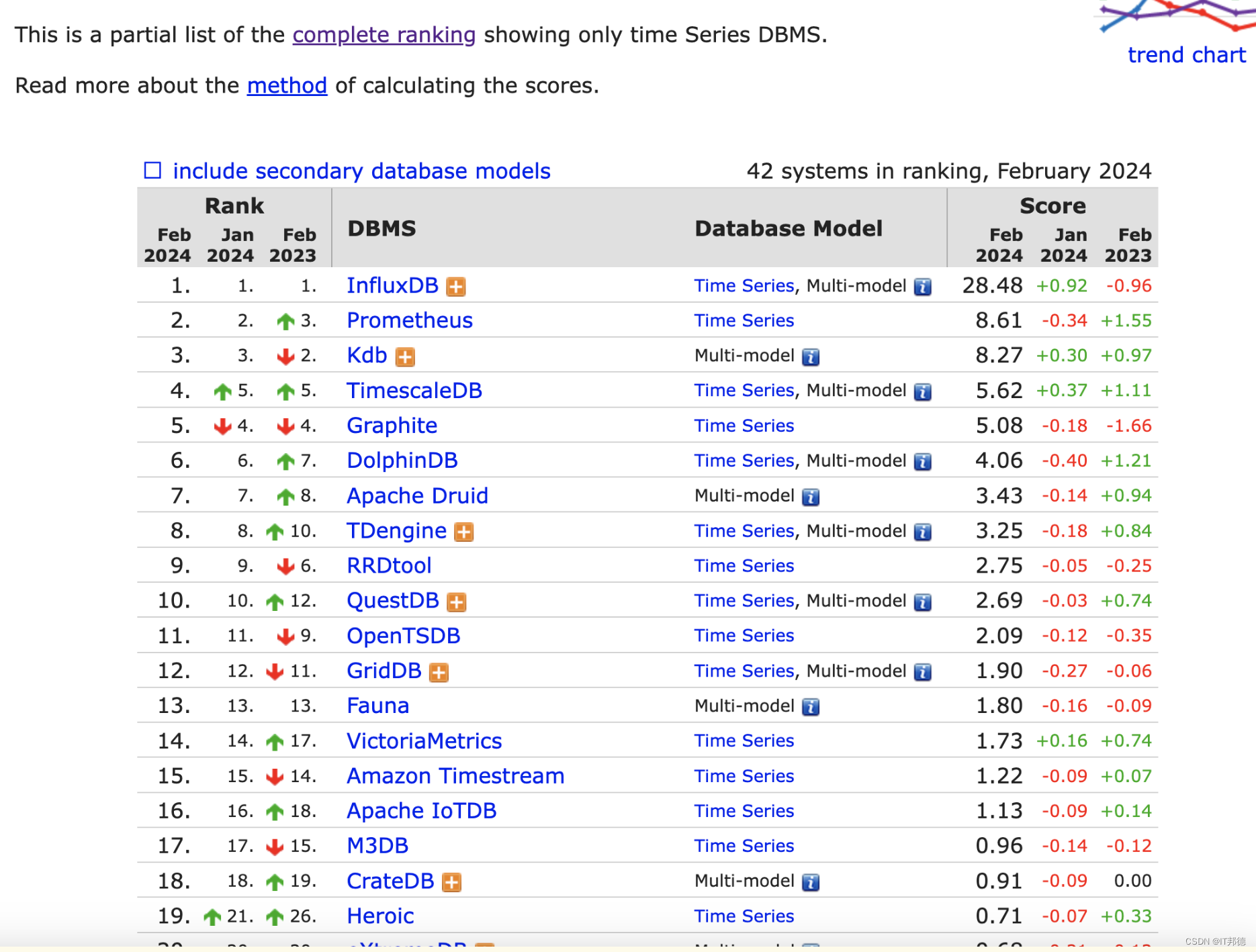
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库。OpenCV最初由Intel开发,目的是为了提供一个通用的基础设施,让计算机视觉应用更加容易地被开发出来。它现在拥有一个庞大的用户社区,并且被广泛用于学术和商业领域。OpenCV支持多种编程语言,包括C++、Python、Java等,并且可以在不同的平台上运行,如Windows、Linux、Mac OS等。OpenCV的主要功能包括但不限于以下几个方面:
一、图像处理
包括图像的基本操作(如读取、显示、保存)、图像变换(如缩放、旋转、仿射变换)、颜色空间转换、滤波、边缘检测、图像增强等。
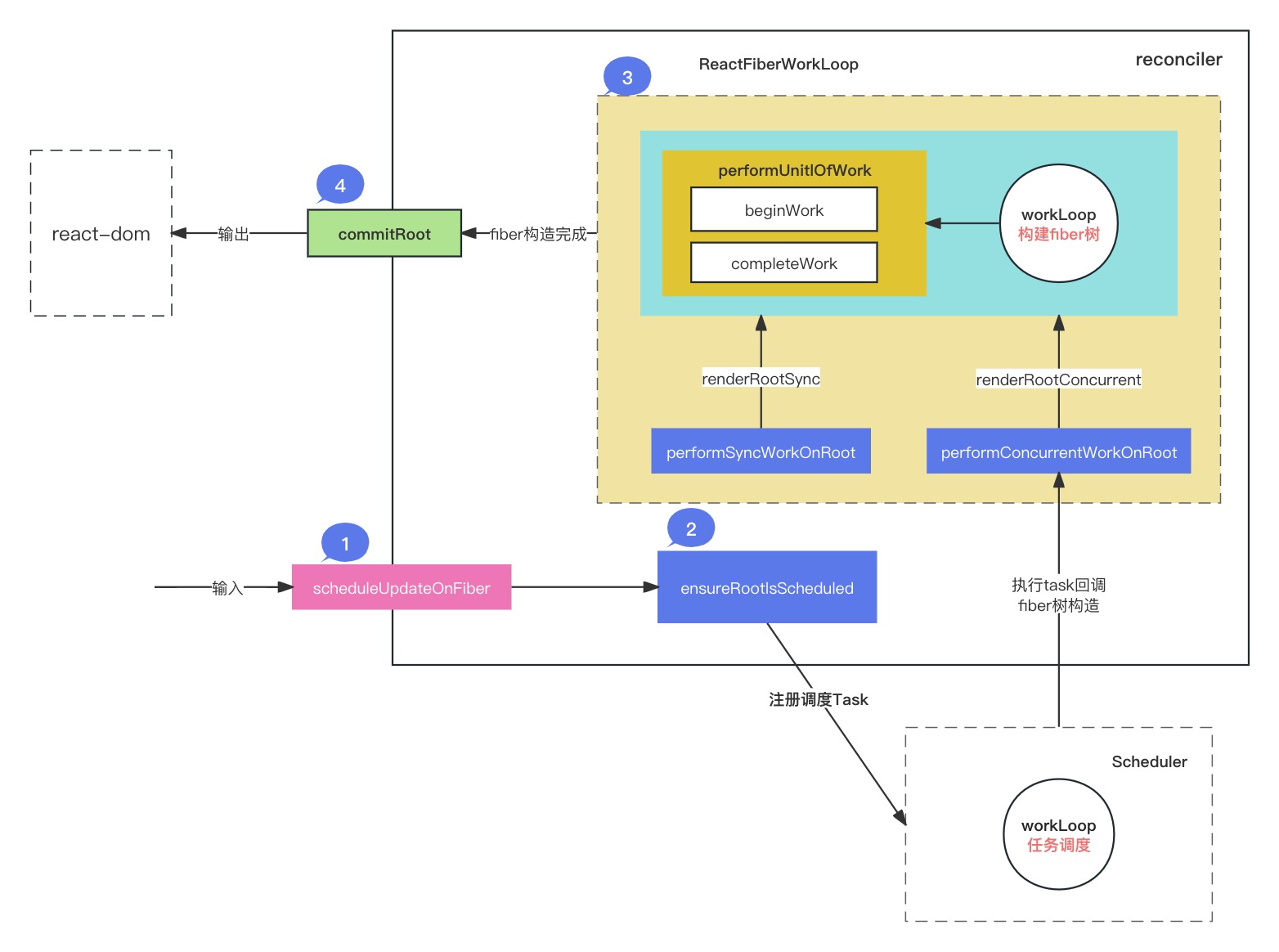
这里有一个使用Python和OpenCV进行基本图像处理的例子,我们将演示如何读取一张图片,对其进行灰度转换,然后应用高斯模糊,最后显示原图和处理后的图像:
import cv2
import matplotlib.pyplot as plt
# 读取图片
image = cv2.imread('your_image_path.jpg') # 请替换 'your_image_path.jpg' 为你的图片路径
# 将图片转换为灰度图
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 应用高斯模糊,核大小为 (5, 5)
blurred_image = cv2.GaussianBlur(gray_image, (5, 5), 0)
# 使用matplotlib显示原图和处理后的图像
plt.figure(figsize=(10, 10))
# 显示原图
plt.subplot(1, 3, 1)
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)) # 将BGR图像转换为RGB
plt.title('Original Image')
# 显示灰度图
plt.subplot(1, 3, 2)
plt.imshow(gray_image, cmap='gray')
plt.title('Grayscale Image')
# 显示经过高斯模糊处理的图像
plt.subplot(1, 3, 3)
plt.imshow(blurred_image, cmap='gray')
plt.title('Blurred Image')
plt.show()
这段代码首先使用cv2.imread()函数读取一张图片。接着,使用cv2.cvtColor()函数将图片从BGR颜色空间转换为灰度图。然后,我们使用cv2.GaussianBlur()对灰度图像应用高斯模糊,这里选择了5x5的核大小,并将标准差设置为0,这意味着它将从核大小中计算得出。
最后,我们使用matplotlib的plt.imshow()函数来显示原始图片、灰度图片和模糊处理后的图片。注意,由于OpenCV默认使用BGR颜色空间,而matplotlib则是使用RGB,因此我们在显示原始图像之前将其从BGR转换为RGB。
这个例子展示了如何使用OpenCV进行一些基本的图像处理操作,包括读取图片、颜色空间转换和模糊处理。你可以通过改变参数或应用不同的函数来尝试更多的图像处理技术
二、特征检测
诸如SIFT、SURF、ORB等特征检测算法,可以用来检测图像中的关键点,并通过计算描述子来描述这些关键点的周围区域,从而用于图像匹配和识别等应用。
在这个例子中,我们将使用Python和OpenCV库来展示如何进行特征检测和描述。具体来说,我们将使用ORB(Oriented FAST and Rotated BRIEF)算法来检测关键点并提取它们的描述符。ORB是一种快速的特征点检测和描述子提取算法,非常适合于实时应用。
步骤概述:
- 导入必要的库。
- 读取图像。
- 初始化ORB检测器。
- 使用ORB检测关键点。
- 使用ORB计算描述符。
- 在图像上绘制关键点。
- 显示结果。
import cv2
import matplotlib.pyplot as plt
# 读取图像
image = cv2.imread('your_image_path.jpg') # 替换 'your_image_path.jpg' 为你的图片路径
# 初始化ORB检测器
orb = cv2.ORB_create()
# 检测ORB关键点和计算描述符
keypoints, descriptors = orb.detectAndCompute(image, None)
# 将关键点绘制到图像上。参数color为关键点的颜色,flags为绘制选项
image_keypoints = cv2.drawKeypoints(image, keypoints, None, color=(0, 255, 0), flags=0)
# 使用matplotlib显示结果
plt.figure(figsize=(8, 8))
plt.imshow(cv2.cvtColor(image_keypoints, cv2.COLOR_BGR2RGB)) # 将BGR图像转换为RGB
plt.title('ORB KeyPoints')
plt.show()
在这段代码中,我们首先读取一张图片,然后创建一个ORB对象。使用detectAndCompute方法检测关键点并计算它们的描述符。最后,我们使用drawKeypoints方法在图像上绘制检测到的关键点,并使用matplotlib显示结果图像。
需要注意的是,你需要确保你的环境中已经安装了opencv-python库,并且你需要替换代码中的'image_path.jpg'为你自己的图像文件路径。这个例子展示了如何在图像中检测和描述特征点,这对于很多计算机视觉任务来说是非常重要的一步,比如图像匹配和对象识别。
三、立体视觉
包括立体图像对的校正、深度图的生成、3D重建等,用于从多个角度拍摄的图像中恢复出三维场景的信息。在立体视觉(Stereo Vision)方面,OpenCV提供了一些关键的功能,可以用于从两个或多个视角获取的图像中重建3D场景。这里我将通过一个简单的例子来说明如何使用OpenCV实现立体视觉的基本步骤,包括摄像机标定、图像校正、立体匹配和深度图计算。
环境设置
首先,确保你的环境中已安装OpenCV。可以使用如下命令安装(如果还未安装的话):
!pip install opencv-python opencv-python-headless
立体视觉的基本步骤
- 摄像机标定(Camera Calibration):获取摄像机的内部参数和畸变系数。
- 图像校正(Image Rectification):根据摄像机参数调整图像,使成对图像的对应点在同一水平线上。
- 立体匹配(Stereo Matching):计算左右图像间的对应点,生成视差图(Disparity Map)。
- 深度图计算(Depth Map Calculation):根据视差图和摄像机参数计算深度图。
下面是一个简化的代码示例,展示如何使用OpenCV进行立体匹配和深度图计算:
import cv2
import numpy as np
# 加载左右视图图像
left_img = cv2.imread('left_image_path.jpg', 0) # 以灰度模式读取
right_img = cv2.imread('right_image_path.jpg', 0)
# 创建立体匹配对象
stereo = cv2.StereoBM_create(numDisparities=16, blockSize=15)
# 计算视差图
disparity = stereo.compute(left_img, right_img)
# 显示视差图
cv2.imshow('Disparity', disparity / 16.)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个例子中,我们使用StereoBM算法来计算视差图。numDisparities和blockSize是立体匹配过程中的两个重要参数,分别代表视差搜索的范围和匹配块的大小。这个简单的例子没有包含摄像机标定和图像校正的步骤,因为这通常需要一个更复杂的设置和多张用于标定的图像。
请注意,立体视觉和3D重建是一个复杂的领域,涉及到许多高级概念和技术。这个例子仅旨在提供一个基本的介绍。在实际应用中,你可能需要进行更复杂的操作,比如使用更高级的立体匹配算法(如StereoSGBM),以及进行精确的摄像机标定和图像校正。
四、物体检测
可以识别图像中的各种对象,如人脸、行人、车辆等。OpenCV提供了多种预训练的分类器,也支持使用深度学习模型进行更复杂的物体识别。
OpenCV 提供了多种物体检测方法,包括但不限于 Haar 级联检测、基于深度学习的检测(如使用 SSD、YOLO)等。下面,我将通过一个简单的 Haar 级联检测的例子来说明如何使用 OpenCV 进行物体检测。
Haar 级联分类器是一种有效的物体检测方法,尤其是用于面部和眼睛检测。它基于“Haar 特征”和“级联分类器”,OpenCV 已经提供了一些训练好的 Haar 级联文件,可以直接用来检测面部、眼睛等。
环境设置
确保你的环境中已安装 OpenCV。可以使用以下命令安装(如果还未安装的话):
pip install opencv-python
示例代码
以下是一个使用 Haar 级联检测人脸和眼睛的例子:
import cv2
# 加载 Haar 级联分类器
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')
# 读取图像
img = cv2.imread('your_image.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测面部
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
# 在检测到的面部周围画矩形框
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
# 在每个面部区域检测眼睛
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
# 显示结果图像
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个例子中,首先加载了人脸和眼睛的 Haar 级联文件。然后读取图像,并将其转换为灰度图,因为 Haar 级联检测在灰度图上工作效果更好。detectMultiScale 函数用于检测图像中的面部,其参数包括图像、缩放因子和最小邻居数。检测到的面部用矩形框标出,并在每个面部区域内部进一步检测眼睛。
请注意,这个示例假设你已经有了用于检测的图像文件,并且将 'your_image.jpg' 替换为你的图像文件路径。此外,Haar 级联检测对于图像中物体的位置、大小和方向比较敏感,可能需要调整参数以获得最佳效果。
五、运动分析与物体跟踪
通过分析连续帧之间的变化来估计物体的运动,或者对视频中的特定物体进行跟踪。
OpenCV 提供了多种运动分析和物体跟踪的方法。这里,我将通过一个简单的示例来说明如何使用 OpenCV 进行物体跟踪,特别是使用背景减除和光流法。
示例 1: 背景减除法
背景减除是一种常用于检测视频中移动物体的方法。OpenCV 提供了几种背景减除算法,其中 createBackgroundSubtractorMOG2 是一种广泛使用的方法。
import cv2
# 创建背景减除器
backSub = cv2.createBackgroundSubtractorMOG2()
# 捕获视频
cap = cv2.VideoCapture('your_video.mp4')
while True:
ret, frame = cap.read()
if not ret:
break
# 应用背景减除
fgMask = backSub.apply(frame)
# 显示原始视频和前景掩码
cv2.imshow('Frame', frame)
cv2.imshow('FG Mask', fgMask)
keyboard = cv2.waitKey(30)
if keyboard == 'q' or keyboard == 27:
break
cap.release()
cv2.destroyAllWindows()
在这个例子中,我们首先创建了一个背景减除器对象,然后逐帧读取视频,将每一帧传递给背景减除器以获取前景掩码。这个掩码显示了移动物体的位置。
示例 2: 光流法
光流是图像中物体或表面的可视运动模式,它可以用于跟踪视频中的物体。下面是使用 OpenCV 的密集光流法(Farneback 方法)的示例:
import cv2
import numpy as np
cap = cv2.VideoCapture('your_video.mp4')
# 读取第一帧
ret, frame1 = cap.read()
prvs = cv2.cvtColor(frame1, cv2.COLOR_BGR2GRAY)
# 为光流图像创建一个随机颜色的图
hsv = np.zeros_like(frame1)
hsv[..., 1] = 255
while True:
ret, frame2 = cap.read()
if not ret:
break
next = cv2.cvtColor(frame2, cv2.COLOR_BGR2GRAY)
# 计算光流
flow = cv2.calcOpticalFlowFarneback(prvs, next, None, 0.5, 3, 15, 3, 5, 1.2, 0)
# 极坐标转换
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
hsv[..., 0] = ang*180/np.pi/2
hsv[..., 2] = cv2.normalize(mag, None, 0, 255, cv2.NORM_MINMAX)
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
# 显示结果
cv2.imshow('frame2', bgr)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
prvs = next
cap.release()
cv2.destroyAllWindows()
这个示例首先读取视频的第一帧,并计算后续每一帧与前一帧之间的光流。然后,将光流的矢量方向转换为颜色,使其可以可视化。这种方法可以用来观察视频中的整体运动趋势。
请确保替换 'your_video.mp4' 为你的视频文件路径。这些示例展示了如何使用 OpenCV 进行简单的运动分析和物体跟踪,但是这些方法在复杂的场景中可能需要进一步的调整和优化。
六、机器学习
OpenCV 提供了一些基础的机器学习功能,包括 k-最近邻(k-NN)、支持向量机(SVM)、决策树等。在这里,我将通过一个简单的示例来说明如何使用 OpenCV 的 k-最近邻(k-NN)算法来进行数据分类。
示例:使用 k-最近邻进行数据分类
首先,我们需要创建一些数据点作为训练集,并为这些数据点指定标签。然后,我们将使用 k-NN 算法来对一个新的数据点进行分类。
import numpy as np
import cv2
# 创建数据点和标签
# 这里我们创建了两类数据点:一类位于图像的上半部分,另一类位于下半部分
trainData = np.random.randint(0, 100, (25, 2)).astype(np.float32)
responses = np.random.randint(0, 2, (25, 1)).astype(np.float32)
# 将数据点按照标签分成两组
red = trainData[responses.ravel() == 0]
blue = trainData[responses.ravel() == 1]
# 新的数据点
newcomer = np.random.randint(0, 100, (1, 2)).astype(np.float32)
# 使用 k-NN 算法进行分类
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, responses)
ret, results, neighbours, dist = knn.findNearest(newcomer, 3)
# 打印结果
print("Result: {}\n".format(results))
print("Neighbours: {}\n".format(neighbours))
print("Distance: {}\n".format(dist))
# 可视化
import matplotlib.pyplot as plt
plt.scatter(red[:,0], red[:,1], 80, 'r', '^')
plt.scatter(blue[:,0], blue[:,1], 80, 'b', 's')
plt.scatter(newcomer[:,0], newcomer[:,1], 80, 'g', 'o')
plt.show()
在这个示例中,我们首先生成了一组随机的训练数据,然后使用 k-NN 算法来对一个新的数据点进行分类。我们将结果、新数据点的最近邻和这些邻居的距离打印出来。最后,我们使用 matplotlib 将结果可视化,以便更直观地理解分类过程。
这个简单的示例展示了如何使用 OpenCV 的 k-NN 实现进行基本的机器学习任务。请注意,对于复杂的机器学习和深度学习任务,你可能需要使用更专门的库,如 scikit-learn、TensorFlow 或 PyTorch。
以上只是简单的介绍opencv常见的功能,大家可以通过探索 OpenCV 的文档和社区资源,你可以学习到如何利用这个强大的库来实现复杂的计算机视觉项目。