随着大数据技术的迅猛发展,机器学习在各行各业的应用日益广泛。Apache Spark作为大数据处理的利器,其内置的机器学习库MLlib(Machine Learning Library)提供了一套高效、易用的工具,用于处理和分析海量数据。本文将深入探讨Spark MLlib,介绍其核心功能和应用场景,并通过实例展示如何在实际项目中应用这些工具。
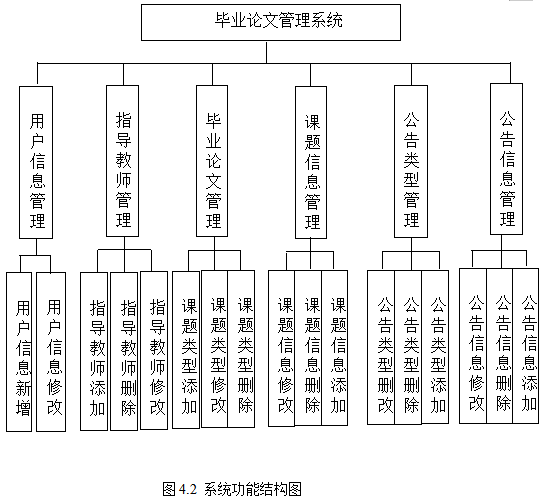
一、Spark MLlib概述
1. 什么是Spark MLlib?
Spark MLlib是Apache Spark框架中的机器学习库,旨在提供可扩展的、高效的机器学习算法。它支持常见的机器学习任务,如分类、回归、聚类和协同过滤等,并提供了特征提取、转换和选择的工具。
2. Spark MLlib的特点
- 高性能:基于Spark的分布式计算引擎,能够处理大规模数据。
- 易用性:提供简单易用的API,支持Scala、Java、Python和R等多种编程语言。
- 丰富的算法:涵盖了广泛的机器学习算法,包括线性回归、逻辑回归、决策树、支持向量机、K均值聚类等。
- 与Spark生态系统无缝集成:可以与Spark SQL、Spark Streaming等组件无缝集成,支持从数据预处理到模型部署的全流程。
3. Spark MLlib的架构
Spark MLlib主要分为两个部分:
- RDD-based API(mllib):基于弹性分布式数据集(RDD)的早期API,提供了一些基本的机器学习算法和工具。
- DataFrame-based API(ml):基于DataFrame的高层次API,提供了更丰富的功能和更高的抽象层次,更推荐使用。
二、Spark MLlib的核心功能
1. 数据预处理
数据预处理是机器学习的重要环节,包括特征提取、转换和选择等步骤。Spark MLlib提供了多种工具来帮助用户进行数据预处理:
- 特征提取:从原始数据中提取特征。例如,
Tokenizer用于将文本数据拆分为单词列表,CountVectorizer用于将文本转换为词频向量。 - 特征转换:将特征转换为适合模型训练的形式。例如,
StandardScaler用于标准