一.微服务保护
1.初识Sentinel
- 雪崩问题及解决方案
- 微服务调用链路中的某个服务故障,引起整个链路中的所有微服务都不可用,这就是雪崩。
- 解决方案
- 超时处理:设置超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待
- 舱壁模式:限定每个业务能使用的线程数,避免耗尽整个tomcat的资源,因此也叫线程隔离
- 熔断降级:由断路器统计业务执行的异常比例,如果超出阈值会熔断该业务,拦截该业务的一切请求
- 流量控制:限制业务访问的QPS,避免服务因流量的突增而故障
2.微服务整合Sentinel
引入sentinel依赖
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency>配置控制台地址
spring: cloud: sentinel: transport: dashboard: localhost:8080
3.限流
簇点链路
- 就是项目内的调用链路,链路中被监控的每个接口就是一个资源,默认情况下sentinel会监控springMVC的每一个端点,因此springMVC的每一个端点就是调用链路的一个资源
流控模式有哪些?
- 直接:对当前资源限流
- 关联:高优先级资源触发阈值,对低优先级资源限流
- 链路:阈值统计时,只统计从指定资源进入当前资源的请求,是对请求来源的限流
sentinel默认只标记Controller中的方法资源,要标记其他方法,需要使用@SentinelResource注解
关闭将Controller方法做两content整合,否则链路模式失效
spring: cloud: sentinel: transport: dashboard: localhost:8080 web-context-unify: false流控效果
- 快速失败:达到阈值后,新的请求会被立即拒绝并抛出FlowException异常,默认处理方式
- warm up:预热模式,对超出阈值的请求同样是拒绝并抛出异常。但这种模式阈值会动态变化,从一个较小值逐渐加到最大阈值
- 排队等待:让所有的请求按照先后次序排队执行,两个请求的间隔不能小于指定时长
热点参数限流
- 分别统计参数值相同的请求,判断是否超过QPS阈值(热点参数限流对默认的springMVC资源无效)
4.隔离和降级
虽然限流可以避免因高并发而引起的服务故障,但服务还会因为其他原因而故障。而要将这些故障控制在一定范围,避免雪崩,就要靠线程隔离和熔断降级手段了。
Feign整合Sentinel
修改OrderService的application.yml文件,开启Feign的Sentinel功能
feign: client: config: default: # 这里是default就是全局配置,如果是写服务名,则针对某个微服务的配置 logger-level: FULL # 日志级别 sentinel: enabled: true # 开启Sentinel给FeignClient编写失败后的降级逻辑
方式一:FallbackClass,无法对远程调用的异常做处理
方式二:FallbackFactory:可以对远程调用的异常做处理
在feign-api项目中定义类,实现FallbackFactory
@Slf4j public class UserClientFallbackFactory implements FallbackFactory<UserServiceClient> { @Override public UserServiceClient create(Throwable throwable) { return new UserServiceClient() { @Override public User findById(Long id) { // 记录信息异常 log.error("查询用户失败" , throwable); // 根据业务需要返回数据 return new User(); } }; } }在配置类中注入该回调类
@Configuration public class FeignClientConfiguration { @Bean public Logger.Level feignLogLevel() { return Logger.Level.FULL; } @Bean public UserClientFallbackFactory userClientFallbackFactory() { return new UserClientFallbackFactory(); } }在UserserviceClient中指定失败回调
@FeignClient(value = "userservice" , fallbackFactory = UserClientFallbackFactory.class) public interface UserServiceClient { @GetMapping("user/{id}") User findById(@PathVariable Long id); }
线程隔离
- 线程池隔离:基于线程池,有额外开销,但隔离性更强
- 信号量隔离(Sentinel默认采用):基于技术器模式,简单,开销小
熔断降级
- 断路器熔断策略:
- 慢调用:业务的响应时长大于指定时长的请求认定为慢调用请求。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断
- 异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断
- 断路器熔断策略:
5.授权规则
授权规则可以对调用方的来源做控制,有白名单和黑名单两种方式
在gateway中添加全局过滤器,添加请求头
spring: application: name: gateway cloud: nacos: server-addr: localhost:8848 # nacos地址 gateway: routes: # 网关路由配置 - id: user-service # 路由id 自定义 uri: lb://userservice # 路由的目标地址 lb是负载均衡 predicates: # 路由断言 - Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求 - id: order-service uri: lb://orderservice predicates: # 路由断言 - Path=/order/** # 这个是按照路径匹配,只要以/order/开头就符合要求 filters: - AddRequestHeader=color, blue default-filters: - AddRequestHeader=origin, gatewaySentinel通过RequestOriginParser这个接口的parseOrigin来获取请求的来源
@Component public class HeaderOriginParser implements RequestOriginParser { @Override public String parseOrigin(HttpServletRequest request) { String origin = request.getHeader("origin"); if (StringUtils.isEmpty(origin)){ origin = "blank"; } return origin; // 该结果会被sentinel定义的授权规则检验 } }在sentinel控制台中定义授权规则
自定义异常结果
默认情况下,发生限流、降级、授权拦截时,都会抛出异常到调用方限流异常,自定义异常返回结果需要实现BlockExceptiionHandler
BlockExceptiionHandler的子类
异常 说明 FlowException 限流异常 ParamFlowException 热点参数限流异常 DegradeException 降级异常 AuthorityException 授权规则异常 SystemBlockException 系统规则异常 实现BlockExceptiionHandler
@Component public class SentinelExceptionHandler implements BlockExceptionHandler { @Override public void handle(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, BlockException e) throws Exception { String msg = "未知异常"; int status = 429; if (e instanceof FlowException) { msg = "请求被限流"; } else if (e instanceof ParamFlowException) { msg = "热点参数限流"; } else if (e instanceof DegradeException) { msg = "请求被降级"; } else if (e instanceof AuthorityException) { msg = "授权规则异常"; status = 401; } else if (e instanceof SystemBlockException) { msg = "系统规则异常"; } httpServletResponse.setContentType("application/json;charset=utf-8"); httpServletResponse.setStatus(status); httpServletResponse.getWriter().println("msg:" + msg + " " + "status:" + status); } }
6.规则管理模式
原始模式:Sentinel的默认模式,讲规则保存在内存中,重启服务丢失
pull模式:控制台将配置的规则推送到Sentinel客户端,而客户端会将配置规则保存在本地文件或数据库中。以后会定时去本地文件或数据库中查询,更新本地规则。
push模式:控制台将配置规则推送到远程配置中心。监听变更实时更新
二、分布式事务
1.什么是分布式事务?
- 在分布式系统下,一个业务跨越多个服务或数据源,每个服务都是一个分支事务,要保证所有分支事务最终状态一致,这样的事务就是分布式事务。
2.理论基础
CAP定理:分布式系统三个指标,分布式系统无法同时满足这三个指标。
- 分布式系统节点通过网络连接,一定会出现分区问题
- 当分区出现时,系统的一致性和可用性就无法同时满足
- Consistency(一致性):用户访问分布式系统的任意节点,得到的数据必须一致
- Availability(可用性):用户访问集群中的任意健康节点,必须能得到响应,而不是超时拒绝
- Partition tolerance(分区容错性)
- Partition(分区): 因为网络故障或其他原因导致分布式系统中的部分节点与其他节点失去连接,形成独立分区。
- Tolerance(容错):在集群出现分区时,整个系统也要持续对外提供服务
BASE理论:BASE理论是对CAP的一种解决思路,包含三个思想
- Basically Available(基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用
- Sorf State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
分布式事务最大的问题是各个子事物的一致性问题,可以借鉴CAP定理和BASE理论
- AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致
- CP模式:各个子事务执行相互等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态
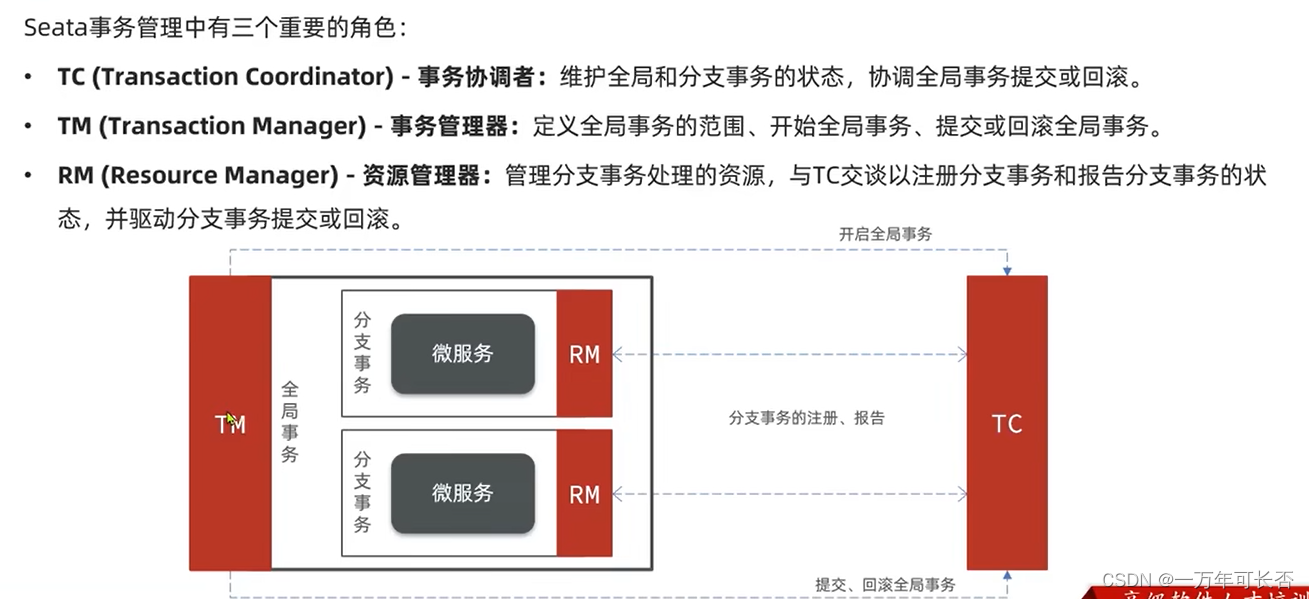
分布式事务模型:解决分布式事务,各个子系统之间必须能感知到彼此的事务状态,才能保证状态一致,因此需要一个事务协调者来协调每个一个事务的参与者(子系统事务)。
- 子系统事务称为分支事务,有关联的各个分支事务在一起称为全局事务
3.部署与集成Seata
4.Seata的四种模式
XA模式(强一致性):XA规范是X/Open组织定义的分布式事务处理标准,XA规范描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对XA规范提供了支持。
Seata的XA模式
- RM一阶段的工作:
- 注册分支事务到TC
- 执行分支业务SQL但不提交
- 报告执行状态到TC
- TC二阶段的工作:TC检测各分支事务执行状态
- 如果都成功:通知所有RM提交事务
- 如果有失败:通知所有RM回滚事务
- RM二阶段的工作:接收TC指令,提交或回滚事务
- RM一阶段的工作:
XA模式的优点
- 事务一致性强,满足ACID原则
- 常用数据库都支持,实现简单,并且没有代码侵入
- 缺点:
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- 依赖关系型数据库实现事务
实现XA模式
修改application.yaml文件(每个参与事务的微服务),开启XA模式
seata: registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址 # 参考tc服务自己的registry.conf中的配置 type: nacos nacos: # tc server-addr: 127.0.0.1:8848 namespace: "" group: DEFAULT_GROUP application: seata-tc-server # tc服务在nacos中的服务名称 cluster: SH tx-service-group: seata-demo # 事务组,根据这个获取tc服务的cluster名称 service: vgroup-mapping: # 事务组与TC服务cluster的映射关系 seata-demo: SH data-source-proxy-mode: XA #开启数据源代理的XA模式给发起全局事物的入口方法添加@GlobalTransactional注解
@Override @GlobalTransactional public Long create(Order order) { // 创建订单 orderMapper.insert(order); try { // 扣用户余额 accountClient.deduct(order.getUserId(), order.getMoney()); // 扣库存 storageClient.deduct(order.getCommodityCode(), order.getCount()); } catch (FeignException e) { log.error("下单失败,原因:{}", e.contentUTF8(), e); throw new RuntimeException(e.contentUTF8(), e); } return order.getId(); }
AT模式:AT模式同样是分阶段提交事务模型,不过弥补了XA模型中资源锁定周期过长的缺陷。
Seata的AT模式
- 阶段一RM工作:
- 记录undo_log(数据快照)
- 执行业务sql并提交
- 报告事务状态
- 阶段二提交时RM的工作:删除undo_log即可
- 阶段二回滚时RM的工作:根据undo_log恢复数据到更新前
- 阶段一RM工作:
AT模式与XA模式最大的区别是?
- XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源
- XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚
- XA模式强一致;AT模式最终一致
AT模式的优点
- 一阶段完成直接提交事务,释放数据库资源、性能较好
- 利用全局锁实现读写隔离
- 没有代码侵入,框架自动完成回滚和提交
AT模式的缺点
- 两阶段之间属于软状态,属于最终一致
- 框架的快照功能会影响性能,但比XA模式好很多
实现AT模式与XA模式不同的是仅需修改yaml文件事务所实现方式
seata: registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址 # 参考tc服务自己的registry.conf中的配置 type: nacos nacos: # tc server-addr: 127.0.0.1:8848 namespace: "" group: DEFAULT_GROUP application: seata-tc-server # tc服务在nacos中的服务名称 cluster: SH tx-service-group: seata-demo # 事务组,根据这个获取tc服务的cluster名称 service: vgroup-mapping: # 事务组与TC服务cluster的映射关系 seata-demo: SH data-source-proxy-mode: AT #开启数据源代理的AT模式
TCC模式
原理::TCC模式与AT模式非常相似,每阶段都是独立事务,不同的是TCC通过人工编码来实现恢复数据。需要实现3个方法:
- Try:资源的检测和预留
- Confirm:完成资源操作业务;要求Try成功Confirm要能成功。
- Cancel:预留资源释放,可以理解为try的反向操作
TCC模式的优点
- 一阶段直接提交事务,释放数据库资源,性能好
- 相比于AT模型,无需生成快照,无需使用全局锁,性能最强
- 不依赖数据库业务,而是依赖补偿操作,可以用于非事务型数据库
TCC模式的缺点
- 有代码侵入,需要人为编写try,confirm,cancel接口,太麻烦
- 软状态,食物最终一致
- 需要考虑Confirm和Cancel失败的情况,做好幂等处理
实现TCC
准备数据库冻结表
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for account_freeze_tbl -- ---------------------------- DROP TABLE IF EXISTS `account_freeze_tbl`; CREATE TABLE `account_freeze_tbl` ( `xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `user_id` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `freeze_money` int(11) UNSIGNED NULL DEFAULT 0, `state` int(1) NULL DEFAULT NULL COMMENT '事务状态,0:try,1:confirm,2:cancel', PRIMARY KEY (`xid`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = COMPACT; -- ---------------------------- -- Records of account_freeze_tbl -- ---------------------------- SET FOREIGN_KEY_CHECKS = 1;编写TCC业务逻辑层接口
@LocalTCC public interface TCCAccountService { @TwoPhaseBusinessAction(name = "deduct" , commitMethod = "confirm" , rollbackMethod = "cancel") void deduct(@BusinessActionContextParameter(paramName = "userId") String userId , @BusinessActionContextParameter(paramName = "money") int money); boolean confirm(BusinessActionContext ctx); boolean cancel(BusinessActionContext ctx); }实现TCC业务逻辑接口
@Service public class TCCAccountServiceImpl implements TCCAccountService { @Autowired private AccountMapper accountMapper; @Autowired private AccountFreezeMapper accountFreezeMapper; @Override @Transactional public void deduct(String userId, int money) { String xid = RootContext.getXID(); // 防止业务悬挂 AccountFreeze oldFreeze = accountFreezeMapper.selectById(xid); if (oldFreeze != null) { // cancel执行过,拒绝执行 return; } // 扣款 accountMapper.deduct(userId , money); // 记录冻结资金 AccountFreeze freeze = AccountFreeze.builder() .freezeMoney(money) .xid(xid) .userId(userId) .state(AccountFreeze.State.TRY).build(); accountFreezeMapper.insert(freeze); } @Override public boolean confirm(BusinessActionContext ctx) { String xid = ctx.getXid(); int count = accountFreezeMapper.deleteById(xid); return count == 0; } @Override public boolean cancel(BusinessActionContext ctx) { AccountFreeze freeze = accountFreezeMapper.selectById(ctx.getXid()); // 获取UserId String userId = ctx.getActionContext("userId").toString(); // 防止空回滚 if (freeze == null) { AccountFreeze freezeNUll = AccountFreeze.builder() .state(AccountFreeze.State.CANCEL) .xid(ctx.getXid()) .userId(userId) .freezeMoney(0) .build(); accountFreezeMapper.insert(freezeNUll); return true; } // 幂等判断 if (freeze.getState() == AccountFreeze.State.CANCEL) { return true; } // 回滚数据 accountMapper.refund(freeze.getUserId(), freeze.getFreezeMoney()); // 设置事务状态为cancel freeze.setState(AccountFreeze.State.CANCEL); int count = accountFreezeMapper.updateById(freeze); return count == 1; } }
Saga模式:Saga模式是seata提供的长事务解决方案。
Saga的两个阶段
- 一阶段:直接提交本地事务
- 二阶段:成功则什么都不做,失败则通过编写补偿业务代码来回滚
Saga模式的优点
- 事务参与者可以基于事件驱动实现异步调用,吞吐高
- 一阶段直接提交事务,无锁,性能好
- 不用编写TCC中的三个阶段,实现简单
缺点:
- 软状态持续时间不确定,时效性差
- 没有锁,没有事务隔离,会有脏写
5.Seata高可用
三、分布式缓存
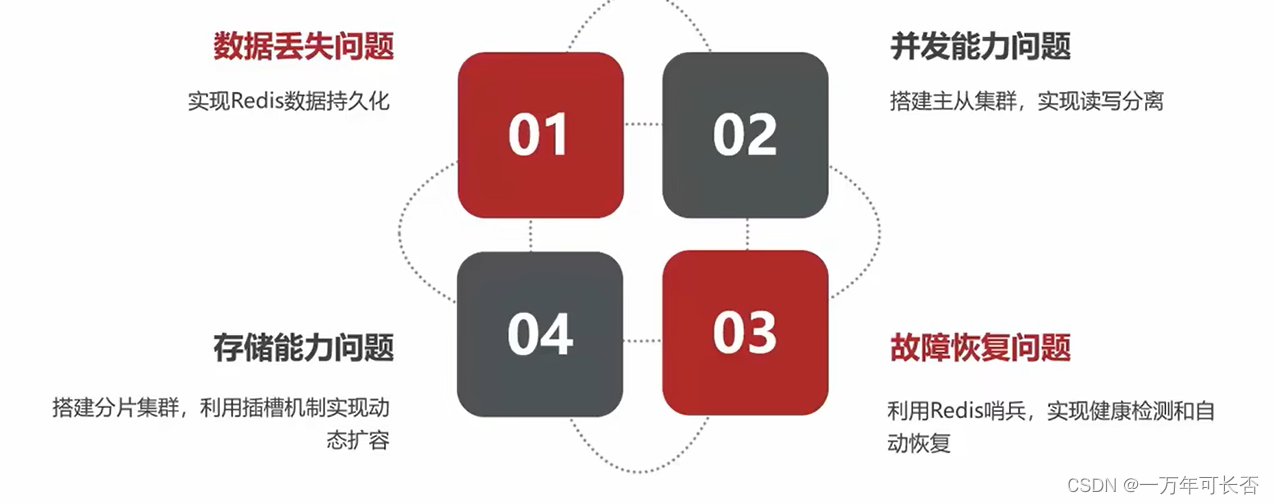
1.Redis持久化
- RDB持久化:全称Redis DataBase Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启时,从磁盘读取快照文件,恢复数据
- RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新的RDB文件替换旧的RDB文件
- RDB什么时候执行?save 60 1000代表什么含义?
- 默认是服务正常停止时
- 代表60秒内至少执行1000次修改则触发RDB
- RDB的缺点?
- RDB执行间隔时间长,两次RDB之间写入数据有丢失风险
- fork子进程、压缩、写出RDB文件都比较耗时
- RDB方式bgsave的基本流程?
- AOF持久化:AOF全称为Append Only File(追加文件)。Redis处理的每一个写命名都会记录在AOF文件,可以看做是命令日志文件。
2.搭建主从架构与哨兵模式
3.RedisTemplate的哨兵模式
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层使用lettuce实现了节点的感知和自动切换
实现
在pom文件中引入redis的starter依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>然后在配置application.yml中指定sentinel的信息
spring: redis: sentinel: master: mymaster # 指定master 名称 nodes: # 指定redis-sentinel集群信息 - 192.168.88.101:27001 - 192.168.88.101:27002 - 192.168.88.101:27003配置主从读写分离
@Bean public LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer() { return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED); }
4.Redis分片集群
搭建分片集群
散列插槽
Redis会把每一个master节点映射到0~16383共16384个插槽上(hash slot)。数据key不是与节点绑定,而是与插槽绑定,Redis会根据key的有效部分计算插槽值。分两种情况:
- key中包含“{}”,且“{}”中至少包含一个字符,“{}”中的部分是有效部分
- key中不包含“{}”,整个key都是有效部分
Redis如何判断某个key在集群中哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在的实例即可
如何将同一类数据固定的保存在同一个Redis实例?
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
集群伸缩
添加一个节点到集群
# 后一个参数为集群中已存在的节点 redis-cli --cluster add-node 192.168.88.101:7004 192.168.88.101:7001为新节点分配分片
# 找出要被分配的节点 redis-cli --cluster reshard 192.168.88.101:7001 # 指定要移动的分片的数量 3000 # 接收者的redis集群ID 739892758277523532hf24h4v2 # 指定数据源ID 1824771274fsd88h43242h5532 # 结束 done # 确定 yes
故障转移
- 首先是该实例与其他实例失去连接
- 然后是疑似宕机
- 最后是确定下线,自动提升一个slave为新的master
数据迁移
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移
cluster failover
5.RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集全的支持,而使用的步骤与哨兵模式基本一致:
- 引入redis的starter依赖
- 配置分片集群地址
- 配置读写分离
与哨兵模式相比,其中只有分片集群的配置方式略有差异:
spring: redis: cluster: nodes: # 指定redis-sentinel集群信息 - 192.168.88.101:7001 - 192.168.88.101:7002 - 192.168.88.101:7003 - 192.168.88.101:8001 - 192.168.88.101:8002 - 192.168.88.101:8003
四、多级缓存
1.多级缓存的意义及解决方案
- 传统缓存的问题
- 请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
- Redis缓存失效时,会对数据库产生冲击
- 多级缓存方案:多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能。
2.进程缓存-caffeine
缓存分类:缓存在日常开发中起到至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力
- 分布式缓存,例如Redis
- 优点:存储容量大、可靠性好、可以在集群间共享
- 缺点:访问缓存有网络开销
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 进程本地缓存,例如HashMap、GuavaCache
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
- 分布式缓存,例如Redis
Caffeine:Caffeine是一个基于java8开发的,提供了近乎最佳命中率的高性能本地缓存库。目前Spring内部的缓存使用的就是Caffeine
Caffeine示例
/* 基本用法测试 */ @Test void testBasicOps() { // 创建缓存对象 Cache<String, String> cache = Caffeine.newBuilder().build(); // 存数据 cache.put("name" , "小刚"); // 取数据 String name = cache.getIfPresent("name"); System.out.println("name = " + name); // 未命中的参数,则从数据库查 String age = cache.get("age", item -> { return "18"; // 此处模拟数据库查询 }); System.out.println("age = " + age); }Caffeine提供了三种缓存驱逐策略
基于容量:设置缓存的数量上限
/* 基于大小设置驱逐策略: */ @Test void testEvictByNum() throws InterruptedException { // 创建缓存对象 Cache<String, String> cache = Caffeine.newBuilder() // 设置缓存大小上限为 1 .maximumSize(1) .build(); // 存数据 cache.put("gf1", "柳岩"); cache.put("gf2", "范冰冰"); cache.put("gf3", "迪丽热巴"); // 延迟10ms,给清理线程一点时间 Thread.sleep(10L); // 获取数据 System.out.println("gf1: " + cache.getIfPresent("gf1")); System.out.println("gf2: " + cache.getIfPresent("gf2")); System.out.println("gf3: " + cache.getIfPresent("gf3")); }基于时间:设置缓存的有效时间
/* 基于时间设置驱逐策略: */ @Test void testEvictByTime() throws InterruptedException { // 创建缓存对象 Cache<String, String> cache = Caffeine.newBuilder() .expireAfterWrite(Duration.ofSeconds(1)) // 设置缓存有效期为 10 秒 .build(); // 存数据 cache.put("gf", "柳岩"); // 获取数据 System.out.println("gf: " + cache.getIfPresent("gf")); // 休眠一会儿 Thread.sleep(1200L); System.out.println("gf: " + cache.getIfPresent("gf")); }基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据量。性能差
在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理或驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
Caffeine实践
引入依赖
<dependency> <groupId>com.github.ben-manes.caffeine</groupId> <artifactId>caffeine</artifactId> </dependency>编写配置类,注入Bean
@Configuration public class CaffeineConfig { @Bean public Cache<Long , Item> itemCaffeine() { return Caffeine.newBuilder() .initialCapacity(100) .maximumSize(10000) .build(); } @Bean public Cache<Long , ItemStock> itemStockCaffeine() { return Caffeine.newBuilder() .initialCapacity(100) .maximumSize(10000) .build(); } }编写业务逻辑
@RestController @RequestMapping("item") public class ItemController { @Autowired private IItemService itemService; @Autowired private IItemStockService stockService; @Autowired private Cache<Long , Item> itemCache; @Autowired private Cache<Long , ItemStock> itemStockCache; @GetMapping("/{id}") public Item findById(@PathVariable("id") Long id){ return itemCache.get(id , item -> itemService.query() .ne("status", 3).eq("id", item) .one()); } @GetMapping("/stock/{id}") public ItemStock findStockById(@PathVariable("id") Long id){ return itemStockCache.get(id , item -> stockService.getById(item)); } }
3.lua语言
Lua是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放,其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
数据类型
数据类型 描述 nil 只有值nil属于该类,表示一个无效值(相当于false) boolean 包含两个值:false和true number 表示双精度类型的实浮点数 string 字符串由一对双引号或单引号来表示 function 由C或Lua编写的函数 table Lua中的表其实是一个关联数组,数组的索引可以是数字、字符串或表类型。在Lua里,table的创建是通过“构造表达式”来完成,最简单的表达式是{},用来创建一个空表 判断变量的值
print(type("你好"))
变量:lua声明变量的时候,并不需要指定数据类型
local str = 'hello' local num = 123 local flag = true local arr = {'1' , '2' , '3'} local map = {name = 'jack' , age = 21}访问table:
-- 访问数组,lua数组从角标1开始 print(arr[1]) -- 访问table print(map['name']) print(map.name)
循环
遍历数组
-- 声明数组 local arr = {'1' , '2' , '3'} -- 遍历数组 for index,value in ipairs(arr) do print(index , value) end遍历table
-- 声明map local map = {name='jack' , age=21} -- 遍历map for key,value in pairs(map) do print(key , value) end
函数
函数的定义
function 函数名(arg1 , arg2...) -- 函数体 return 返回值 end
条件控制
if(布尔表达式) then -- true时执行 else -- false时执行 end逻辑运算基于英文
操作符 描述 and 逻辑与 or 逻辑或 not 逻辑非
4.初识OpenResty
OpenResty是一个基于Nginx的高性能web平台,用于方便的搭建能够处理超高并发、扩展性极高的动态web应用、web服务和动态网关。具备下列特点
- 具备Nginx的完整功能
- 基于Lua语言进行扩展,集成了大量精良的Lua库、第三方模块
- 允许使用Lua自定义业务逻辑、自定义库
OpenResty快速使用
在nginx反向代理服务器上配置服务代理,将请求转发到OpenResty中
#user nobody; worker_processes 1; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; sendfile on; #tcp_nopush on; keepalive_timeout 65; # OPenResty地址 upstream nginx-cluster{ server 192.168.88.101:8081; } server { listen 80; server_name localhost; location /api { # 请求转发给OpenResty proxy_pass http://nginx-cluster; } location / { root html; index index.html index.htm; } error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } } }在OpenResty中的nginx的nginx.conf文件中写入处理配置
#user nobody; worker_processes 1; error_log logs/error.log; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; #lua 模块 lua_package_path "/usr/local/openresty/lualib/?.lua;;"; # c模块 lua_package_cpath "/usr/local/openresty/lualib/?.so;;"; server { listen 8081; server_name localhost; location /api/item { # 默认的响应类型 default_type application/json; # 响应结果由lua/item.lua来决定 content_by_lua_file lua/item.lua; } location / { root html; index index.html index.htm; } error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } } }编写lua/item.lua脚本,此处默认返回静态资源假数据
-- ngx.say() 函数相当于response,给客户端响应结果 ngx.say('{"id":10001,"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列屎黄色 820.70.36.4","price":199999999999,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp"}')重新加载nginx
ngnix -s reload
5.获取请求参数
[!tip]
OpenResty提供了各种ApI用来获取不同类型的请求参数:
| 参数格式 | 参数示例 | 参数解析代码示例 |
|---|---|---|
| 路径占位符 | /item/1001 | 1.正则表达式匹配:location ~ /item/(\d+){content_by_lua_file lua/item.lua;} 2.匹配到的参数会存入ngx.var数组中,可用角标获取:local id = ngx.var[1] |
| 请求头 | id:1001 | 返回值是table类型:local headers = ngx.req.get_headers() |
| Get请求参数 | ?id=1001 | 返回值是table类型:local getParams = ngx.req.get_uri_args() |
| Post表单参数 | id=1001 | 1.读取请求体:ngx.req.read_body() 2.返回值是table类型:local postParms = ngx.req.get_post_args() |
| JSON参数 | {“id”:1001} | 1.读取请求体:ngx.req.read_body() 2.返回值是string类型:local jsonBody = ngx.req.get_body_data() |
6.查询Tomcat
nginx提供了内部API用以发送http请求:
local resp = ngx.location.capture("/path" , { method = ngx.HTTP_GET, -- 请求方式 args = {a=1,b=2}, -- get方式传参数 body = "c=3&d=4" -- post方式传参数 })[!TIP]
返回的响应内容包括:
- resp.status:响应状态码
- resp.header:响应头,是一个table
- resp.body:响应体,就是一个响应数据
[!WARNING]
注意:此处的"/path"是路径,并不包含IP和端口。这个请求会被nginx内部的server监听并处理。
但是我们希望这个请求发送到Tomcat服务器,所以还需要编写一个server来对这个路径做反向代理
location /path { # 这里是windows电脑的ip和java服务端接口,需要确保windows的防火墙处于关闭状态 proxy_pass http://192.168.88.1:8081; }封装http查询的函数
[!TIP]
我们可以把http查询的请求 封装为一个函数,放到OpenResty函数库中,方便后期使用。
在/usr/local/openresty/lualib目录下创建common.lua文件:
vi /usr/local/openresty/lualib/common.lua在common.lua中封装http查询的函数
-- 封装函数,发送http请求,并解析响应 local function read_http(path, params) local resp = ngx.location.capture(path,{ method = ngx.HTTP_GET, args = params, }) if not resp then -- 记录错误信息,返回404 ngx.log(ngx.ERR, "http not found, path: ", path , ", args: ", args) ngx.exit(404) end return resp.body end -- 将方法导出 local _M = { read_http = read_http } return _M
实现
编写item.lua
-- 导入common函数库 local common = require('common') local read_http = common.read_http -- 导入cjson库,该库可以处理json数据 local cjson = require('cjson') -- 获取请求参数 local id = ngx.var[1] -- 查询商品信息 local itemJson = read_http("/item/" .. id , nil) -- 查询库存信息 local stockJson = read_http("/item/stock/" .. id , nil) -- 使用cjson转化为对象 local item = cjson.decode(itemJson) local stock = cjson.decode(stockJson) -- 组合数据 item.stock = stock.stock item.sold = stock.sold -- 返回结果 ngx.say(cjson.encode(item))在OpenResty内部的ngnix服务器编写接受请求的location
location /item { # 这里是windows电脑的ip和java服务端接口,需要确保windows的防火墙处于关闭状态 proxy_pass http://192.168.88.1:8081; }[!tip]
实际情况tomcat服务往往存在多个实例,本地缓存的数据只在实例中,不能共享,而nginx的负载均衡策略默认轮询,会轮流访问多个实例。因此为了提高本地缓存命中率我们可以对uri路径进行哈希操作,对于同一个uri访问相同的实例,此时本地缓存命中率大大提升。
7.冷启动与缓存预热
冷启动:服务刚刚启动时,redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力。
缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到redis中。
缓存预热实现
利用docker安装redis
docker run \ --name redis \ -p 6379:6379 \ -d redis redis-server \ --appendonly yesjava项目引入依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>配置redis地址
spring: redis: port: 6379 host: 192.168.88.101编写RedisHandler
@Component public class RedisHandler implements InitializingBean { @Autowired private RedisTemplate redisTemplate; @Autowired private IItemService itemService; @Autowired private IItemStockService iItemStockService; @Autowired private ObjectMapper objectMapper; @Override public void afterPropertiesSet() throws Exception { // 查询数据库数据 List<Item> itemList = itemService.list(); List<ItemStock> itemStockList = iItemStockService.list(); // 添加数据进redis缓存 itemList.stream().forEach(item -> { // 将item序列化为json try { String json = objectMapper.writeValueAsString(item); redisTemplate.opsForValue().set("item:id:" + item.getId() , json); } catch (JsonProcessingException e) { throw new RuntimeException(e); } }); itemStockList.stream().forEach(item -> { // 将item序列化为json try { String json = objectMapper.writeValueAsString(item); redisTemplate.opsForValue().set("stockItem:id:" + item.getId() , json); } catch (JsonProcessingException e) { throw new RuntimeException(e); } }); } }
7.查询Redis缓存
封装函数
[!Tip]
OpenResty提供了操作Redis的模块,我们只需要引入该模块就能直接使用
引入Redis模块,并初始化Redis对象
-- 引入该模块 local redis = require('resty.redis') -- 初始化Redis对象 local red = redis:new() -- 设置Redis超时时间 red:set_timeouts(1000 , 1000 , 1000)重新封装函数
-- 关闭redis连接的工具方法,其实是放入连接池 local function close_redis(red) local pool_max_idle_time = 1000 -- 连接的空闲时间,单位毫秒 local pool_size = 100 -- 连接池大小 local ok,err = red:set_Keepalive(pool_max_idle_time , pool_size) if not ok then ngx.log(ngx.ERR,"放入Redis连接池失败:",err) end endOpenResty提供了操作Redis模块,我们只要引入该模块就能直接使用
-- 查询redis的方法,ip和port是redis地址,key是查询的key local function read_redis(ip , port , key) -- 获取一个链接 local ok,err = red:connect(ip , port) if not ok then ngx.log(ngx.ERR , "连接Redis失败:" , err) return nil end -- 查询Redis local resp,err = red:get(key) -- 查询失败处理 if not resp then ngx.log(ngx.ERR , "查询Redis失败:" , err , ",key = " , key) end -- 得到的数据为空处理 if resp == ngx.null then resp = nil ngx.log(ngx.ERR , "查询到的Redis数据为空,key = " , key) end close_redis(red) return resp end
编写item.lua
-- 导入common函数库 local common = require('common') local read_redis = common.read_redis local read_http = common.read_http -- 导入cjson库,该库可以处理json数据 local cjson = require('cjson') -- 封装查询函数 function read_data(key , path , params) -- 查询redis local resp = read_redis("127.0.0.1" , 6379 , key) -- 判断查询结果 if not resp then ngx.log(ngx.ERR , "查询为空,key: " , key) -- redis查询失败,去查询http resp = read_http(path , params) end return resp end -- 获取请求参数 local id = ngx.var[1] -- 查询商品信息 local itemJson = read_data("item:id:" .. id , "/item/"..id , nil) ngx.log(ngx.ERR , "itemJson------>: " , itemJson) -- 查询库存信息 local stockJson = read_data("stockItem:id:" .. id , "/item/stock/"..id , nil) ngx.log(ngx.ERR , "stockJson---->: " , stockJson) -- 使用cjson转化为对象 local item = cjson.decode(itemJson) local stock = cjson.decode(stockJson) -- 组合数据 item.stock = stock.stock item.sold = stock.sold -- 返回结果 ngx.say(cjson.encode(item))
8.添加nginx本地缓存
OpenResty为Nginx提供了shard dict的功能,可以在nginx的多个worker之间共享数据,实现缓存功能。
开启共享字典,在ngnix.conf的http下添加配置:
# 共享字典,也就是本地缓存,名称叫做:item_cache,大小150m lua_shared_dict item_cache 150m;操作共享词典
-- 获取本地缓存对象 local item_cache = ngx.shared.item_cache -- 存储,指定key、value、、过期时间,单位s,默认为0代表永不过期 item_cache:set('key' , 'value' , 1000) -- 读取 local val = item_cache:get('key')修改查询代码
-- 导入common函数库 local common = require('common') local read_redis = common.read_redis local read_http = common.read_http -- 导入cjson库,该库可以处理json数据 local cjson = require('cjson') -- 导入共享词典,本地缓存 local item_cache = ngx.shared.item_cache -- 封装查询函数 function read_data(key , path , params) -- 首先查询本地缓存 local val = item_cache:get(key) if not val then -- 如果查询不到再查询Redis或http ngx.log(ngx.ERR, "查询本地缓存失败,查询Redis Key:" , key ) -- 查询redis local resp = read_redis("127.0.0.1" , 6379 , key) val = resp -- 判断查询结果 if not resp then ngx.log(ngx.ERR , "redis查询为空,key: " , key , "尝试查询HTTP") -- redis查询失败,去查询http val = read_http(path , params) end end -- 查询成功,写入内存 item_cache:set(key , val , 60) return val end -- 获取请求参数 local id = ngx.var[1] -- 查询商品信息 local itemJson = read_data("item:id:" .. id , "/item/"..id , nil) ngx.log(ngx.ERR , "itemJson------>: " , itemJson) -- 查询库存信息 local stockJson = read_data("stockItem:id:" .. id , "/item/stock/"..id , nil) ngx.log(ngx.ERR , "stockJson---->: " , stockJson) -- 使用cjson转化为对象 local item = cjson.decode(itemJson) local stock = cjson.decode(stockJson) -- 组合数据 item.stock = stock.stock item.sold = stock.sold -- 返回结果 ngx.say(cjson.encode(item))
9.缓存同步
数据同步策略
- 设置有效期
- 同步双写
- 异步通知
Canal:译为水道、管道,canal是阿里巴巴旗下的一款开源项目,基于java开发。基于数据库增量日志解析,提供增量数据订阅&消费。canal基于mysql主从同步实现
业务实现:
引入Canal依赖
<dependency> <groupId>top.javatool</groupId> <artifactId>canal-spring-boot-starter</artifactId> <version>1.2.1-RELEASE</version> </dependency>编写配置
canal: destination: heima # canal实例名,要跟canal-server运行时的destination一致 server: 192.168.150.101:11111 # canal地址Canal推送给Canal-client的是被修改的这一行数据(row),而我们引入的canal-client则会帮我们把行数据封装到Item实体类中。这个过程中需要数据库与实体类的映射关系,需要用到JPA的几个注解
@Data @TableName("tb_item") public class Item { @TableId(type = IdType.AUTO) @Id // 标记表中的Id字段 private Long id;//商品id @Column(name = "name") // 字段名不一致可以指定 private String name;//商品名称 private String title;//商品标题 private Long price;//价格(分) private String image;//商品图片 private String category;//分类名称 private String brand;//品牌名称 private String spec;//规格 private Integer status;//商品状态 1-正常,2-下架 private Date createTime;//创建时间 private Date updateTime;//更新时间 @TableField(exist = false) @Transient // 表中没有的字段 private Integer stock; @TableField(exist = false) @Transient // 表中没有的字段 private Integer sold; }编写监听器,监听Canal消息:
@CanalTable("tb_item") // 指定要监听的表 @Component public class ItemHandler implements EntryHandler<Item> { @Autowired private RedisHandler redisHandler; @Autowired private Cache<Long , Item> itemcache; @Override public void insert(Item item) { // 写数据到Redis redisHandler.insertOrUpdateItem(item); // 写数据到jvm缓存 itemcache.put(item.getId() , item); } @Override public void update(Item before, Item after) { // 更新数据到redis redisHandler.insertOrUpdateItem(after); // 写数据到jvm缓存 itemcache.put(after.getId() , after); } @Override public void delete(Item item) { // 删除数据到Redis redisHandler.deleteItem(item); // 删除数据到jvm缓存 itemcache.invalidate(item.getId()); } }
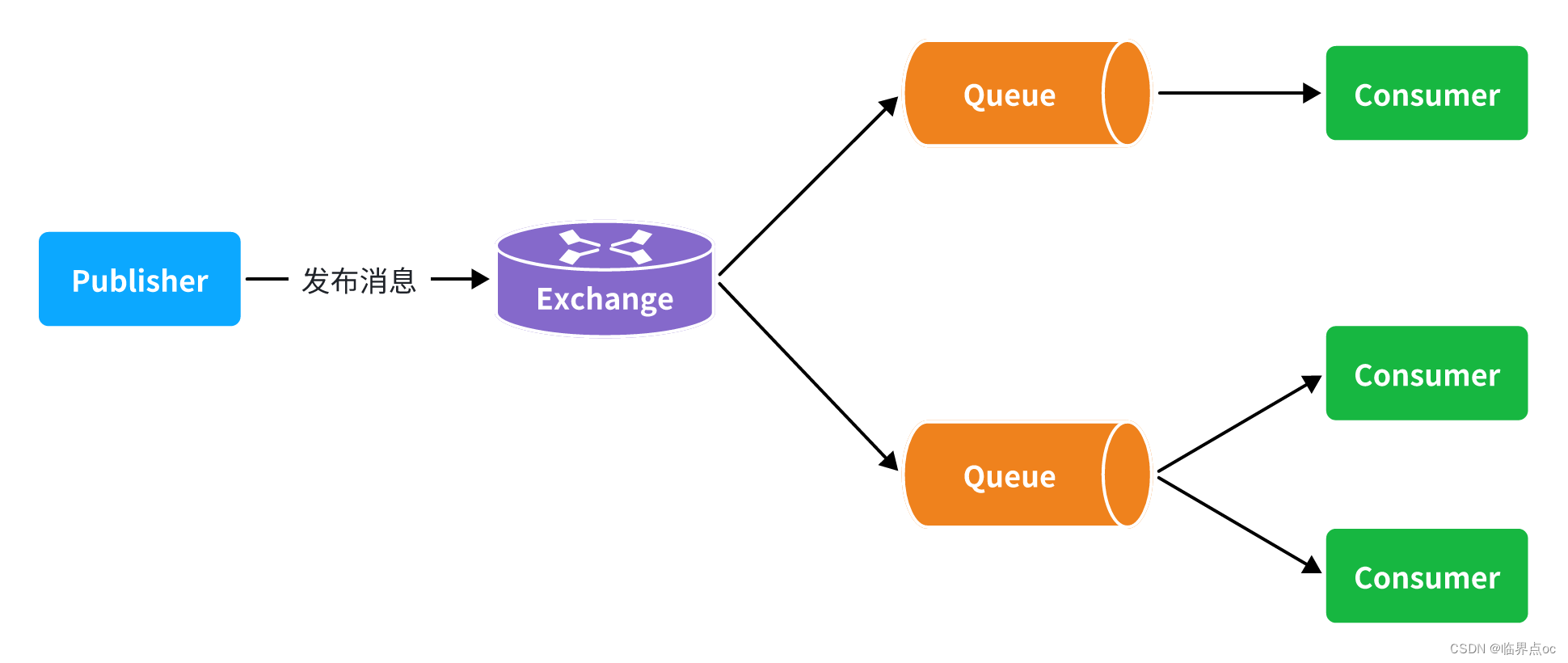
五、服务异步通讯-rabbitMQ的高级特性
1.消息可靠性
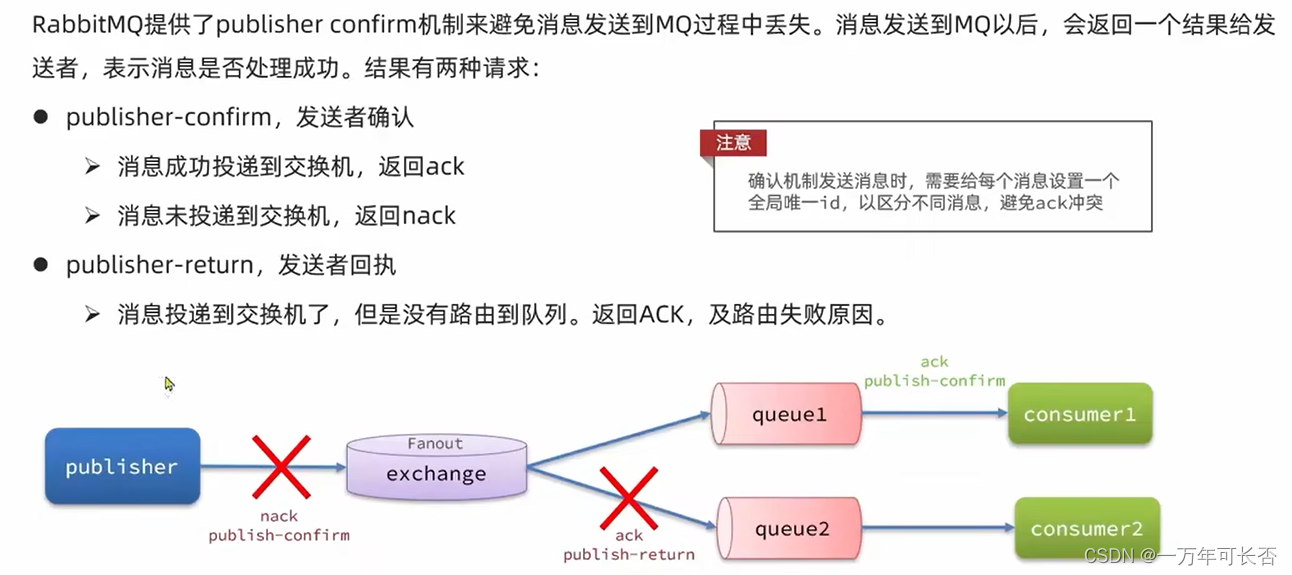
消息确认机制:RabbitMQ提供了publisher confirm机制来避免消息发送到MQ中丢失。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功。结果有两种请求:
- publisher-confirm,发送者确认
- 消息成功投递到交换机,返回ack
- 消息未投递到交换机,返回nack
- publisher-return,发送者回执
- 消息投递到交换机了,但是没有路由到队列,返回ACK,及路由失败原因
- publisher-confirm,发送者确认
SpringAMQP实现生产者消息确认
在publisher这个微服务的application.yaml中添加配置
spring: rabbitmq: addresses: 192.168.88.101 # 地址名 port: 5672 # 端口 virtual-host: / # 虚拟主机 username: itcast password: 123321 publisher-confirm-type: correlated # 消息确认为异步回调 simple为同步回调 template: mandatory: true # 定义消息路由失败策略。true则调用ReturnCallback;false则直接丢弃消息每一个RabbitTemplate只能配置一个ReturnCallback,因此需要在项目启动过程中配置:
@Slf4j @Component public class CommonConfig implements ApplicationContextAware { @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { // 获取rabbitTemplate实例 RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class); // 设置ReturnCallback rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() { @Override public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) { log.info("消息发送失败,应答码:{},原因:{},交换机:{},路由键:{},消息:{}", replyCode , replyText , exchange , routingKey , message.toString()); // 如需需要可以设置重发... } }); } }发送消息,指定消息ID、消息ConfirmCallback
@Test public void testSendMessage2SimpleQueue(){ // 1.准备消息 String message = "hello , Spring amqp!"; // 2.指定交换机 String exchange = "amq.topic"; // 4.准备routing key String routingkey = "simple.test"; // 5.准备CorrelationData CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString()); correlationData.getFuture().addCallback(result -> { // 判断是否发送成功! if (result.isAck()) { log.info("消息投递成功!消息ID:" + correlationData.getId()); } else { log.error("消息投递到交换机失败! 消息ID" + correlationData.getId()); } }, ex -> { log.error("消息发送失败!error:" + ex + " 消息ID" + correlationData.getId()); // 如需需要可以设置重发... }); rabbitTemplate.convertAndSend(exchange , routingkey , message , correlationData); }
2.消息持久化
交换机持久化:
@Bean public DirectExchange simpleExchange() { // 三个参数:交换机名称、是否持久化、当没有queue与其绑定时是否自动删除 return new DirectExchange("simple.direct" , true , false); }队列持久化
@Bean public Queue simpleQueue() { // 使用QueueBuilder构造队列,durable就是持久的 return QueueBuilder.durable("simple,queue").build(); }消息持久化,springAMQP中的消息默认是持久的,可以通过属性指定
Message msg = MessageBuilder .withBody(message.getBytes(StandarCharsets.UTF_8)) // 消息体 .setDeliverMode(MessageDeliveryMode.PERSISTENT) // 持久化 .build();
3.消费者消息确认
RabbitMQ支持消费者确认机制,即:消费者处理消息后可以向MQ发送ack回执,MQ收到ack回执后才会删除消息。
SpringMVC的三种确认模式
- manual:手动ack,需要在业务代码结束后,调用api发送ack
- auto:自动ack,由spring监测llistener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
- none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
AMQP开启消息确认:
spring: rabbitmq: addresses: 192.168.88.101 # 地址名 port: 5672 # 端口 virtual-host: / # 虚拟主机 username: itcast password: 123321 publisher-confirm-type: correlated # 消息确认为异步回调 simple为同步回调 template: mandatory: true # 定义消息路由失败策略。true则调用ReturnCallback;false则直接丢弃消息 listener: simple: prefetch: 1 acknowledge-mode: auto # 消息确认机制: none 关闭 , manual:手动 , auto自动
4.失败重试机制
当消费者出现异常之后,消息会不断requeue(重新入队)到队列,再重新发送给消费者,然后再次异常,再次requeue,无限循环,导致mq的消息处理飙升,带来不必要的处理压力,我们可以利用Spring的retry机制,在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。
AMQP开启消息失败重试
spring: rabbitmq: addresses: 192.168.88.101 # 地址名 port: 5672 # 端口 virtual-host: / # 虚拟主机 username: itcast password: 123321 listener: simple: prefetch: 1 # 修改消费者提前把握的最大数量 retry: enabled: true # 开启消费者失败重试 initial-interval: 1000 # 初始的失败等待市场为1秒 multiplier: 2 # 下次失败的等待时长倍数,下次等待时长 = multiplier * last-interval max-attempts: 4 # 最大重试次数 stateless: true # true无状态,false为有状态,如果业务中包含事务,这里改为false消费者失败消息处理策略:在开启重试模式后,重试次数用尽,如果消息依然失败,则需要有MessageRecoverer接口来处理,它包含三种不同的实现:
- RejectAndDontRequestRecoverer:重试耗尽后,直接reject,丢失消息。默认就是这种方式
- ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
- RepublishMessageRecoverer:重新耗尽后,将失败消息投递到指定的交换机
AMQP实现失败消息处理:
@Configuration public class ErrorMessageConfig { @Bean public Queue errorQueue() { return new Queue("error.queue" , true , true, false); } @Bean public DirectExchange errorDirectChange() { return new DirectExchange("error.direct" , true , false); } @Bean public Binding errorDirectAndErrorQueueBinding() { return BindingBuilder.bind(errorQueue()).to(errorDirectChange()).with("error"); } @Bean public MessageRecoverer errorMessageRecoverer(RabbitTemplate rabbitTemplate ) { return new RepublishMessageRecoverer(rabbitTemplate , "error.direct" , "error"); } }
5.如何确保RabbitMQ消息的可靠性?
- 开启生产者确认模式,确保生产者的消息能够到达队列
- 开启持久化功能,确保消息未消费前在队列中不会丢失
- 开始消费者确认机制为auto,由spring确认消息处理成功后完成ack
- 开启消费者失败重试机制,并设置MessageRecoverer,多次重试失败后将消息投递到异常交换机,交由人工处理
6.死信交换机
初识死信交换机
- 死信:当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
- 消费这使用basic.reject或basic.nack声明消费失败,并且消息的requeue参数设置为false
- 消息是一个过期消息,超时无人消费
- 要投递的队列消息堆积满了,最早的消息可能成为死信
- 如果该队列配置了dead-letter-exchange属性,指定了一个交换机。那么队列中的死信就会投递到这个交换机中,而这个交换机称为死信交换机
- 如何给队列绑定死信交换机?
- 给队列设置dead-letter-exchange属性,指定一个交换机
- 给队列设置dead-letter-routing-key属性,设置死信交换机与死信队列的RoutingKey
- 死信:当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
TTL:也就是Time-To-Live。如果一个队列中的消息TTL结束仍未消费,则会变为死信,ttl超时分为两种情况:
- 消息所在的队列设置了存活时间
- 消息本身设置了存活时间
AMQP实现死信交换机
绑定死信交换机与死信队列
@RabbitListener(bindings = @QueueBinding( value = @Queue(name = "dl.queue" , durable = "true"), exchange = @Exchange(name = "dl.direct" , type = "direct"), key = "dl" )) public void listenDlQueue(String msg) { log.info("死信队列消息者收到消息:{}" , msg); }绑定ttl交换机和ttl队列
@Configuration public class TTLMessageConfig { @Bean public DirectExchange ttlDirectExchange() { return new DirectExchange("ttl.direct" , true , false); } @Bean public Queue ttlQueue() { return QueueBuilder.durable("ttl.queue") .ttl(10000) .deadLetterExchange("dl.direct") .deadLetterRoutingKey("dl") .build(); } @Bean public Binding ttlDirectAndTtlQueueBinding() { return BindingBuilder.bind(ttlQueue()).to(ttlDirectExchange()).with("ttl"); } }发送消息
@Test public void testTTl(){ String msg = "java是世界上最好的语言!"; Message message = MessageBuilder .withBody(msg.getBytes(StandardCharsets.UTF_8)) // .setExpiration("5000") // 此处可以设置消息本身的超时时间 .build(); CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString()); correlationData.getFuture().addCallback( result -> { if (result.isAck()) { log.info("消息投递成功!消息ID为:" + correlationData.getId()); } }, ex -> { log.error("消息投递失败:" + ex); } ); rabbitTemplate.convertAndSend("ttl.direct" , "ttl" , message , correlationData); }
消息超时的两种方式是?
- 给队列设置ttl属性,进入队列后超过ttl时间的消息变为死信
- 给消息设置ttl属性,队列接收到消息超过ttl时间后变为死信
- 两者共存,以时间短的ttl为准
7.延迟队列
介绍:利用TTL结合死信交换机,我们实现了消息发出后,消费者延迟收到消息的效果。这种消息模式就称为延迟队列模式
- 延迟发送短信
- 用户下单,如果用户在15分钟内未支付,则自动取消
- 预约工作会议,20分钟后自动停止所有参会人员
安装延迟队列插件
见RabbitMQ安装文档
8.惰性队列
消息堆积问题:当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。最早接收到的消息,可能就会成为死信,会被丢弃,这就是消息堆积问题。
- 解决消息堆积的三种思路:
- 增加更多的消费者
- 在消费者内开启线程池加快消息处理速度
- 扩大队列容积,提高堆积上限
惰性队列:从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的概念,也就是惰性队列
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存
- 支持数百万条的消息存储
AMQP中声明惰性队列的两种方式:
@Bean方式
@Bean public Queue lazyQueue() { return QueueBuild .durable("lazy.queue") .lazy() // 开启惰性队列 .build(); }注解方式
@RabbitListener(queuesToDeclare = @Queue( name = "lazy.queue" , durable = "true", arguments = @Argument(name = "x-queue-mode" , value = "lazy") )) public void listenQueue(String msg) { log.info("收到消息:{}" , msg); }
getBytes(StandardCharsets.UTF_8))
// .setExpiration(“5000”) // 此处可以设置消息本身的超时时间
.build();
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
correlationData.getFuture().addCallback(
result -> {
if (result.isAck()) {
log.info(“消息投递成功!消息ID为:” + correlationData.getId());
}
},
ex -> {
log.error("消息投递失败:" + ex);
}
);
rabbitTemplate.convertAndSend("ttl.direct" , "ttl" , message , correlationData);
}
```
消息超时的两种方式是?
- 给队列设置ttl属性,进入队列后超过ttl时间的消息变为死信
- 给消息设置ttl属性,队列接收到消息超过ttl时间后变为死信
- 两者共存,以时间短的ttl为准
7.延迟队列
介绍:利用TTL结合死信交换机,我们实现了消息发出后,消费者延迟收到消息的效果。这种消息模式就称为延迟队列模式
- 延迟发送短信
- 用户下单,如果用户在15分钟内未支付,则自动取消
- 预约工作会议,20分钟后自动停止所有参会人员
安装延迟队列插件
见RabbitMQ安装文档
8.惰性队列
消息堆积问题:当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。最早接收到的消息,可能就会成为死信,会被丢弃,这就是消息堆积问题。
- 解决消息堆积的三种思路:
- 增加更多的消费者
- 在消费者内开启线程池加快消息处理速度
- 扩大队列容积,提高堆积上限
惰性队列:从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的概念,也就是惰性队列
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存
- 支持数百万条的消息存储
AMQP中声明惰性队列的两种方式:
@Bean方式
@Bean public Queue lazyQueue() { return QueueBuild .durable("lazy.queue") .lazy() // 开启惰性队列 .build(); }注解方式
@RabbitListener(queuesToDeclare = @Queue( name = "lazy.queue" , durable = "true", arguments = @Argument(name = "x-queue-mode" , value = "lazy") )) public void listenQueue(String msg) { log.info("收到消息:{}" , msg); }