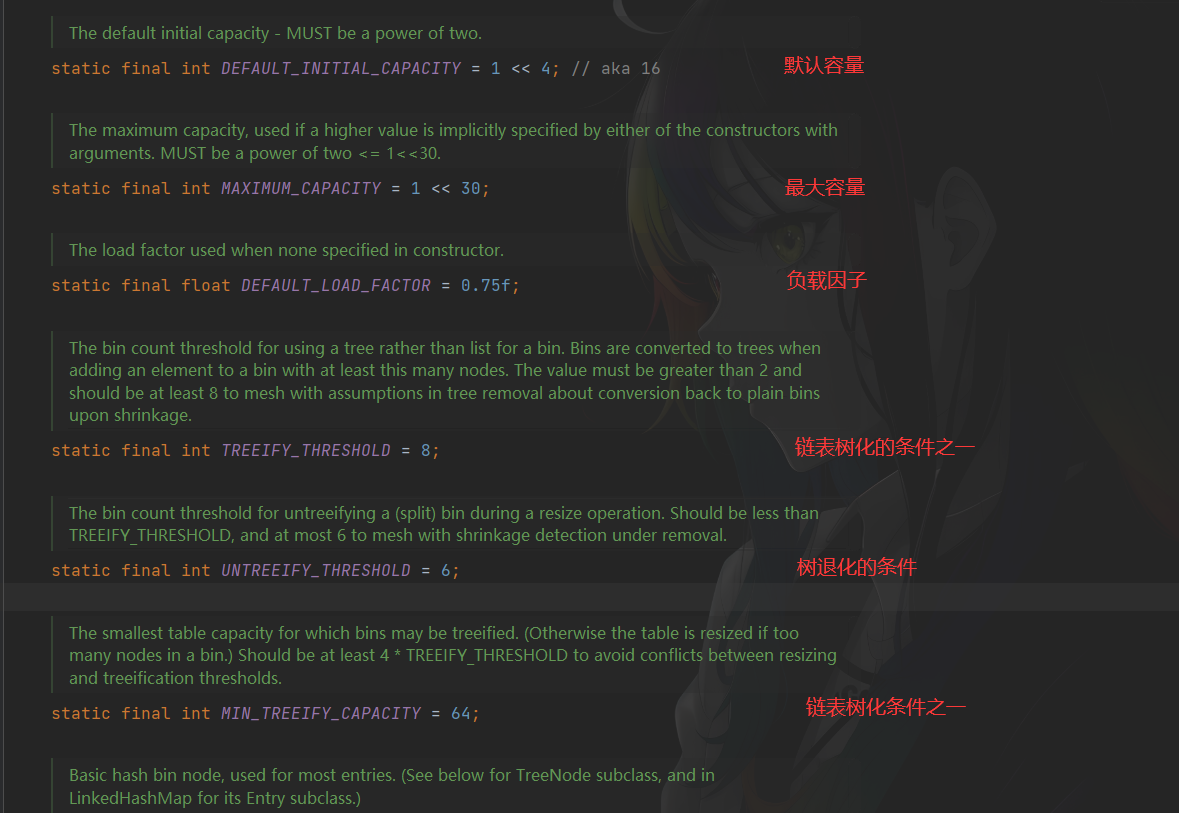
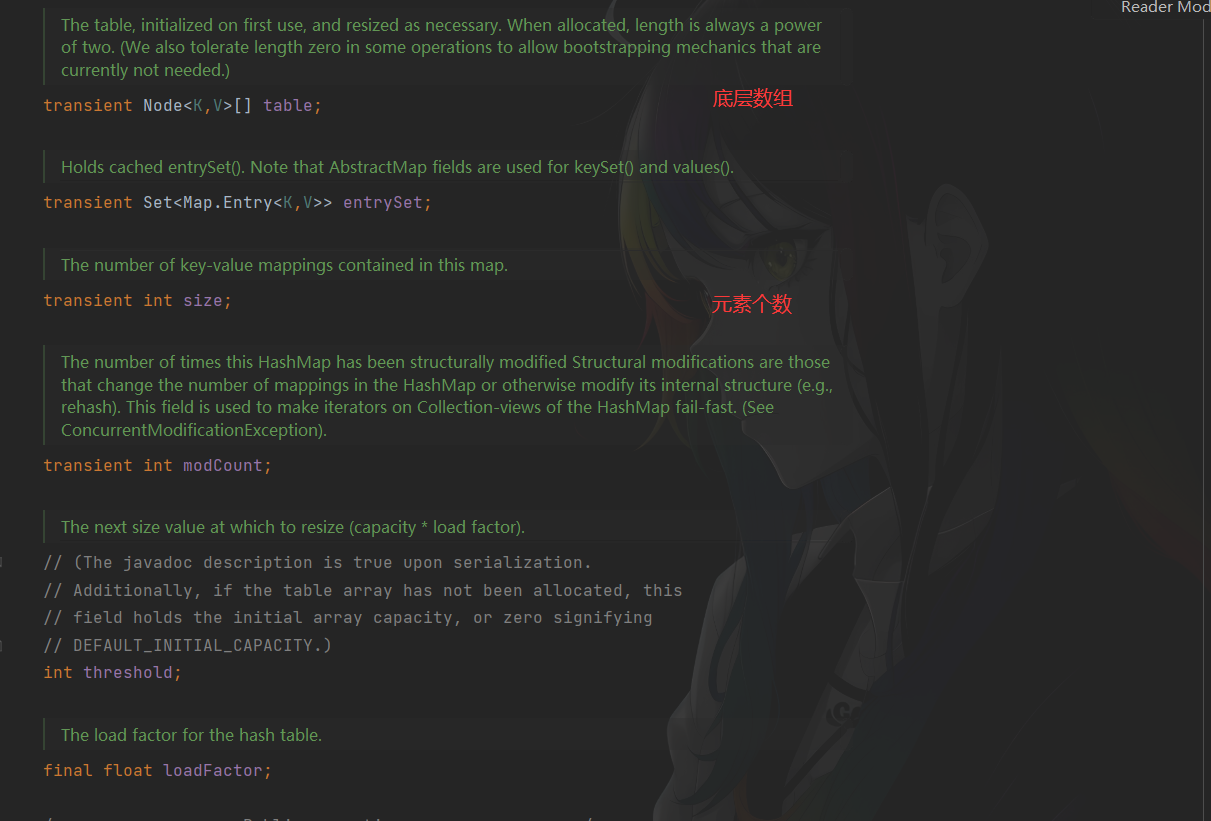
常见字段
构造方法
哈希方法
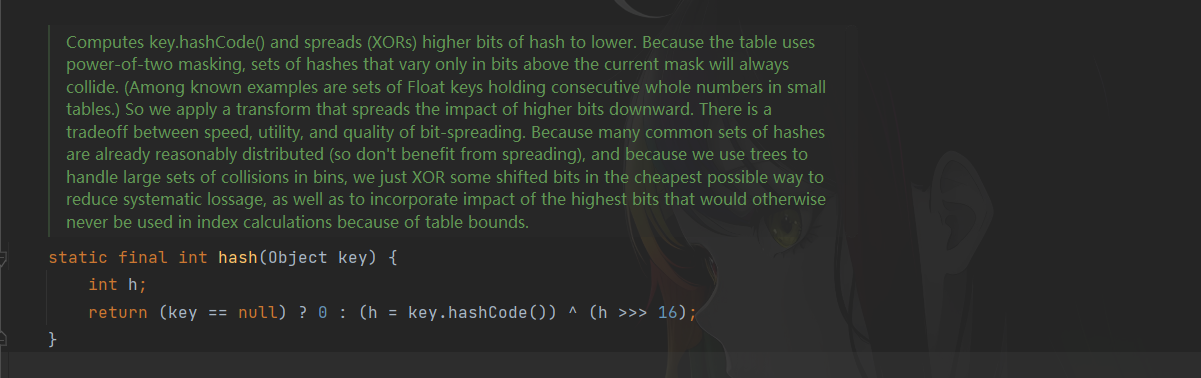
为什么哈希要使用低16位与高16位进行异或操作呢?
为了降低冲突的概率,例如小李是某某省的人,他的身份证开头是433432.后面是200011120882,小明是另一个省的他的开头是122121,后面也是200011120882,如果取低位那么他与小李就会冲突,而低位所包含的信息与高位包含的信息进行异或后则会降低冲突的概率
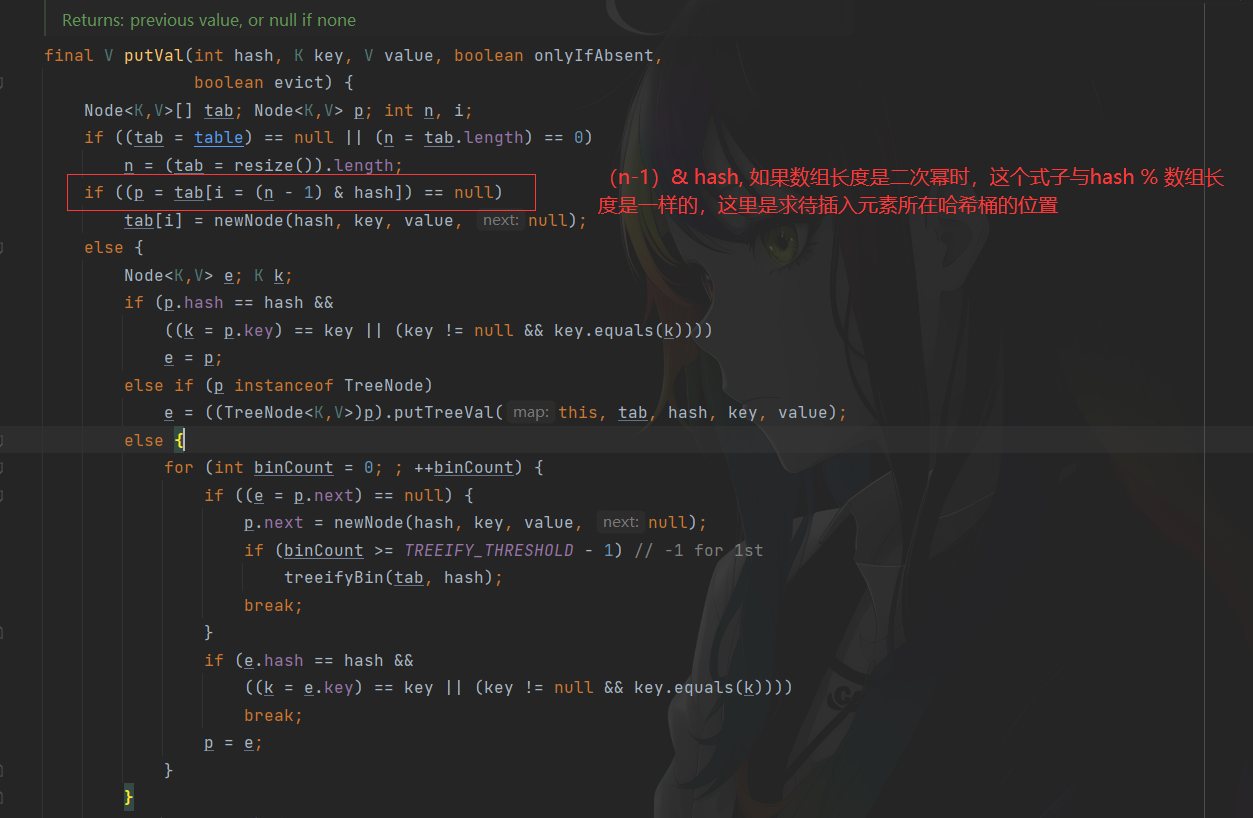
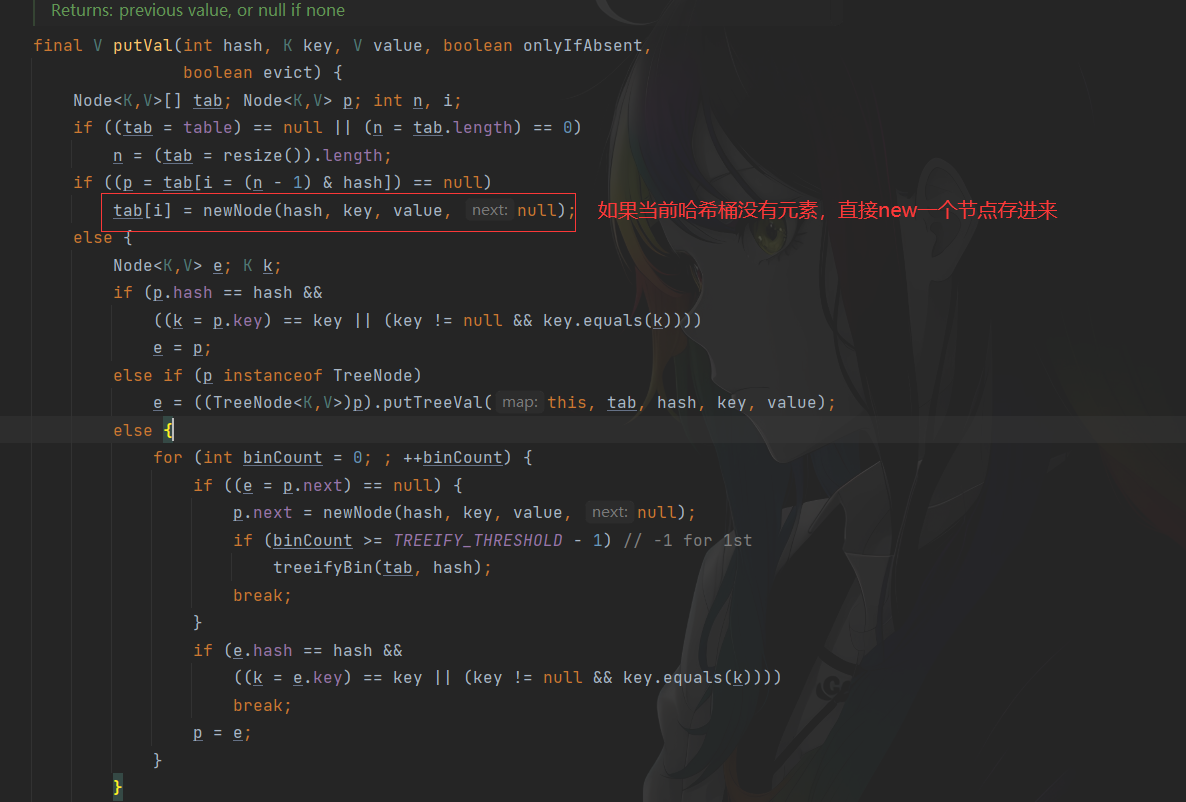
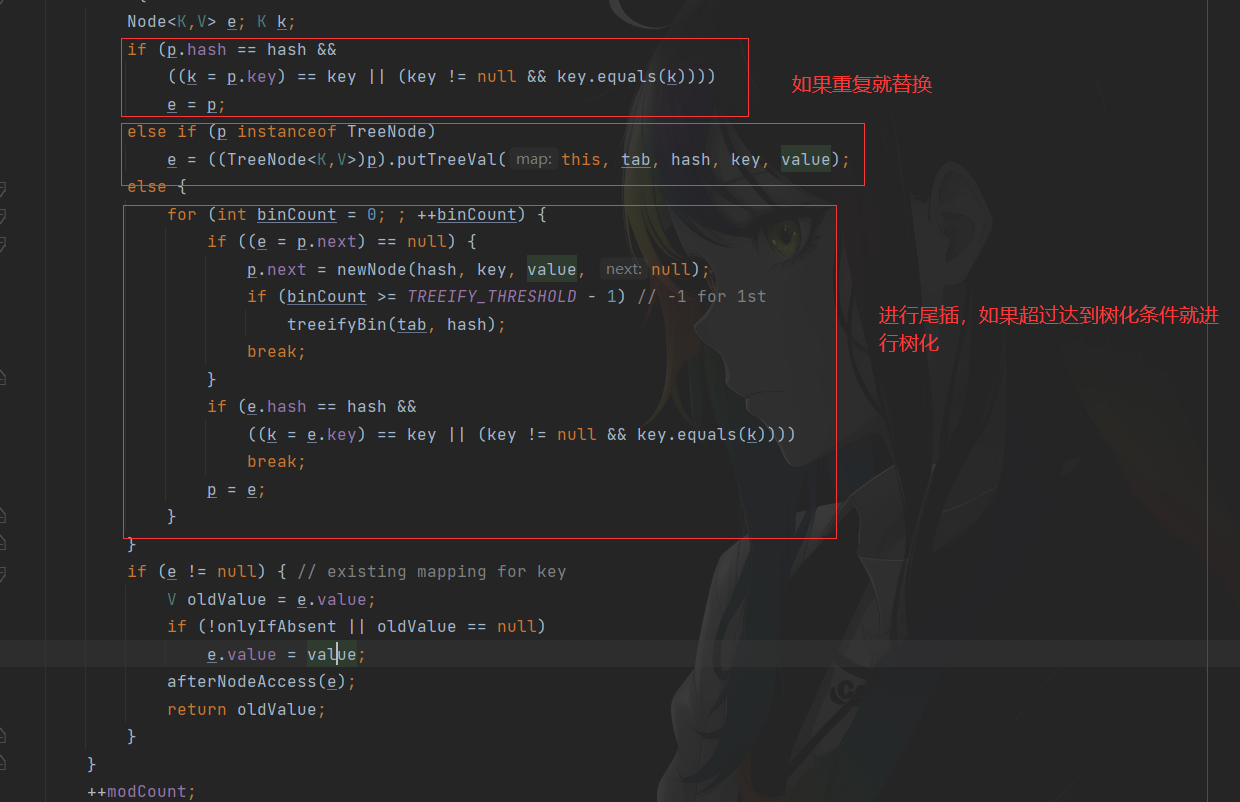
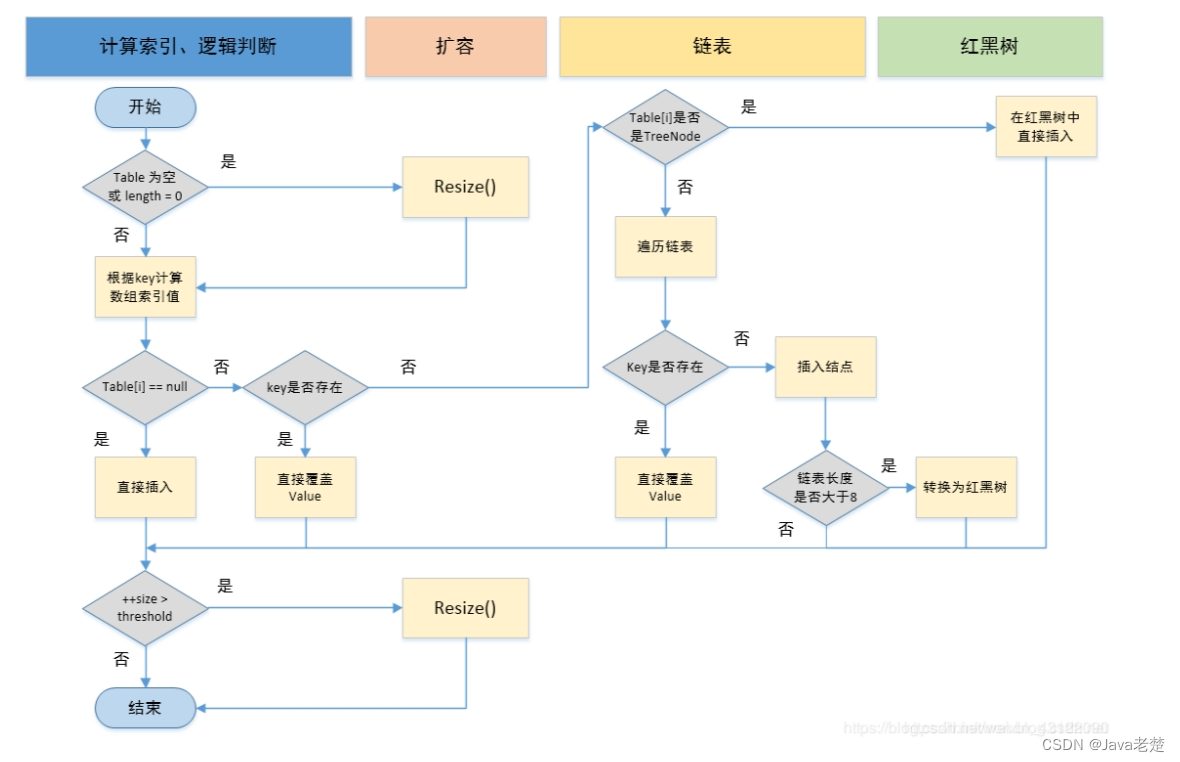
Put方法