一、什么是query改写?
query改写其实理解起来很简单,就是把原始的query经历一系列的操作,然后变成另外一个query,从而达到提升召回率和准确率的效果。
- query改写的过程中,这一系列的操作,其实是围绕两个方面展开的。第一是在原始query中添加一些有用的内容(可以理解为query扩展),把本该召回却没有召回的内容给召回,提高topK的召回率。第二是在原始query中去掉一些杂质内容(可以理解为蒸馏),主要操作是对召回的数据,进行一个反馈。
围绕这两个方面,特别是在LLM越来越火热的情况下,学术界有了越来越多的研究。
二、现阶的搜索方式
主要有三类:
其中最主流的是Bm25相关性搜索。
其次是在LLM取得阶段性进步后,使用模型做文本嵌入,然后做向量的搜索,利用余弦距离,来计算相关性。
最后是稀疏向量检索模型,这个非主流的方式,es官方为我们提供了英文的稀疏向量模型,在英文场景下的效果非常好。
三、关于query改写对召回的影响
针对扩展这个方向,要看具体的相关度匹配方法。
例如以BM25为代表的稀疏检索。BM25相关性匹配算法,最基本的就是依赖搜索的关键词和候选集的关键词的重叠。query扩展是会引入更多的词,扩大了召回的可能性,但是前提是引入正向的词,假如引入的是噪音数据,那么反而会降低召回的效果。所以针对BM25的搜索方法,需要做两件事,第一是如何丰富query;第二是如何对query蒸馏,去掉干扰因素。
在例如针对稠密向量检索。假如文本嵌入模型的能力足够强,简单的扩展关键词是没有意义的。而是如何扩展更多的有帮助的知识,来丰富query,从而提高召回率。
请时刻记得BM25和向量检索各自的特点。以为各自的特点,在query改写的时候会有不同的操作逻辑。
四、现阶段query Rewrite的挑战
1. 将query直接送给BM25去召回,或者向量检索去召回,召回率低,topk低。
2. 对于非即系搜索,我们想要在改写的时候考虑上下文的连贯性,去改写query。
五、利用模型做query Rewrite
LLM现在已经有了里程碑式的成功。LLM已成为引领各个领域变革的力量。LLM具有超强的语义理解能力,和超强的零样本生成能力。
针对使用LLM改写query这个方向,学术界,有了比较多的论文。包括谷歌和微软。
TODO 论文解读与链接
六、一口气读完10余篇论文后,关于LLM做Rewrite的总结
在此之前,我们先大体上看一下召回的流程图
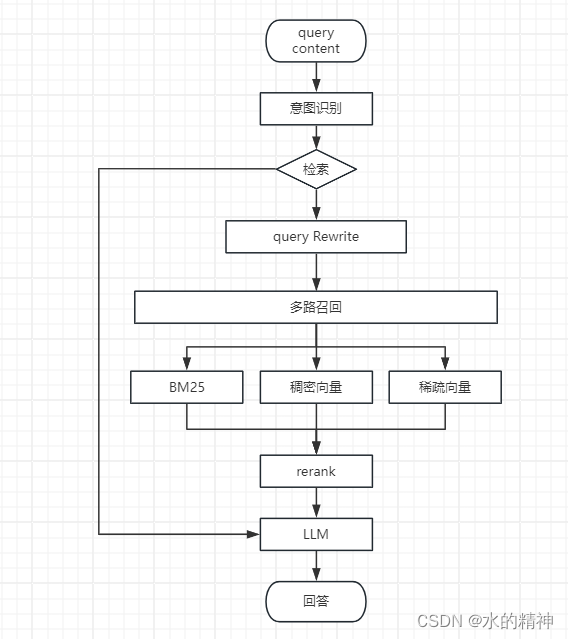
首先来说一下,这些论文中,提到的改写思路,先进行一个分类
1. HyDE
利用模型将对原始query生成一个假设性回答。然后再把假设性回答作为query去做召回。
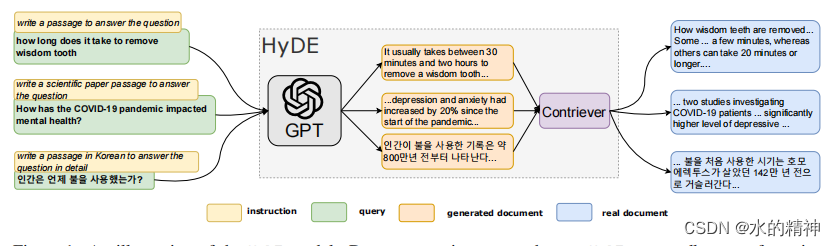
优势:利用LLM引入了query之外的外部知识,这部分知识可能和query很相关,从而丰富了query。
劣势:由于模型的幻觉问题,可能会生成和原始query相背离的答案。其次模型并不能总是生成有帮助的答案。此时会引入噪音数据,从而让查询变的更差。
具体操作步骤,针对不同的检索方式,有不同的操作细节。由于文章篇幅的问题,请到具体的文章上看,包含了原论文。
BM25:Query Rewrite —— 基于大模型的query扩展改写,召回提升3%-15%-CSDN博客
向量检索:Query Rewrite —— 基于大模型的query扩展改写,HyDE 生成假设性答案(论文)-CSDN博客
2.GRM
针对上述的模型幻觉问题,有一个改进方案,引入评估模型。
使用LLM针对query生成N个主题(论文中是生成5个主题,主题代表的是不同方向),然后再根据不同的主题让LLM分别去生成一个假设性回答,这里是生成10,也就是最后会得到50条数据。建设相关性评估模型,来过滤掉模型生成的负面的case。从而减少使用大模型做query Rewrite的时候的负面影响。
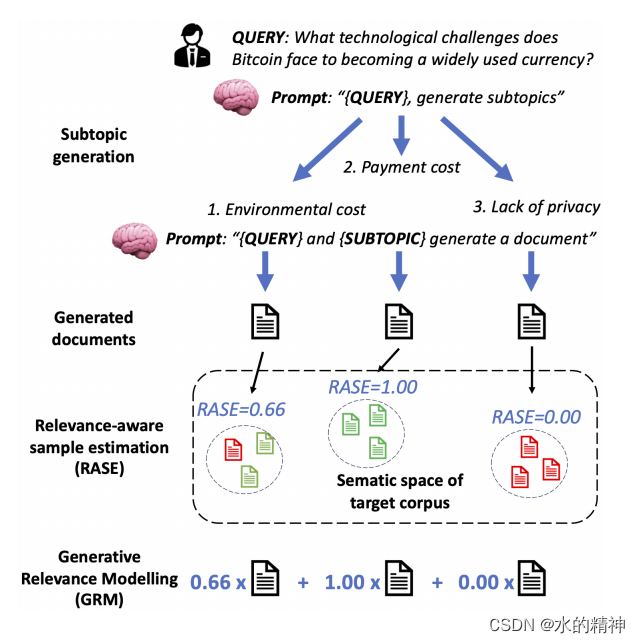
优势: 一定程度上可以减缓模型的幻觉问题
详细细节:Query Rewrite —— 基于大模型的query扩展改写,通过GRM减少LLM的幻觉问题(论文)-CSDN博客
3. PRF
为了解决模型的幻觉问题,而做出的改进。Pseudo-relevance feedback (伪相关反馈)。这也是一个在query改写过程中,解决模型幻觉问题的思路。
在改写前,先拿原始query去进行一次query,然后将召回的数据作为参考内容,送给模型,根据这些内容重新生成query。通过先在候选集中进行一次召回。可以给模型一个参考的内容,可以有效的减少模型的幻觉问题。
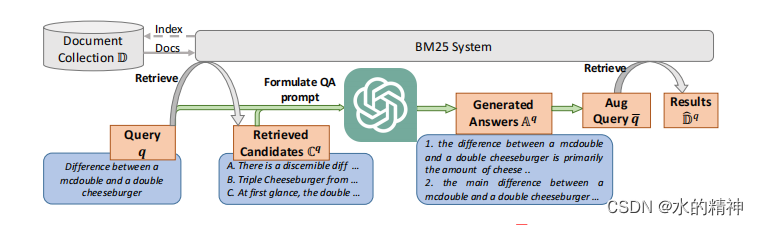
优势:可以一定程度上解决模型幻觉问题,有效解决解决词汇表不匹配问题。毕竟是根据query召回的内容去生成query的。
劣势:这将会很依赖首次的检索,如果召回的数据质量很差,就GG了。
关于PRF的细节
Query Rewrite —— 基于大模型的query扩展改写,PRF(论文)-CSDN博客
4.PRF + GRF
针对PRF的首次检索质量问题,有了 generative-relevance feedback (生成相关反馈)改进。
最近关于生成相关性反馈(GRF)的研究表明,使用从大型语言模型生成的文本的查询扩展模型可以改进稀疏检索,而不依赖于第一次检索的有效性。这项工作将GRF扩展到密集和学习的稀疏检索范式。GRF是在检索前, 靠模型,依赖模型的知识能力去扩展query。
乍一看GRF不是和上边的HyDE思路是一样的吗?不是有模型幻觉问题吗,怎么又回来了?别着急,这里是GRF + PRF。将两者进行结合。
并且这里的GRF是有改进的,并不是HyDE那种直接生成。
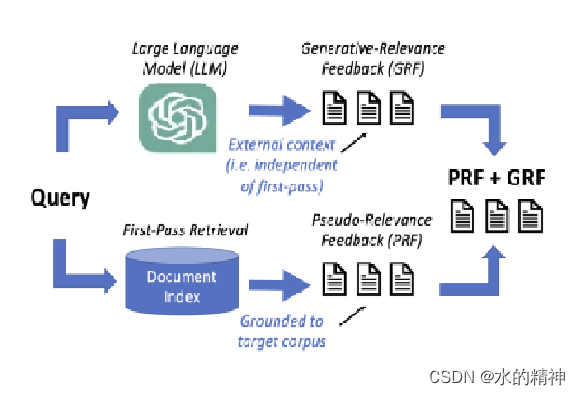
这里细节请看这篇文章Query Rewrite —— 基于大模型的query扩展改写,PRF+ GRF协同发力减少LLM的幻觉问题(论文)-CSDN博客
优势:将GRF和 PRF结合,有效减少了模型的幻觉问题,并且略微减缓了PRF严重依赖首次检索数据质量的问题。
注意:这里的GRF 时间上和GRM是有些类似的,在实际使用过程中,GRF的实现可以结合GRM的实现。
5. HyDE + PRF
北大的论文中,将HyDe + PRF进行了结合,来解决模型的幻觉问题。
Query Rewrite —— 基于大模型的query扩展改写,如何减少LLM的幻觉问题,召回提升15%(北大论文)-CSDN博客
6.CoT+ PRF
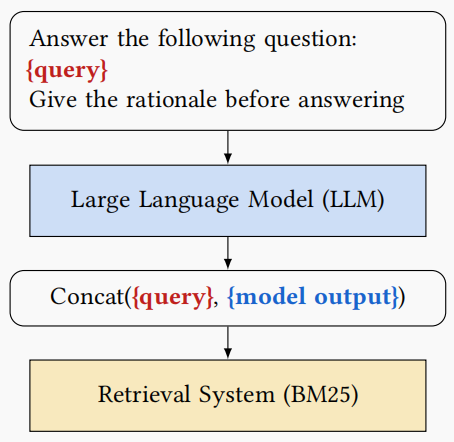
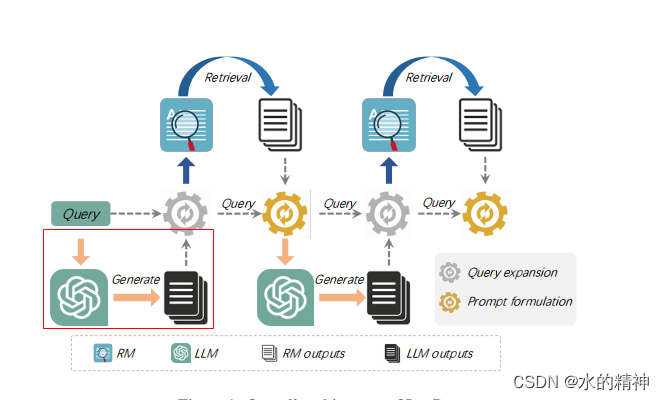
在谷歌的论文中,提出,使用LLM来改写query,并指定让LLM生成思维链CoT。这将有助于召回提升。思维链,在解决复杂的query问题的时候,往往会有不错的效果。
如下所示

详细细节:
Query Rewrite —— 基于大模型的query扩展改写(基于思维链),召回提升3%-CSDN博客
7.session上下文
重写的时候考虑上下文的连贯性。
主要解决的是从上下文的会话信息中,提取信息,已补充和改写最新的query。解决上下文的关联问题。详细细节请看这篇文章:Query Rewrite —— 基于大模型的query扩展改写,综合考虑上下文信息(人大论文)_query 改写论文-CSDN博客
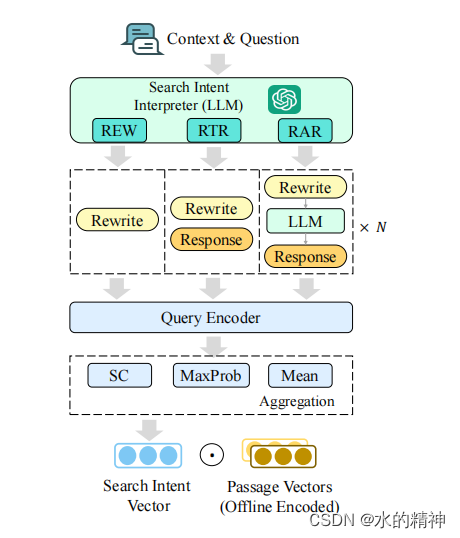
8. PRF + GRF + GRG + CoT + session上下文
这是我个人提出的想法,即要利用LLM提高召回率。又要减少模型的幻觉问题。还有考虑到上下文的会话数据。当然对于多轮对话,session上下文才有意义。并不是必须得。
七、顾虑
使用LLM改写query,虽然能够带来蛮不错的召回率提升效果,但是也带来了诸多问题。第一是检索成本,如果每个请求都要过两次模型,那么会有非常大的成本问题。第二,通常调用模型,响应时间都会大大增加,这会增大整个查询链路的延迟。甚至是无法满足实时交互。
八、参考文献
- Wang L, Yang N, Wei F. Query2doc: Query Expansion with Large Language Models[J]. arXiv preprint arXiv:2303.07678, 2023.
- Jagerman R, Zhuang H, Qin Z, et al. Query Expansion by Prompting Large Language Models[J]. arXiv preprint arXiv:2305.03653, 2023.
- Mao K, Dou Z, Chen H, et al. Large Language Models Know Your Contextual Search Intent: A Prompting Framework for Conversational Search[J]. arXiv preprint arXiv:2303.06573, 2023.
- Mackie I, Sekulic I, Chatterjee S, et al. GRM: Generative Relevance Modeling Using Relevance-Aware Sample Estimation for Document Retrieval[J]. arXiv preprint arXiv:2306.09938, 2023.
- Vincent Claveau. 2022. Neural text generation for query expansion in information retrieval. In IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT '21). Association for Computing Machinery, New York, NY, USA, 202–209. https://doi.org/10.1145/3486622.3493957
- Gao L, Ma X, Lin J, et al. Precise zero-shot dense retrieval without relevance labels[J]. arXiv preprint arXiv:2212.10496, 2022.
- Shen T, Long G, Geng X, et al. Large Language Models are Strong Zero-Shot Retriever[J]. arXiv preprint arXiv:2304.14233, 2023.
- Ma X, Gong Y, He P, et al. Query Rewriting for Retrieval-Augmented Large Language Models[J]. arXiv preprint arXiv:2305.14283, 2023.
- Mackie I, Chatterjee S, Dalton J. Generative and Pseudo-Relevant Feedback for Sparse, Dense and Learned Sparse Retrieval[J]. arXiv preprint arXiv:2305.07477, 2023.
- Feng J, Tao C, Geng X, et al. Knowledge Refinement via Interaction Between Search Engines and Large Language Models[J]. arXiv preprint arXiv:2305.07402, 2023.