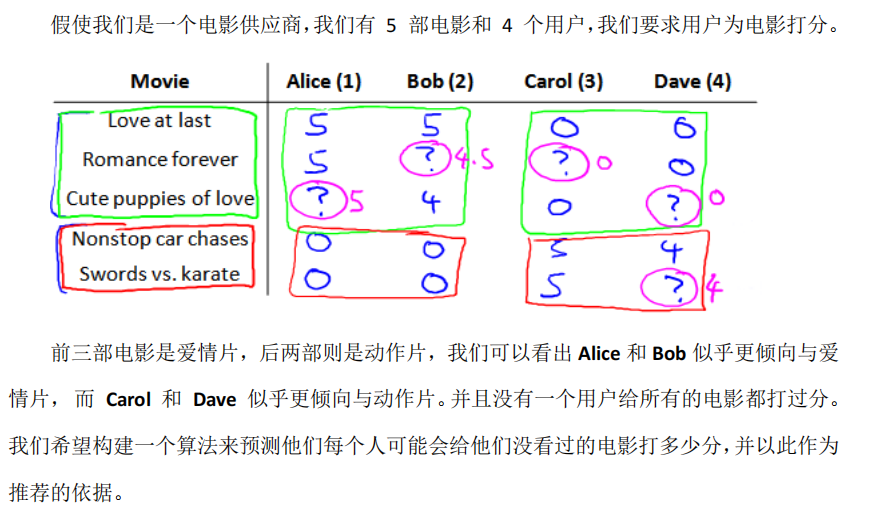
机器学习的范式包含但不限于以下几种:
三种主流范式:
- 监督学习(Supervised Learning)
监督学习模型主要是根据标注数据对模型的输入和输出学习到一种映射关系,以此对测试数据集中的样本进行预测。包含两类任务:分类和回归
- 无监督学习(Unsupervised Learning)
相比于监督学习,无监督学习仅依赖于无标签的数据训练模型来学习数据表征。主要任务包括:聚类、密度估计(学习输入数据的分布)、可视化(对数据简单进行统计或将高维数据映射到低维向量空间进行可视化)
- 强化学习(Reinforcement Learning)
强化学习强调如何基于环境而行动,以取得最大化的预期利益。与监督学习不同的是,强化学习不需要带标签的输入输出对,同时也无需对非最优解的精确地纠正。其关注点在于寻找探索(对未知领域的)和利用(对已有知识的)的平衡。Google的AlphaGo 是较为成功的强化学习案例。
一些主流的强化学习算法有:Q-learning、temporal-difference learning、deep reinforcement learning
混合学习范式
- 半监督学习(Semi-Supervised Learning)
半监督学习主要以少量标签数据和大量无标签数据来训练模型。半监督学习在实际场景中应用较多,因为实际生产中存在少量有标签和大量无标签的数据情况。主要思想是:在使用带标签数据进行有监督训练的同时,通过未标签的数据提供额外的信息来提高模型的性能。这种方法的基本假设是,未标签的数据中可能包含有助于提高模型泛化性能的信息。
半监督学习的主要方法包括:
- 自训练(Self-training):模型使用带标签数据进行有监督训练,然后使用模型对未标签数据进行预测,将预测结果添加到已标签数据中,反复迭代这个过程。
- 生成对抗网络(GAN):通过生成模型和判别模型的对抗训练,生成模型试图生成逼真的数据样本,而判别模型则试图区分生成的样本和真实样本。生成的数据可以与有标签的数据一起用于模型的训练。
- 协同训练(Co-Training):使用多个模型,每个模型在不同的特征空间上进行训练,然后模型之间相互交换信息,利用对方的预测结果作为标签。
- 标签传播(Label Propagation):通过在图上传播有标签节点的信息来为未标签节点生成标签,节点之间的连接表示样本之间的相似性。
- 自监督学习(Self-Supervised Learning)
自监督学习主要是利用「辅助任务(pretext)「从大规模的无监督数据中挖掘」自身的监督信息」来提高学习表征的质量,通过这种构造监督信息对网络进行训练,从而可以学习到对下游任务具有价值的表征。自监督学习的模型主要分为对比方法和生成方法;
- 多示例学习(Multi-Instance Learning)
多示例学习属于监督学习。在多示例学习中,训练集由一组具有分类标签(label)的多示例包(bag)组成,每个多示例包(bag)含有若干个没有分类标签的示例(instance)。如果多示例包(bag)至少含有一个正示例(instance),则该包被标记为正类多示例包(正包)。
如果多示例包的所有示例都是负示例,则该包被标记为负类多示例包(负包)。多示例学习的目的是,通过对具有分类标签的多示例包的学习,建立多示例分类器,并将该分类器应用于未知多示例包的预测。
统计推断
- 归纳学习(Inductive Learning)
归纳是从“具体到一般”的过程,即从一些实例中总结规律的过程。机器学习模型基于训练数据进行拟合是一个归纳法的过程。
- 演绎推断(Deductive Inference)
演绎是从一般到特殊的“特化过程”,在机器学习背景下,归纳是基于训练数据来拟合模型,演绎是基于训练的模型来对测试数据进行推断。
- 直推学习(Transductive Learning)
直推学习是同时使用训练样本和测试样本来训练模型,然后再次使用测试样本来测试模型效果,例如现在 GNN 中图节点分类中较为常见。
学习技术
- 多任务学习(Multi-Task Learning)
多任务学习(现在大多数机器学习任务都是单任务学习)是把多个相关(related)的任务放在一起学习同时学习多个任务,属于迁移学习的一种类型。
相关联的多任务学习比单任务学习能去的更好的泛化(generalization)效果。多任务学习的一个典型的例子:使用相同的单词嵌入来学习文本中的单词的分布式表示,然后这些单词在多个不同的自然语言处理监督学习任务中共享。
- 主动学习(Active Learning)
主动学习是在大多数情况下,有类标的数据比较稀少而没有类标的数据是相当丰富的,但是对数据进行人工标注又非常昂贵,此时学习算法可以主动地提出一些标注请求,将一些经过筛选的数据提交给专家进行标注,因此需要一个外在的专业人员能够对其进行标注的实体,即主动学习是交互进行的。这个筛选过程是主动学习主要研究点。
- 在线学习(Online Learning)
在线学习指利用在线流式的数据来迭代训练模型,online learning包括了incremental learning和decremental learning等情况,描述的是一个动态学习的过程。前者是增量学习,每次学习一个或多个样本,这些训练样本可以全部保留、部分保留或不保留;后者是递减学习,即抛弃“价值最低”的保留的训练样本。与在线学习相对的是离线学习(offline learning)。
- 迁移学习(Transfer Learning)
迁移学习是属于机器学习的一种研究领域。它专注于存储已有问题的解决模型,并将其利用在其他不同但相关问题上,例如现在的计算机视觉任务很多都是基于预训练的模型。
- 集成学习(Ensemble Learning)
集成学习是组合多个弱监督模型以得到一个更好更全面的强监督模型,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。集成学习的主流方法包括:bagging,boosting 和 stacking 等。