需求分析
使用Spark来探索数据是一种高效处理大规模数据的方法,需要对数据进行加载、清洗和转换,选择合适的Spark组件进行数据处理和分析。需求分析包括确定数据分析的目的和问题、选择合适的Spark应用程序和算法、优化数据处理流程和性能、可视化和解释分析结果。同时,需要熟悉Spark的基本概念和操作,掌握Spark编程和调优技巧,以确保数据探索的准确性和效率。
系统实现
了解实验目的
掌握python on Spark的使用理解探索数据的意义和方法,掌握使用Spark探索数据的过程。
1.实验整体流程分析:
- 准备环境,安装Hadoop和Spark组件
- 准备数据,采用开源movielens数据集
- 探索用户数据
- 探索电影数据
- 探索电影评级数据
2.准备数据:
- 打开终端,启动Hadoop和Spark集群

- 下载相关数据集

- 将数据集解压到/usr/目录下

- 上传数据至HDFS
# hadoop fs -mkdir /data
# hadoop fs -ls /
# hadoop fs -put /usr/data/u.user /data/u.user
# hadoop fs -put /usr/data/u.data /data/u.data
# hadoop fs -put /usr/data/u.genre /data/u.genre
# hadoop fs -put /usr/data/u.info /data/u.info
# hadoop fs -put /usr/data/u.item /data/u.item
# hadoop fs -put /usr/data/u.occupation /data/u.occupation
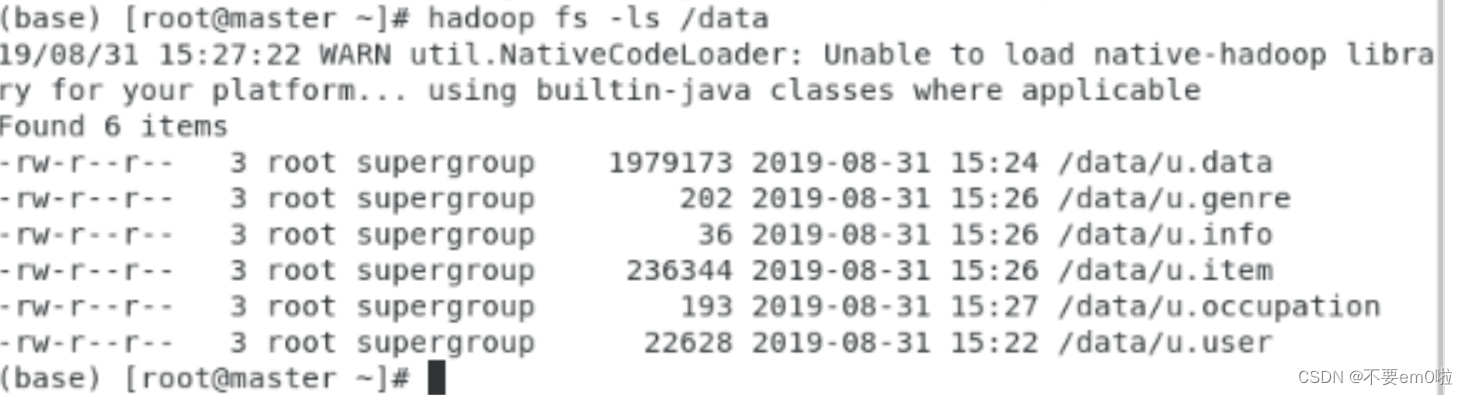
# hadoop fs -ls /data上传后的HDFS的data目录结构如图所示
3.探索用户数据:
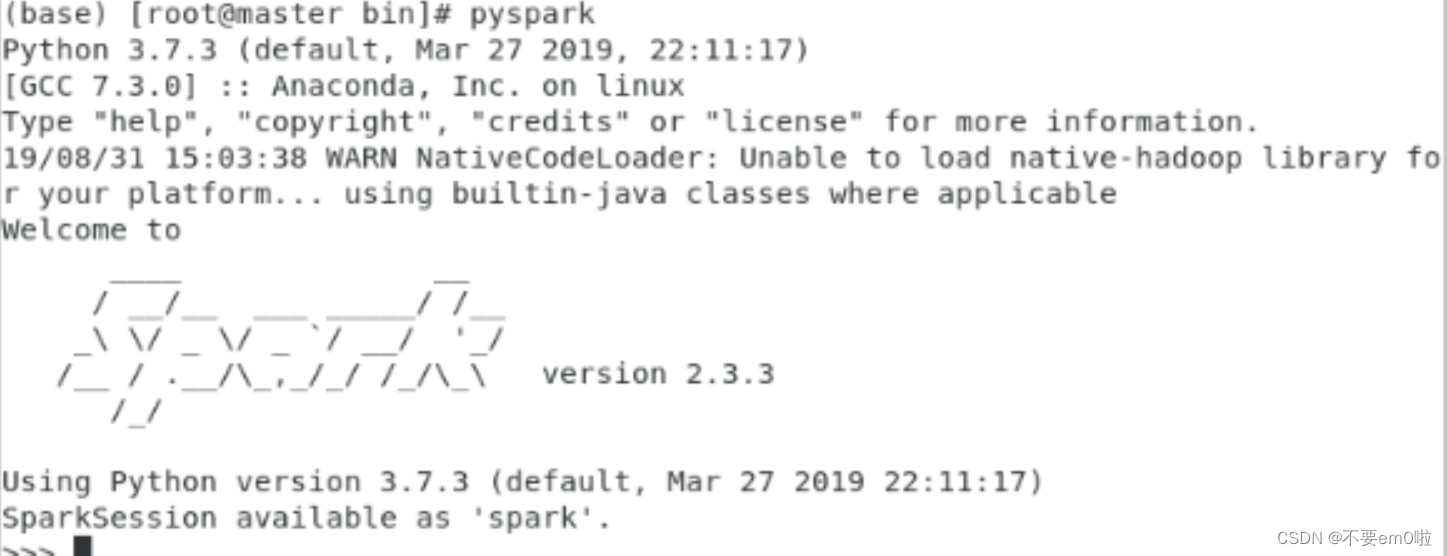
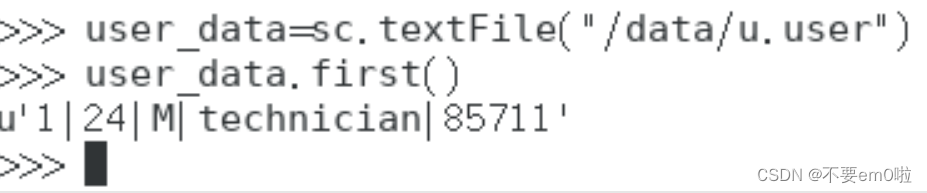
- 打开终端,执行pyspark命令,进入Spark的python环境

- 打印首行记录

运行结果如下
- 分别统计用户、性别和职业的个数
# 以' | '切分每列,返回新的用户RDD
user_fields = user_data.map(lambda line: line.split("|"))
# 统计用户数
num_users = user_fields.map(lambda fields: fields[0]).count()
# 统计性别数
num_genders = user_fields.map(lambda fields: fields[2]).distinct().count()
# 统计职业数
num_occupations = user_fields.map(lambda fields: fields[3]).distinct().count()
# 统计邮编数
num_zipcodes = user_fields.map(lambda fields: fields[4]).distinct().count()
# 返回结果
print ("用户数: %d, 性别数: %d, 职业数: %d, 邮编数: %d" % (num_users, num_genders, num_occupations, num_zipcodes))运行结果如下

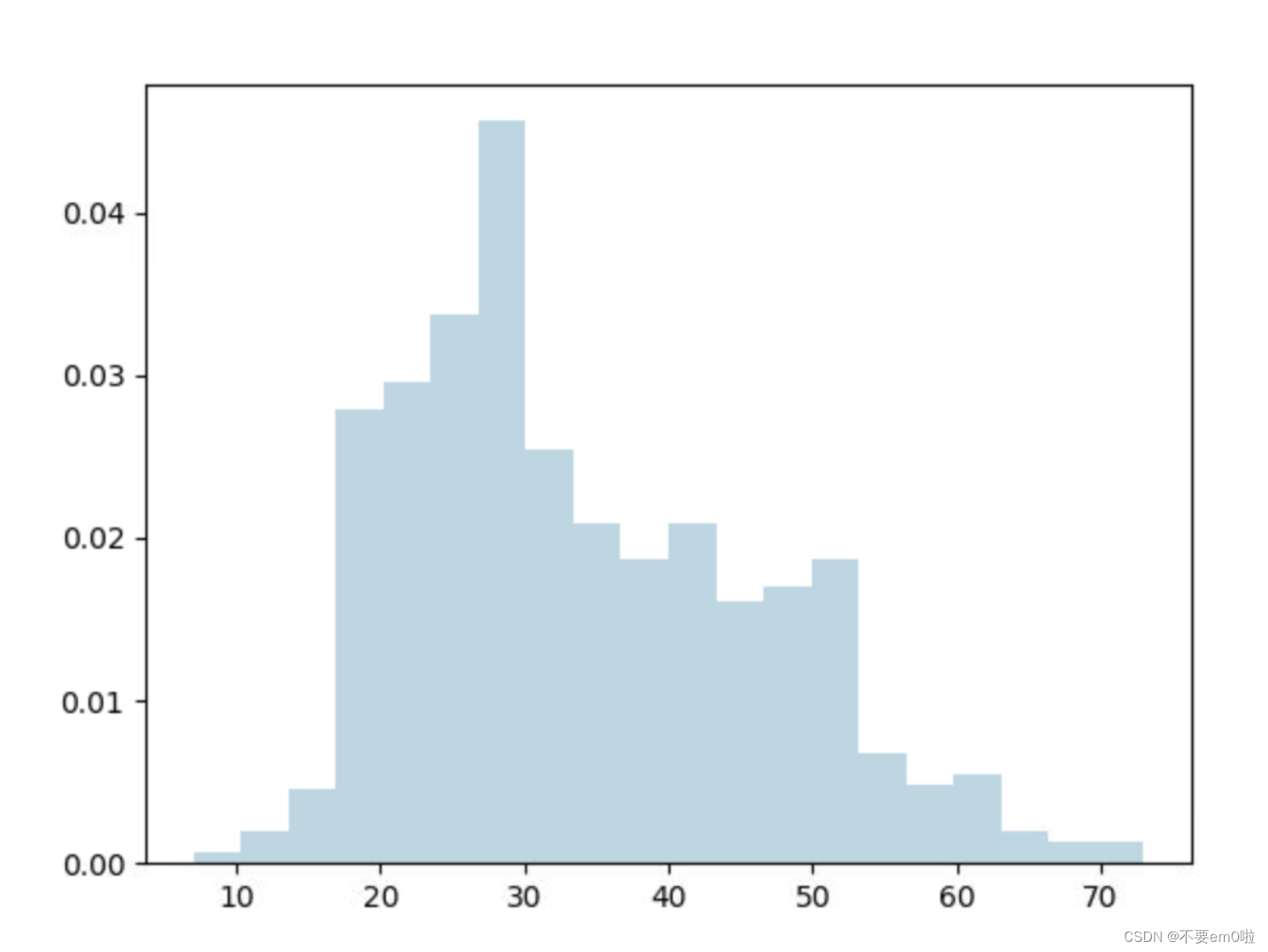
- 查看年龄分布情况,并用plt.show绘制

- 查看职业分布情况,同样绘制图
# 并行统计各职业人数的个数,返回职业统计RDD后落地
count_by_occupation = user_fields.map(lambda fields: (fields[3], 1)).reduceByKey(lambda x, y: x + y).collect()
# 生成x/y坐标轴
x_axis1 = np.array([c[0] for c in count_by_occupation])
y_axis1 = np.array([c[1] for c in count_by_occupation])
x_axis = x_axis1[np.argsort(x_axis1)]
y_axis = y_axis1[np.argsort(y_axis1)]
# 生成x轴标签
pos = np.arange(len(x_axis))
width = 1.0
ax = plt.axes()
ax.set_xticks(pos + (width / 2))
ax.set_xticklabels(x_axis)
# 绘制职业人数条状图
plt.xticks(rotation=30)
plt.bar(pos, y_axis, width, color='lightblue')
plt.show() 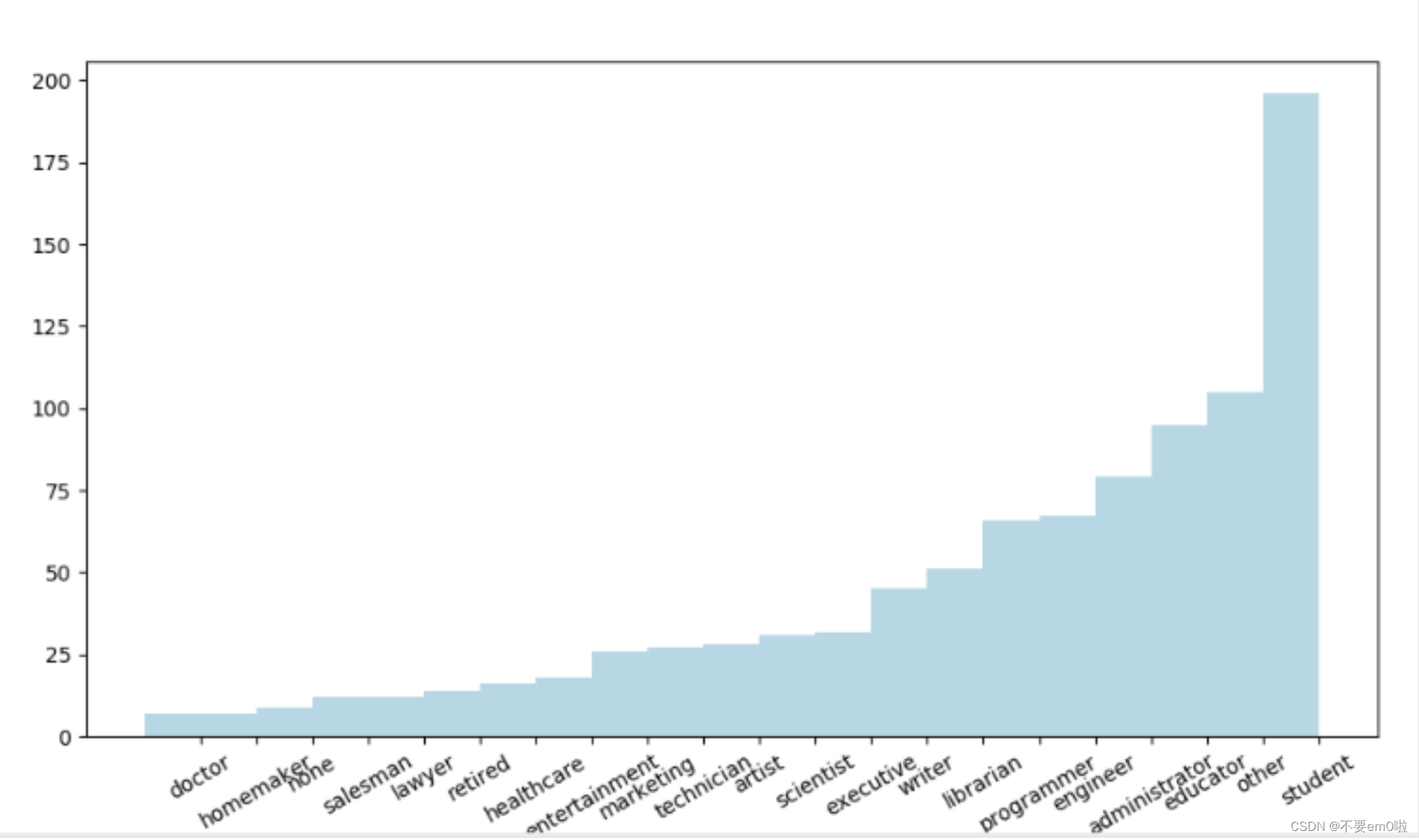
- 统计各职业人数


4.探索电影数据:
- 重新打开终端,执行pyspark命令,进入Spark的python环境
- 打印首行记录


- 查看电影的数量


- 过滤掉没有发现时间信息的记录

注意,输入时需要手动缩进

- 查看影片的年龄分布并绘图

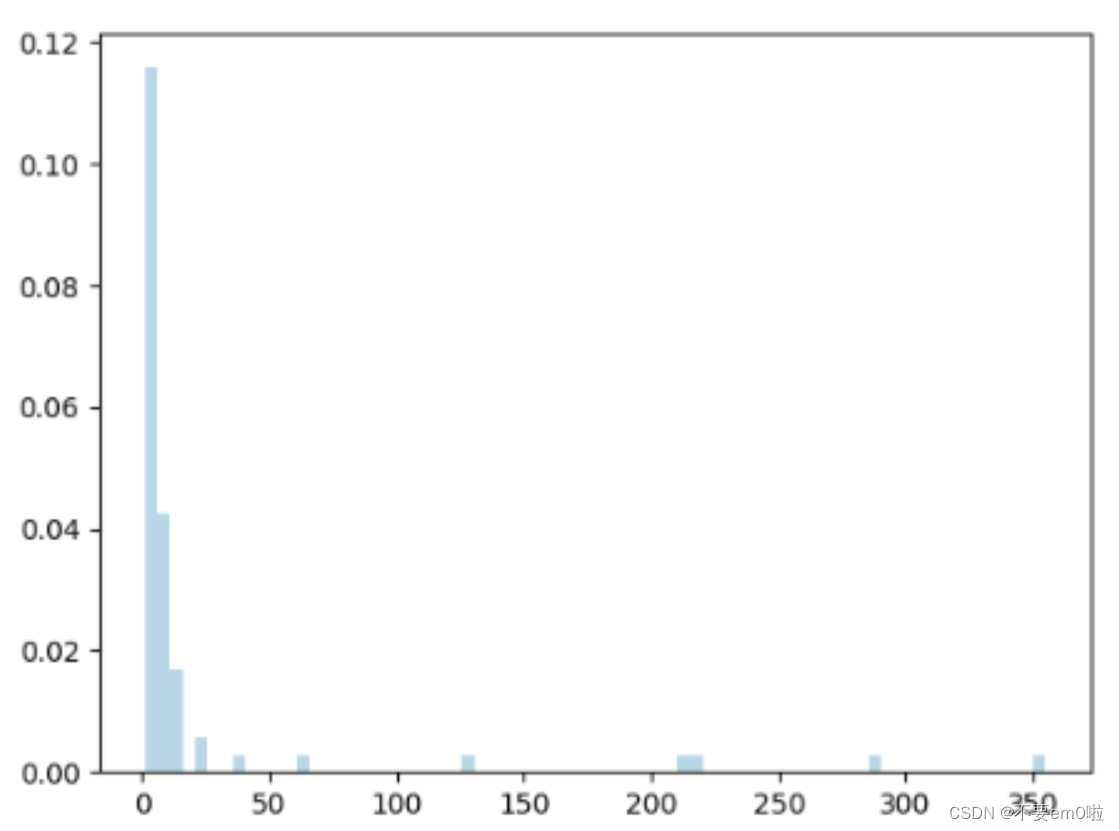
5.探索评级数据:
- 重新打开终端,进入Spark的bin目录下,执行pyspark命令,进入Spark的python环境

- 打印首行记录

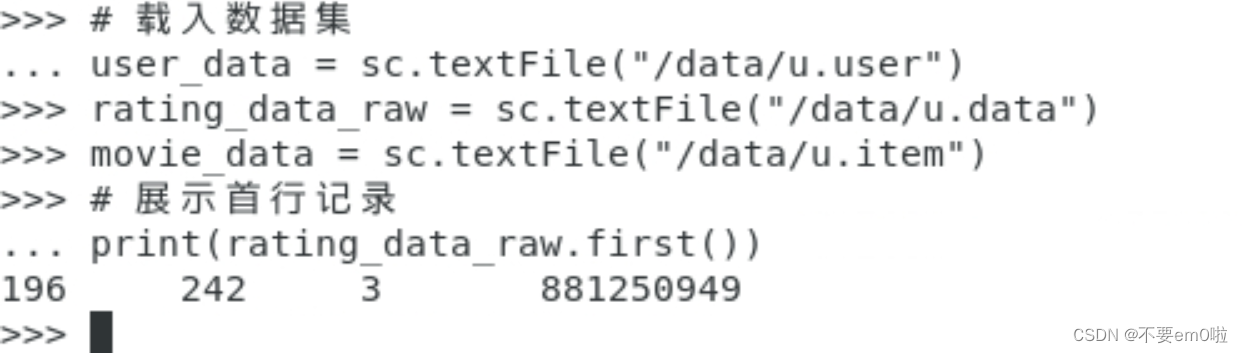
- 查看有多少人参与了评分


- 统计最高、最低、平均、中位评分,以及平均每个用户的评分次数
# 以' | '切分每列,返回新的用户RDD
user_fields = user_data.map(lambda line: line.split("|"))
# 统计用户数
num_users = user_fields.map(lambda fields: fields[0]).count()
# 获取电影数量
num_movies = movie_data.count()
# 获取评分RDD
rating_data = rating_data_raw.map(lambda line: line.split("\t"))
ratings = rating_data.map(lambda fields: int(fields[2]))
# 计算最大/最小评分
max_rating = ratings.reduce(lambda x, y: max(x, y))
min_rating = ratings.reduce(lambda x, y: min(x, y))
# 计算平均/中位评分
mean_rating = ratings.reduce(lambda x, y: x + y) / float(num_ratings)
median_rating = np.median(ratings.collect())
# 计算每个观众/每部电影平均打分/被打分次数
ratings_per_user = num_ratings / num_users
ratings_per_movie = num_ratings / num_movies
# 输出结果
print("最低评分: %d" % min_rating)
print("最高评分: %d" % max_rating)
print("平均评分: %2.2f" % mean_rating)
print("中位评分: %d" % median_rating)
print("平均每个用户打分(次数): %2.2f" % ratings_per_user)
print("平均每部电影评分(次数): %2.2f" % ratings_per_movie)
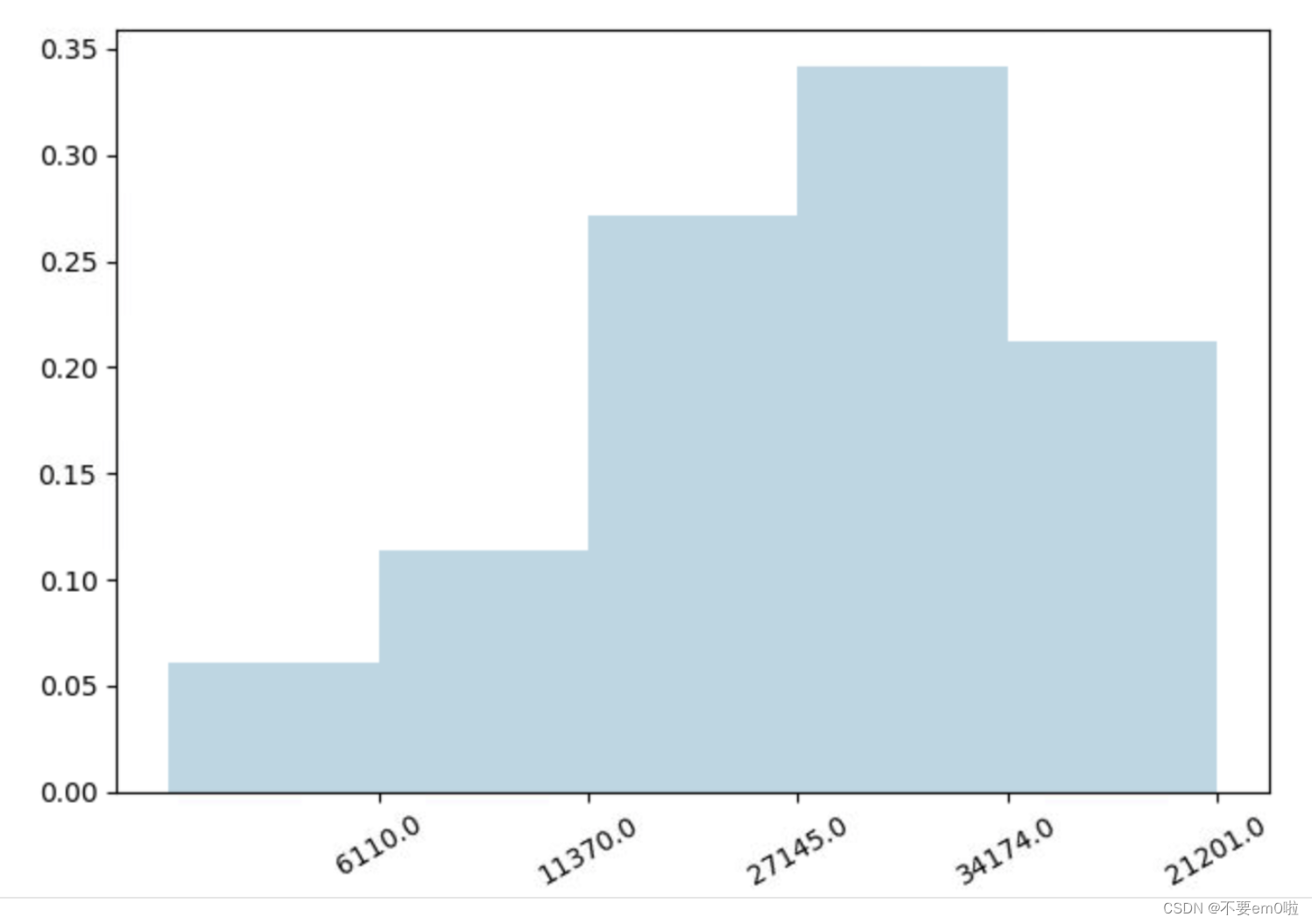
- 统计评分分布情况
# 生成评分统计RDD,并落地
count_by_rating = ratings.countByValue()
# 生成x/y坐标轴
x_axis = np.array(count_by_rating.keys())
y_axis = np.array([float(c) for c in count_by_rating.values()])
# 对人数做标准化
y_axis_normed = y_axis / y_axis.sum()
# 生成x轴标签
pos = np.arange(len(y_axis))
width = 1.0
ax = plt.axes()
ax.set_xticks(pos + (width / 2))
ax.set_xticklabels(y_axis)
# 绘制评分分布柱状图
plt.bar(pos, y_axis_normed, width, color='lightblue')
plt.xticks(rotation=30)
plt.show()