面试题来源 :PostgreSQL学徒 PostgreSQL面试题集锦
已有的答案:Hehuyi_In 《PostgreSQL面试题集锦》学习与回答
一、MVCC 实现机制以及和 Oracle 的差异
ORACLE,MYSQL都是使用的UNDO来实现多版本并发控制,undo条目记录在从额外的undo表空间中,如果UNDO段不够会报ora-01555的错误。
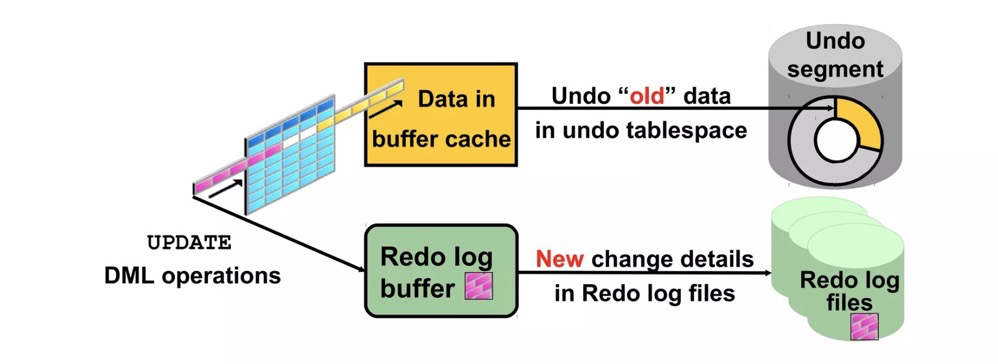
https://www.slideshare.net/AmitBhalla2/less10-undo-15946188
PostgreSQL没有undo机制,为了保证事务回滚,旧的元组仍然在表上。如update会新插入一行数据,老的数据还保留在原来的位置,然后通过元组头、clog等来判断新旧元组哪个是有效的。这些元组头上的可见性信息包括xmin、xmax、cmin、cmax、infomask、infomask2,存储在元组头

https://www.interdb.jp/pg/pgsql05/03.html
优劣势:undo方案需要额外的undo空间,空间管理比较简单,问题在于大事务回退时非常麻烦,需要将undo段回滚。新增元组方案的大事务回滚非常快,不过该方式会有死元组问题,导致需要引入vacuum机制来清理死元组。vacuum freeze本身跟清理死元组没什么关系(但都是vacuum进程),freeze是为了防止事务ID回卷。
二、为什么会有表膨胀及表膨胀的危害
为什么有表膨胀?
同上,因为PG特殊的MVCC机制,delete不会真的删除元组,update相当于delete+insert,旧元组本身不能通过DML语句来删除,这样就只有“涨”空间没有“清理”空间,这就是表膨胀。此时一般需要vacuum来清理死元组,把空间标记为可用,下次写入时可以用到这部分空间;或者vacuum full等方式重写表,让表变得更加紧凑。
表膨胀的危害:
- 表占用过大的空间
- 进而引起sql性能降低
- 表过大会也会导致vacuum清理时间变成长;vacuum full阻塞时间也会变长,不过可以通过pg_repack来代替vacuum full,减少阻塞时间
处理表膨胀:
1.手动vacuum
- 不会阻塞查询和DML业务
- 不会立即回收空间,只是把空间标记为可用
- 如果表的最后一个page没有元组了,这个page会被truncate

(https://www.interdb.jp/pg/pgsql06.html)
2.autovacuum
- autovacuum会根据需要自动调用vacuum进行concurrently清理
3.手动vacuum full
- 8级锁,阻塞一切
- 表完全重写,操作系统上对应的文件会被清理和重建
- 重建索引、FSM(可用空间文件)、VM (page可见性文件)
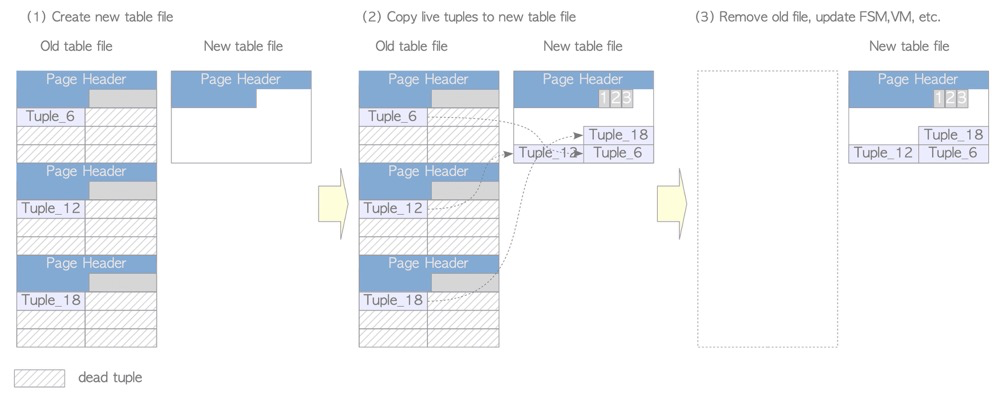
4.pg_repack等手动重建表
- pg_repack只有在最后切换表的时候有短暂的锁
- 其他具备数据同步、切换功能的工具
避免表膨胀:
一般来说autovacuum可处理表膨胀,不过有些场景下清理进行的可能不顺利:
1.autovacuum worker没跑起来
autovacuum,track_counts参数均必须打开,autovacuum才会工作autovacuum_max_workers设置足够work进程数上限,可能同一时间需要多个work清理多个表- 没有到达表的vacuum阈值–delete和update的行数:阈值=
autovacuum_vacuum_threshold+autovacuum_vacuum_scale_factor*tuples autovacuum_vacuum_insert_threshold和autovacuum_vacuum_insert_scale_factor表示insert的阈值,算法同上。insert触发的vacuum阈值理论上跟表膨胀清不清理没什么关系,因为insert不会产生死元组。不过为了防止一次来不及处理回卷问题,pg13新增了这个参数(参考 postgresql-autovacuum-insert-only-tables)autovacuum_naptime表示autovacuum launcher的执行周期。比如该参数设置的特别大,可能造成autovacuum_max_workers足够,并且有表达到清理阈值,但launcher没有唤醒worker的情况vacuum_defer_cleanup_age延迟多少个事务再进行vacuum清理(本身是为了缓解备库环境查询冲突而设置的参数,因为有hot_standby_feedback和复制槽,pg16已删除该参数)
2.关闭或调整cost-based vacuuming让autovacuum跑的更快
- 由于为了降低vacuum对IO的影响,可能打开了cost-based vacuuming功能,vacuum/autovacuum达到cost limit时睡眠
autovacuum_vacuum_cost_delay(或vacuum_cost_delay)毫秒。vacuum_cost_delay默认0表示关闭cost-based vacuuming功能,autovacuum_vacuum_cost_delay为-1表示使用vacuum_cost_delay参数。应该关闭delay或者将delay值调小 - 如果开启了cost-based vacuuming,应合理调大
vacuum_cost_limit的触发睡眠值,以及调小计算到limit里的vacuum_cost_page_dirty,vacuum_cost_page_miss,vacuum_cost_page_hit参数
3.表上有事务阻止vacuum运行
- 业务的长事务没有结束。业务侧事务不要跑太长时间;数据库侧可通过断开连接的方式杀掉会话1).手动kill 2).设置idle_in_transaction_session_timeout限制事务idle过长 3).设置old_snapshot_threshold限制SQL执行过长(PG14以前不建议打开)
- 未关闭的游标
- hot_standby_feedback打开后,主库记录catalog_xmin,备库长查询阻止主库回收(参考:流复制-查询冲突)
- 删除不要的复制槽
- 孤儿事务。prepared事务是PG内部的显示开起的2PC事务,prepared事务如果开启后没有完成,prepared事务又与会话无关,导致孤儿事务无限期阻塞(参考:pg事务:2PC)
- pg_dump逻辑备份开启隐式repeatable read隔离级别,事务未结束
4.性能方面
maintenance_work_mem参数是vacuum等维护操作使用的内存,默认64MB可以再调大一点。或者用autovacuum_work_mem参数单独设置autovacuum worker的内存,autovacuum_work_mem默认-1表示使用maintenance_work_mem参数的设置- 一般大表的vacuum会特别慢,由于同一表上的vacuum无法并行,可以将大表改造为分区表,vacuum可以在各个分区上并行执行
- 良好的IO系统
5.调整表上的autovacuum参数
- 全局的autovacuum相关参数设置可能不适应于某些特殊业务表,可调整表上的autovacuum相关参数,提高触发vacuum几率
6.手动vacuum
- autovacuum总体上是难预料的,对于特殊的业务表可手动vacuum
- 在业务低峰期手动执行vacuum命令,可附带freeze,analyze一起使用
以上可以处理99.99%的表膨胀问题,有一种表膨胀上面的方法是难以处理的:cost-based vacuuming关闭的情况下,autovacuum清理死元组速度赶不上生成速度。本质上是因为update(或者insert+delete)事务并发太多,这次的vacuum还没来得及清理出之前的可用空间,就有大量update生成新的空间和死元组,导致表不断膨胀。解决办法:
- 改造为分区表以增加vacuum并行度,前提是update需要打散到各个分区上,不然没有意义
- 低峰期执行vacuum full或者pg_repack,彻底清理表的空洞。
- 不太可能有24h高并发的表,如果有应该改造为多表写入,或者搬到redis等缓存系统上
https://www.interdb.jp/pg/pgsql06.html
https://www.postgresql.org/docs/16/routine-vacuuming.html
https://www.postgresql.org/docs/16/runtime-config-autovacuum.html
https://www.postgresql.org/docs/16/runtime-config-resource.html#GUC-VACUUM-COST-DELAY
三、长事务的危害以及如何溯源长事务
一般的查询不会生成事务ID,而是虚拟事务ID(vxid),虚拟事务ID由backendID和backend本地计数器组成,与事务ID(XID)没有关系(参考:pg事务:事务ID)。不过查询虽然不会生成事务ID,但是它会持有快照以保证可见性检查,快照中包含元组xmin等信息(参考:pg事务:可见性检查,pg事务:快照)
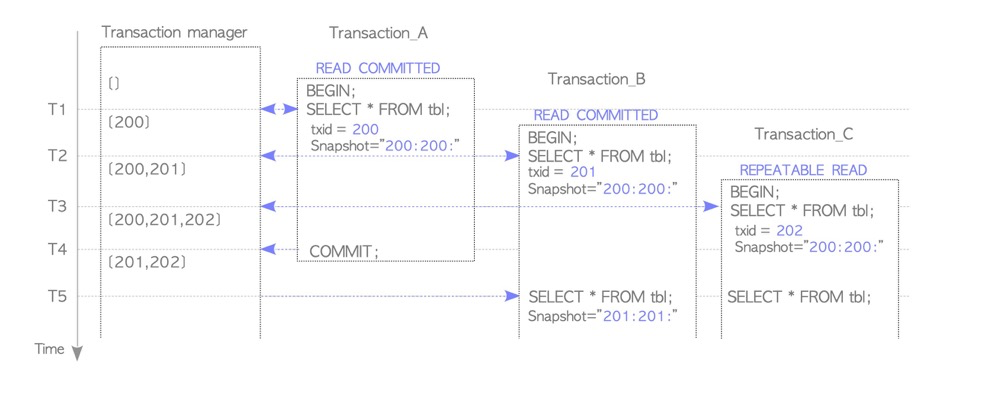
(https://www.interdb.jp/pg/pgsql05/05.html)
所以,长事务问题不仅包含DML语句也包含查询语句,不过两者的申请的锁是不同的
长事务的危害:
- 阻碍vacuum回收,导致表膨胀、导致过多的空间占用、导致SQL性能下降
- 阻碍其他锁申请,例如DDL执行前必须检查表上是否有长事务,不然长期申请不到更高级别的锁,导致锁放大
- 长事务会导致create index currently失败,留下失效索引
- 占用连接池(当然一般主要是长连接问题导致)
- 逻辑解析数据落盘导致复制延迟,与大事务也有关系(参考:pg内功修炼:逻辑复制)
- 一个长事务和一个savepoint子事务也可能造成查询库性能断崖(参考: Why we spent the last month eliminating PostgreSQL subtransactions)
如何溯源长事务:
- pg_stat_activity查看xact_start事务开始时间,state_change查看事务是否还在运行
四、子事务的危害和注意事项
子事务的危害:
事务ID消耗过快,过早的处理事务回卷问题。每个子事务都会消耗一个xid
PGPROC_MAX_CACHED_SUBXIDS溢出,导致性能下降。每个backend都有子事务cache为
PGPROC_MAX_CACHED_SUBXIDS,固定64个子事务(源码写死),超过64个子事务会溢出到pg_subtrans目录(参考:PostgreSQL Subtransactions Considered Harmful)子事务和for update显示行锁一起使用,导致数据库性能急剧下降 (参考:Notes on some PostgreSQL implementation details)
一个长事务和一个savepoint子事务也可能造成查询库性能断崖(参考:Why we spent the last month eliminating PostgreSQL subtransactions
使用建议和注意事项:
- 不建议使用子事务,参考以上危害
- 如果有从库查询业务,禁止使用子事务。
- 如果仍有子事务,子事务设置不要超过64个,最好是更低
- 除了显示savepoint使用子事务,excetpion、框架、工具中同样会产生子事务
五、表结构变更哪些操作是非 online 的
表结构变更都是非online的,因为所有表结构变更(alter table)都需要申请8级锁,只是有些表结构变更本身需要很长时间或者变更后业务跑的慢。所以这个问题可以转化为下面下面三个问题:
对索引是否有影响?对统计信息是否有影响?是否要重写表导致长期持有8级锁?
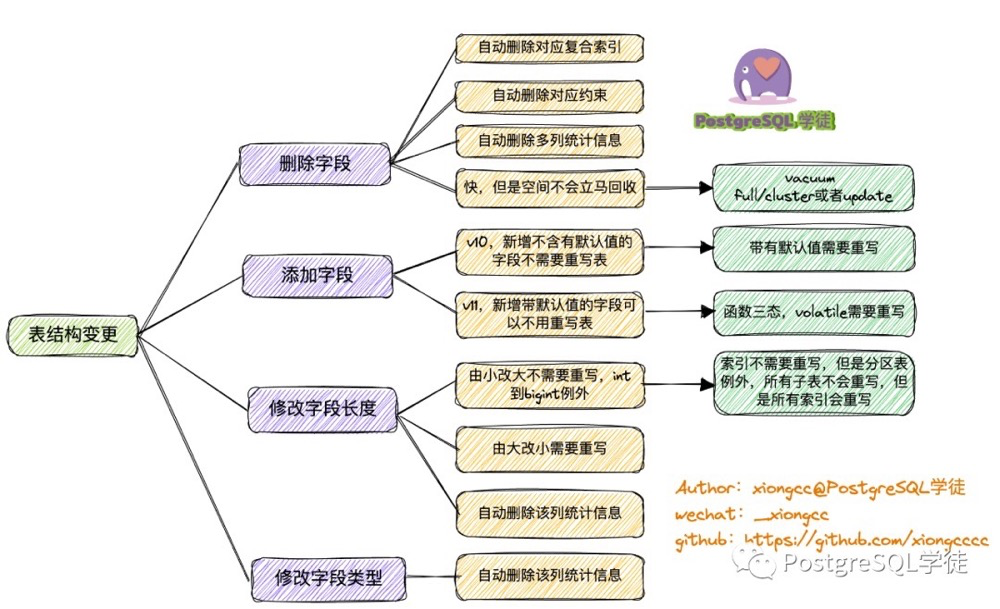
结合上面的信息,汇总记忆:
- 删除字段可立即完成,但需要考虑复合索引和多列统计信息失效,以免引起sql性能雪崩
- 添加字段只考虑带默认值:1)pg10以前需要带默认值需要重写表 2)pg11以后 默认值为volatile函数需要重写表。另外添加字段后不会立即有统计信息
- 修改自动长度:小改大,除int到bigint,都不需要重写表;大改小需要重写表;列统计信息失效
- 修改字段类型:表重写;统计信息失效。
- 已有字段添加约束会扫描表,需要注意扫描时间,(如
ADD CONSTRAINT,SET NOT NULL) - 已有字段添加默认值立即完成(如
SET/DROP DEFAULT) - SET { LOGGED | UNLOGGED } 会重写表
- 表的storage_parameter变更,具体看变更什么参数。比如fillfactor、autovacuum相关参数是online的非8级锁,立即完成(参考:[Storage Parameters)
六、物理备份需要注意什么(pg_start_backup)

(https://postgrespro.com/media/2022/03/24/pgpro-backup-methods%20(1).pdf)
pg物理备份:
块层面的备份,一般不支持单独的database备份(pg_probackup除外)
排他模式没有必要存在,原因:1) 只能在主库备份 2)不允许并行备份 3)创建的backup label可能阻止主库实例恢复 4)功能上跟非排他备份没有区别。PG9.6开始支持非排他模式,PG15移除排他模式
如果显示使用pg_start_backup(),应显示使用pg_stop_backup()关闭备份模式(PG15后函数名有些区别)
备份中FPI功能会强制打开,即使没有把full_page_writes设为on
所有工具(maybe),备份开始前都会调用pg_stop_backup()做一个checkpoint写脏数据,并备份从备份开始到结束的所有wal日志,哪怕是备份过程中数据库新生成的WAL,以保证数据一致性和PITR
pg_basebackup:
原生自带
封装pg_start_backup和pg_stop_backup命令
pg17开始支持增量备份,支持合并备份集
占用一个walsender进程
pg_probackup:
非常强大,支持增量备份、增量恢复、并行、合并被集、备份集校验、远程备份、恢复指定database等
BUG:寻址空间不能超过4GB,可通过修改源码修复
pgBackRest:
也非常强大
大前提:必须备份机到数据库主机的配置ssh
https://developer.aliyun.com/article/59359
https://www.postgresql.org/docs/current/app-pgbasebackup.html
https://www.enterprisedb.com/blog/exclusive-backup-mode-finally-removed-postgres-15
https://github.com/MasaoFujii/pg_exclusive_backup
https://github.com/postgrespro/pg_probackup
https://pgbackrest.org/user-guide.html
七、逻辑备份是如何确保一致性的
- pg_dump的一次完整的备份是在一个事务中完成的, 事务隔离级别为serializable 或者 repeatable read
- pg_dump在备份数据开始前, 需要对进行备份的对象加ACCESS SHARE锁,防止表被删除。
另外逻辑备份还需注意:
- 导出时需要特别注意是否有锁冲突
- 如果有ddl需求,应考虑不要备份全库或长时间备份;或者把备份任务拆开为多个,比如一次一个表多次调用pg_dump
https://developer.aliyun.com/article/14582
八、WAL 堆积的原因有哪些
- 失效的复制槽
- 逻辑复制有长事务
- 过大的wal_keep_size
- 过小的archive_timeout。强制切换wal并归档,相当于pg_switch_xlog()切换日志+归档
- 归档失败会生成.ready文件
- 单进程归档,归档速度跟不上
- FPI全页写(应检查checkpoint是否过于频繁、UUID等离散写行为)
九、长连接的危害是什么
pg在获得快照数据的时候,需要检索所有backend进程的事务状态,过多的连接导致性能下降(建议连接数不超过1000,pg14有优化但是仍不建议过多连接)
relcache/syscache不会释放缓存的元数据,且每个进程都单独缓存,导致内存消耗较多
十、infomask 标志位的作用是什么
- infomask提供了事务、锁、元组状态等信息,比如事务是否提交、终止,行锁信息、HOT信息、列个数等等,非常多信息
- header中有两个infomask:
infomask和infomask2。他们存储的信息有所不同,通过不同的位代表不同的含义 - hitbits的事务信息也会写入infomask,这样可以不用访问clog,仅访问元组头信息就可以知道元组的插入、删除任务是否完成、是否先于或后于本事务以判断元组的可见性
十一、空值是如何存储的以及索引是否存储空值
空值如何存储:
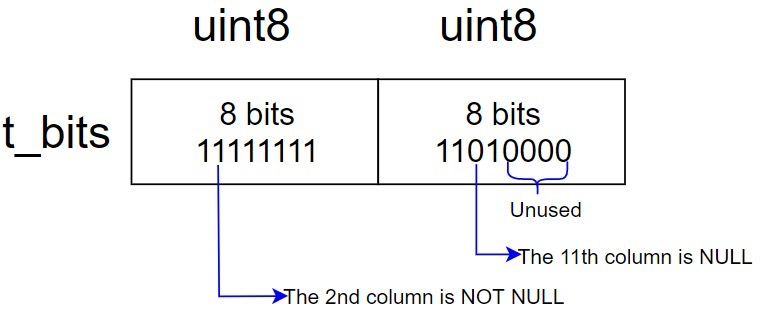
- 在tuple header中存储null,而不是tuple的data段
- infomask中有一位标记该元组是否有NULL
- t_bits有n*8位(n为整数,如10列的表有16位的t_bits),以位图来代表哪一列是null的
索引是否存储空值:
- postgresql的索引存储空值,oracle索引不存空值
- 存储的位置取决于(NULLS FIRST or NULLS LAST)
https://www.highgo.ca/2020/10/20/the-way-to-store-null-value-in-pg-record/
十二、为什么需要有全页写(full_page_write)
官方文档对full page write介绍比较笼统:
This is needed because a page write that is in process during an operating system crash might be only partially completed, leading to an on-disk page that contains a mix of old and new data. The row-level change data normally stored in WAL will not be enough to completely restore such a page during post-crash recovery. Storing the full page image guarantees that the page can be correctly restored, but at the price of increasing the amount of data that must be written to WAL. (Because WAL replay always starts from a checkpoint, it is sufficient to do this during the first change of each page after a checkpoint
操作系统文件页一般为4k,pg的page一般为8k,可能发生partial write的情况,导致磁盘上的一个数据页既包含老数据也包含新数据,这会导致数据恢复时发生数据丢失,所以需要引入引入全页写机制。
partial write跟磁盘有很大关系,能详细回答这个问题是比较难的,参考roger这篇文章,总结:
partial write与磁盘是否支持原子写有关系
partial write与操作系统块大小与数据库块大小是否匹配有关系。oracle、pg的块默认8k,mysql默认16k,os默认4k,数据库的一次最小IO对于操作系统来讲需要调用多次完成
对于PG来说,如果数据页出现partial write,可根据wal中的full page进行恢复
对于mysql,有double write机制。double write buffer是磁盘上的空间,顺序写;在写数据前先顺序写到这里以缓解partial write问题
对于oracle,做了很多工作不过没有一个明显的解决方案。但是oracle支持块级恢复以替换损坏的数据块。
不同的DB都采用了不同的方案来减少partial write,比如PG把整个数据页写到wal日志中,但是这带来了wal写放大问题。当然这可以通过一些方式缓解wal写放大。
怎么完美解决partial write问题?
- 支持原子写的设备
- OS最小IO与数据库最小IO保持一致
http://www.killdb.com/2020/04/05/double_write_partial_write_oracle_mysql_postgresql/
十三、索引失效的各种原因
索引失效:
create index concurrently时因为死锁或唯一索引检查失败会留下一个invalid索引,invalid索引也会被更新
分区表主表上索引invalid,代表某些分区有索引某些分区没有(参考:PostgreSQL分区表)
索引用不上:
统计信息不准确
选择率
数据倾斜
软解析,前5次缓存了其他执行计划
最左原则
数据过少,如hash、全表不比索引慢
函数(除非对应immutable函数索引),隐式转换、运算、like左边带%···
数据类型不一致
字符集不一致(pg里问题不大,因为pg中database一旦创建字符集不能更改,一个database下的数据是同一字符集,不同database正常不能交叉访问)
sql的collation排序与索引collation排序不一致
like只能使用collation C或pattern索引(参考:PostgreSQL本地化)
correlation较大,索引的逻辑顺序与数据的物理顺序相关性,通过索引访问较为离散的数据
limit xx ordr by column1、min/max等需要取TOP N的场景,优化器选择了其他索引
十四、commit log 的作用
commit log是为了记录事务状态的。在表的下一次可见性检查时,触发hintbits,将clog的事务状态写入到元组头。
**为什么不能将事务状态立即写入元组头?**hintbits立即更新性能非常差,所以将事务状态先放在clog,减少PGXACT的争用,以提升性能
十五、数据库的连接方式以及各自适用的场景
1.1 Nested Loop Join

lzldb=# explain select a from lzl1,t3 where lzl1.col1=t3.a::text;
QUERY PLAN
-----------------------------------------------------------
Nested Loop (cost=0.00..2.29 rows=10 width=4)
Join Filter: ((lzl1.col1)::text = (t3.a)::text)
-> Seq Scan on t3 (cost=0.00..1.01 rows=1 width=4)
-> Seq Scan on lzl1 (cost=0.00..1.10 rows=10 width=2)
驱动表(图中outer,plan中的第一行表)将自身的每个行与被驱动表(图中inner,plan中第二行表)的每行匹配,驱动表只扫描一次,被驱动表被扫描N次(N=驱动表的行数)
NL适用几乎所有场景,是最简单暴力的连接,一般较小的表为驱动表(其实两个表都不会太大,除非其他场景的join都不适用)
1.2 Materialized Nested Loop Join
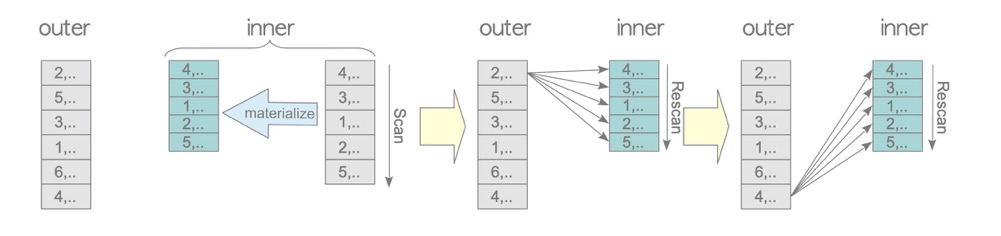
testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id;
QUERY PLAN
-----------------------------------------------------------------------
Nested Loop (cost=0.00..750230.50 rows=5000 width=16)
Join Filter: (a.id = b.id)
-> Seq Scan on tbl_a a (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..98.00 rows=5000 width=8)
-> Seq Scan on tbl_b b (cost=0.00..73.00 rows=5000 width=8)
如果因为被驱动表(inner)需要被扫描多次,如果每次都是物理IO的话将会非常慢(看起来也很蠢)。Materialize就是把被驱动表scan到内存(work_mem)中,只做一次物理扫描表,让被驱动表在内存中被多次访问。
这种场景是真实业务中非常常见的。
1.3 Indexed Nested Loop Join(inner indexed)
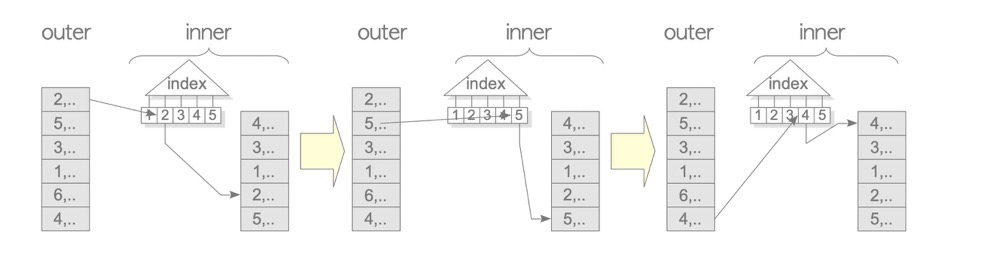
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id;
QUERY PLAN
--------------------------------------------------------------------------------
Nested Loop (cost=0.29..1935.50 rows=5000 width=16)
-> Seq Scan on tbl_b b (cost=0.00..73.00 rows=5000 width=8)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..0.36 rows=1 width=8)
Index Cond: (id = b.id)
**1.4 NL变体 **
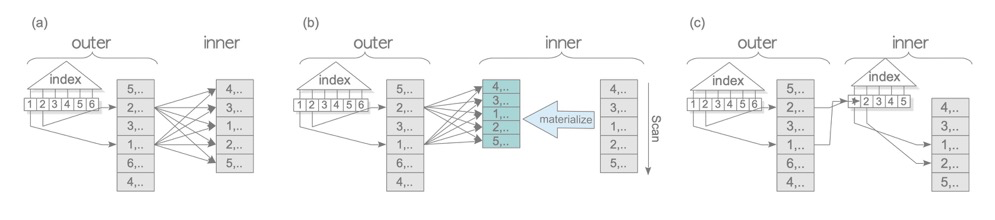
本质都是NL,主要变化是两边的表上是否有用到索引、是否有Materialize
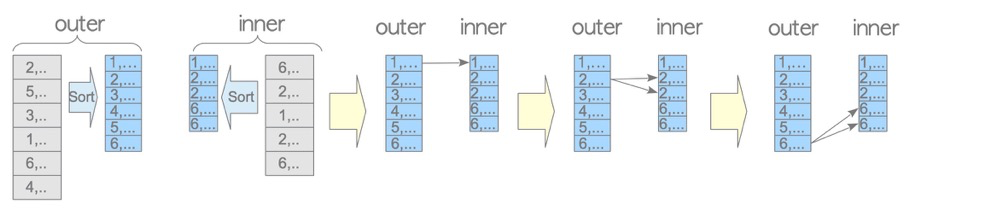
2.1 merge join
testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id AND b.id < 1000;
QUERY PLAN
-------------------------------------------------------------------------
Merge Join (cost=944.71..984.71 rows=1000 width=16)
Merge Cond: (a.id = b.id)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: a.id
-> Seq Scan on tbl_a a (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=135.33..137.83 rows=1000 width=8)
Sort Key: b.id
-> Seq Scan on tbl_b b (cost=0.00..85.50 rows=1000 width=8)
Filter: (id < 1000)
(9 rows)
merge join的驱动表和被驱动表都需要先排序(plan中两表都有Sort)再匹配。优势在于表扫描次数、匹配次数比NL少,劣势在于需要排序。
因为索引是排序的,再加上sql本身可能带distinct、group by、sort、max/min等等排序需求,所以merge join也常见
2.2 Materialized Merge Join

testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id;
QUERY PLAN
-----------------------------------------------------------------------------------
Merge Join (cost=10466.08..10578.58 rows=5000 width=2064)
Merge Cond: (a.id = b.id)
-> Sort (cost=6708.39..6733.39 rows=10000 width=1032)
Sort Key: a.id
-> Seq Scan on tbl_a a (cost=0.00..1529.00 rows=10000 width=1032)
-> Materialize (cost=3757.69..3782.69 rows=5000 width=1032)
-> Sort (cost=3757.69..3770.19 rows=5000 width=1032)
Sort Key: b.id
-> Seq Scan on tbl_b b (cost=0.00..1193.00 rows=5000 width=1032)
(9 rows)
Materialize虽然没有减少扫描表的次数(两个表都只有一次),不过排序操作可以放到backend的work_mem中进行,这样排序效率更高;当然如果超过work_mem会放到磁盘排序。
2.3 merge join变体
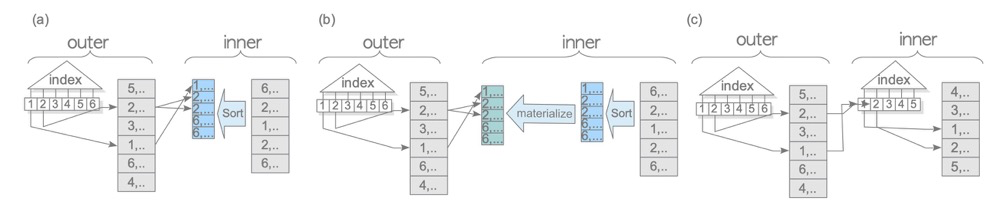
与NL变体类似,主要是Materialize和索引。用到索引的话,因为索引本身是有序的,所以就不需要额外的排序了。如下index scan不用排序也可以用到merge join
QUERY PLAN
--------------------------------------------------------------------------------------
Merge Join (cost=135.61..322.11 rows=1000 width=16)
Merge Cond: (c.id = b.id)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..318.29 rows=10000 width=8)
-> Sort (cost=135.33..137.83 rows=1000 width=8)
Sort Key: b.id
-> Seq Scan on tbl_b b (cost=0.00..85.50 rows=1000 width=8)
Filter: (id < 1000)
(7 rows)
所以索引和Materialize在merge join中是很常见的。
3.1 hash join
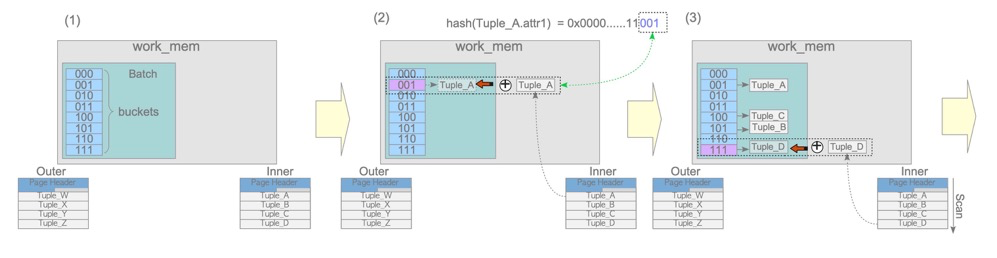
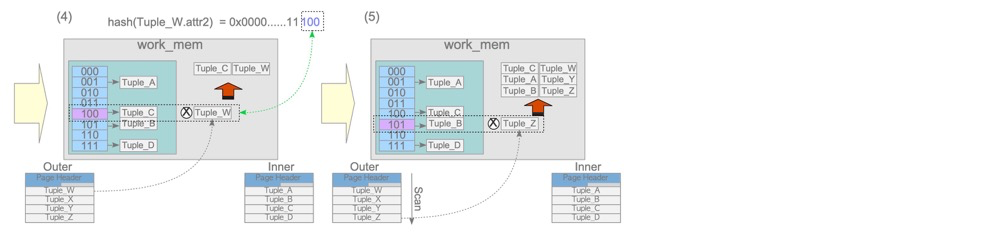
hash join分为build和probe阶段
build阶段将驱动表(上图的inner,plan中的第二行!)放到work_mem中,在probe阶段通过对比hash值
- hash join只有‘=’才有可能发生
- hash join占用内存,一般两张表都不会很大
- 注意驱动表(hash构建表)是plan中的第二行,跟NL相反
3.2 Hybrid Hash Join with Skew
没看太懂,看上去可以落盘,有时间来补
https://www.interdb.jp/pg/pgsql03/05/01.html
十六、各种索引的适用场景(HASH/GIN/BTREE/GIST/BLOOM/BRIN)
(1) BTREE
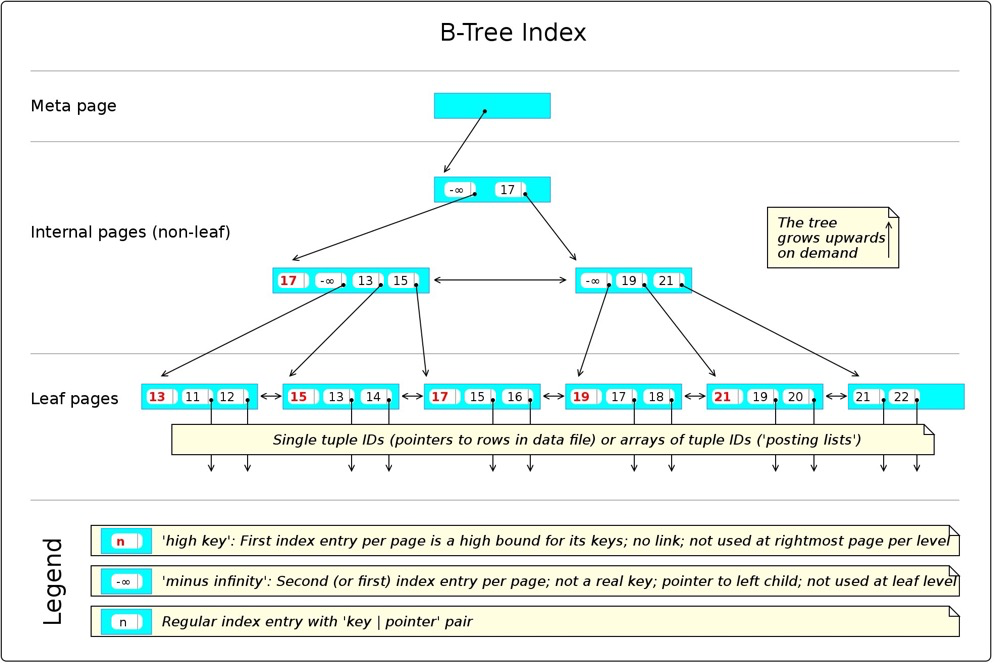
https://en.wikibooks.org/wiki/PostgreSQL/Index_Btree
可能被使用的方式:
< <= = >= > IS NULL IS NOT NULL LIKE 'foo%'
- 有个meta节点指向root节点
- 叶子节点访问复杂度 O(logN) ,N为行数
- 本身排序,容易被ORDER BY,min/max,group by,merge joins等等使用
- 默认索引类型,最为常见。在不同的数据库中结构都差不多,一般就是叶子节点结构有些区别(mysql二级索引叶子节点存储索引键和主键,再通过主键去访问聚簇索引;oracle索引叶子节点存储索引键和rowid;pg索引叶子节点存储索引键和tid)。
(2) HASH

(https://leopard.in.ua/2015/04/13/postgresql-indexes)
索引数据转化为32位的hash值,存放于对应的hash bucket中,不同的hash值指向各自的数据行。
- 复杂度 O(1)
- hash索引"只"能用于
=条件 - key value比较大的时候,一般都比BTREE索引更小,并且不需要像btree那样顺序对比每个字符大小,效率更高。所以hash索引更适合key value比较大的场景
(3) GIST
GIST-generalized search tree 与BTEE类似,也是一种平衡树。GIST索引其实不是一种索引,而是包含许多索引策略的框架,R-TREE,RD-TREE。不同于BTREE使用=,>等这类操作符处理数字、字符型数据,GIST更擅长处理地理、文本、图片等等数据,地理数据相关操作符有:<->计算距离,<<是否在左边,@>是否包含等等
GIST擅长的:
- GIS数据处理(类似的数据处理也可以,比如digoal-GIST索引提升IP范围查询效率)
- 邻近算法(pg_vector等向量数据涉及,空了研究~)
- full-text search(好像需要Contrib/intarray)
RTREE:
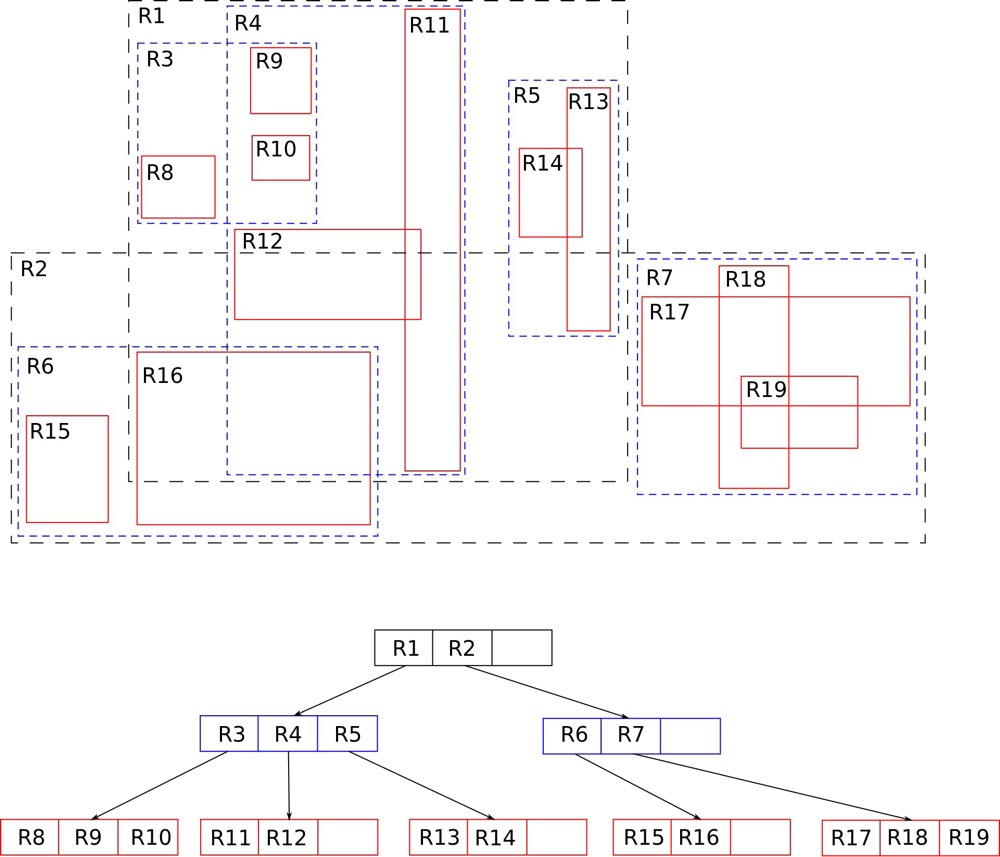
(https://en.wikipedia.org/wiki/R-tree)
GIS数据最常见的索引就是RTREE。二维空间数据是一个个坐标,一个个扫描坐标去寻找地址是比较慢的,BTREE不适合索引此类数据,而RTREE应运而生。RTREE的核心是在不同层级上把邻近的点通过长方形(rectangle)进行分组,分组越细定位越准。
https://postgrespro.com/blog/pgsql/4175817
(4)SP-GIST:
Space-Partitioned GIST与GIST类似,也是一个创建索引的框架。SP-GIST适合将空间划分为非交叉区域的结构(注意RTREE是交叉的),例如quadtrees, k-d trees, and radix trees
quadtrees:

(https://en.wikipedia.org/wiki/Quadtree)
Q-TREE有正方形、长方形、各种形,最“正”的Q-TREE如上。Q-tree一般有如下性质:
- 每个内部节点都有四个子节点
- 索引遵循深度结构来寻找数据
k-d trees:

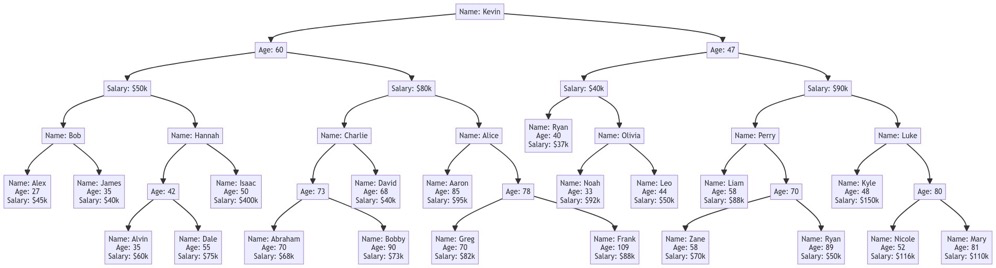
(https://en.wikipedia.org/wiki/K-d_tree)
k-dimensional tree以多维空间的概念来管理多维点,每个非叶节点都被一分为二。例如上面的立体空间图,是一个3维 k-d tree模型,第一次分割(红色)将整个空间一分为二,第二次分割(绿色)将子空间一分为二···直到不能分割。第二个图是3维 k-d tree的树形结构(不要把它看成是btree!),该树中只有3个维度:Name、Age、Salary
radix-tree:

(https://en.wikipedia.org/wiki/Radix_tree)
radix(基数),每个child都合成其parent。找到key的复杂度为O(路径长度),如果有common prefix,复杂度较高。
https://postgrespro.com/blog/pgsql/4220639
(5) GIN
BRTEE和GIST在有非常多键值数据的情况下,查询效率非常低。而GIN索引(Generalized Inverted Index)非常擅长此类场景:array、full text、json的检索操作。另外,GIST和GIN都是Generalized生成式的,支持多种数据索引,同时他俩也支持full text索引。GIN只支持Bitmap scans。
postgres原生支持许多操作符,其中有些是GIN索引相关的数据类型操作符:
PG支持两种数据类型以支持全文搜索:tsvector和tsquery
1.tsvector:
tsvector将text进行分词并去重和排序,并使用tsvector_ops的操作符。例如如下分词
SELECT 'The Fat Rat is a Rat'::tsvector;
tsvector
----------------------------
'Fat' 'Rat' 'The' 'a' 'is'
通过::tsvector分词一般不是分词的最终形态,to_tsvector函数用于分词的normalization(最终形态),它可以分词并展示分词的位置:
SELECT to_tsvector('english', 'The Fat Rat is a Rat');
to_tsvector
-------------------
'fat':2 'rat':3,6
注意’the’、‘is’、‘a’,大小写 都没有了,这是to_tsvector的规则,这种规则是符合真实场景的,因为全文搜索一般都是词汇
2.tsquery:
正常来说可以通过词汇来搜索tsvector分词过的text,如下
SELECT to_tsvector('The Fat Rat is a Rat') @@ 'rat';
?column?
----------
t
此时如果要搜索“既包含fat又包含rat”,简单的词汇输入是办不到的,tsquery就是操作用来搜索的分词的。
tsquery可以由 & (AND), | (OR), ! (NOT), <-> (FOLLOWED BY) 组成。示例:
SELECT to_tsvector('The Fat Rat is a Rat') @@ to_tsquery( 'fat&rat' );
?column?
----------
t
SELECT to_tsvector('The Fat Rat is a Rat') @@ to_tsquery( 'fat&rat&cat');
?column?
----------
f
SELECT to_tsvector('The Fat Rat is a Rat') @@ to_tsquery( 'rat<->fat');
?column?
----------
f
fulltext gin:
全文gin索引首先将索引字段分词(to_tsvector),类似如下doc_tsv就是将left分词后的状态:
ctid | left | doc_tsv
-------+----------------------+---------------------------------------------------------
(0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4
(0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7
(0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8
(1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1
(1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1
(1,3) | I am a sheet slitter | 'sheet':4 'slitter':5
(2,1) | I slit sheets. | 'sheet':3 'slit':2
(2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6
(2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2
然后通过分词和分词所在的ctid进行索引:
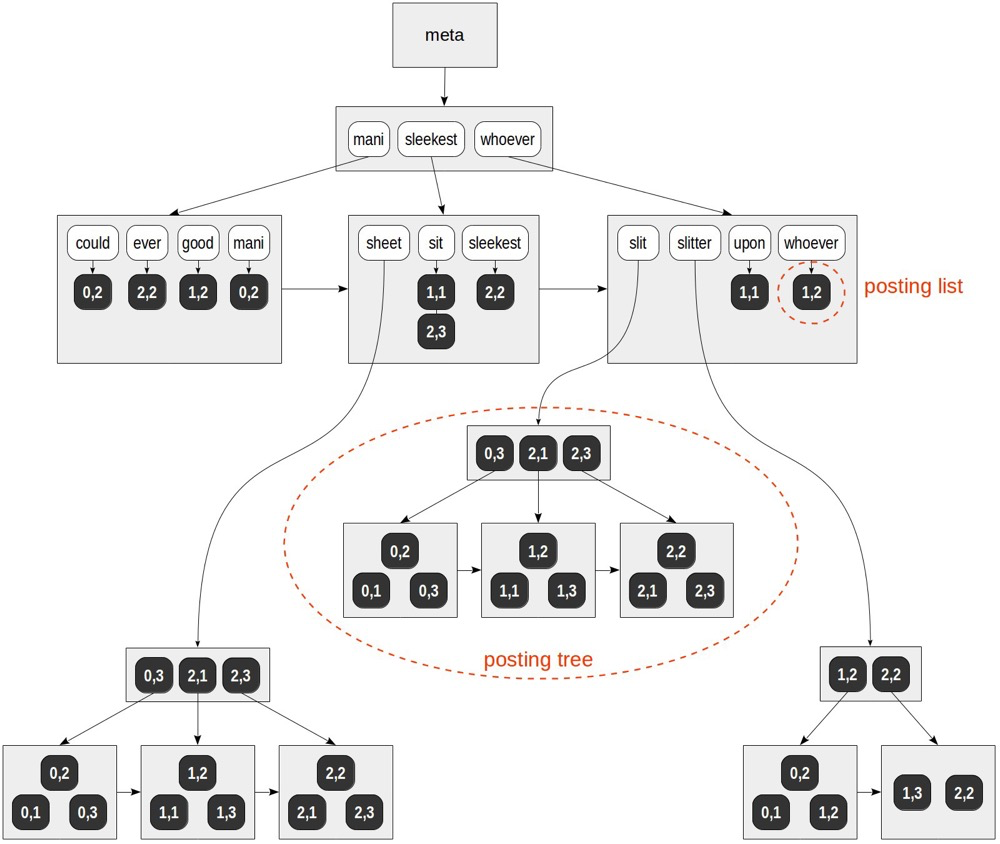
(https://postgrespro.com/blog/pgsql/4261647)
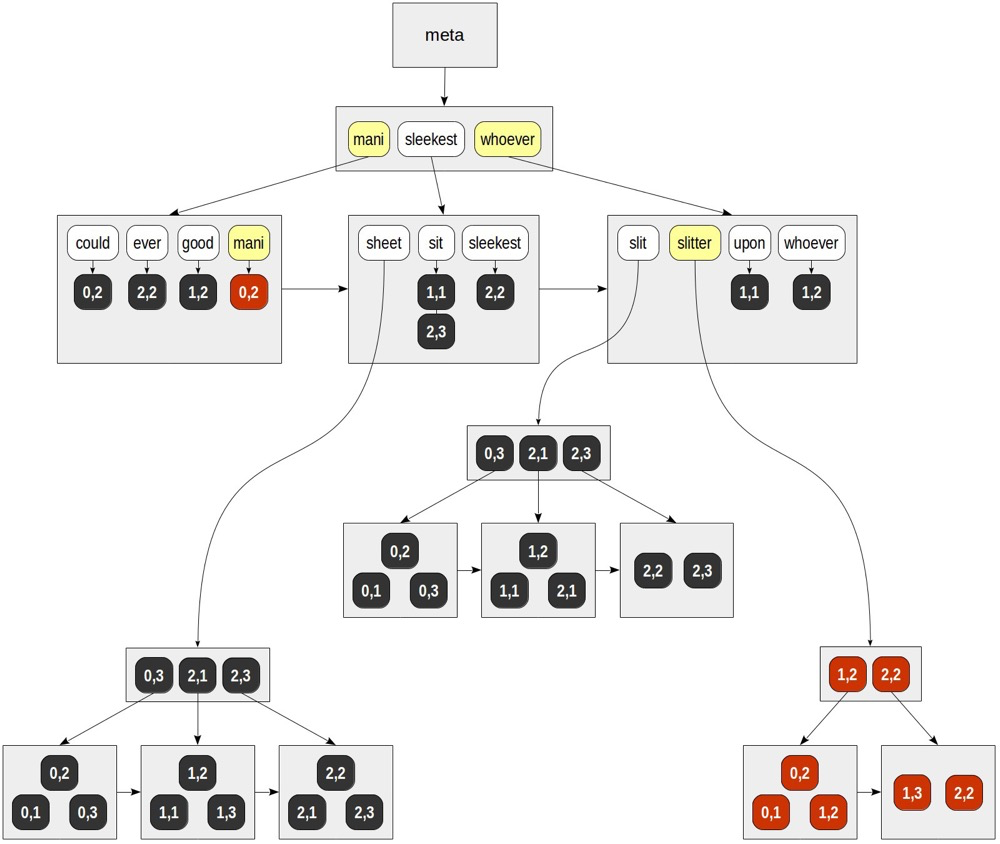
索引以分词的顺序排序,类似BTREE;在叶节点存储分词所指向的ctid,以为同一分词可以来自多个tuple,所以分词可以指向多个ctid,如果有多个ctid需要构建posting tree,类似于其下的ctids再构建btree。
fulltext gin寻址:
for “mani” — (0,2).
for “slitter” — (0,1), (0,2), (1,2), (1,3), (2,2).
GIN的更新:
如果需要更新(增删改)一条文本,一般需要更新GIN索引上的很多地方,因为
1)一条文本可以有很多分词,分散在GIN索引的各个branch上
2)一个分词下面可能包含多个ctid,因为许多文本都有这个分词
这就导致GIN的更新代价是非常大的。通常可以通过批量更新来执行,而不是一条一条的更新,因为有些分词是相同的,这样更新工作会少很多。
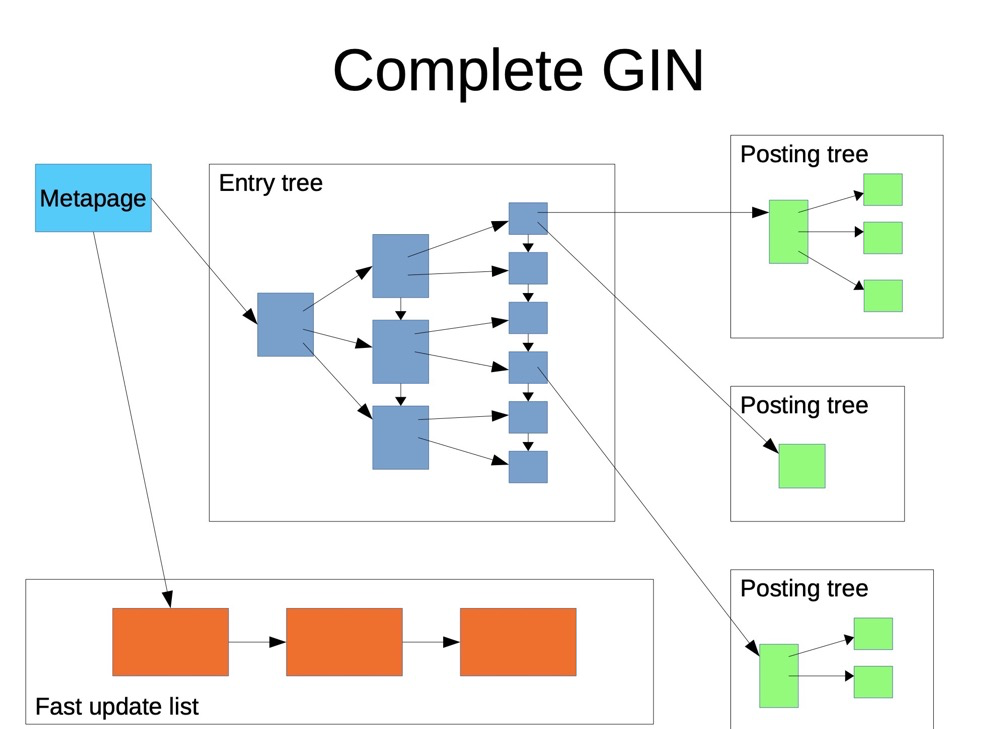
除了批量更新外,GIN还提供了快速更新功能(fastupdate = true):
(https://www.pgcon.org/2016/schedule/attachments/434_Index-internals-PGCon2016.pdf)
GIN的快速更新:
- 增量更新的数据会放到单独的地方,不排序
- 当有vacuum或list到达gin_pending_list_limit时,会将增量更新回写到GIN主索引上
GiST or GIN?
GiST和GIN都是生成式的,是索引框架,同时都支持全文索引,但是他们的全文索引结构完全不同。GIST适合处理地理数据、多维空间数据,,GIN主要是对键值包含多value的场景进行索引,如array、full text、json。
- GIN索引比GiST更快,一般而言全文索引可以盲选GIN( 参考 GIST vs GIN)
- 只有在非常多更新的情况下,可以考虑GiST索引。前提是fast update策略无法解决更新问题(如配置夜间回写策略),最好对GiST和GIN的全文索引的各种场景进行对比。
https://www.postgresql.org/docs/16/datatype-textsearch.html
https://postgrespro.com/blog/pgsql/4261647
(6) BRIN

(https://postgrespro.com/blog/pgsql/5967830)
BRIN不是tree类型的索引,数据以多个page(or Block)为一个range(类似range partition,但是不物理分区),表被分为一个个的range,就像这个索引的名字一样Block Range Index(BRIN)。
BRIN索引最关键的就是revmap层,revmap只存储键值的范围和ctid,而不存储键值本身。这也是为什么BRIN索引非常小的原因,存储键值的话就类似没有branch的BTREE索引了。
因为只存储键值的范围和ctid,这样导致在寻找数据的时候,需要访问命中的revmap页上所指向的所有数据页,最后再recheck出最终数据行。
QUERY PLAN
----------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (actual time=75.151..192.210 rows=587353 loops=1)
Recheck Cond: (airport_utc_offset = '08:00:00'::interval)
Rows Removed by Index Recheck: 191318
Heap Blocks: lossy=13380
-> Bitmap Index Scan on flights_bi_airport_utc_offset_idx
(actual time=74.999..74.999 rows=133800 loops=1)
Index Cond: (airport_utc_offset = '08:00:00'::interval)
索引键值的顺序和存储顺序是否一致是非常关键的。例如,一个额外的键值数据不是顺序存储的,它可能在“距离”较远的页上,此时必须多一个IO来访问远距离的数据页。最糟糕的情况,可能导致扫描整个表:

(https://www.pgcon.org/2016/schedule/attachments/434_Index-internals-PGCon2016.pdf)
BRIN适合的场景:
BRIN索引只适合索引键值与存储顺序高度一致的数据。可以直接查pg_stats中的列的correlation,应趋近于1(-1似乎也符合?),一般是递增主键和时间字段。
几乎没有更新的场景。更新可能导致correlation降低
BRIN索引一般适合极大的数据,特别是TB及以上的数据
https://postgrespro.com/blog/pgsql/5967830
(7) Rum
Rum是一个extension,没有原生包含在PG里。RUM和GIN索引是类似的,区别在于RUM多存储了tsvector的位置信息。
GIN虽然需要to_tsvector()(或者直接tsvector)来分词,但是GIN没有使用到to_tsvector()分词出来的位置信息。例如,如果要想找两个分词的距离,GIN索引是无法实现的,只能通过to_tsvector()分词出来的裸数据来判断。此时RUM就可以派上用场了。
RUM索引相对于GIN,在ctid旁边附带了分词的位置信息:
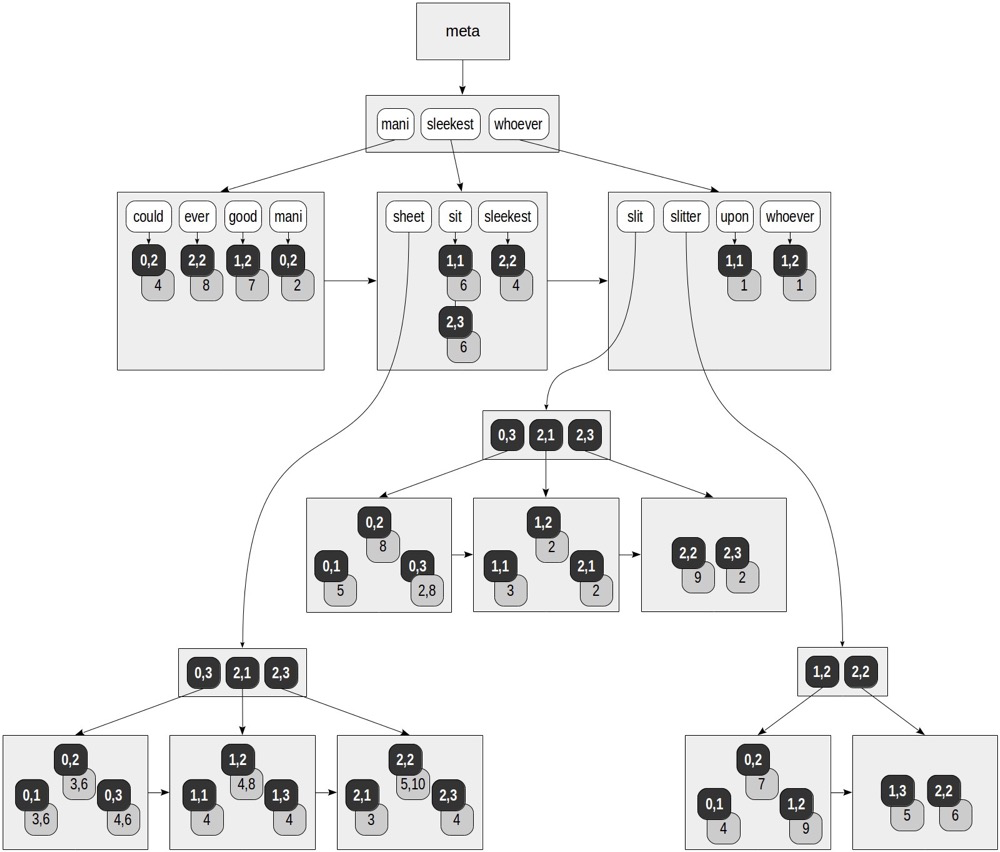
(https://postgrespro.com/blog/pgsql/4262305)
RUM与GIN类似适用于全文索引,额外的还有:
- 可以用距离操作符(如<=>)计算距离
- 可以通过位置来排序
https://postgrespro.com/blog/pgsql/4262305
(8)BLOOM
BLOOM过滤器可以快速确认一个元素是否在一个子集中。布隆过滤器可能出现假阳性,在子集中不一定是真的,不在子集中一定是真的。BLOOM索引也不是tree结果,跟BRIN类似也是平展的(与BRIN类似也要recheck)。
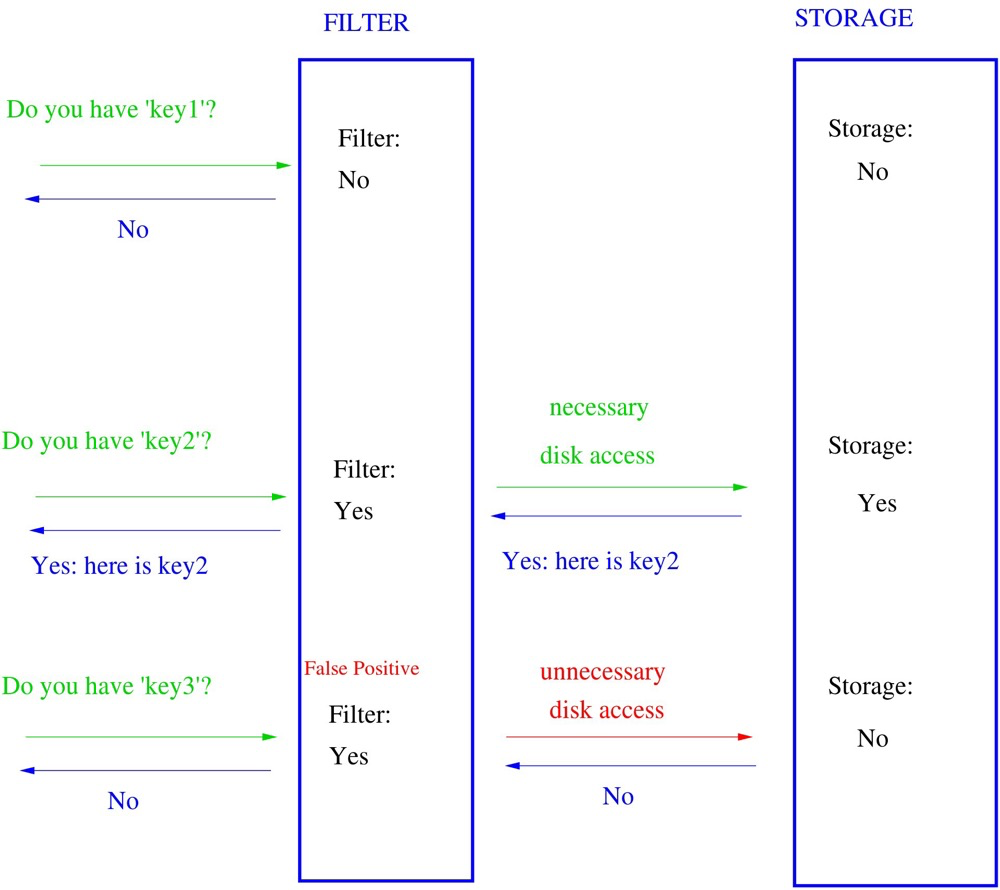
(https://en.wikipedia.org/wiki/Bloom_filter)
bloom索引可以索引很多列,bloom索引与hash索引有些类似,与hash索引不同的是它可以指定hash的字段并组合到一起,汇总后的长度受length限制。正因为它分段hash并截断的特性,所以存在假阳性。length越短,假阳性的可能性越大(length最大4096 bit)。
create index on ... using bloom(...) with (length=..., col1=..., col2=..., ...);

(https://postgrespro.com/blog/pgsql/5967832)
https://www.postgresql.org/docs/current/bloom.html
https://postgrespro.com/blog/pgsql/5967832
总结:
| index type | 结构 | 操作符 | 寻址复杂度 | 原生? | 有序? | 寻址是否准确 | 适用场景 | 优势 | 缺点 |
|---|---|---|---|---|---|---|---|---|---|
| btree | btree;branch存储键值范围,页节点存储键值和ctid,一般是升序 | >=,=,is null等常见操作符都支持,最左匹配原则 | O(logN) | 是 | 是 | 是 | 高选择率场景;不适合太大的数据; | 符合大部分场景;不需要额外排序 | 键值大时索引会非常大;索引碎片,分裂(HOT会减缓该现象) |
| hash | 构建hash桶,不同hash值指向不同的数据行 | 仅= | O(1) | 是 | 否 | 是 | 仅有=条件的场景;key value较大 | 一般比较小;寻址快 | 场景极少 |
| GiST | 索引框架;R-TREE,RD-TREE;在不同图层上对地址进行分组,分组越细定位越准 | 空间操作符:如<->计算距离,<<是否在左边,@>是否包含等等 |
图层高度 | 是 | 是(支持邻近算法) | 是 | GIS;KNN;频繁更新的全文索引 | GIS,多维度的数据 | 特殊场景 |
| sp-GiST/Q-tree | (sp-GiST是索引框架;索引不包含重叠数据) Q-tree:每个节点都有4个年内部节点; | 空间操作符:上下左右、等值、包含 | 图层高度 | 是 | 是 | 是 | GIS | GIS | GIS |
| sp-GiST/k-d tree | k-d tree:将多维空间在节点上一分为二,直到不能再分割; | 空间操作符 | 最低O(k),平均O(logN),最高O(N/2) | 是 | 是 | 是 | GIS;多维数据 | GIS,多维度的数据 | 特殊场景 |
| sp-GiST/radix-tree | 3.radix-tree:每个child都合成其parent; | 一般操作符;=,>,~等 | 最低O(1),最高O(N) | 是 | 是 | 是 | 没有common数据的场景 | 比一般的GiST支持一般操作符 | 场景少,可能会非常慢 |
| GIN | 索引框架;类似btree结构,branch存储分词范围,leaf存储分词和指向的ctid,一个分词指向多个ctid可能有子post tree结构;fast update打开的情况下多一个存储增量数据的链表空间 | 不同数据类型操作符稍有不同,一般有 @@含有 | 与文本长度、分词重复度相关,近似O(logN) | 是 | N(索引branch有序,但索引没有分词位置信息) | 是 | 键值包含多value的场景,如array;full text;json;很多列 | 键值包含多value的场景可能是最佳选择 | 更新需要合适的策略 |
| BRIN | 非tree结构,将数据页以range分开,rev索引层只键值存储范围和ctid | 一般操作符:< <= = >= > | 找到数据页的复杂度O(1),返回数据复杂度O(N),N为recheck的行数 | 是 | 不严格有序,但只适合有序 | 否 | 顺序存储(时序、自增列等);适合极大的表;几乎没有更新;适合一定范围内的查找 | 索引够小 | 极度要求corrlation |
| RUM | 与GIN类似,仅多存储分词位置信息 | 包含GIN的操作符,多一些位置操作符 | 与文本长度、分词重复度相关,近似O(logN) | 否 | 有(可用于邻近查找) | 是 | 键值包含多value的场景,适合KNN | 比GIN多存储位置信息 | 需要安装额外插件 |
| BLOOM | 每个字段hash并截断,非树形结构,以位图过滤 | 一般操作符:< <= = >= > | 未命中时O(1),命中时O(N),N为recheck的行数 | 是 | 否 | 否 | 适合未命中的场景 | 可能会非常快 | recheck时可能很慢 |
索引小节的其他参考:
Types of PostgreSQL Indexes. Short and clear
https://leopard.in.ua/2015/04/13/postgresql-indexes
https://pic.huodongjia.com/ganhuodocs/2017-07-15/1500104265.79.pdf
https://developer.aliyun.com/article/698090?spm=a2c6h.12873639.article-detail.43.702e7149IBMYL9
https://postgresql.us/events/pgopen2019/sessions/session/647/slides/45/look-it-up.pdf
https://www.pgcon.org/2016/schedule/attachments/434_Index-internals-PGCon2016.pdf
十七、行锁是如何实现的,行锁是否会存储在共享内存中
PG中的行锁在行的行头,不会在内存中实现。
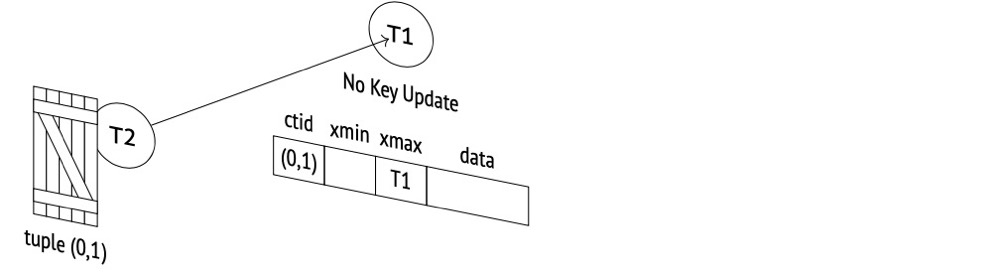
(1)t1更新后不提交,会获得relation和transactionid的排他锁:

(2)t2更新同一行会被阻塞,本次阻塞通过transactionid的sharelock锁实现,relation、tuple锁 T2都会获得:

(3)t3再更新这个行,本次阻塞通过tuple排他锁实现
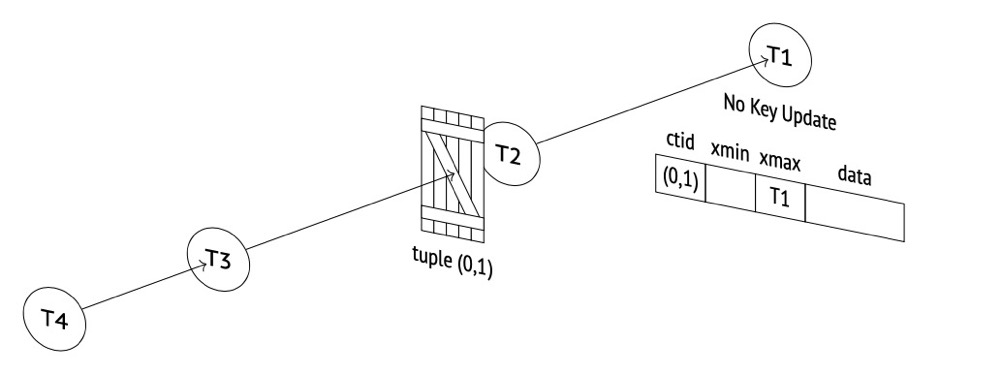
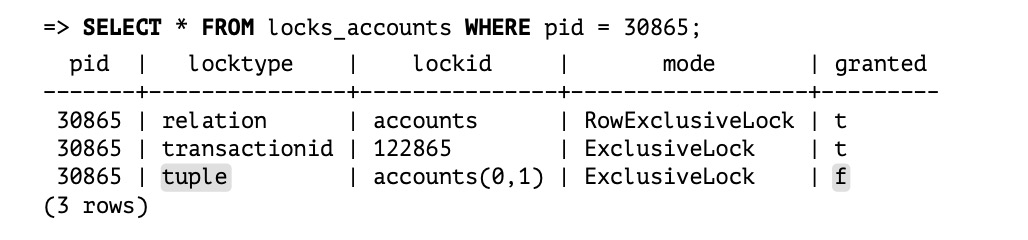
总之,PG的行锁通过transactionid锁、relation锁和tuple锁共同实现:

《postgresql-internals-14》
https://postgrespro.com/blog/pgsql/5968005
十八、流复制和逻辑复制的区别以及各自适用的场景
这里的流复制一般指的是PG的物理复制,通过全量的WAL日志同步到下游,由下游的PG库回放wal,是物理块级别的复制:

逻辑复制需要逻辑解析wal上相关表的事务信息,通过reorder buffer排序事务,然后由output plugin决定数据输出形式,下游不一定是PG库。必须有复制槽管理逻辑解析、output plugin、reorder buffer、复制点位等信息,还有replica identity、slot/sender状态信息等知识点:

逻辑复制本身存在很多问题,然而应用越来越广泛,是PG社区重点更新的功能之一。
例如(不完全统计)
- logical_decoding_work_mem不是写死的4096(条变更),成为GUI参数可调整。解析的落盘的问题得到一定缓解
- 在PG14后支持流式逻辑复制,事务没有提交也可以传递数据到下游,后续的事务提交信息决定是否应用该变更事务
- 从库支持复制槽,逻辑复制可建立在从库上
- failover slot(进行中?)
- 还有很多很多更新···
十九、流复制冲突是什么以及为什么会产生复制冲突
产生冲突的原因:
备库正在执行基于某个表的查询(这个查询可能是应用产生的,也可能是手动连接进行的查询),这时主库执行了drop table操作,该操作写入wal日志后传至备库进行应用,为了保证数据一致性,postgresql必然会迅速回放数据,这时drop table和select就会形成冲突。因为主库不知道从库的事务状态,而从库又需要与主库保持一致,所以才发生了“查询冲突”
产生冲突的场景:
1.主库排他锁(包括显示LOCK命令和各种DDL)
2.主库vacuum清理死元组,从库如果正在使用该元组,就会产生冲突
3.主库删除了从库查询正在使用的表空间
4.主库删除了从库正在使用的数据库
缓解查询冲突(无法彻底解决):
hot_standby_feedback:备库会定期向主库通知最小活跃事务id(xmin)值,这样使得主库vacuum进程不会清理大于xmin值的事务。
max_standby_streaming_delay:备库查询不会立即取消,而是等待一个时间后如果还没结束再抛出报错
max_standby_archive_delay:备机因为处理归档的wal日志产生查询冲突而取消查询之前的等待时间
vacuum_defer_cleanup_age:指定vacuum延迟清理死亡元组的事务数,即vacuum和vacuum full操作不会立即清理刚刚被删除元组
二十、简述 PostgreSQL 中的权限体系

不知道怎么汇总,汇总下来应该也记不住,属实有些复杂,简单几点如下:
- 权限访问需要每层都“打通”,缺一不可
- 最好将只读/读写/owner用户区分开
- 只读、读写权限可通过角色来管理
二十一、常见的高可用方案以及高可用选型及优缺点
高可用选型需要考虑的:
- 同步模式的选择、可用区和跨地域多活
- switch over、failover
- 负载均衡、读写分离
- 主机、数据库、业务层面的高可用
- VIP切换、连接串高可用、如何切换连接
- 如何解决单点故障或脑裂问题,如何选举
下面介绍一些网上能找到的架构:
pgpool-II+watchdog:
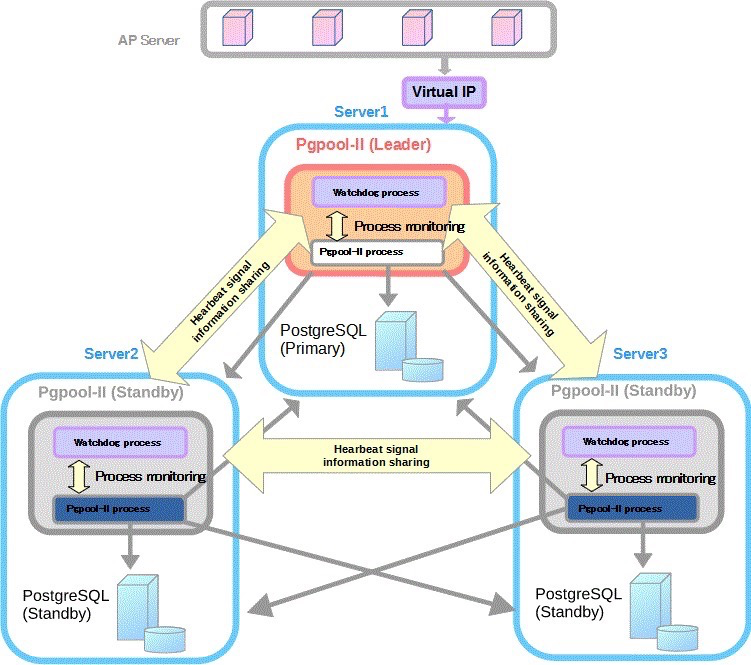
(https://www.pgpool.net/docs/latest/en/html/example-cluster.html)
优点:自动故障转移、读写分离、负载均衡、watchdog选举
缺点:配置复杂、pgpool不完全支持所有pg特性、pgpool有性能丢失问题、依赖watchdog选举
patroni+etcd:

优点:图形界面(patroni)、自动故障转移、多数派选举
缺点:学习成本、不支持其他数据库(patroni)
partroni+pgbouncer+haproxy+etcd:

(https://www.percona.com/sites/default/files/eBook-PostgreSQL-High-Availability.pdf)
优点:主打一个开源节流:haproxy用于负载均衡,pgcbouncer管理连接池、patroni管理集群、etcd用于选举
缺点:配置非常复杂
平安金融云rasesql架构:
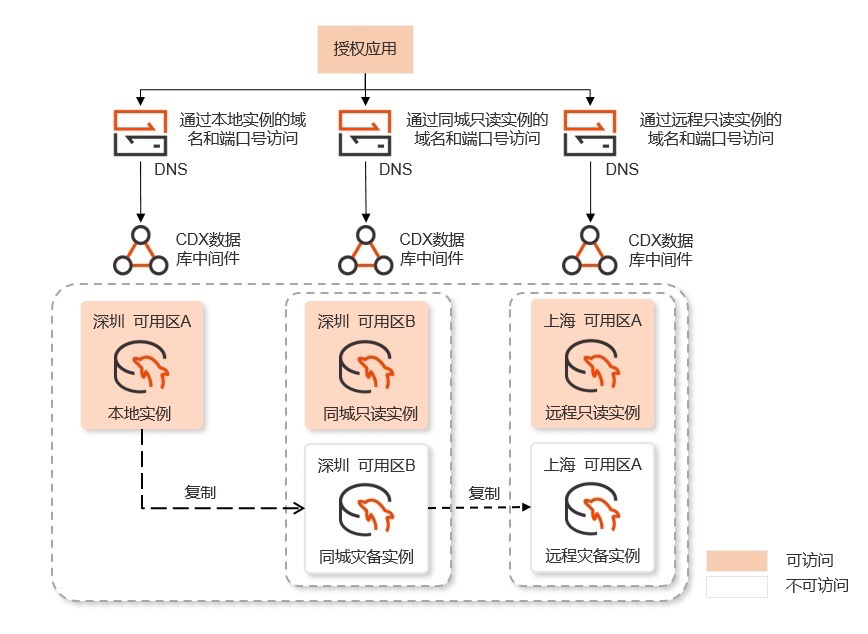
(https://www.ocftcloud.com/ssr/help/database/RASESQL/intro.Architecture)
优点:支持故障转移、架构简单
缺点:同城远程不可直接只读访问,资源占用较多,不可选举(?)
阿里云polar-x:
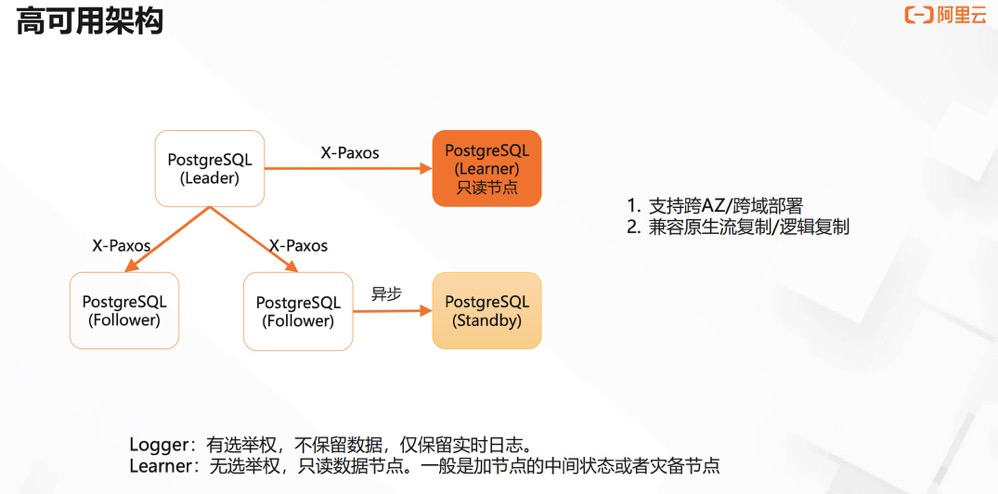
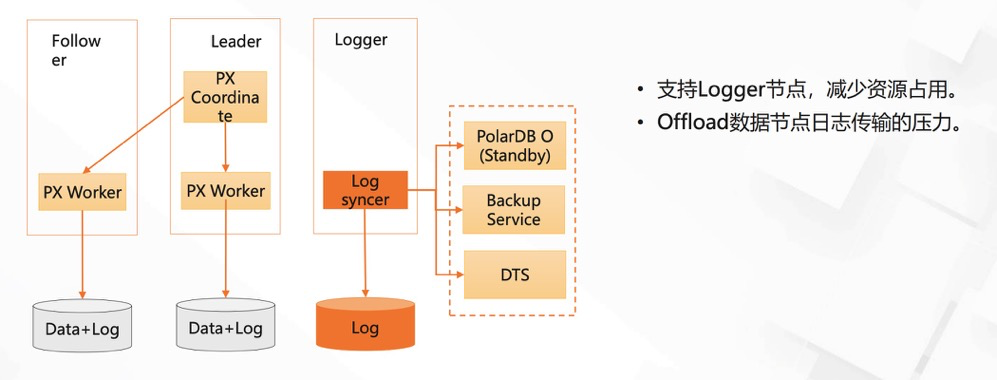
(PolarDB for PostgreSQL 三节点功能介绍)
优点:读写分离、可以加入不参加选举的节点、故障转移、logger节点参与选举/数据流/备份
缺点:…
google cloud pg:
有三种架构可以选择:

google云原生架构(MIG):

优点:三种方案可以选择、文档完善!(其他两个方案都源自开源架构,优缺点都差不多,下面介绍下MIG云原生方案)
MIG方案优势:不依赖PG原生的高可用方案,通过Regional persistent disk来实现数据高可用,主zone网络隔离,可把disk attach到同一region的zoneB上使用(1分钟内完成attach)。
MIG方案缺点:没有只读库、只能同region内故障转移(不支持搭建在多region上)
aurora for pg:
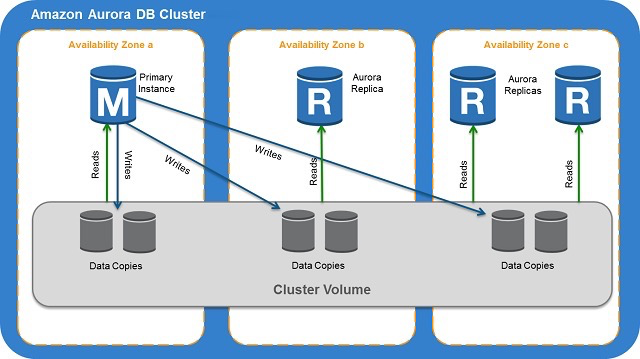
优点:架构简单,恢复后的主节点可自动加入集群,多region部署,standby可读
缺点:(似乎)没有选举动作,文档文字多图少
崔健:PostgreSQL的高可以架构设计与实践
https://www.pgpool.net/docs/latest/en/html/example-cluster.html
使用Patroni和HAProxy创建高度可用的PostgreSQL集群
https://www.percona.com/sites/default/files/eBook-PostgreSQL-High-Availability.pdf
PolarDB for PostgreSQL 三节点功能介绍
https://cloud.google.com/architecture/architectures-high-availability-postgresql-clusters-compute-engine
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.html
二十二、synchronous_commit 五种级别的区别,为什么备库的查询不能立马看到主库插入的数据

二十三、事务 ID 回卷的原因以及如何维护优化
为什么有事务ID回卷问题:
每个非查询事务都会消耗事务ID。查询事务消耗虚拟事务ID,虚拟事务ID是本地计数的,虽然有回卷问题,但是会话重启VXID重新计数,所以基本没有什么问题。
但是事务ID是有上限的,TransactionId是32位无符号整型,总共可以存储 2^32=4294967296,42亿多个事务,此时需要把事务ID回卷到初始状态,这就是为什么事务ID是一个环。
由于可见性原则,又需要把42亿事务分成两半,一半代表未来一半代表过去,PG实例中的最大最小事务之差不能超过21亿,这就是21亿事务的由来。

(https://www.interdb.jp/pg/pgsql05/01.html)
事务ID冻结:
由于可见性元组,例如一个可见的行(如下xid=100)与最新的事务之差超过了21亿,它会由可见变为不可见:
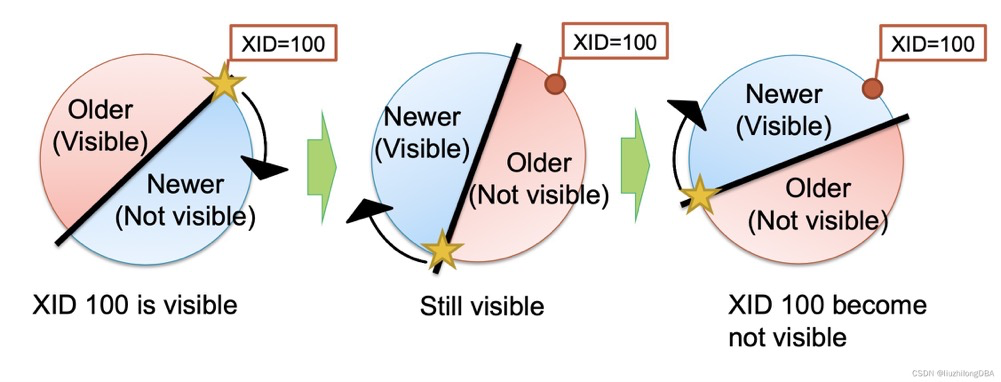
(忘了哪来的图了,自己找找)
为了解决这个问题引进事务ID冻结机制。事务ID冻结将过旧的元组的xmin设置为FrozenXID=2,比所有正常事务都旧。也就是说txid=2对于所有正常事务(txid>=3)都是可见的。在9.4及以后的版本,用t_infomask中的xmin_frozen来表示冻结元组,而不是重写t_xmin为2。
**惰性模式:**vm文件最初是为了减少vacuum的消耗,它可以让vacuum跳过完全没有死元组的页(all-visible )。后来(pg9.4)增强了freeze进程,让惰性模式冻结操作也可以在vacuum过程中跳过这些完全没有死元组的页(all-visible)。
惰性模式的冻结触发条件:随vacuum操作触发(似乎没有自己的触发条件???)
惰性模式冻结哪些元组:除开标记在vm中all-visible跳过的页,冻结那些元组的xmin和活跃事务ID(实际上是oldestxmin)的间隔超过vacuum_freeze_min_age(默认5kw)的元组,将其标记为xmin_frozen状态。如下图中tuple 9的xmin=3000不会冻结。
惰性模式更像是vacuum过程中附带的操作:反正都在concurrently vacuum扫描和清理死元组,pages已经扫描了,顺带把能frozen的元组frozen了。

**急性模式:**惰性模式有个问题,它随vacuum一起工作,会跳过vm中完全没有死元组的页(all-visible),如果一个页中的元组全是活元组(all-visible but not all-frozen )且xmin都很旧了,只靠惰性模式是冻结不到的。所以冻结需要急性模式:跳过vm中已经标记的all-frozen页并冻结。在真实场景中,一般急性模式才是经常周期运行的且需要关注的:哪怕表中只有一个页的元组都是insert插入(哪怕只有一个静态页),就需要急性模式。
急性模式的冻结触发条件:
1)针对vacuum操作的Vacuum_freeze_table_age:当database级的最小xmin(实际是pg_database.datfrozenxid字段,也是该database上所有pg_class.relfrozenxid的最小值)和活跃事务ID(实际上是oldestxmin)的间隔超过Vacuum_freeze_table_age时(默认1.5亿),vacuum会使用触发急性模式冻结。
2)针对autovacuum的autovacuum_freeze_max_age:无论是惰性模式还是急性模式的Vacuum_freeze_table_age,都需要先触发vacuum操作,仅靠vacuum本身触发条件去做冻结是不靠谱的,需要一个针对freeze的deadline参数:autovacuum_freeze_max_age。当元组年龄大于autovacuum_freeze_max_age时(2亿),强制触发autovacuum去冻结元组。哪怕autovacuum是关闭的,仍然可以触发这个deadline条件的冻结操作。
急性模式冻结哪些元组:与惰性模式类似,除了all-frozen页(惰性是all-visible,是有区别的),冻结那些元组的xmin和活跃事务ID(实际上是oldestxmin)的间隔超过vacuum_freeze_min_age(默认5kw)的元组,如下tuple 11没有被frozen

vacuum freeze命令:vacuum freeze命令等价于把vacuum_freeze_min_age和vacuum_freeze_table_age设置为0,并且以急切模式进行冻结操作,冻结所有非活动的xmin元组。
**vacuum_failsafe_age:**由于大表的vacuum操作非常慢,可能freeze操作还没跑完,事务ID已经回卷了。由于freeze是由vacuum进程做的,vacuum又有很多其他操作和参数设置,为了加速freeze,将cost-based vacuuming、buffer策略、index vacuuming都忽略。参数默认16亿,实际上vacuum过程中参数生效值不低于autovacuum_freeze_max_age*105%
**clog可能也更新:**额外的,冻结如果更新了pg_database.datfrozenxid ,还会清理不需要的clog。clog是记录事务状态的,以判断“比较新“的事务和元组可见性。如果一个database中的frozenxid都推进的比较新了,说明那些”老的”元组都被标记为了frozen——一直可见,所以clog中“老的”事务状态信息可以不要了
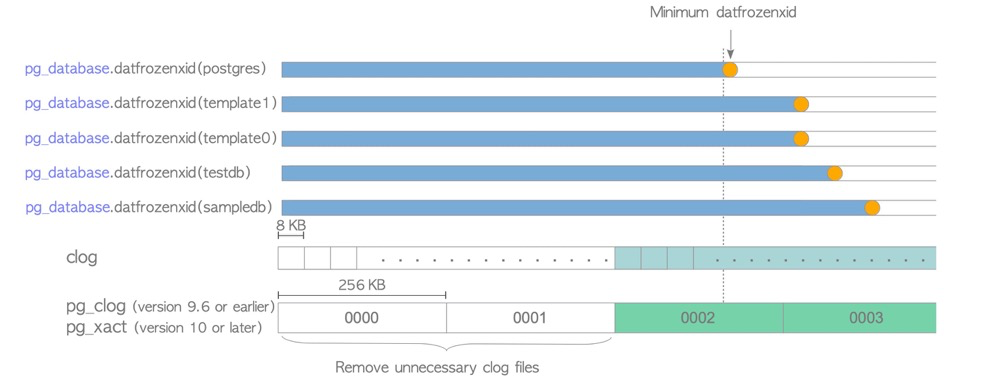
维护优化方案:(汇总自灿总的汇总)
- 生产环境中做好pg_database.frozenxid的监控,当快达到触发值时,我们应该选择一个业务低峰期窗口主动执行vacuum freeze操作,而不是等待数据库被动触发。
- 分区表,表过大会造成prevent wraparound操作时间较长
- 对大表设置不同的vacuum年龄,alter table test set (autovacuum_freeze_max_age=xxxx);
- 用户自己调度 freeze,如在业务低谷的时间窗口,对年龄较大,数据量较大的表进行vacuum freeze。
- 关注阻止freeze的场景:长事务、复制槽、hot_standby_feedback、pg_dump、游标、孤儿事情
- 设置足够的worker进程,以免需要vacuum的场景全部排队
- 如果关注负载问题,可以考虑开启cost-based vacuuming,让vacuum达到一定阈值时睡眠(vacuum_cost_delay等参数)
- autovacuum_freeze_max_age的值应大于vacuum_freeze_table_age,给手动vacuum留一定的空间,官方建议:vacuum_freeze_table_age = 0.95 * autovacuum_freeze_max_age;如果vacuum_freeze_table_age 低于0.95 * autovacuum_freeze_max_age,那么vacuum仍然取0.95 * autovacuum_freeze_max_age。
- vacuum_failsafe_age。pg14及以上设置合理的参数vacuum_failsafe_age,加速大表的freeze操作防止回卷,该参数应设置为大于autovacuum_freeze_max_age*105%
https://www.interdb.jp/pg/
https://www.postgresql.org/docs/16/routine-vacuuming.html#VACUUM-FOR-WRAPAROUND
二十四、vacuum / autovacuum 的作用以及如何调优
作用:
- 清除UPDATE或DELETE操作后留下的“死元祖”
- 跟踪表块中可用空间,更新free space map
- 更新index-only扫描所需的visibility map
- “冻结”表中的行,防止事务ID回卷
- 定期ANALYZE,更新统计信息
调优:
- 设置足够的worker进程,以免需要vacuum的场景排队
- 可增大maintenace_work_mem(或autovacuum_work_mem)的值
- 关注阻止vacuum的场景:长事务、复制槽、hot_standby_feedback、pg_dump、游标、孤儿事情
- 对于特殊表(业务敏感表和大表)可单独设置autovacuum触发阈值(threshold、fillfactor;insert threshold、fillfactor):死元组回收阈值、统计信息更新阈值、防止回卷阈值
- 对于特殊表(业务敏感表和大表)关闭表级的autovacuum,在业务低峰期运行vacuum,包括死元组回收、统计信息、回卷动作
- 如果需要关注业务负载压力,可开启cost-based vacuuming,让vacuum达到某阈值时睡眠
- 分区表,避免vacuum长时间运行不完,甚至刚运行完又立即vacuum
- 尽量避免vacuum full 8级锁操作。用户逻辑复制+rename或者pg_repack处理表膨胀和索引膨胀,增加表/索引的执行效率并回收空间
二十五、函数三态以及函数为什么需要有 execute
volatile函数(不稳定,默认):
- 可以做任何事,包括修改数据库。
- 在同一个事务中,即使是相同的参数,返回的结果也会不同。
- 在函数内的每个query执行时获取一次snapshot,因此即便在同一函数中相同interactive query多次执行,每次的可见数据不同执行结果也会不同。
- 由于每次要重新计算,优化器无法提前预估,其性能可能较差
- 不支持创建函数索引
- 典型函数:timeofday()、random()、所有修改类函数
stable函数(稳定):
- 不可以修改数据库
- 在同一个事务中,对于相同的参数,返回的结果相同。在函数开始执行时获取snapshot,内部的每个query不再重复获取,函数内的相同的interactive query执行结果是一致的。
- 不支持创建函数索引
- 典型函数:current_timestamp家族函数,在一个事务中无论调用多少次只会有一个值
immutable函数(非常稳定):
- 不可以修改数据库
- 只要给定相同参数,永远返回相同的结果。快照获取原理与stable函数一致。
- 与stable函数的重要区别是:immutable不仅缓存plan,在后续的执行时直接使用这个plan
- 支持创建函数索引
- 一些基于数据库参数的函数是不应该指定为immutable的,比如timezone相关函数,是stable函数
- 典型函数:计算1+2
函数为什么需要有execute:
PREPARE: parsed, analyzed, and rewritten
EXECUTE: planned and executed
强制SQL进行硬解析:避免SQL因为数据倾斜使用错误的执行计划。
与普通SQL不同,plpgsql中默认使用Plan Caching,会自动将SQL以prepare方式执行,尝试生成和缓存generic plan 进行软解析。但是,如果有数据倾斜问题,缓存的执行计划可能是低效的,对部分核心业务来说是不可接受的。此时可以考虑使用execute语句,强制根据每个变量值生成对应执行计划,提高准确度。
https://blog.csdn.net/Hehuyi_In/article/details/128885660
https://www.postgresql.org/docs/16/xfunc-volatility.html
二十六、为什么要使用 create index concurrently 以及 CIC 的危害
why CIC:
create index需要sharelock锁,与dml的RowExclusiveLock是冲突的,所以在线业务不应该直接使用create index。CIC使用ShareuUpdateExclusiveLock与DML锁不冲突,所以推荐使用CIC方式创建索引。
CIC的流程:
1.在系统表中插入索引的元数据,包括pg_class、pg_index,然后开启两个事务,进行两次扫描
2.开启事务1,拿到当前snapshot1。
3.扫描test1表前,等待所有修改过test1表(写入、删除、更新)的事务结束。
4.扫描test1表,并建立索引。
5.结束事务1。
6.开启事务2,拿到当前snapshot2。
7.再次扫描test1表前,等待所有修改过B表(写入、删除、更新)的事务结束。
8.在snapshot2之后启动的事务对test1表执行的DML,会修改这个myidx的索引。
9.再次扫描B表,更新索引。(从TUPLE中可以拿到版本号,在snapshot1到snapshot2之间变更的记录,将其合并到索引)
10.上一步更新索引结束后,等待事务2之前开启的持有snapshot的事务结束。
11.结束索引创建。索引可见。
CIC的问题:
1.先后开启两个事务,比create index多扫描一次表
2.必须等待长事务结束才能开始扫描
3.CIC创建的索引可能会失效
CIC异常中断会留下失效索引
CIC创建唯一索引过程中,插入/更新的数据违反唯一约束,也会导致CIC失败留下失效索引
4.失效索引仍然会因为DML的更新而更新
5.分区主表不支持CIC创建索引,可在子表上以CIC一个个创建完成后,再在主表上以only方式创建索引
二十七、HOT 原理
HOT:
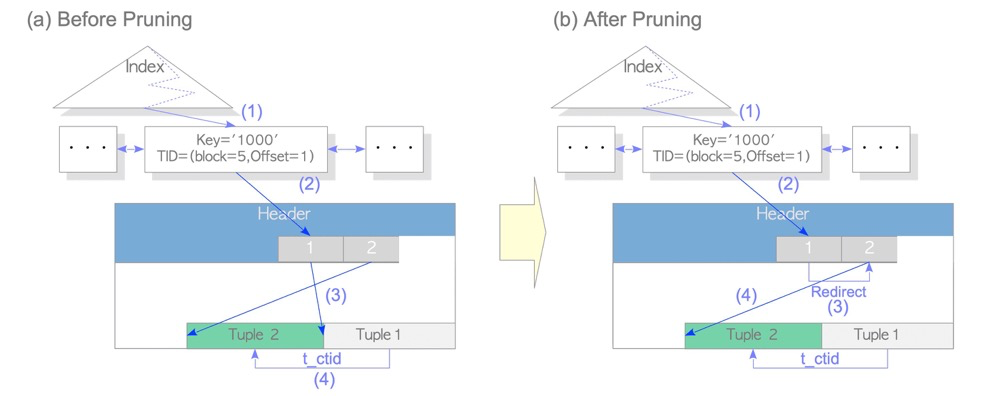
如果没有HOT,每次更新元组都会更新索引,如下新增更新一个元组,会增加一个索引条目,并且老的索引条目指向死元组。这会导致索引更新、索引空间、索引vacuum的压力。
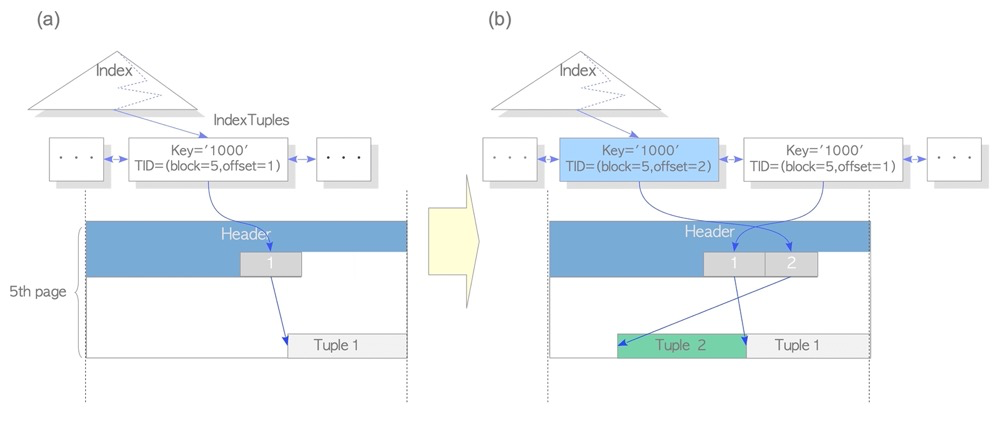
有HOT的情况下,页内的更新只会更新元组,不会更新索引:
HOT元组在infomask中对应HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE位:
lzldb=> create table tt(a int);
lzldb=> create index idxtt on tt(a);
lzldb=> insert into tt values(1);
lzldb=> update tt set a=1; --多次执行
lzldb=> select * from tt; --更新完后执行一次可见性检查,让剩余的一点clog事务提交信息更新到tuple header
lzldb=> SELECT lp,case lp_flags when 0 then '0:LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,
t_ctid, raw_flags, combined_flags
FROM heap_page_items(get_raw_page('tt', 0)),
LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2)
WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL;
lp | lp_flags | t_ctid | raw_flags | combined_flags
----+-----------+--------+-----------------------------------------------------------------------------------------+----------------
1 | LP_NORMAL | (0,2) | {HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED,HEAP_HOT_UPDATED} | {}
2 | LP_NORMAL | (0,3) | {HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
3 | LP_NORMAL | (0,4) | {HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
4 | LP_NORMAL | (0,5) | {HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
5 | LP_NORMAL | (0,5) | {HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
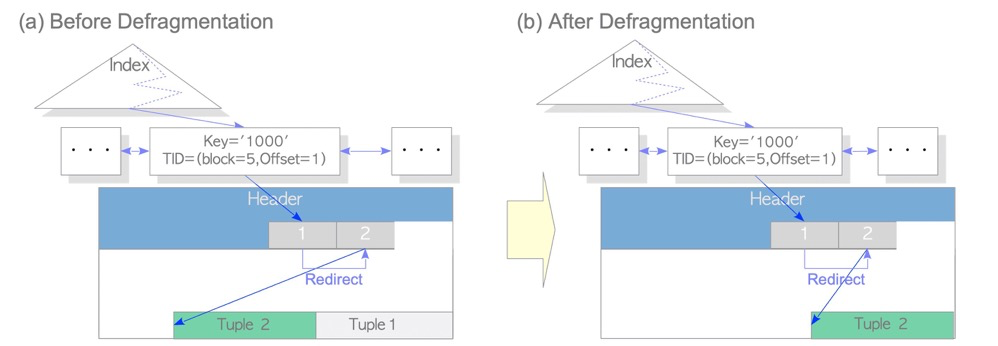
lp(line pointer)=1的元组,通过ctid(0,2)指向第二行,第二行又指向第三行···最终指向第五行。ctid是一个链条可指向最后的那个数据行。死元组上都有HEAP_HOT_UPDATED信息,表示该元组是HOT链上已被updated的行;链最后有HEAP_ONLY_TUPLE标识,表示这是HOT链尾端的元组。
有了HOT,vacuum时,只清理页内的死元组,不需要更新索引
lzldb=> vacuum tt;
VACUUM
lzldb=> SELECT lp,case lp_flags when 0 then '0:LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,
t_ctid, raw_flags, combined_flags
FROM heap_page_items(get_raw_page('tt', 0)),
LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2)
WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL;
lp | lp_flags | t_ctid | raw_flags | combined_flags
----+-----------+--------+----------------------------------------------------------------------+----------------
5 | LP_NORMAL | (0,5) | {HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
vacuum后死元组被清理
再更新的话,又开始新的HOT链:
lzldb=> update tt set a=1;
lzldb=> update tt set a=1;
lzldb=> select * from tt;
lzldb=> SELECT lp,case lp_flags when 0 then '0:LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,
t_ctid, raw_flags, combined_flags
FROM heap_page_items(get_raw_page('tt', 0)),
LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2)
WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL;
lp | lp_flags | t_ctid | raw_flags | combined_flags
----+-----------+--------+-----------------------------------------------------------------------------------------+----------------
2 | LP_NORMAL | (0,3) | {HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
3 | LP_NORMAL | (0,3) | {HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
5 | LP_NORMAL | (0,2) | {HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
新的HOT链没有从lp1开始,为什么呢?因为lp1已经被占用了,索引还指向着lp1
lzldb=> SELECT itemoffset, ctid, data, dead, htid, tids[0:2] AS some_tids
FROM bt_page_items('idxtt',1);
itemoffset | ctid | data | dead | htid | some_tids
------------+-------+-------------------------+------+-------+-----------
1 | (0,1) | 01 00 00 00 00 00 00 00 | f | (0,1) |
htid (0,1) 就是page 0,lp 1。vacuum只清理了数据page,索引没有被更新,vacuum只清理了死元组合和HOT链中间的部分,ctid HOT链头尾没有动。
INDEX ONLY SCAN:
索引唯一扫描是各种数据中常见的、高效的索引扫描方式,它表示不需要访问数据页,只访问索引页就可以返回结果。但是这在PG中存在问题,因为可见性信息存储在数据页header中,索引页没有可见性信息,只访问索引原则上支持不了MVCC。
VM文件不仅可以支持vacuum跳过表all-visible的页,还可以支持INDEX ONLY SCAN判断表all-visible的页上的tuple可见性原则:

参考:interdb
二十八、PostgreSQL中是否有锁升级
基本没有。
只有Predicate lock有escalation,Predicate lock在需要做可串行化的时候才会使用,本意是锁谓词,防止数据异常现象从而实现可串行化,PG库中对应SIReadLock。
- Predicate lock最细的粒度是锁某个范围内的行
- 当行数超过一定阈值时,锁行对应的page
- 当page超过一定阈值时,锁对应的表
- Predicate lock只有3种级别的锁:行、page、表
https://postgrespro.com/blog/pgsql/5968020
二十九、复制槽的作用以及复制槽的危害
对于物理复制,可以不需要复制槽,通过hot_standby_feedback和一些参数来管理wal。有复制槽后其实不需要这些参数,通过复制槽可以管理wal日志
对于逻辑复制,必须有复制槽,相当于一个逻辑复制链路对应一个复制槽。对于逻辑复制来说,复制槽不仅管理wal日志,还负责管理逻辑解析、output plugin、解析/发送日志的位点(lsn),在复制中断后可以重传解析日志。

复制槽的危害:
其实复制槽没有什么危害,它本身的一大功能就是简化wal日志管理的,没有复制槽仍然要制定策略管理wal日志,pg社区也推荐使用复制槽。只是需要注意,对于不需要的复制槽一定要清理,以免复制槽存储过久的位点阻止wal日志清理把磁盘打满。额外的,还要注意,DBA不要随意清理复制槽,一旦清理位点信息也没有了,下游链路可能要重新初始化数据和同步,最好是确认复制链路是否可以再次启动同步。
三十、为什么会有死锁以及死锁检测机制

最简单的,事务T1持有资源1,事务T2持有资源2,如果t1尝试获得资源2,t2尝试获得资源1,此时就形成死锁。死锁如果没有管理机制可以无限期等待,所以所有DBMS都有死锁检测机制。死锁一般都以为着业务逻辑问题,如果不显示取消“环”中的某个事务来打破“环”,PG会自行检测死锁,并通过deadlock_timeout(默认1s)参数来强制结束一个事务,“环”中的其他事务可以继续执行。
https://postgrespro.com/blog/pgsql/5968020
三十一、SQL 慢能从哪些方面入手排查

三十二、为什么需要使用分区表以及分区表的优势和劣势
分区表将表数据分成更小的物理分片,以此提高性能、可用性、易管理性,并且对业务透明。分区表是关系型数据库中比较常见的对大表的优化方式,数据库管理系统一般都提供了分区管理,而业务可以直接访问分区表而不需要调整业务架构,当然好的性能需要合理的分区访问方式。
PG原生支持声明式分区表、继承分区表,常用插件实现的分区表有pathman。PG10开始支持声明式分区表,并在后续版本中有较多加强(详见PostgreSQL分区表-分区表的历史),建议PG12及以后使用声明式分区表。
分区表的优势:
SQL性能提升。在某些场景下,比如把大量的数据分成多个分区,而SQL只需要查那一个分区的数据时发生分区裁剪,SQL性能可能会极大的提升
分区可以和索引配合使用。比如访问一个分区上的一个索引要比访问一个未分区的大索引要更高效。
删除一个分区比删除多行数据更高效。这在时间范围分区中很常见,删除一个用不到的历史分区是非常快的,但是如果没有分区,delete删除数据不仅慢还需要额外的维护操作
vacuum更快。一个大表在回收旧版本信息或收集统计信息时会非常慢,在vacuum还没执行完的时候可能SQL已经存在问题了。如果有分区的话,vacuum会快很多。
IO分散能力。不同的分区可以放在不同的路径、不同的磁盘上。极少使用数据可以放在便宜的磁盘上。
更多的维护技巧。直接维护一个大表是非常困难的,比如一个极大的表做vacuum时就有很多问题,而分区表的各个分区可以单独运行vacuum。不仅如此,attach/detach、本地索引/约束等可以在很多场景中灵活使用。
可能使用到partition wise join或者partition wise aggregation特性
分区表的劣势:
PG中分区表也是表,表过多导致解析慢合relcache缓存表元数据过大
表过多可能报错。参考之前的文章较少的分区也报错too many range table entries
即使分区过多没有报错,且在生成执行计划的时候没有做分区剪裁(执行的时候有可能做),那么explain出来的执行计划会非常多,此时日志中也会打印长长的执行计划影响日志阅读。
一些奇怪的问题:不同用户查看到不同的执行计划
PG原生分区表的几个较大的限制:
- 没有原生的自动创建分区功能
- 只支持分区索引,不支持全局索引
- 主键必须包含分区键。postgresql目前只能在各自的分区内判断唯一性,所以有这个限制。oracle和mysql都没有这种限制。
- 唯一索引必须包含分区键。同理主键
- 无法创建定义在全局的约束(约束子表会继承但是不能创建全局约束)
分区表的维护:
新分区没有数据,可以直接使用partition of(8级锁,只需注意长事务问题)添加分区表
新分区有数据,应使用attach(4级锁,不阻塞读写)方式添加分区(如有必要可以先添加新分区的分区约束,减少约束检查时间),detach concurrently(4级锁)删除分区
注意attach不会像partition of那样自动创建索引、约束、默认值、行级触发器,需提前建好
分区主表索引不支持CIC,创建分区索引的正确姿势:1主表only创建 2分区concurrently创建 3 attach所有分区索引到主索引上索引自动标记为有效。
字段长度增加不会重建索引,一个例外情况是分区表字段长度增加会重建索引
三十三、软硬解析的概念
硬解析:对于一个SQL语句,优化器首先需要进行词法分析、语法分析,将其转换为pg能识别的查询树,再对其解析重写和优化,生成执行计划树,执行器才能知道如何执行该语句,这种完整的解析叫做硬解析。
软解析: 显然,如果每个语句每次都执行如此复杂的步骤,效率会很低,因此pg会将SQL解析出来的执行计划缓存在进程内存中,符合一定条件时可以直接使用,提高效率,这种解析叫做软解析。
PG绑定变量SQL解析的五次机制:
五次机制是为了防止数据倾斜,导致使用低效的执行计划。
前5次执行的SQL:都根据实际传入变量生成执行计划(叫做custom plan),属于硬解析。
第6次执行的SQL:生成一个通用的执行计划(generic plan),并与前5次执行计划比较。
- 如果不差于前5次:固定第6次的执行计划,后续即使参数再发生变化,该SQL的执行计划也不会再变,属于软解析
- 如果差于前5次中任何一个执行计划,以后每次都重新生成执行计划,即都是硬解析。
强制使用软/硬解析
PG 12 中引入了 force_custom_plan 参数,有以下可选值:
- auto:默认,即按照五次机制处理
- force_custom_plan:永远进行硬解析,适用于有数据倾斜且性能和稳定性要求高的SQL
- force_generic_plan:永远使用generic plan,适用于没有数据倾斜或者性能和稳定性要求不高的SQL
两种计划的使用次数
PG 14 在pg_prepared_statements视图中新增了generic_plans和custom_plans两列,可以看到两种计划的次数。由于pg的执行计划只是缓存在进程中,pg_prepared_statements视图只能看到本会话的SQL情况,看不到其他会话和全局信息。
五次机制的源码:
/*
* choose_custom_plan: choose whether to use custom or generic plan
*
* This defines the policy followed by GetCachedPlan.
*/
static bool
choose_custom_plan(CachedPlanSource *plansource, ParamListInfo boundParams)
{
double avg_custom_cost;
...
/* Let settings force the decision */
if (plan_cache_mode == PLAN_CACHE_MODE_FORCE_GENERIC_PLAN)
return false;
if (plan_cache_mode == PLAN_CACHE_MODE_FORCE_CUSTOM_PLAN)
return true;
/* See if caller wants to force the decision */
if (plansource->cursor_options & CURSOR_OPT_GENERIC_PLAN)
return false;
if (plansource->cursor_options & CURSOR_OPT_CUSTOM_PLAN)
return true;
/* Generate custom plans until we have done at least 5 (arbitrary) */
if (plansource->num_custom_plans < 5)
return true;
avg_custom_cost = plansource->total_custom_cost / plansource->num_custom_plans;
/*
* Prefer generic plan if it's less expensive than the average custom
* plan. (Because we include a charge for cost of planning in the
* custom-plan costs, this means the generic plan only has to be less
* expensive than the execution cost plus replan cost of the custom
* plans.)
*
* Note that if generic_cost is -1 (indicating we've not yet determined
* the generic plan cost), we'll always prefer generic at this point.
*/
if (plansource->generic_cost < avg_custom_cost)
return false;
return true;
}
三十四、vm / fsm / init 文件是什么
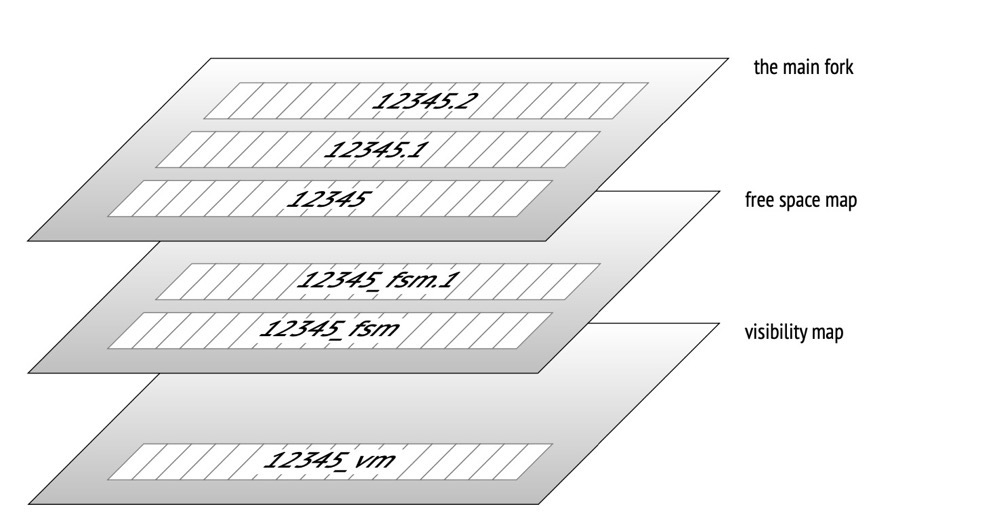
**数字后缀:**文件每超过1G(默认)fork一个文件,通过./configure --with-segsize在build时更改大小
vm: 页可见性文件,包含all-visible和all-frozen信息,可帮助 1)加速vacuum扫描,vacuum可跳过all-visible的页 2)加速eager freeze过程,eager freeze可跳过all-frozen页 3)支持INDEX ONLY SCAN,标记all-visible页可不用访问页本身就可以判断元组可见性
**fsm:**可用空间映射文件,帮助PG定位页上的可用空间;对于索引页,由于索引是有序的,记录每个索引页的可用空间意义不大,索引的fsm文件只包含全空索引页
init:unlogged table才有的fork文件,大小为0,相当于标记这个数据文件是unlogged的
《postgresql-internals-14》
三十五、内存回收机制:kswapd/direct memory reclaim/pdflush
内存回收机制:
后台内存回收(kswapd):在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
直接内存回收(direct reclaim):如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。

(https://vivani.net/2022/06/14/linux-kernel-tuning-page-allocation-failure/)
pages_low: 当可用的空闲页面数量低于pages_low 时,buddy allocator会唤醒kswapd进程,内核开始将页换出到硬盘。
**pages_min: **当可用页面数量达到 pages_min时,说明页回收工作的压力就比较大,因为内存域中急需空闲页。分配器将以同步的方式执行 kswapd 工作,有时也称为直接内存回收(direct reclaim)。
pages_high: 一旦 kswapd 被唤醒开始释放页面,只有在可用页面数量达到pages_high时,内核才认为该区域是“平衡的”。如果水位线达到pages_high,kswapd 将重新进入休眠状态。空闲页多于pages_high,则内核认为zone的状态是理想的。
内存回收以zone为单位进行,/proc/zoneinfo可以查看min、low、high的值。
vm.min_free_kbytes也就是min_pages线,十分重要的操作系统参数。非常低的值会阻止系统有效地回收内存,这可能会导致系统崩溃并中断服务。太高的值会增加系统回收活动,造成分配延迟,这可能导致系统立即进入内存不足状态。
pdflush和kcompactd:
pdflush:pagecache中的脏页需要写入到磁盘,无论是sync(fsync等)还是操作系统调度刷脏还是数据库commit,最终都要调用到linux底层的内核线程pdflush进行刷脏工作。
kcompactd:page compation是专门针对内存碎片整理的(刷脏也可以,因为内存会回收给buddy系统),与pdflush刷脏不一样,内存压缩不需要写盘
观察内存回收:
sar是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘 I/O、CPU 效率、内存使用状况、进程活动及 IPC 有关的活动等

sar -B可观察到kswapd内存回收和直接内存回收:
示例:sar查看内存页的状态
sar -B 1 3
- pgpgin/s:表示每秒从磁盘或SWAP置换到内存的字节数(KB)
- pgpgout/s:表示每秒从内存置换到磁盘或SWAP的字节数(KB)
- fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和(major + minor)
- majflt/s:每秒钟产生的主缺页数
- pgfree/s:每秒被放入空闲队列中的页个数
- pgscank/s:每秒被 kswapd 扫描的页个数
- pgscand/s:每秒直接被扫描的页个数
- pgsteal/s:每秒钟从 cache 中被清除来满足内存需要的页个数
- %vmeff:每秒清除的页(pgsteal)占总扫描页(pgscank + pgscand)的百分比
示例:sar查看历史内存信息
sar -B -s "08:00:00" -e "10:00:00"
#不加-e表示从开始时间点到现在的信息
$ sar -B -s "08:00:00"
09:45:01 PM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
09:46:01 PM 414429.37 395024.08 179478.63 0.07 352922.62 12003.78 4266.52 16269.42 99.99
09:47:01 PM 879907.08 337948.43 157970.97 0.02 402290.21 0.00 0.00 0.00 0.00
09:48:01 PM 772977.43 507343.30 150255.50 0.05 466742.08 0.00 5821.28 5821.27 100.00
强推:linux内存浅析
三十六、进程调度,D进程的危害和形成原因
没有看太懂进程调度具体指的是什么内容,我这就以进程通信(IPC)来回答吧
进程通信(IPC):
由于虚拟地址空间中的用户空间不能被其他用户进程访问,如果通过内核区域实现多进程的用户访问同一内存数据,那么无法避免上下文切换(如下图右)。多进程的应用程序明显需要进程间的相互访问,所以一种直接可以实现用户进程访问同一物理内存的方法便应运而生,这就是共享内存(如下图左)。
共享内存是实现进程相互访问IPC(inter process communication)的机制之一,其他的方式还有message queues和semaphores。共享内存是最快的IPC(inter-process communication)机制之一,因为它不需要进程间相互copy数据,进程可以通过自己的地址空间访问到共享内存。
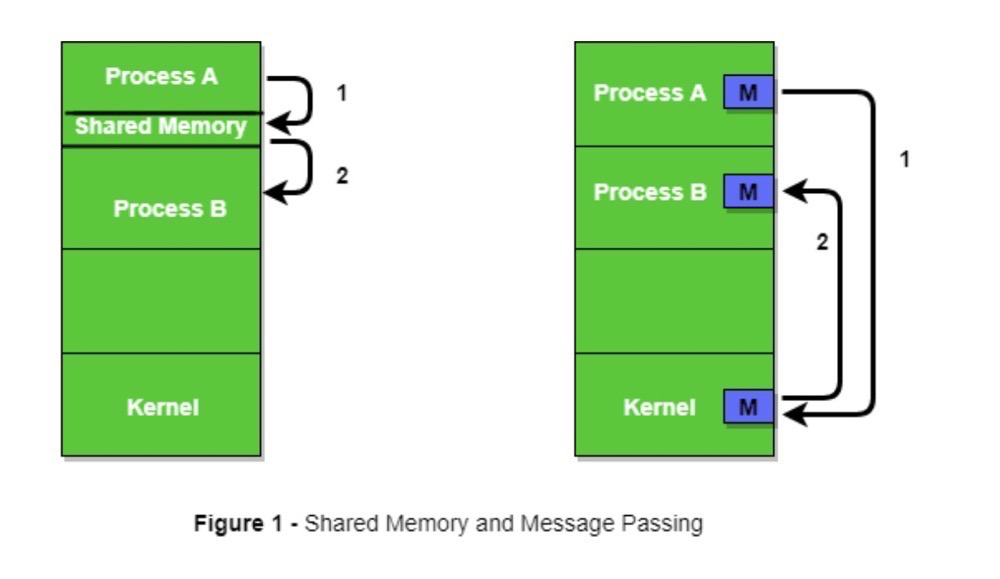
(https://www.geeksforgeeks.org/inter-process-communication-ipc/)
共享内存也有很多实现方式。PG中,shared_buffer默认使用mmap实现共享内存机制,对应shared_memory_type参数;并行查询默认使用POSIX,对应dynamic_shared_memory_type参数。

(https://momjian.us/main/writings/pgsql/inside_shmem.pdf)
D进程:
D进程含义:不可中断的睡眠状态。表示该进程正在等待某个外部事件完成,如磁盘I/O操作或网络请求。通常情况下,D进程不能被直接终止。
D进程产生的原因:进程正在等待某个外部事件,典型的比如触发直接内存回收,它是同步的会阻塞应用程序访问磁盘,当时的磁盘访问相关进程处于D状态。注意:D进程是操作系统或硬件层面触发的,与应用程序本身关系不大(a little),比如一条PG大查询会话本身不会产生D进程,也可以被kill掉。
三十七、抓包解包,分析 PostgreSQL 协议
PG支持的协议:
1)连接协议:
- TCP/IP 协议: PostgreSQL 最常用的连接方式是通过 TCP/IP 协议进行通信,允许客户端和服务器在网络上进行连接和交换数据。
- Unix 域套接字(Unix domain socket): 对于位于同一台主机上的客户端和服务器之间的连接,可以使用 Unix 域套接字进行本地通信,通常比 TCP/IP 更快。
- SSL/TLS 协议: PostgreSQL 支持在 TCP/IP 连接上启用 SSL/TLS 加密,以确保数据在传输时的安全性。TLS是SSL的后续版本,PG(似乎)已经不支持SSL协议,不过相关参数还保留着供TLS使用。
2)密码认证协议:
- MD5: 作为较早的默认密码认证协议,MD5(Message Digest Algorithm 5)用于在服务器端存储和验证用户密码。
- SCRAM-SHA-256: SCRAM-SHA-256(Salted Challenge Response Authentication Mechanism with SHA-256)是一种更安全的身份验证协议,使用 SHA-256 哈希算法和挑战-响应机制来进行用户身份验证。PG10开始逐渐替代MD5。
简单的抓包分析:
tcpdump抓包语句:
tcpdump tcp port 5432 -i lo -s0 -nSX -vvv
抓一个count(*)看看(已经通过psql -h连接到数据库里了) :
lzldb=> select count(*) from t1; --只抓这个看看
count
-------
4
抓包内容:
15:51:34.828820 IP (tos 0x0, ttl 64, id 29027, offset 0, flags [DF], proto TCP (6), length 82)
172.18.10.85.37240 > 172.18.10.85.postgres: Flags [P.], cksum 0x6d13 (incorrect -> 0x57c6), seq 1091052893:1091052923, ack 3014367256, win 350, options [nop,nop,TS val 92480460 ecr 92427582], length 30
0x0000: 4500 0052 7163 4000 4006 5c74 ac12 0a55 E..Rqc@.@.\t...U
0x0010: ac12 0a55 9178 1538 4108 255d b3ab 9818 ...U.x.8A.%]....
0x0020: 8018 015e 6d13 0000 0101 080a 0583 23cc ...^m.........#.
0x0030: 0582 553e 5100 0000 1d73 656c 6563 7420 ..U>Q....select.
0x0040: 636f 756e 7428 2a29 2066 726f 6d20 7431 count(*).from.t1
0x0050: 3b00 ;.
15:51:34.830090 IP (tos 0x0, ttl 64, id 49370, offset 0, flags [DF], proto TCP (6), length 115)
172.18.10.85.postgres > 172.18.10.85.37240: Flags [P.], cksum 0x6d34 (incorrect -> 0x6e5c), seq 3014367256:3014367319, ack 1091052923, win 342, options [nop,nop,TS val 92480461 ecr 92480460], length 63
0x0000: 4500 0073 c0da 4000 4006 0cdc ac12 0a55 E..s..@.@......U
0x0010: ac12 0a55 1538 9178 b3ab 9818 4108 257b ...U.8.x....A.%{
0x0020: 8018 0156 6d34 0000 0101 080a 0583 23cd ...Vm4........#.
0x0030: 0583 23cc 5400 0000 1e00 0163 6f75 6e74 ..#.T......count
0x0040: 0000 0000 0000 0000 0000 1400 08ff ffff ................
0x0050: ff00 0044 0000 000b 0001 0000 0001 3443 ...D..........4C
0x0060: 0000 000d 5345 4c45 4354 2031 005a 0000 ....SELECT.1.Z..
0x0070: 0005 49 ..I
15:51:34.830098 IP (tos 0x0, ttl 64, id 29028, offset 0, flags [DF], proto TCP (6), length 52)
172.18.10.85.37240 > 172.18.10.85.postgres: Flags [.], cksum 0x6cf5 (incorrect -> 0x5cb9), seq 1091052923, ack 3014367319, win 350, options [nop,nop,TS val 92480461 ecr 92480461], length 0
0x0000: 4500 0034 7164 4000 4006 5c91 ac12 0a55 E..4qd@.@.\....U
0x0010: ac12 0a55 9178 1538 4108 257b b3ab 9857 ...U.x.8A.%{
...W
0x0020: 8010 015e 6cf5 0000 0101 080a 0583 23cd ...^l.........#.
0x0030: 0583 23cd ..#.
肉眼看报文···可以简单分析出,这个count语句只产生了3个报文,甚至可以看到select.count(*).from.t1语句
wireshark分析报文:
窗口1:
tcpdump tcp port 5432 -i lo -s0 -nSX -vvv -w tcpdump.cap
窗口2:
[postgres@iZ2vcdugd3f2h0t7x20pqmZ data]$ psql -h 172.18.10.85 -p 5432 -d lzldb -U lzl --步骤1,连接
Password for user lzl: --步骤2,输入密码
lzldb=> select count(*) from t1; --步骤3,查个SQL
count
-------
4
lzldb=> \q --步骤4,退出连接
注意有4个步骤,至少对应报文的4个部分内容
- 步骤1-请求连接
- 步骤2-输入密码
- 步骤3-查个SQL
- 步骤4-退出连接
包抓好,下面开始用wireshark分析tcpdump.cap的报文。
1)步骤1-请求连接[1-10]——TCP三次握手[1-3]:
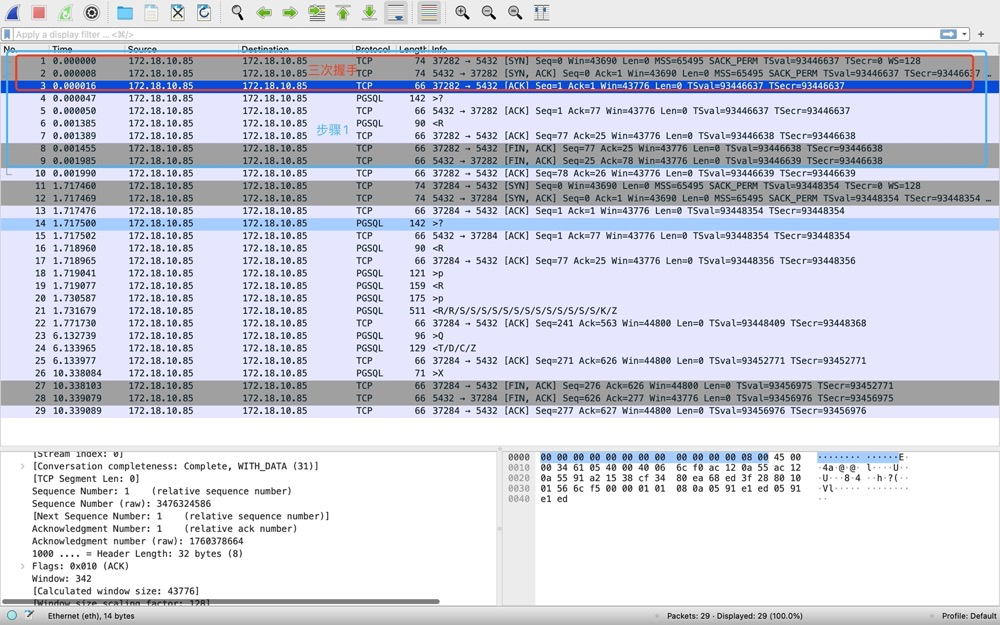
- 37282->5432发送SYN,seq=0
- 5432->37282发送SYN+ACK,seq=0 ack=1
- 37282->5432发送ACK,seq=1 ack=1
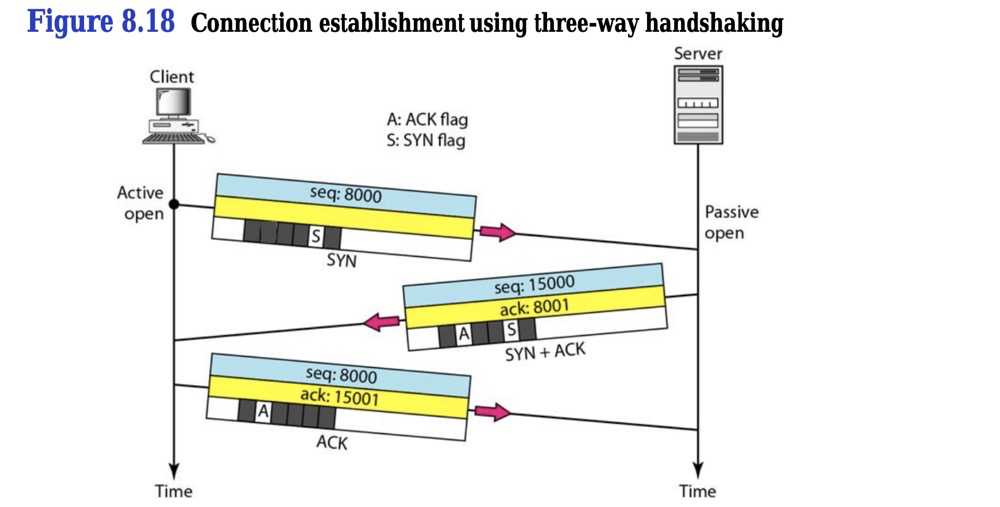
(https://www.researchgate.net/publication/340247809_Computer_Network_Chapter_8_Transport_Layer_UDP_and_TCP)
2)步骤1-请求连接[1-10]——pgsql协议启动和认证请求[4-7]:

三次握手完成后,PSQL客户端立即向PG server发送开始建立PGSQL协议的消息[4],info为>?,为协议启动消息

上面的>?报文是37282->5432,其实不用专门在Transmission Control Protocol中看source和destination。PGSQL协议虽然比TCP协议在info上展示的信息更少,但它也是有方向的:>表示37282->5432,<表示37282<-5432。
随后第二个PGSQL协议是认证请求[6],info为<R,37282<-5432。

3)步骤1-请求连接[1-10]——三次挥手[8-10]。在server向client发送PGSQL协议认证请求后,client请求断开TCP协议,3次TCP挥手(注意不是4次挥手,下面会提及)。注意此时psql命令行的状态是等待输入密码···
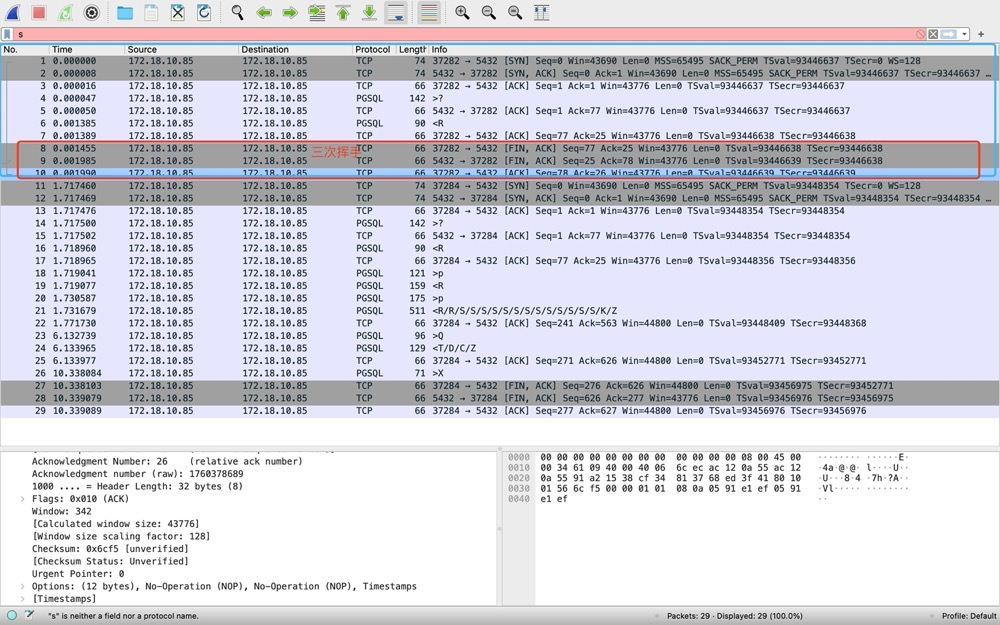
4)步骤2-输入密码[11-22]——三次握手[11-13]。因为第一次TCP协议结束了,建连接还得从TCP开始···所以得先开始第二次TCP协议三次握手:
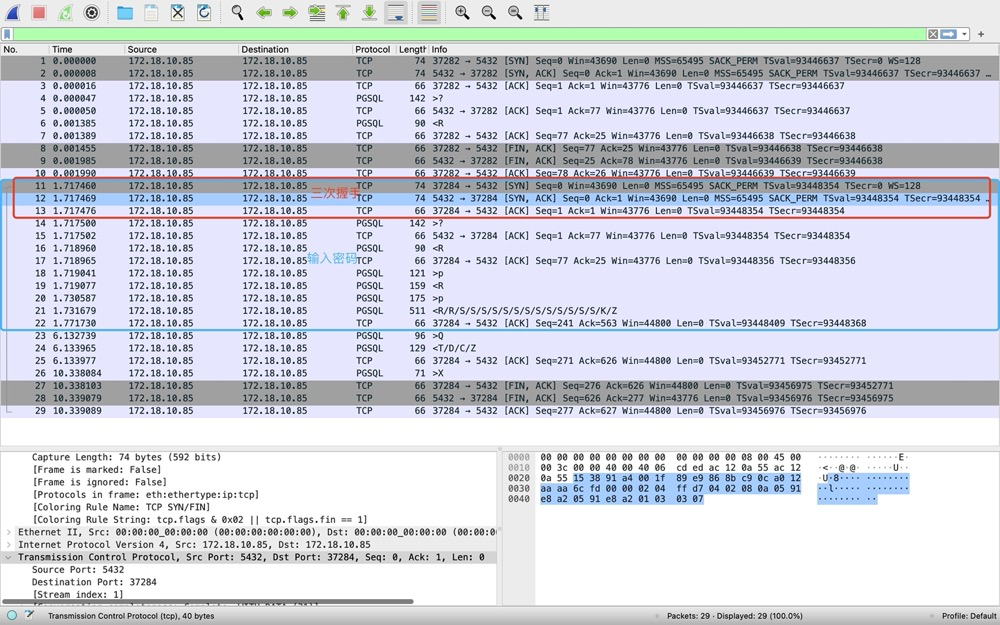
5)步骤2-输入密码[11-22]——密码认证[14-22]。认证阶段稍微复杂一些。[14-16]实际上跟步骤1中的[4-7]做的事情是一样的,client请求启动PGSQL协议,server返回认证需求。随后[18-20]都是在做密码认证,密码认证机制为SCRAM-SHA-256,密码认证其实传了4个报文,包括[21]的两个R认证消息。随后[21]连接建立,前两个R是认证完成消息;中间有很多S表示Parameter status:应用名、字符集、时区等等参数信息;K表示Backend key,返回fork出来的backend PID;Z表示ready for query。
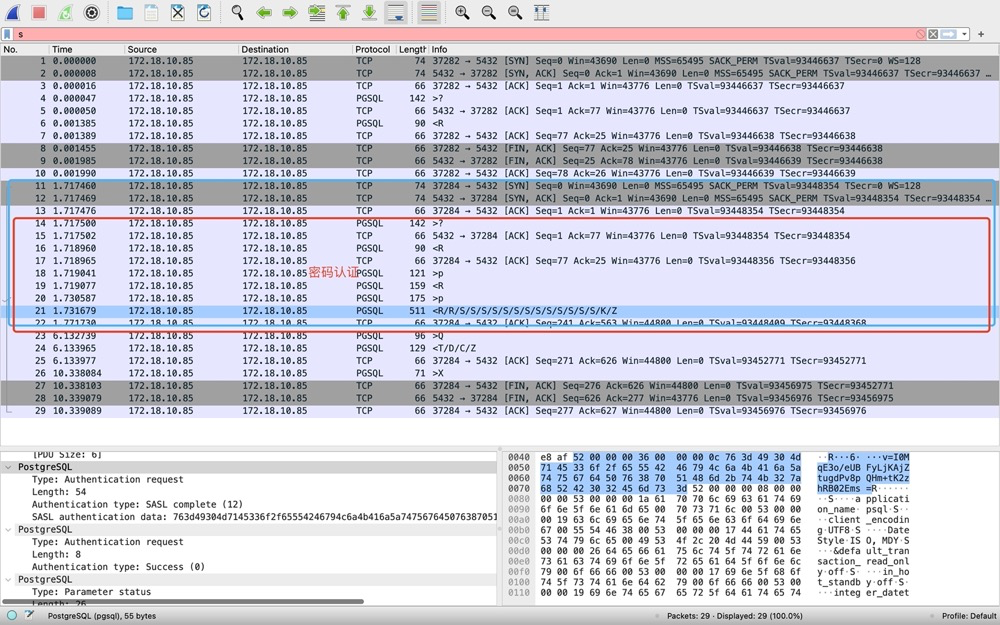
5)步骤3-查个SQL[23-25]
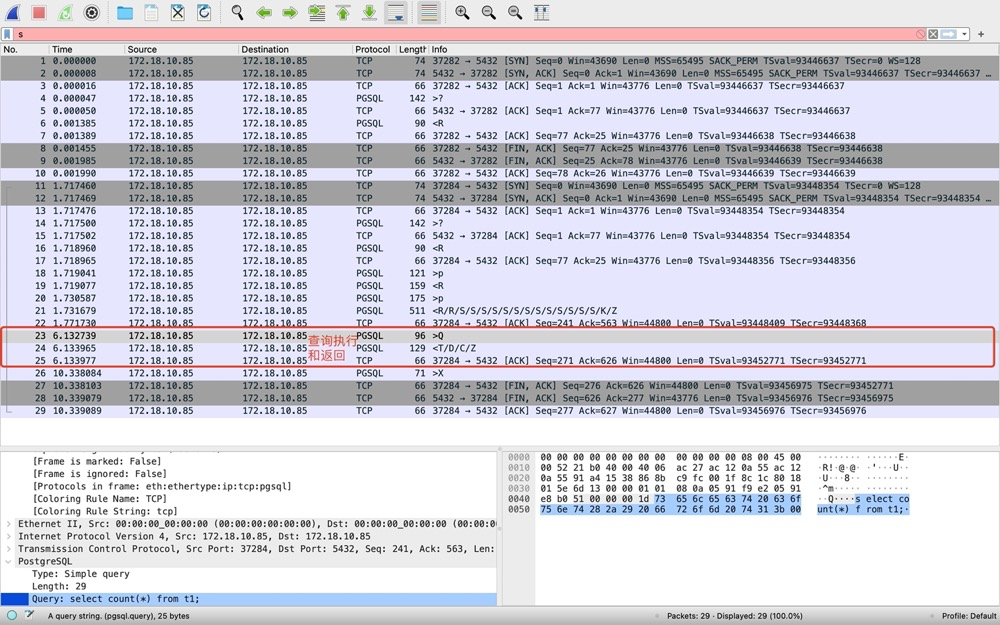
[23]Q明显代表query,client发出包含SQL的报文;[24]返回结果,T代表Row Description,这里只包含列名count;D代表data row数据行,这里的返回的count结果为4,数据没有加密是明文的:

C代表命令完成;Z代表ready。
5)步骤4-断开连接[26-29]。[26]client主动发出结束会话的消息,PGSQL协议(对应\q);[27-29]仍然是3次TCP挥手过程。
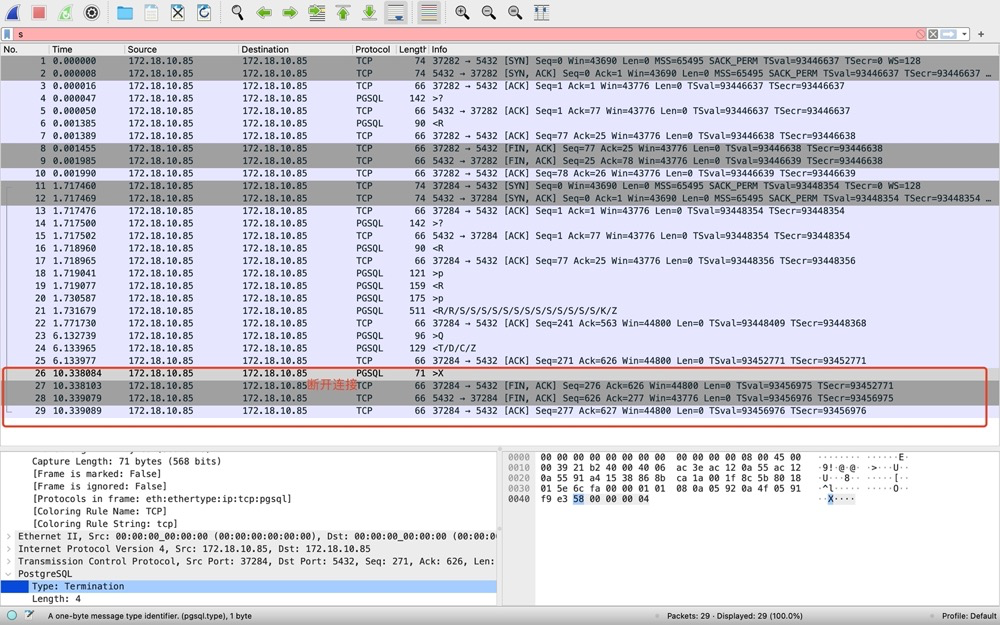
为啥是三次挥手而不是此次挥手?
「没有数据要发送」并且「开启了 TCP 延迟确认机制」,那么第二和第三次挥手就会合并传输,这样就出现了三次挥手:
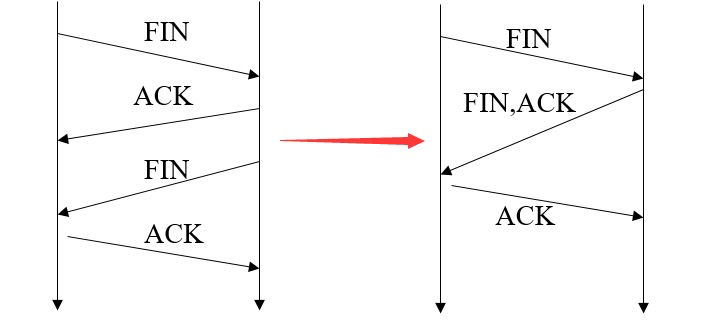
因为 TCP 延迟确认机制是默认开启的,所以导致我们抓包时,看见三次挥手的次数比四次挥手还多。
OK,PG的简单抓包和分析完成。汇总一个本次分享的Postgres网络传输图:

抓包分析注意事项:
- 需要先搞清楚链路,一般业务请求端和数据库服务端之间还有很多节点,比如网络交换机,请求转发服务等等
- 节点上要最好都抓包,两端同时抓包
- 注意抓包时间,设置过滤器等
可能丢包的点:
https://mp.weixin.qq.com/s/dF4juaW-ttI0Zn1j0z6tag
丢包会涉及到⽹卡、驱动、内核协议栈三⼤类,每一层都有可能会丢包:
- 在两台 VM 连接之间,可能会发生传输失败的错误,比如网络拥塞、线路错误等;
- 在网卡收包后,环形缓冲区可能会因为溢出而丢包;
- 在 IP 层,可能会因为路由失败、组包大小超过 MTU 等而丢包;
- 在传输层,可能会因为端口未监听、资源占用超过内核限制等而丢包;
- 在套接字层,可能会因为套接字缓冲区溢出而丢包;
- 在应用层,可能会因为应用程序异常而丢包;
参考:
三十八、存储,SAN/NAS/DAS

三十九、一条 IO 请求的生命周期
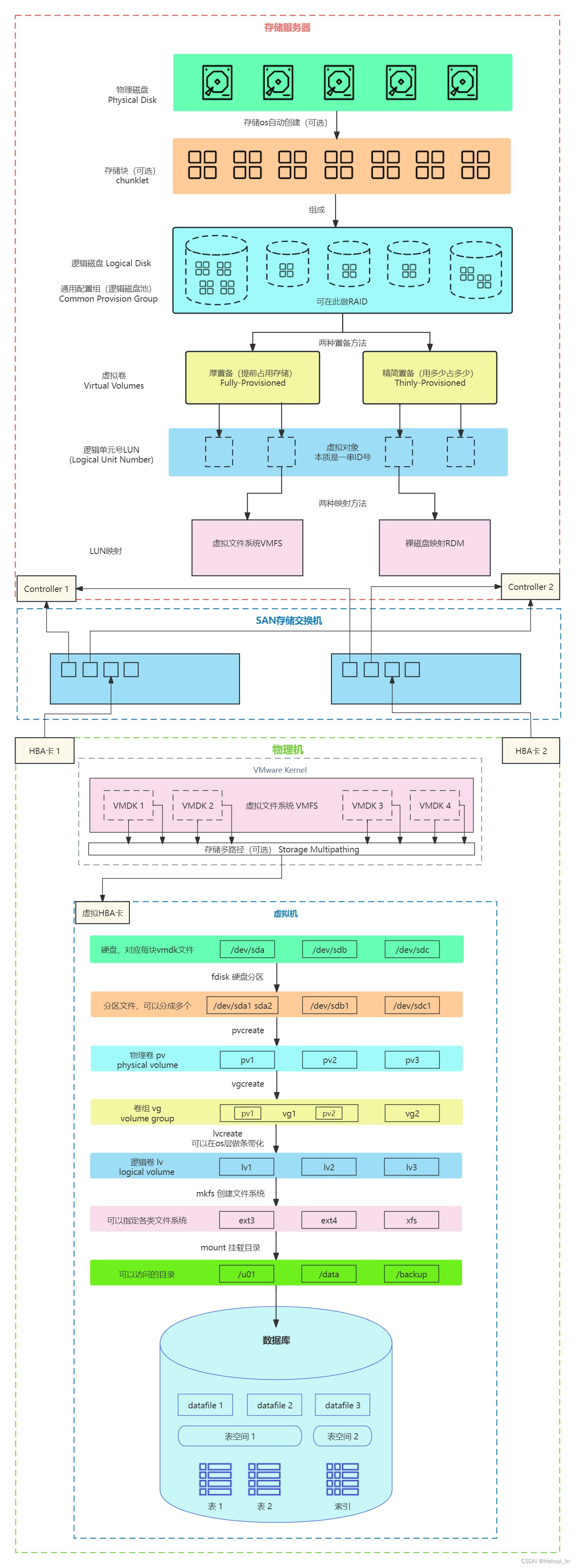
(https://blog.csdn.net/Hehuyi_In/article/details/100715177?spm=1001.2014.3001.5501)