一·摘要

在机器学习中,惩罚系数是一个至关重要的超参数,它通过正则化机制来防止模型对训练数据过度拟合,从而提升模型在新、未见过的数据上的泛化性能。正则化过程涉及在损失函数中添加一个额外的项,这个项与模型参数的大小有关,并且由惩罚系数λ控制。这个额外的成本项旨在抑制过大的参数值,因为过大的参数值往往会导致模型过于复杂,从而增加过拟合的风险。
二·个人简介
🏘️🏘️个人主页:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证,CSDN内容合伙人,阿里云社区专家博主,新星计划导师,在职数据分析师。
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。

| 类型 | 专栏 |
|---|---|
| Python基础 | Python基础入门—详解版 |
| Python进阶 | Python基础入门—模块版 |
| Python高级 | Python网络爬虫从入门到精通🔥🔥🔥 |
| Web全栈开发 | Django基础入门 |
| Web全栈开发 | HTML与CSS基础入门 |
| Web全栈开发 | JavaScript基础入门 |
| Python数据分析 | Python数据分析项目🔥🔥 |
| 机器学习 | 机器学习算法🔥🔥 |
| 人工智能 | 人工智能 |
三·惩罚系数概念
在机器学习中,惩罚系数是一个至关重要的超参数,它通过正则化机制来防止模型对训练数据过度拟合,从而提升模型在新、未见过的数据上的泛化性能。正则化过程涉及在损失函数中添加一个额外的项,这个项与模型参数的大小有关,并且由惩罚系数λ控制。这个额外的成本项旨在抑制过大的参数值,因为过大的参数值往往会导致模型过于复杂,从而增加过拟合的风险。
L1和L2正则化是最常见的正则化形式。L1正则化倾向于推动模型参数中的一些变成零,产生稀疏解,这对于特征选择很有帮助。而L2正则化则倾向于让参数值均匀地接近零,但不会完全为零,这有助于确保模型的所有部分都有一定的贡献,而不是依赖于少数几个特征。
选择合适的惩罚系数非常关键,因为它直接影响到模型的泛化能力。如果惩罚系数太大,模型可能会因过于简单而欠拟合;如果太小,又可能会因过于复杂而过拟合。因此,通过交叉验证等技术来选择最佳的λ值是很重要的。
在多种机器学习算法中,包括线性回归、逻辑回归、岭回归、LASSO回归以及支持向量机等,都可以看到惩罚系数的应用。引入了惩罚系数后,模型的训练就变成了一个带约束的优化问题,需要使用特定的优化算法来解决,比如梯度下降法或坐标下降法。
四·原理
惩罚系数的原理是将约束优化问题转化为无约束优化问题来求解。这是通过在目标函数中加入一个与约束条件相关的惩罚项来实现的,这个惩罚项通常与被违反的约束条件的程度成比例。当迭代点不满足约束条件时,该方法会对目标函数的值施加一个很大的惩罚,迫使迭代点靠近或保持在可行域内。这样,随着惩罚系数的增加,无约束问题的解逐渐趋近于原约束问题的解。
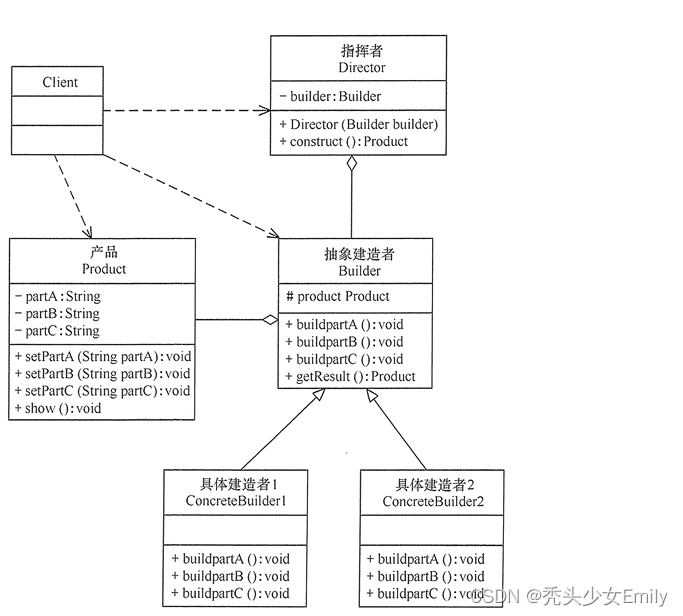
- 外点法和内点法:惩罚函数法分为外点法和内点法。外点法适用于等式和不等式混合的约束,可以从定义域内的任意点开始,将问题真正转化为无约束问题。而内点法要求初始点必须位于可行域内部,并且只适用于不等式约束。内点法的主要思想是从可行域内部出发,并在可行域内部进行搜索。
- 构造惩罚项:对于含有等式约束的问题,可以构造一个包含惩罚项的辅助函数,并求该函数的最小值。其中,惩罚项由一个很大的正数(惩罚因子)和违反约束程度的乘积构成。当迭代点满足约束条件时,不施加惩罚;否则,通过增加目标函数值的方式施加惩罚。
- SUMT方法:即序列无约束极小化技术,是一种实现惩罚函数法的具体计算过程。它涉及构造一系列的无约束问题,通过逐步增加罚因子来求解这一系列问题,最终得到约束问题的解。
- 乘子法:是另一种处理约束优化问题的方法,它通过增广拉格朗日函数来引入约束,其中的参数不需要趋向无穷大就能求得最优解,因此可以避免罚函数可能出现的病态行为。
- 理论支持:为了确保算法的有效性,存在一系列引理和定理来证明在一定条件下,通过这种转化得到的无约束问题的解会收敛到原约束问题的最优解。
五·作用
惩罚系数的作用体现在以下几个方面:
- 防止过拟合:通过引入惩罚系数,机器学习模型在训练时会被鼓励选择较为简单的模型参数,从而避免模型对训练数据过度拟合。
- 平衡拟合与泛化:惩罚系数帮助模型在拟合训练数据和保持良好泛化能力之间找到合适的平衡点,以期在未知数据上也能表现良好。
- 控制模型复杂度:较大的惩罚系数会限制模型参数的大小,降低模型复杂度;而较小的惩罚系数则允许模型有更多的自由度来学习数据的复杂结构。
- 优化问题的转换:在优化问题中,惩罚系数用于将有约束的优化问题转换为无约束问题,使得问题更易于求解。
- 调整损失函数:在某些算法中,如支持向量机(SVM),惩罚系数C可以看作是对违反硬间隔的损失函数(如hinge loss)的惩罚程度。当C值较大时,模型会更加强调正确分类的重要性,可能导致过拟合;而C值较小时,模型可能会忽视一些错分的情况,可能导致欠拟合。
六·详细讲解
惩罚系数是调节模型好坏的关键参数
下图展示了惩罚系数 对各个自变量(特征)的权重系数 的影响, 轴为惩罚系数 , 轴为权重系数 ,每一个
颜色表示一个自变量的权重系数
当 越大时(向左移动),惩罚项的影响也越大,会使每个自变量的权重系数趋近于零
当 越小时(向右移动),惩罚项的影响也越小,会使每个自变量的权重系数幅度变大
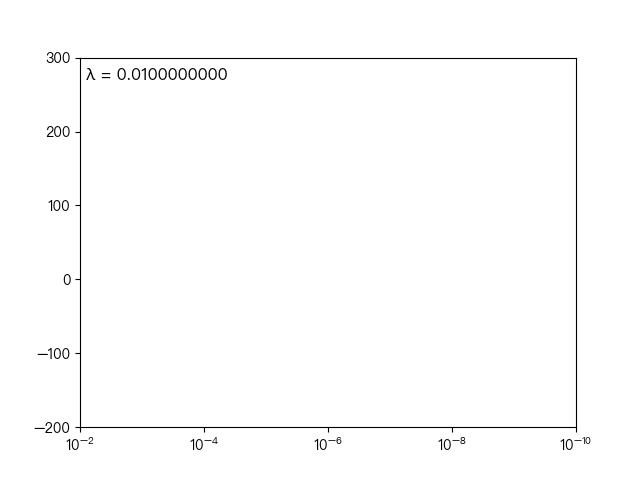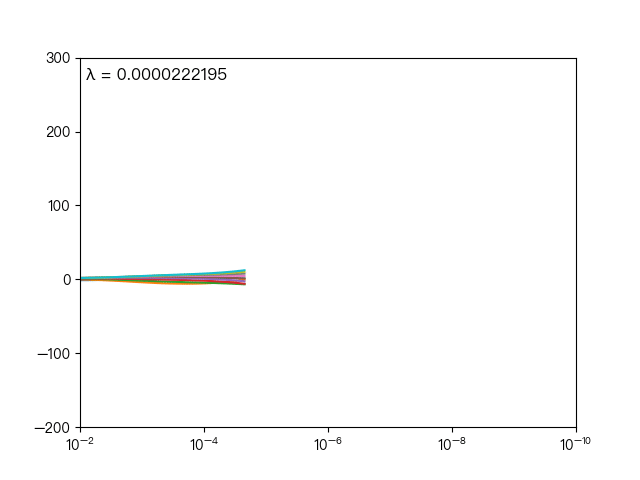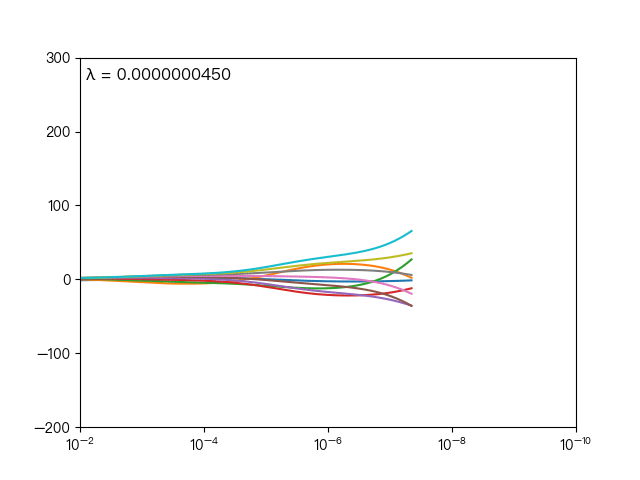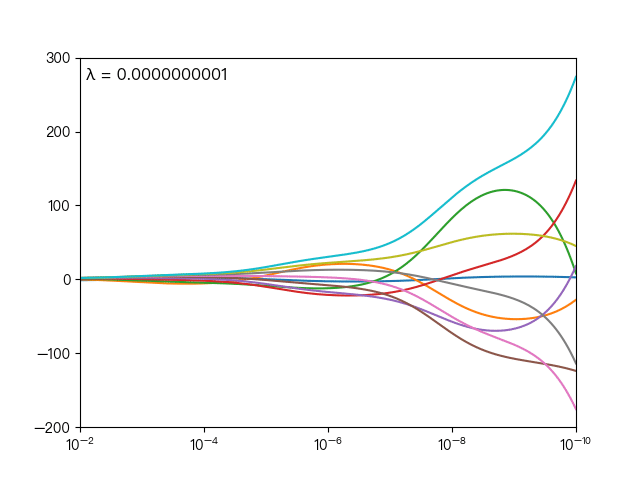
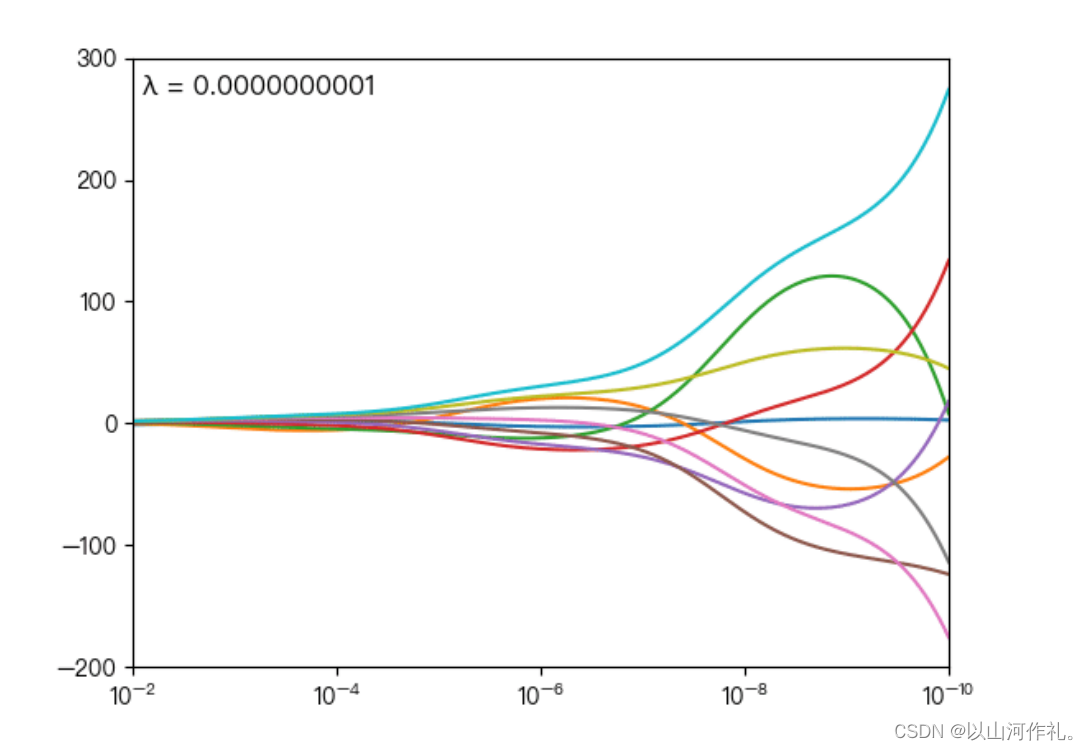
可以看到当 λ 越大时( λ 向左移动),惩罚项占据主导地位,会使得每个自变量的权重系数趋近于零,而当 λ 越小时( λ 向右移动),惩罚项的影响越来越小,会导致每个自变量的权重系数震荡的幅度变大。在实际应用中需要多次调整不同的 λ 值来找到一个合适的模型使得最后的效果最好。