Scrapy的介绍
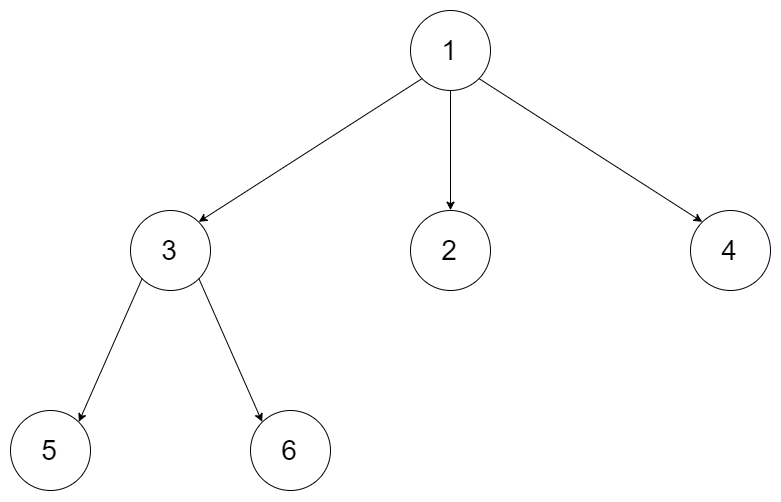
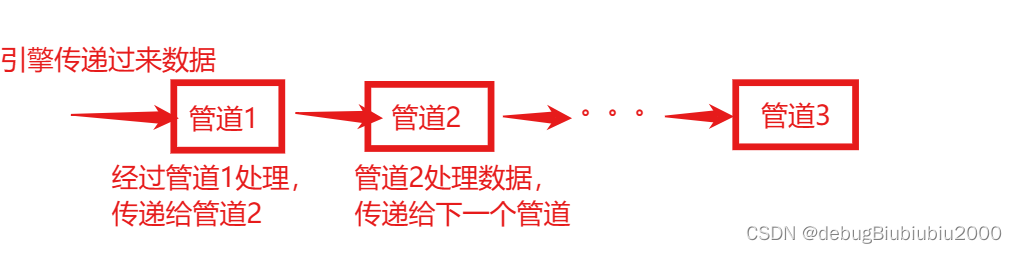
scrapy的工作流程(重点!!!)
如下图所示:
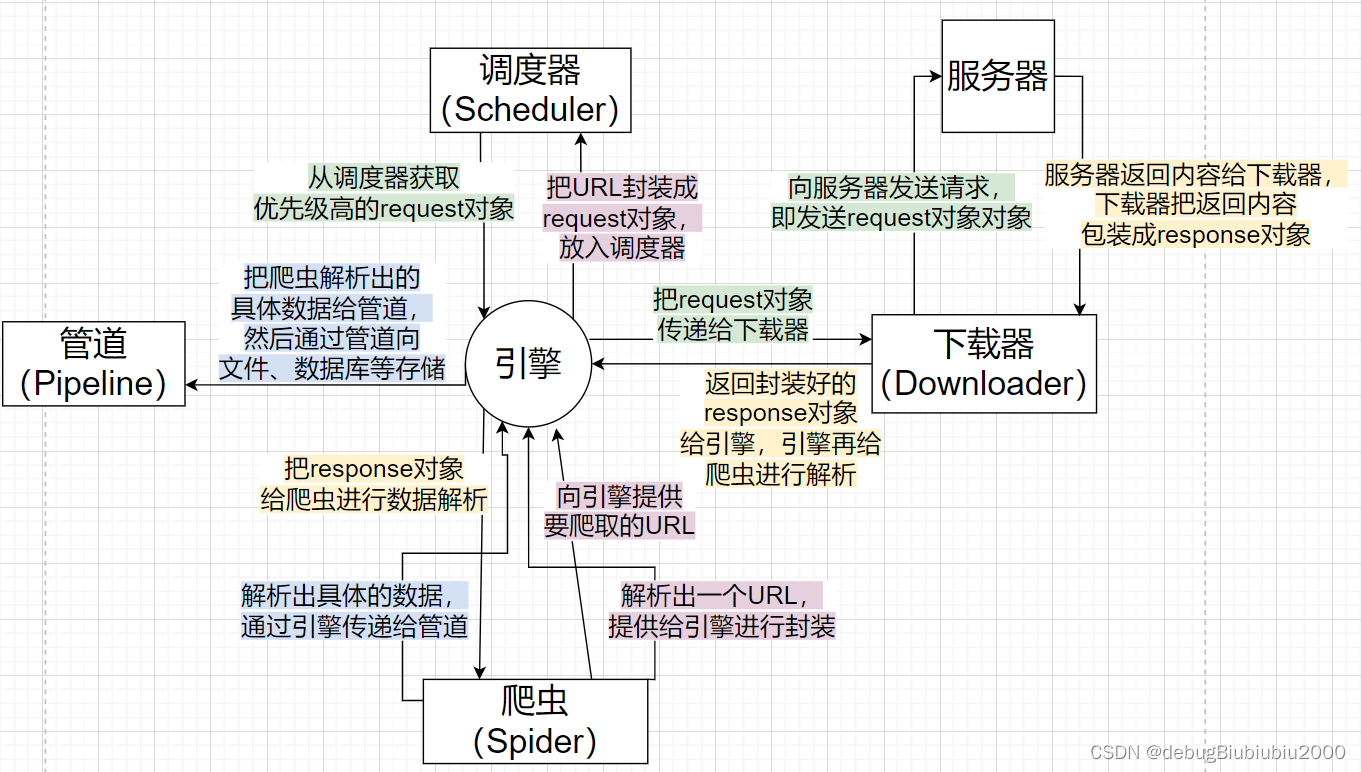
爬虫:
- 负责向引擎提供要爬取网页的URL,引擎会把这个URL封装成request对象并传递给调度器,
- 把引擎传递过来的response对象进行数据解析。数据解析有两种结果:
- 解析出具体的数据,那么通过引擎把这个具体的数据传递给管道,然后存入文件、数据库等
- 解析出一个新的URL,那么过程同作用1
管道:负责把引擎传递过来的数据进行存储,存入文件、数据库等。管道可以有多个,比如MySQL的管道,某个文件的管道,mango的管道等。
调度器:可以把调度器的存储结构看成一个优先队列,不同的request对象可能优先级不一样,按优先级的高低进行调度
- 把引擎传递过来的request对象放入队列进行排队,调度器可以实现去重的效果,即对两个相同的URL,只存储一个
- 向引擎提供队头的request对象(即优先级高的request对象),引擎把这个request对象传递给下载器进行请求
下载器:把引擎传递过来的request对象发送给服务器请求数据,并把服务器返回的内容封装成response对象, 然后把这个response对象传递给引擎,引擎再把这个response对象传递给爬虫进行数据解析
引擎:从上面的流程中可以看到,引擎负责控制数据流在所有组件流动,并在相应动作时触发事件,相当于爬虫的大脑
注意,在实际的代码编写过程中,我们只需要关注爬虫和管道部分的代码编写,而引擎、调度器、下载器都不需要我们实现
scrapy的安装
在终端输入以下命令(包有点大,建议切换成国内的镜像源,如清华源等,据说安装可能会有很多问题,但是可能我人品比较好,没遇到,嘿嘿。如果有问题的百度一下吧)
pip install scrapy
scrapy的基本使用
以爬取4399游戏网站的游戏名称为例,scrapy有以下几个步骤:

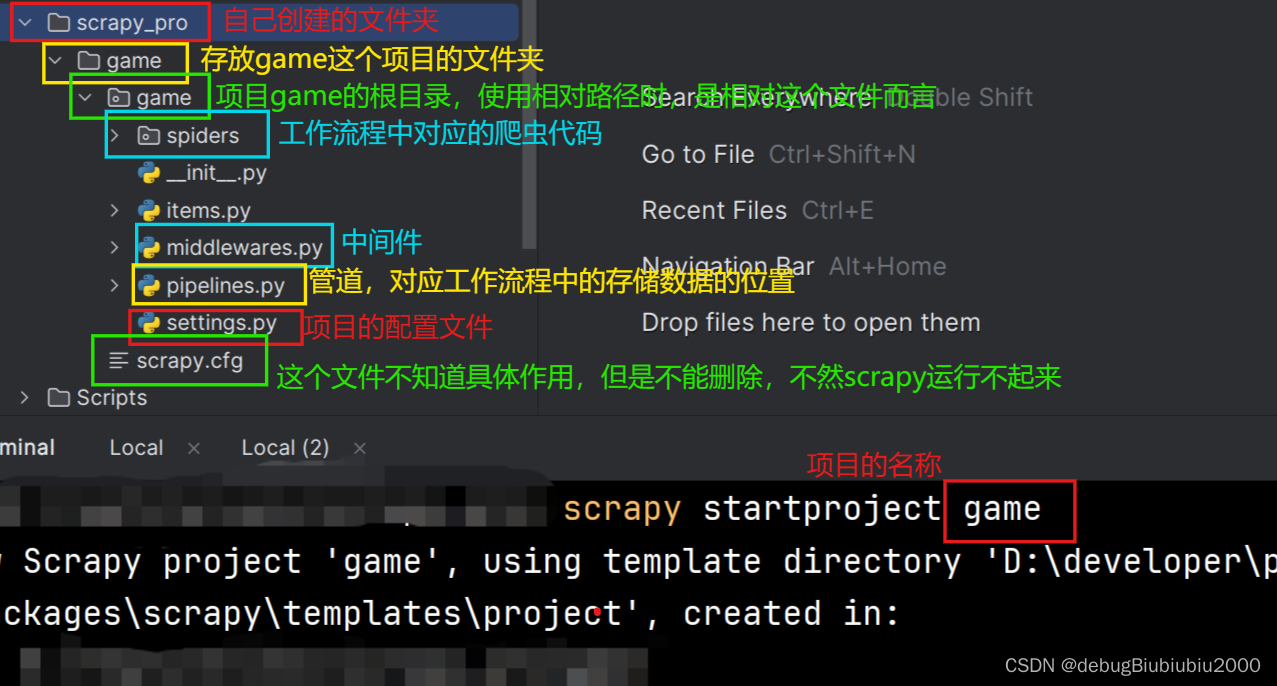
1、创建scrapy项目
首先在某个文件夹下打开终端,输入以下命令创建scrapy项目
scrapy startproject 项目名称
2、创建一个爬虫程序
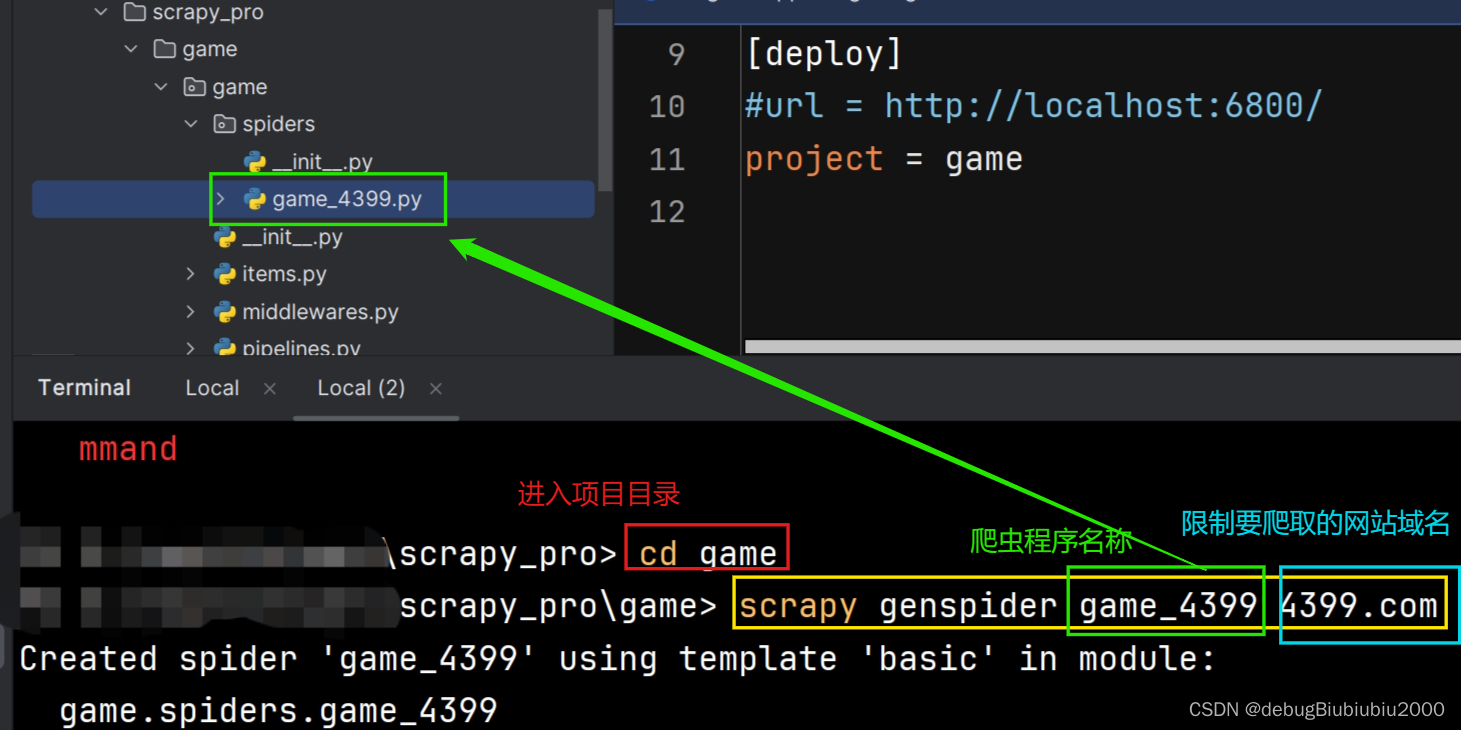
首先进入项目文件夹下,然后输入命令:
scrapy genspider 爬虫程序的名称 要爬取网站的域名
3、编写爬虫程序
在game_4399.py文件中编写爬虫代码,代码如下
import scrapy
class Game4399Spider(scrapy.Spider):
name = "game_4399" # 爬虫程序的名称
allowed_domains = ["4399.com"] # 允许爬取的域名
# 默认情况下是:https://4399.com
# 但是我们不从首页开始爬取,所以改一下URL
start_urls = ["https://4399.com/flash/"] # 一开始爬取的URL
def parse(self, response): # 该方法用于对response对象进行数据解析
# print(response) # <200 http://www.4399.com/flash/>
# print(response.text) # 打印页面源代码
# response.xpath() # 通过xpath解析数据
# response.css() # 通过css解析数据
# 获取4399小游戏的游戏名称
# txt = response.xpath('//ul[@class="n-game cf"]/li/a/b/text()')
# txt 列表中的每一项是一个Selector:
# <Selector query='//ul[@class="n-game cf"]/li/a/b/text()' data='逃离克莱蒙特城堡'>]
# 要通过extract()方法拿到data中的内容
# print(txt)
# txt = response.xpath('//ul[@class="n-game cf"]/li/a/b/text()').extract()
# print(txt) # 此时列表中的元素才是游戏的名字
# 也可以先拿到每个li,然后再提取名字
lis = response.xpath('//ul[@class="n-game cf"]/li')
for li in lis:
# name = li.xpath('./a/b/text()').extract()
# # name 是一个列表
# print(name) # ['王城霸业']
# 一般我们都会这么写:li.xpath('./a/b/text()').extract()[0]
# 但是这样如果列表为空就会报错,所以换另一种写法
# extract_first方法取列表中的第一个,如果列表为空,返回None
name = li.xpath('./a/b/text()').extract_first()
print(name) # 王城霸业
category = li.xpath('./em/a/text()').extract_first() # 游戏类别
date = li.xpath('./em/text()').extract_first() # 日期
print(category, date)
# 通过yield向管道传输数据
dic = {
'name': name,
'category': category,
'date': date
}
# 可以认为这里是把数据返回给了管道pipeline,
# 但是实际上是先给引擎,然后引擎再给管道,只是这个过程不用我们关心,scrapy会自动完成
# 这里的数据会在管道程序中接收到
yield dic4、运行scrapy爬虫程序
在终端输入命令,就可以看到爬虫程序运行结果。
scrapy crawl 爬虫程序名称


5、总结scrapy的基本使用
关于第6、7步,在下面的scrapy管道中会说到。

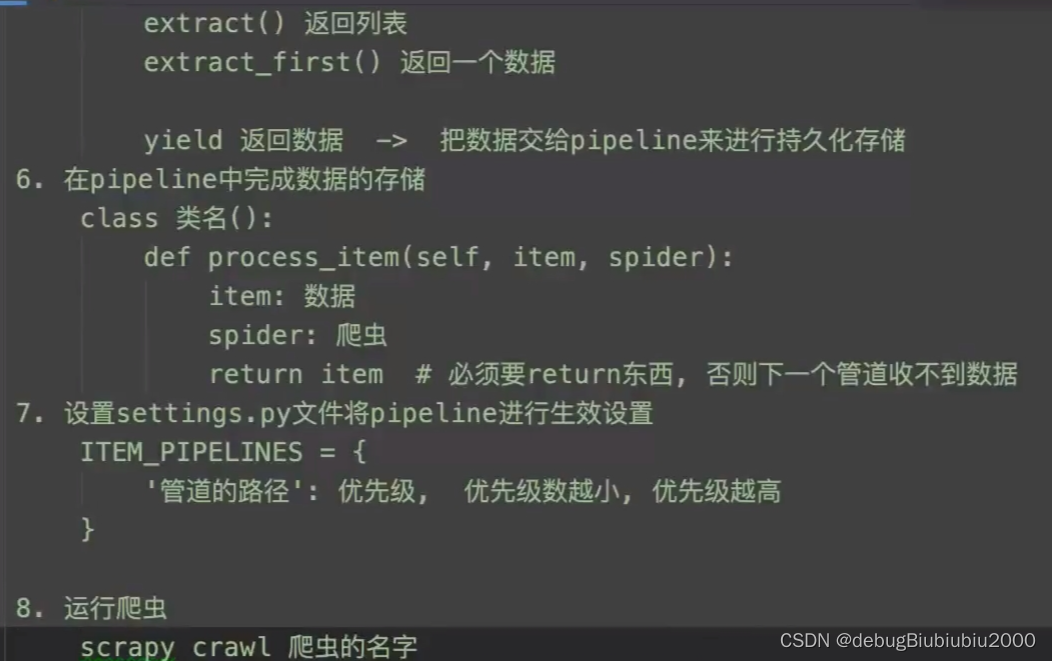
Scrapy中的管道
基本介绍
我们接着看上述4399中创建的scrapy项目,管道的默认情况如下:

管道程序默认是不生效的,需要在settings文件进行配置,如下:

pipelines.py文件中的代码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# 默认情况下管道是不开启的,需要在settings文件中进行设置
class GamePipeline:
def process_item(self, item, spider):
"""
接收爬虫通过引擎传递过来的数据
:param item: 具体的数据内容
:param spider: 对应传递数据的爬虫程序
:return:
"""
print(item) # {'name': '武器升级', 'category': '休闲类', 'date': '2024-01-06'}
print(spider) # <Game4399Spider 'game_4399' at 0x22867dafc70>
return item # 把数据传递给下一个管道settings文件中关于管道的代码
ITEM_PIPELINES = {
# 管道程序的所在路径:优先级
# 300 表示管道的优先级,数字越小优先级越高
# 优先级高的管道会比优先级低的管道先拿到数据
"game.pipelines.GamePipeline": 300,
}
运行命令:scrapy crawl game_4399,运行结果如下(只截取了一部分):

上述只有一个管道,如果有多个管道,比如我们自定义一个管道,代码如下:
from itemadapter import ItemAdapter
# 默认情况下管道是不开启的,需要在settings文件中进行设置
class GamePipeline:
def process_item(self, item, spider):
"""
接收爬虫通过引擎传递过来的数据
:param item: 具体的数据内容
:param spider: 对应传递数据的爬虫程序
:return:
"""
print(item) # {'name': '武器升级', 'category': '休闲类', 'date': '2024-01-06'}
print(spider) # <Game4399Spider 'game_4399' at 0x22867dafc70>
return item # 把数据传递给下一个管道
# 自定义一个管道程序
# 记得在settings文件中配置,否则不生效
class OtherPipeline:
def process_item(self, item, spider):
# 比如这里给传递过来的数据添加一个新的字段
item['new_field'] = 'hello'
return itemsettings文件关于管道的代码
ITEM_PIPELINES = {
# 管道程序的所在路径:优先级
# 300 表示管道的优先级,数字越小优先级越高
# 优先级高的管道会比优先级低的管道先拿到数据
"game.pipelines.GamePipeline": 300,
# 优先级比GamePipeline高,可以通过运行结果看出
"game.pipelines.OtherPipeline": 299
}
运行结果如下,可见多了一个字段
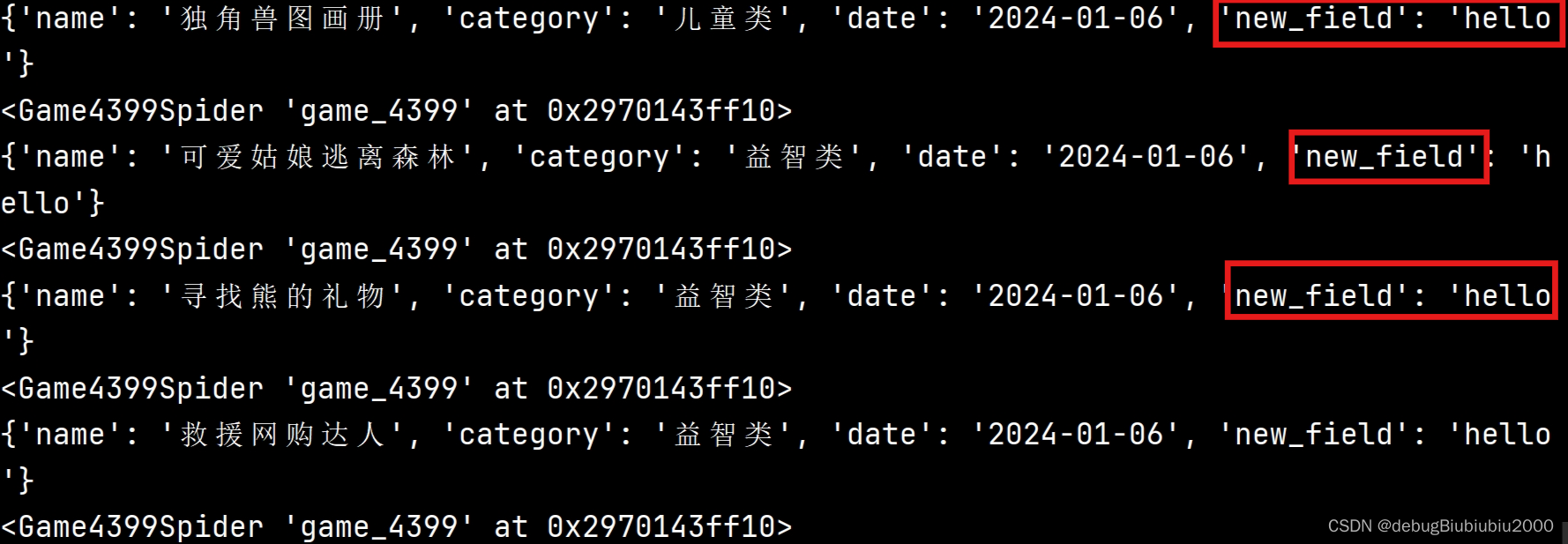
scrapy中的数据格式item
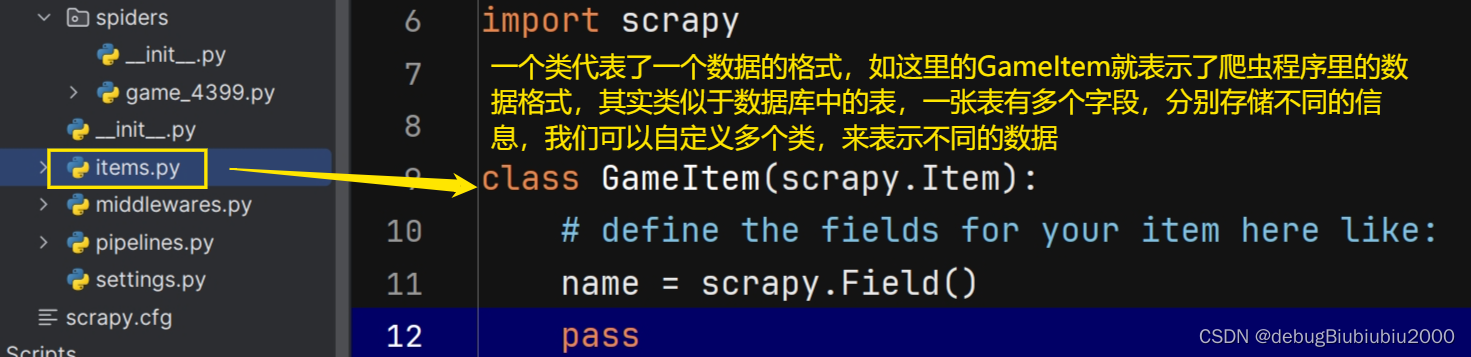
在上述的项目中,我们在爬虫程序里解析出来的数据组装成了字典然后使用yield传递给了管道,但是这实际上是不符合scrapy的规范的。在scrapy中,数据用item表示。
还是以上面的4399为例。game_4399.py中的代码如下:
import scrapy
from game.items import GameItem
class Game4399Spider(scrapy.Spider):
name = "game_4399" # 爬虫程序的名称
allowed_domains = ["4399.com"] # 允许爬取的域名
# 默认情况下是:https://4399.com
# 但是我们不从首页开始爬取,所以改一下URL
start_urls = ["https://4399.com/flash/"] # 一开始爬取的URL
def parse(self, response): # 该方法用于对response对象进行数据解析
# 也可以先拿到每个li,然后再提取名字
lis = response.xpath('//ul[@class="n-game cf"]/li')
for li in lis:
name = li.xpath('./a/b/text()').extract_first()
category = li.xpath('./em/a/text()').extract_first() # 游戏类别
date = li.xpath('./em/text()').extract_first() # 日期
# 通过yield向管道传输数据
# dic = {
# 'name': name,
# 'category': category,
# 'date': date
# }
# 可以认为这里是把数据返回给了管道pipeline,
# 但是实际上是先给引擎,然后引擎再给管道,只是这个过程不用我们关心,scrapy会自动完成
# 如果只有一个数据,可以通过return返回,但是在scrapy中没人使用return,都是用yield的
# 另外,在scrapy中,只希望yield返回三个类型之一的数据:item、request、None
# 这里可以yield dic 返回字典,但是实际上并不希望这么干
# 而且如果换成了 yield [] 返回雷暴,就会报错:
# ERROR: Spider must return request, item, or None, got 'list'
# yield dic
# 我们现在不返回字典,而是返回真正推荐我们返回的格式之一:item
# 先导入GameItem类:from game.items import GameItem
# 然后创建它的实例,使用起来和字典类似
# 区别就是GameItem类里没有定义的字段,就不能使用,比如不能item['某个没有定义的字段']
item = GameItem()
# item['xxx'] 里的xxx要在类GameItem里定义有,否则就会报错
item['name'] = name
item['category'] = category
item['date'] = date
yield itemitems.py中的代码
import scrapy
class GameItem(scrapy.Item):
# 这里定义了三个字段,分别表示游戏的名称、类别和日期
name = scrapy.Field()
category = scrapy.Field()
date = scrapy.Field()
# 可以定义其他字段来表示不同的信息
class OtherItem(scrapy.Item):
pass管道程序pipelines.py中的代码
from itemadapter import ItemAdapter
# 默认情况下管道是不开启的,需要在settings文件中进行设置
class GamePipeline:
def process_item(self, item, spider):
"""
接收爬虫通过引擎传递过来的数据
:param item: 具体的数据内容
:param spider: 对应传递数据的爬虫程序
:return:
"""
print(item) # {'name': '武器升级', 'category': '休闲类', 'date': '2024-01-06'}
print(spider) # <Game4399Spider 'game_4399' at 0x22867dafc70>
return item # 把数据传递给下一个管道
# 自定义一个管道程序
# 记得在settings文件中配置,否则不生效
class OtherPipeline:
def process_item(self, item, spider):
# 比如这里给传递过来的数据添加一个新的字段
# 此时传递过来的item不再是字典,而是GameItem类对象
# 由于GameItem类里没有定义字段new_field,所以不能使用,否则报错
# item['new_field'] = 'hello'
return item数据存储
我们一直说通过管道存储数据,但是上面的例子一直未涉及,现在来讲解怎么把数据进行持久化存储。在上面的例子中,我们已经在管道程序里拿到了引擎传递过来的数据,现在就可以把这些数据存储起来。
首先,先来说一说数据存储的几种方案:
- 存入.csv文件,这类数据一般用于数据分析
- 存入MySQL数据库
- 存入mangodb数据库
- 写入文件,如图片、视频、文字等数据
下面以存入csv文件为例(存入MySQL的也列举了一个模板,mango数据库的操作和MySQL基本一致,但是由于我对mango不熟悉,所以不写了,需要的可以百度一下)
settings文件中的代码
ITEM_PIPELINES = { # 管道程序的所在路径:优先级 # 300 表示管道的优先级,数字越小优先级越高 # 优先级高的管道会比优先级低的管道先拿到数据 "game.pipelines.GamePipeline": 300, "game.pipelines.GameMySqlPipeline": 300, # 优先级比GamePipeline高,可以通过运行结果看出 "game.pipelines.OtherPipeline": 299 }# 配置MySQL MYSQL = { "host": "localhost", # 主机 "port": 3306, # 端口 "user": "xxx", # 用户名 "password": "xxx", # 密码 "database": "xxx" # 数据库名称 }
pipelines.py的代码:
import pymysql
# 导入MySQL配置
from game.settings import MYSQL
# 默认情况下管道是不开启的,需要在settings文件中进行设置
class GamePipeline:
def __init__(self):
self.f = None
def open_spider(self, spider):
""""""
print('爬虫开始了...')
self.f = open('./game_data.csv', mode='a', encoding='utf-8')
def process_item(self, item, spider):
"""
接收爬虫通过引擎传递过来的数据
:param item: 具体的数据内容
:param spider: 对应传递数据的爬虫程序
:return:
"""
print('爬虫进行中...')
# 把数据写入文件
# 写入模式是mode='a',表示在文件里追加,不能是w,否则文件原本的内容会被覆盖
# 以下的这种方式效率不高,因为每传递一次数据,就要进行一次文件的打开的关闭操作
# with open('./game_data.csv', mode='a', encoding='utf-8') as f:
# f.write(f'{item["category"]}, {item["name"]}, {item["date"]}\n')
# 采取另一种方式
# scrapy 提供了两个方法open_spider()、close_spider(),分别会在爬虫开始时和爬虫结束后调用
self.f.write(f'{item["category"]}, {item["name"]}, {item["date"]}\n')
return item # 把数据传递给下一个管道
def close_spider(self, spider):
print('爬虫结束了...')
if self.f:
self.f.close()
# 默认情况下管道是不开启的,需要在settings文件中进行设置
class GameMySqlPipeline:
def __init__(self):
self.conn = None
def open_spider(self, spider):
print('爬虫开始了...')
# self.conn = pymysql.connect( # 创建数据库连接
# host='localhost', # 主机
# port=3306, # 端口
# user='xxx', # 用户名
# password='xxx', # 密码
# database='xxx' # 数据库名称
# )
# 可以向上面那样写,但是更好的办法是写在settings文件中
# 然后从settings文件中导入:from game.settings import MYSQL
self.conn = pymysql.connect( # 创建数据库连接
host=MYSQL['host'], # 主机
port=MYSQL['port'], # 端口
user=MYSQL['user'], # 用户名
password=MYSQL['password'], # 密码
database=MYSQL['database'] # 数据库名称
)
def process_item(self, item, spider):
"""
接收爬虫通过引擎传递过来的数据
:param item: 具体的数据内容
:param spider: 对应传递数据的爬虫程序
:return:
"""
print('爬虫进行中...')
# 把数据写入mysql数据库
# 下载数据库包并导入:pip install pymysql
# 确定自己的数据库中准备好了相应的数据表
try:
cursor = self.conn.cursor()
# 插入的sql语句
# (%s, %s, %s) 对应相应的字段类型,%s表示字符串类型
insert_sql = 'insert into 数据库表名 (字段1, 字段2, 字段3, ...) values (%s, %s, %s)'
# execute()的第二个参数是一个元祖,里面的每一个元素对应sql语句中的字段值
cursor.execute(insert_sql, (item['category'], item['name'], item['date']))
self.conn.commit() # 提交事务
except:
self.conn.rollback() # 出现异常,执行回滚操作
finally:
if cursor:
cursor.close()
return item # 把数据传递给下一个管道
def close_spider(self, spider):
print('爬虫结束了...')
if self.conn:
self.conn.close()
# 自定义一个管道程序
# 记得在settings文件中配置,否则不生效
class OtherPipeline:
def process_item(self, item, spider):
# 比如这里给传递过来的数据添加一个新的字段
# 此时传递过来的item不再是字典,而是GameItem类对象
# 由于GameItem类里没有定义字段new_field,所以不能使用,否则报错
# item['new_field'] = 'hello'
return item结尾
关于scrapy的基本使用,好像还有中间件这个内容,但是我看的那个视频教程这个部分好像漏掉了,反正就是没有笔记,需要了解的自行百度一下吧,或者看官方文档也行。
本人也是初学者,所以文章中有什么错误的地方,欢迎指正。
有一个对应的综合练习:scrapy框架爬取图片