Flink 使用状态来实现有状态的流处理。
1. 状态
在 Flink 中,状态(State)用于记录应用在运行过程中,算子(operator)的中间计算结果或者元数据信息。
运行中的 Flink 应用如果需要上次计算结果进行处理的,则需要使用状态存储中间计算结果。如 Join、窗口聚合场景。
有状态操作的一些例子:
- 对数据流中的重复数据去重,需要记录已经出现过的数据。当新数据流入时,需要根据记录的数据进行去重。
- 检查数据流是否符合某个特定的模式,需要记录之前流入的数据。比如判断一个温度传感器数据流中的温度是否在持续上升。
- 对一个时间窗口内的数据进行聚合分析,需要记录属于该窗口的数据。比如计算过去一小时内接口响应时间的 99 分位数。
- 在线机器学习场景下,使用状态保存模型参数的当前版本,并根据新流入数据更新模型参数。
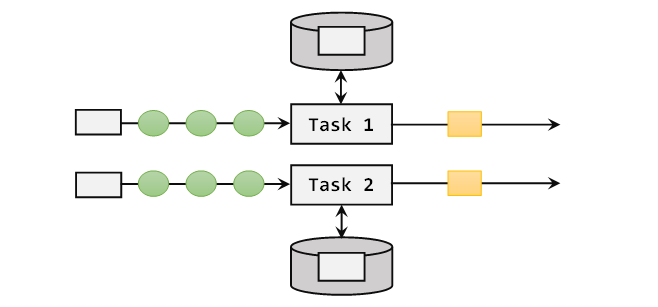
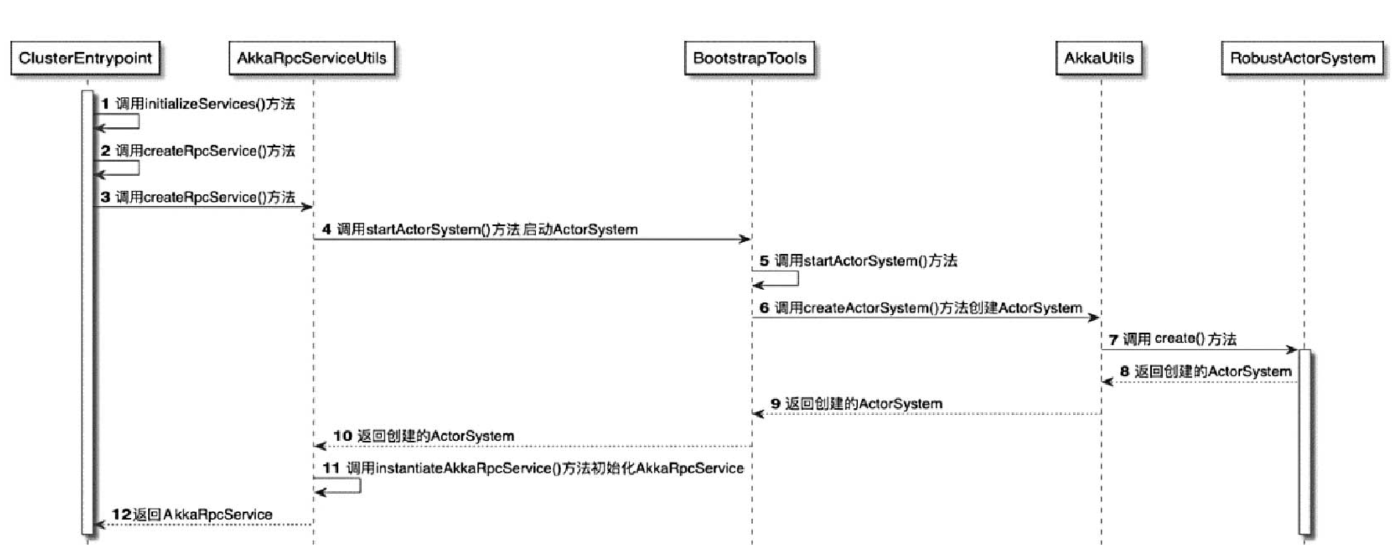
Flink 的一个算子有多个子任务,每个子任务分布在不同实例上。我们可以将 state 理解为某个算子子任务在当前实例上的一个变量,它存储了数据流的历史信息。当新数据流入时,我们可以结合历史信息进行计算。
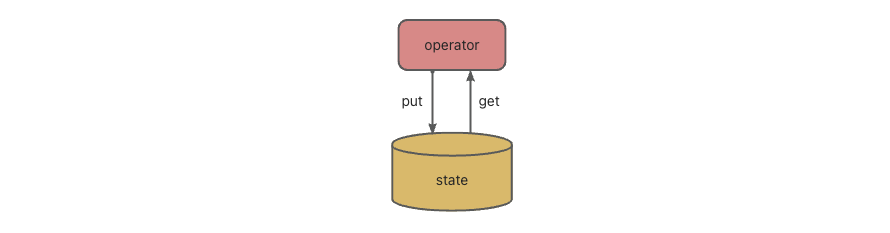
实际上,Flink 的 state 是由算子子任务来创建和管理的。一个 state 更新和获取的流程如下图所示:一个算子子任务接收输入流,获取对应的 state,根据新的计算结果更新 state。
2. 状态类型
Flink 有两种基本类型的状态,托管状态(managed state)和原生状态(raw state)。
Managed State |
Raw State |
|
由谁管理 |
Flink Runtime 托管,自动存储、自动恢复、自动伸缩 |
开发者自己管理,需要自己进行序列化 |
支持的数据结构 |
支持多种数据结构:ListState、MapState 、ValueState等 |
只支持字节数组:byte[] |
使用场景 |
绝大多数 Flink 算子 |
用户自定义算子 |
一般情况下我们使用 Managed State 就可以了,而Managed State可以分为Keyed State和Operator State。
Keyed State是KeyedStream上的状态,不同的key对应的不同的状态。Operator State则是和操作符(Operator)的一个特定的并行实例绑定。
keyed state |
operator state |
|
适用场景 |
只适用于 |
适用于所有算子 |
状态分配方式 |
每个 key 对应一个状态 |
每个算子子任务对应一个状态 |
横向扩展/扩缩容 |
状态随着 keyBy 的分组 KeyGroup 自动在多个算子子任务上迁移 以 KeyGroup 为单位重分配 |
有多种状态重新分配的方式,均匀分配或者广播分配 |
创建和访问方式 |
自定义算子(重写 RichFunction,通过 State 名称从 getRuntimeContext 方法创建或获得 state) |
实现 CheckpointFunction 等接口 |
支持数据结构 |
|
ListState、BroadcastState 等 |
3. StateBackend
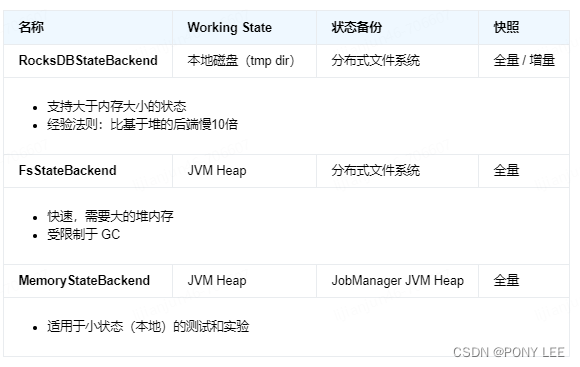
StateBackend定义了状态是如何存储的,不同的 State Backend 会采用不同的方式来存储状态。目前 Flink 提供了三种不同形式的StateBackend,分别是 MemoryStateBackend, FsStateBackend 和 RocksDBStateBackend,三者对比如下:
MemoryStateBackend |
FsStateBackend |
RocksDBStateBackend |
|
可存储对象 |
operator/keyed state |
operator/keyed state |
keyed state |
状态存储位置 |
TaskManager JVM 堆内存 |
TaskManager JVM 堆内存 |
RocksDB |
存取速度 |
快,存取需要访问堆上的对象 |
快,存取需要访问堆上的对象 |
慢,存取需要序列化和反序列化 |
存取大小 |
受限于JVM堆内存大小,可能导致 OOM |
受限于JVM堆内存大小,可能导致 OOM |
支持保存TB级别的state,上限取决于磁盘大小 |
支持快照方式 |
异步全量 |
异步全量 |
异步全量、异步增量 |
state 持久化位置 |
JobManager JVM 堆内存 |
文件系统 |
文件系统 |
一般而言,在生产环境中,我们会在 FsStateBackend 和 RocksDBStateBackend 间选择:
FsStateBackend:性能更好;日常存储是在堆内存中,面临着 OOM 的风险,不支持增量checkpointRocksDBStateBackend:无需担心 OOM 风险,是大部分时候的选择
4. 状态持久化
对于MemoryStateBackend和FsStateBackend来说,状态存储在 TaskManager 的 JVM 堆内存中;对于RocksDBStateBackend来说,状态存储在TaskManager的 ManagedMemory 中,如果 ManagedMemory 不够存储时,RocksDB 使用磁盘进行存储。
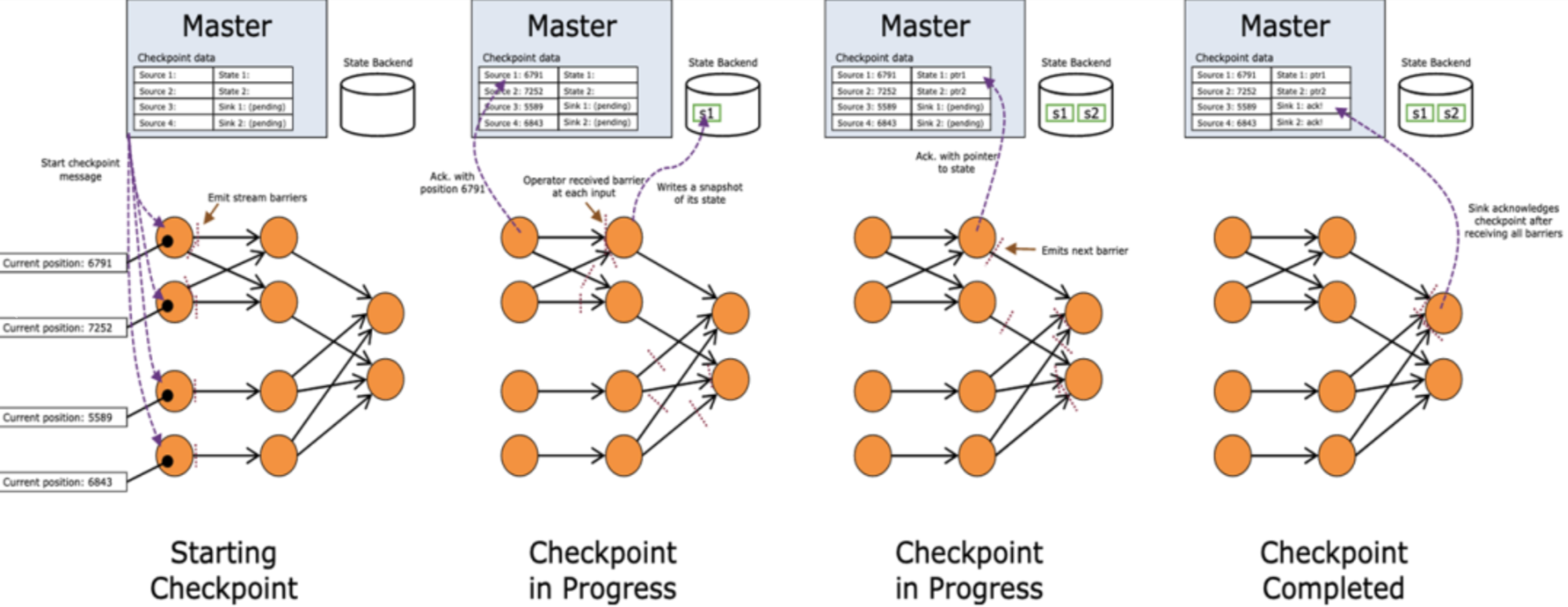
总而言之,状态存储在内存中,虽然满足了存取速度快的要求,但同时也面临着丢失的风险。所以,Flink 引入了状态快照的概念,定期将状态进行持久化。
状态持久化是通过 checkpoint 完成的,所以状态持久化也就是 checkpoint 的存储,可以分为:
- 基于内存的全量
checkpoint HDFS全量checkpoint- 基于
RocksDB的全量/增量checkpoint
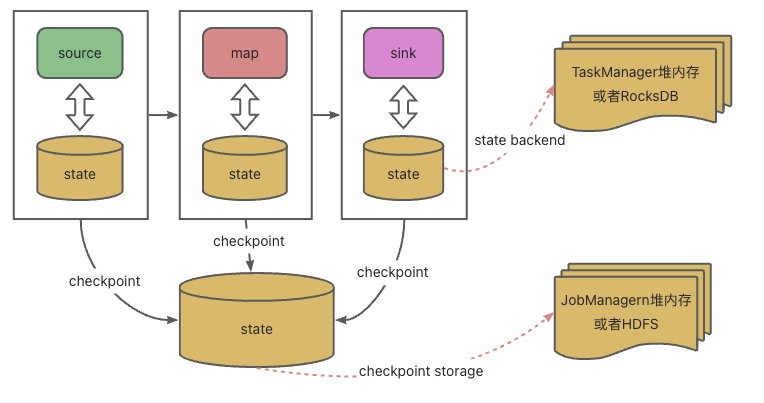
不管使用了哪种state backend,容错都是由CheckpointStorage来管理的,它定义了在流应用中为了实现容错state backend如何保存状态。
Flink定期获取每个操作符的所有状态的持久快照,并将这些快照复制到更持久的地方,比如分布式文件系统。如果发生故障,Flink可以恢复应用程序的完整状态,并恢复处理过程,就像没有发生任何错误一样。存储这些快照的位置叫做CheckpointStorage。
CheckpointStorage有两种实现:一种将其状态快照持久化到分布式文件系统,另一种使用JobManager的堆内存。
JobManagerCheckpointStorage |
FileSystemCheckpointStorage |
|
保存位置 |
JobManager的堆内存 |
文件系统,比如 HDFS,S3, NFS, GCS |
优点 |
轻量级、不需要额外的依赖 |
支持 TB 级别的状态大小;高可用 |
缺点 |
不可扩展,只能保存很小的状态 |
|
适用场景 |
本地开发和测试 |
生产部署 |
StateBackend 与CheckpointStorage的对应关系:
MemoryStateBackend使用JobManagerCheckpointStorageFsStateBackend和RocksDBStateBackend使用FileSystemCheckpointStorage
5. 总结
有了状态之后,Flink 可以实现有状态的流处理。
有了状态之后,Flink 可以跨并行实例重新分配状态,来实现 Flink 应用程序的扩缩容。
Flink 提供了不同的state backends,用于指定如何存储状态,以及在何处存储状态。
State Backend和checkpoint的关系如下图: