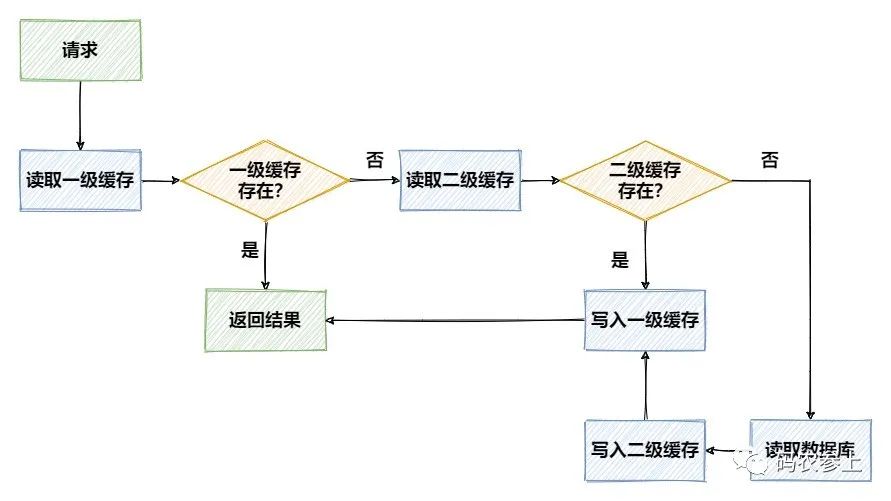
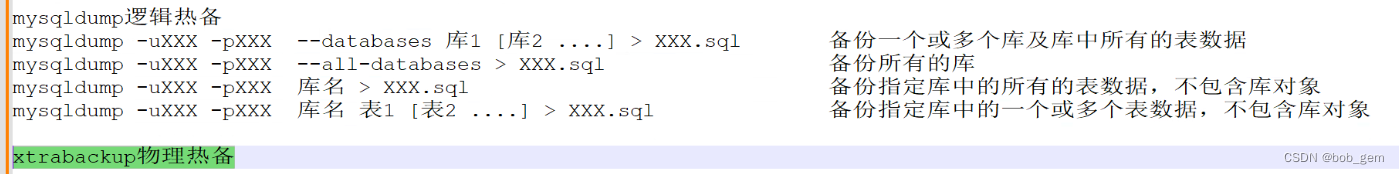备份与恢复
备份与恢复可以防止出现系统崩溃,硬件故障或用户误删除数据等问题,而且在升级mysql数据库之前,备份也是必不可少的一种保护措施。备份恢复还可用于将mysql数据库转移到另一个系统或设置成一个独立的副本服务器。
备份与恢复的作用:
1)做灾难恢复:对损坏的数据进行恢复和还原:还包括了一些误操作所带来的影响。
2)需求改变:因需求改变而需要把数据还原到改变以前
3)测试:测试新功能是否可用
MYSQL主要包括以下几种备份与恢复策略:
1.逻辑备份与物理备份
2.冷备,热备与温备
3.全量备份与增量备份
4.本地备份与远程备份
5.快照备份
6.基于时间点的恢复
7.备份时的压缩与加密
逻辑备份
逻辑备份具有以下特点:
逻辑备份是备份命令通过查询并获取数据库信息和库内对象(表)的信息来完成的。
逻辑备份比物理备份慢,因为逻辑备份必须访问数据库的信息和库内对象信息并将其转换为指定的格式才算备份完成。
逻辑备份输出大于物理备份,尤其是在以文本格式保存时。
逻辑备份与恢复粒度分为服务器级别(MYSQL服务器下所有数据库),数据库级别(指定的数据库下所有的表),表级别。与你时哪种存储引擎没有关系。
备份不包括日志或配置文件。
逻辑备份的优点:
以逻辑备份生成的备份便于传输与保存。
逻辑备份属于一种联机备份行为,不用停数据库。
逻辑备份工具包括mysqldump程序和SELECT …INTO OUTFILE.
这些适用工具产生的逻辑备份文件适用于任何存储引擎,而且恢复起来较为简单,可以直接使用 LOAD DATA语句或mysqlimport进行恢复。
物理备份
物理备份主要用与快速恢复发生严重故障或急需恢复的大型数据库。因为物理备份主要是备份了数据库的数据文件等文件结构,所以可以用与快速恢复。
逻辑备份主要备份了数据库的元数据和用户数据,那么对于数据量比较小的数据库是适用的。而物理备份主要用于大型数据库的恢复。并且物理备份的复用性较强,恢复速度快。
物理备份方法具有以下特点:
备份由数据库的数据文件等文件结构组成。
物理备份方法比逻辑更快,因为他们只涉及文件复制,而不涉及转换。而且物理备份比逻辑备份结构更加清晰和紧凑。
除了数据库必须的文件之外,备份还可以包括任何相关文件,例如日志和配置文件。
MEMORY存储引擎的表中的数据很难以这种方式备份,因为他们的内容没有存储在磁盘上。
(MYSQL Enterprise Backup 产品有一项功能,您可以从MEMORY 表中检索数据并应用于备份)
物理备份的局限性:
备份仅可移植到具有相同或相似硬件的服务器上。
我们可以在mysql数据库停止时执行物理备份也可以在mysql数据库运行时执行物理备份。并且我们要根据现在mysql数据库所处的状态以及存储引擎找到适合的备份策略进行备份。
物理备份工具包括官方的mysqlbackup工具,IBBACKUP工具,XTRABACKUP工具或系统级命令(cp,scp,tar ,rsync)。
对于恢复:
MySQL Enterprise Backup 可以还原InnoDB上的表。
ndb_restore恢复工具
使用系统级命令复制的文件可以通过复制黏贴命令将备份恢复到原始位置。
MYSQL的冷备,热备与温备
1.根据是否需要数据库离线
冷备:在数据库彻底关闭状态下,读写请求均不允许状态下进行备份;
热备:在数据库运行状态下进行备份,这种备份不影响正常的数据库业务。
温备:在数据库运行状态下进行备份,此时仅支持对数据库中数据的读请求,不允许写请求。
注:
1.根据你的需求选择合适的备份策略。
2.MyISAM不支持热备,InnoDB支持热备,但是需要专门的工具。因为MyISAM不支持事务,所以只能使用温备去进行在线备份。
全量(完整)备份与增量备份与差异备份
备份所有选定的文件和目录,并且不依靠文件的存档属性来确定要备份的文件。在备份过程中,将清除所有现有标记,并将每个文件标记为已备份。换句话说,清除存档属性。
全量备份是指在特定时间点数据库中所有数据去做一个完整副本。
这种备份方法的最大优点是,只要有全量备份,就可以恢复丢失的数据。因此极大地加快了系统或数据的恢复时间。但是,它的缺点是,每次备份都有可能破坏InnoDB的数据命中率。另外,由于每次需要备份的数据量很大,因此备份需要很长时间。
增量备份针对自上次备份以来已更改的备份数据(包括全量备份,增量备份)去进行备份。在增量备份期间,仅备份已标记(需要备份)的文件和目录,备份完成后它会清除标记,即:备份后清除文件或目录上的需要备份的标记。换句话说,清除存档属性。
增量备份意味着在完全备份或上一次增量备份之后,每个后续备份仅需要备份与前一个备份相比已添加或发生改变的目录或文件。这意味着第一个增量备份的对象是完全备份后生成的目录或发生INSERT,UPDATE,以及DELETE操作的数据文件。
这种备份的可靠性较差。在这种备份下,每个备份关系就像一条链,一个接一个,任何备份损坏都会导致整个链断开。此备份方法最明显的优点是没有重复的备份数据,因此备份数据量不大,并且备份所需的时间非常短。但是增量备份的数据恢复比较麻烦。你必须具有最后的完整备份和所有增量备份才能完全恢复,因此这大大延长了恢复时间。
差异备份是指备份自上次全量备份以来已更改的数据。在差异备份过程中,仅备份那些已标记的文件和目录。它不会清除标记,也就是说,备份后未将其标记为备份文件。换句话说,未清除存档属性。
差异备份是指在完全备份后到差异备份时已发生添加或修改的数据文件或目录的备份。还原时,我们只需要还原第一个全量备份和最后一个差异备份。
差异备份具有自己的优势,同时避免了其他全量和增量备份策略的缺点。首先,它的优点是备份时间短,节省磁盘空间。DBA只需要全量备份和最后一个差异备份即可还原数据库系统。
差异备份的缺点是它里面会存在重复数据。
本地备份与远程备份
本地备份就是把本地执行备份命令以后所产生的结果文件保存到本地服务器上。
远程备份就是在其他的服务器上启动MYSQL的远程客户端连接功能进行备份,那么所产生的备份文件就一定保存在了你发起命令的那台机器上。
快照热备
快照热备功能主要依靠MYSQL的文件结构所在的存储服务器或者LVM以及文件系统上自己所特有的快照功能进行备份。
比如说LVM的卷组复制功能和一些比较好的存储服务器上自带的存储快照功能,还有比如说ZFS的快照功能等。
这种备份不属于MYSQl所能实现的范围,而是要依靠MYSQL数据库和MYSQL数据库文件结构所在的存储服务器与文件系统所提供的相关功能去实现的。
基于时间点的恢复
从全量备份中恢复数据,这会将我们的mysql数据库恢复到它进行全量备份时的数据库状态。如果该状态还是无法满足我们的一些恢复需要的话,则可以在全量恢复之后执行自全量备份以来所做的增量备份或差异备份,使数据库中的数据状态更新。
增量备份或差异备份时对给定时间跨度内所做更改的恢复。这也称为时间点恢复,因为它使服务器的状态在给定时间内保持最新。
还有一种时间点恢复:
利用二进制日志可以实现基于时间与位置的恢复,例如由于误删除了一张表,这时候完全恢复是没有用的,因为日志里面还是存在错误语句的,我们需要的是恢复到误操作之前的状态,然后跳过误操作数据,再恢复后面操作语句。
备份时的压缩和加密
指的是MYSQL备份的过程中我们可以使用相关的压缩参数,将备份文件进行压缩,并且可以给相关的备份文件进行加密。
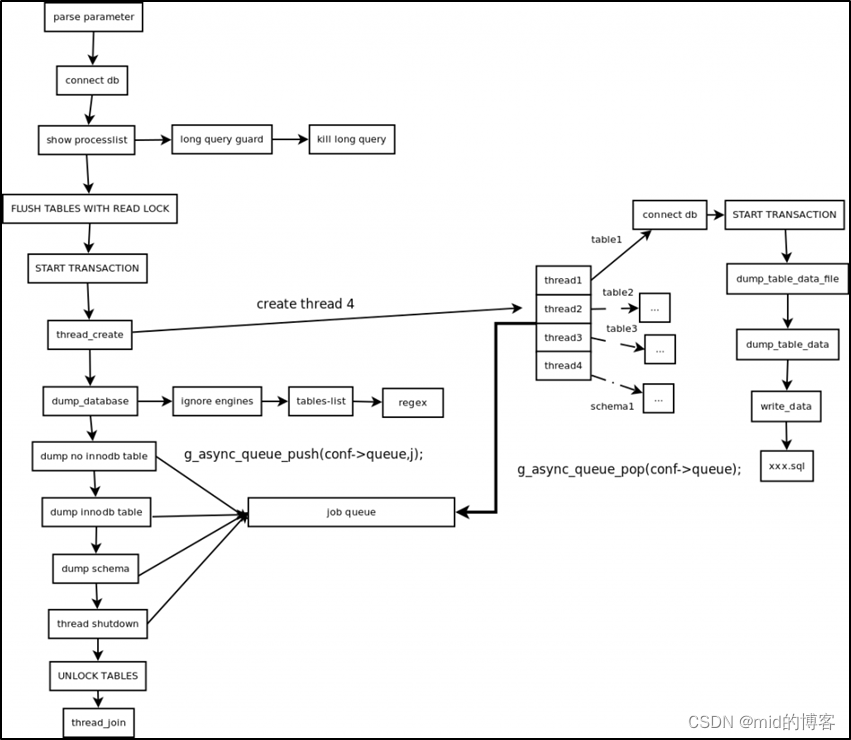
使用mysqldump备份全库
逻辑备份:逻辑备份的是数据库中的元数据和用户数据(DDL DML,DCL)。适用于中小型数据库,效率相对较低。一般在数据库正常提供服务的前提下进行,如mysqldump,select into outfile(表的导出导入)等。
备份的实质:就是把要备份的数据导成.sql或.txt或.csv文件。
mysqldump(逻辑备份,只能全量备份,没有办法使用此单一工具做增量备份)
1)企业版和社区版都包含。
2)本质上使用SQL语句描述数据库及数据导出
3)在MYISAM引擎上锁表,InnoDB引擎上锁行
4)数据量很大时不推荐使用
在不同参数的配合下,备份方式各有所不同,因为mysqldump是以查询数据库的方式进行备份。
mysqldump使用实例:
1.将数据库内的数据全部导出(linux下执行)
mysqldump -uroot -proot --all-database > /tmp/all_db.sql
--远程备份(哪台机器发起的命令,文件就在哪台机器)
mysqldump -h 192.168.100.57 -P 3306 -uroot -proot --all-database > /tmp/all_db.sql;
2.将备份后数据库内的数据全部重新导入回去(linux下执行)
mysql -uroot -proot < /tmp/all_db.sql
3.每个数据库创建之前添加drop数据库语句(--add-drop-database)
mysqldump -uroot -proot --all-database --add-drop-database > /tmp/all_db.sql
4.在每个数据表创建之前加drop数据表语句(默认为打开状态,使用 --skip-add-drop-table取消选项)
mysqldump -uroot -proot --all-database (默认添加drop语句)
mysqldump -uroot -proot --all-database --skip-add-drop-table (取消drop语句)
5.在每个表导出之前增加 LOCK TABLES 并且之后UNLOCK TABLE。(默认为打开状态,使用--skip-add-locks取消选项)
mysqldump -uroot -proot --all-database (默认添加LOCK语句)
mysqldump -uroot =proot --all-database --skip-add-locks (取消lock语句)
6.备份开始时,备份相关操作会请求锁定所有数据库中的表,以保证数据的一致性,这时一个全局读锁,并且自动关闭 --single
-transaction 和 --lock-tables选项
mysqldump -uroot -proot --host=localhost --all-database --lock-all-tables
7.备份过程中依次锁住每个数据库下所有的表,一般用于myisam存储引擎,备份时只能对数据库进行读操作,对于innodb存储引擎,不需要该参数,用 --single-transaction即可
注意当导出多个数据库时,--lock-tables 分别为每个数据库锁定表,因此,该选项不能保证导出文件中的表与数据库之间的逻辑一致性。不同数据库的导出状态可以完全不同
注意LOCK TABLE 会使任何挂起的事务隐含提交,前提是你的autocommit参数是否开启状态
mysqldump -uroot -proot --host=loclhost --all-database --lock-tables
8.--single-transaction 和 --lock-table是互斥的,此选项会将隔离级别设置为重复读,并且随后再执行一条 start transaction 语句,让整个数据在dump过程中保证数据的一致性,这个选项对innodb的数据表很有用,且不会锁表,但是这个不能保证myISAM表和MEMORY表的数据一致性。
为了确保使用 --single-transaction命令时,保证dump文件的有效性,需没有下列语句ALTER TABLE,CREATE TABLE,DROP TABLE,RENAME TABLE,TRUNCATE TABLE.因为一致性读不能隔离上述语句,所以如果在dump过程中,使用上述语句,要想导出大表的话,应该结合使用 --quick选项
--quick
不缓冲查询,直接导出到标准输出,默认为打开状态,使用 --skip-quick取消该选项
mysqldump -uroot -proot --host=localhost --all-database
mysqldump -uroot -proot -host=localhost --all-database --skip-quick
mysqldump -uroot -proot -host=localhost --all-database --single-transaction
9.导出某个数据库
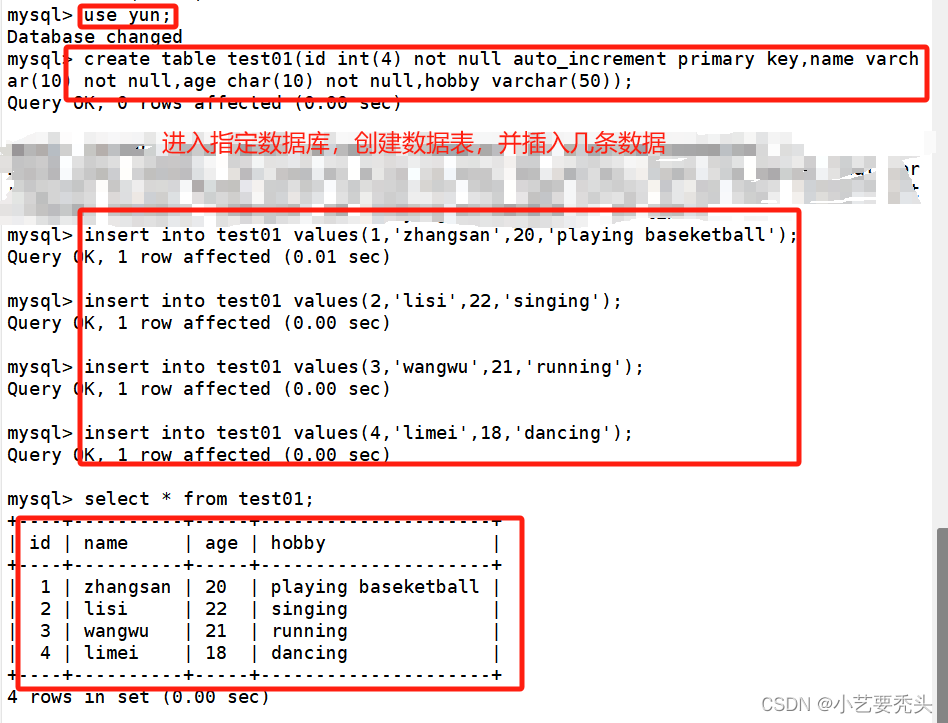
mysqldump -uroot -proot --databases hr > /tmp/hr.sql
10.导出多个数据库
mysqldump -uroot -proot --databases hr hr1 >/tmp/hr_hr1.sql
11.由sql文件导入某个库中(mysql客户端下执行)
source /tmp/hr.sql
使用mysqldump备份还原指定表
1.导出单个表
mysqldump -uroot -proot hr test > /tmp/test.sql
mysqldump -uroot -proot --databases hr --tables test > /tmp/test.sql (正规写法)
2.导出多个表
```html
mysqldump -uroot -proot hr test emp > /tmp/test_emp.sql
3.导出视图``
mysqldump -uroot -proot hr emp_v > /tmp/emp_v.sql
4.若数据中,某些表除外,其余表都需要导出,并设置字符集
mysqldump -uroot -proot --default-character-set=utf8mb4 hr --ignore-table=hr.departments --ignore-table=hr.emp >/tmp/ig.sql
5.sql文件导入到数据(进入mysql服务端,先选择数据库,再执行命令)
source /tmp/test.sql
6.导出带有过滤条件的数据在这里插入代码片
mysqldump -uroot -proot hr emp --where="emp_id < 150" > /tmp/emp.sql5tbv
使用mysqldump备份表结构
1.不导出任何数据,只导出数据库中所有表结构
mysqldump -uroot -proot --all-databases --no-data > /tmp/all_meta.sql
mysqldump -uroot -proot -A --no-data > /tmp/all_meta.sql(简化命令方式)
mysqldump -uroot -proot -A -d > /tmp/all_meta.sql(简化命令方式)
2.不导出任何数据,只导出某个数据库中的所有表结构
mysqldump -uroot -proot hr --no-data > /tmp/hr.sql
mysqldump -uroot -proot --databases hr --no-data > /tmp/hr.sql
--不导出任何数据,多个数据库所有表的结构
mysqldump -uroot -proot --databases hr hr1 --no-data > /tmp/hr_hr1.sql
3.不导出任何数据,只导出某个数据库中某个表的结构
mysqldump -uroot -proot hr emp --no-data > /tmp/emp.sql
mysqldump -uroot -proot --databases hr --tables test --no-data > /tmp/emp.sql
--不导出任何数据,导出多个表的结构
mysqldump -uroot -proot --databses hr --tables emp dep --no-data > /tmp/emp_dep.sql
4.只导出数据库下表的数据,不导出结构
mysqldump -uroot -proot --all-databases --no-create-info > /tmp/all_data.sql
--某个数据库的数据
mysqldump -uroot -proot hr --no-create-info > /tmp/hr_data.sql
--多个数据库的数据
mysqldump -uroot -proot --databases hr hr1 --no-create-info > /tmp/hr_hr1.sql
--某个表的数据
mysqldump -uroot -proot hr emp --no-create-info > /tmp/emp_data.sql
--d多个表的数据
mysqldump -uroot -proot hr emp dept --no-data > /tmp/emp_dept_data.sql
使用SELECT INTO OUTFILE语句导出数据
SELECT INTO OUTFILE 语句就是把查询到的结果给你保存到外部文件中,可以是.txt也可以是,csv,总之按照你要求的格式进行数据导出。
SELECT INTO OUTFILE语句相关语法格式:
select * from table into outfile '/路径/文件名‘ CHARACTER SET (你指定的字符集)
FIELDS TERMINATED BY ‘,’
ENCLOSED BY ’ " ’
ESCAPED BY ’ \ ’
LINES TERMINATED BY ‘\n’;
语句的注意事项:
(1)必须要对文件写入的路径具有相关的读写权限,一般使用的都是 /tmp
(2)文件名必须唯一,不允许出现同名文件。
(3)FIELDS TERMINATED BY ’ , ',必须存在,否则打开的文件列将无法区分,我们必须要给导出的数据添加分隔符
(4)指定正确的字符集
fields子句:在FIELDS子句中有三个亚子句:TERMINAED BY,[OPTIONALLY] ENCLOSED BY 和ESCAPED BY 。如果指定了FIELDS子句,则这三个亚子句中至少要指定一个。
(1)TERMINATED BY 用来指定字段值之间的符号(间隔符),例如:“TERMINATED BY ‘,’ ”指定了逗号作为两个字段值之间的标志。
(2)ENCLOSED BY用来指定字段值之间的符号(间隔符),例如:ENCLOSED BY ’ " '表示文件中字符类型的值放在双引号之间。
OPTIONALLY 用来区分数值类型还是字符类型,如果不加的话,都按照字符类型处理。
(3)ESCAPED BY子句用来指定转义字符,不加这个子句,空值默认是\N,如果加上这个子句,例如,ESCAPED BY '@ ’ 指定为转义字符,取代“\”,如将因空值(null)导出的空格将表示为“ @N ”。
LINES子句:在LINES 子句中使用 TERMINATED BY 指定一行结束的标志,如 LINES TERMINATED BY '?'表示一行以“ ?”作为结束标志,但通常使用“\n”即换行。
select * from hr.employees into outfile '/tmp/emp.sql' CHARACTER SET utf8mb4
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n';
报错:ERROR:The mysql server is running with the --secure-file-priv option so it cannot execute this statement
这个报错的意思是我们无法去执行相关的导出操作,因为有文件操作的安全限制。那么我们查看一下相关的值
show variables like '%secure%';
结果:
------------------------------------------------------
variable_name |value
------------------------------------------------------
require_secure_transport |OFF
secure_auth |ON
secure_file_priv |NULL
------------------------------------------------------
secure_file_priv 的值有三种情况:
secure_file_priv=null --限制mysql 不允许导入导出
secure_file_priv=/path/ --限制mysql的导入导出只能发生在默认的/path/目录下
secure_file_priv='' --不对mysql的导入导出做限制
执行命令:
set secure_file_priv = '';
不允许修改的话,修改my.cnf
在里面添加
secure_file_priv=''保存重启mysql
结果文件中显示:
"100","steven","king","515.123.456","1987-01-23 00:00:00","24000",\N,\N,"90"
"102","kon","king","515.123.456","1987-01-23 00:00:00","24000",\N,\N,"90"
--添加OPTIONALLY
select * from hr.employees into outfile '/tmp/emp.sql' CHARACTER SET utf8mb4
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n';
结果文件中显示:
100,"steven","king","515.123.456","1987-01-23 00:00:00","24000",\N,\N,"90"
102,"kon","king","515.123.456","1987-01-23 00:00:00","24000",\N,\N,"90"
LOAD DATA语句导入到数据库
LOAD DATA语句作用:
将文件中的数据快速导回到mysql数据库中。
数据库应用程序开发中,涉及大批量数据需要插入时,使用load data语句的效率比insert 语句快很多。
相关参数:
load data local infile ‘/文件路径’ into table 表名
CHARACTER SET utf8mb4 --设定字符集
FIELDS TERMINATED BY ‘,’ --字段分隔符
OPTIONALLY ENCLOSED BY ’ " ’ --字符限定符
ESCAPED BY ‘\’ --转义符,默认时遇到表中有空值的时候一定要注意这里,这里用两个\表示一个\。
LINES TERMINATED BY ‘\n’ --换行符,如字段本身也含\n,那么应先去除,否则 load data 会误将其视为另一行记录进行导入。
create table emp1 as select * from emp where 1=2;
select * from hr.emp into outfile '/tmp/emp.txt'
CHARACTER SET utf8mb4
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
ESCAPED BY '\\'
LINES TERMINATED BY '\n';
load data local infile '/tmp/emp.txt' into table hr.emp1
CHARACTER SET utf8mb4
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
ESCAPED BY '\\'
LINES TERMINATED BY '\n';