ONE-PEACE: EXPLORING ONE GENERAL REPRESENTATION MODEL TOWARD UNLIMITED MODALITIES
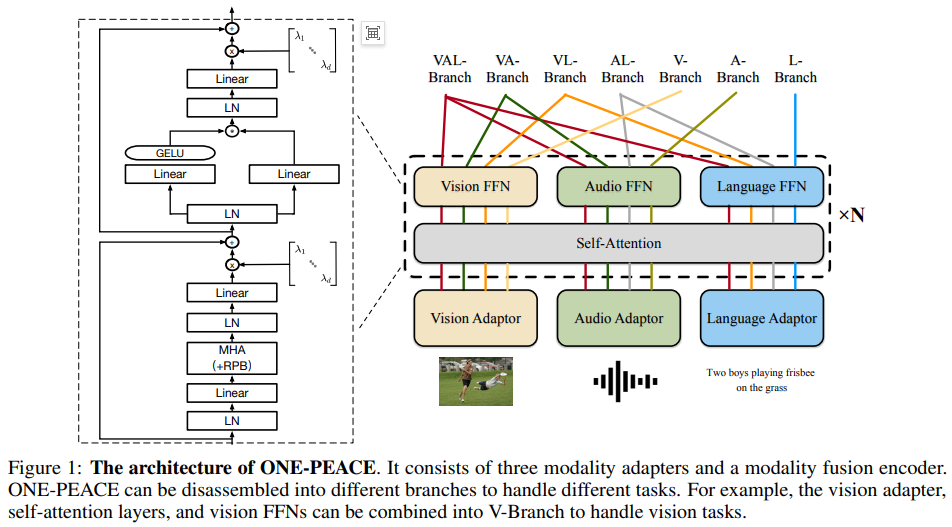
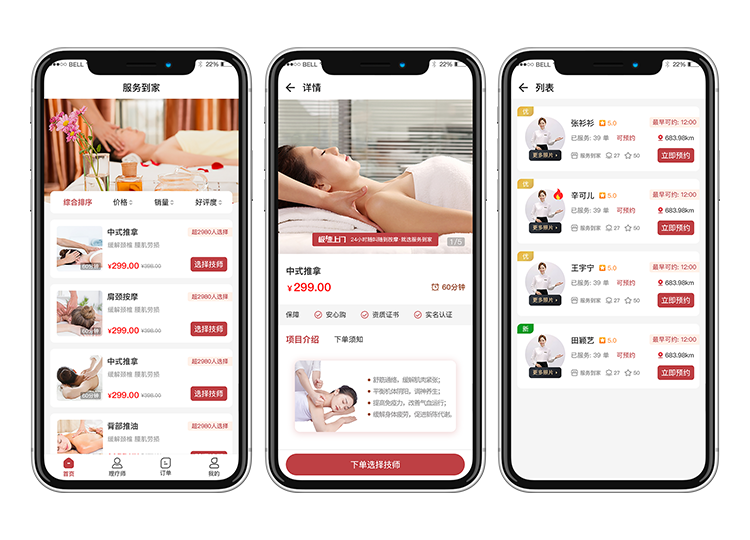
适应不同模态并且支持多模态交互。
预训练任务不仅能提取单模态信息,还能模态间对齐。
预训练任务通用且直接,使得他们可以应用到不同模态。
各个模态独立编码,然后模态融合。
Vision Adapter:使用hierarchical MLP (hMLP) stem对图像分块,直到patch size 16 × 16,不同块之间没有交互。然后打成patch 特征序列,再加一个类别前缀向量,并加上绝对位置编码。得到:![]()
Audio Adapter (A-Adapter):16kHz采样,归一化数据,使用卷积提取相对特征。得到:![]()
Language Adapter (L-Adapter):先变成subword sequence-->加上[CLS] and [EOS]-->embeddings-->absolute positional embeddings-->![]()
预训练任务包括:cross-modal contrastive learning and intra-modal denoising contrastive learning
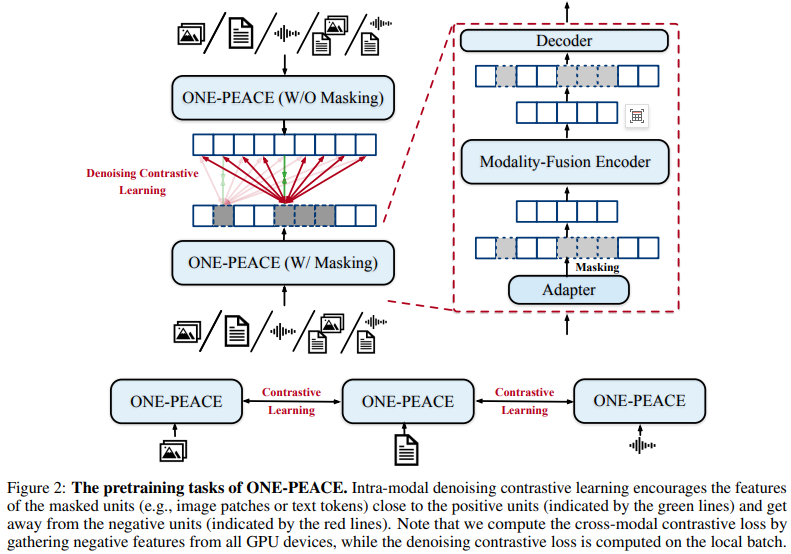
Cross-Modal Contrastive Learning:不同模态之间语义空间对齐。
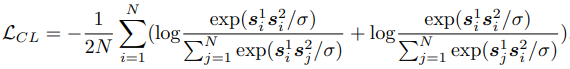
Intra-Modal Denoising Contrastive Learning:单模态内部更精细的细节。





















![[office] EXCEL表格不能使用键盘箭头切换单元格该怎么解决- #媒体#经验分享#知识分享](https://img-blog.csdnimg.cn/img_convert/3f19147a9b924baa21abaa1dfe1c0dfa.jpeg)