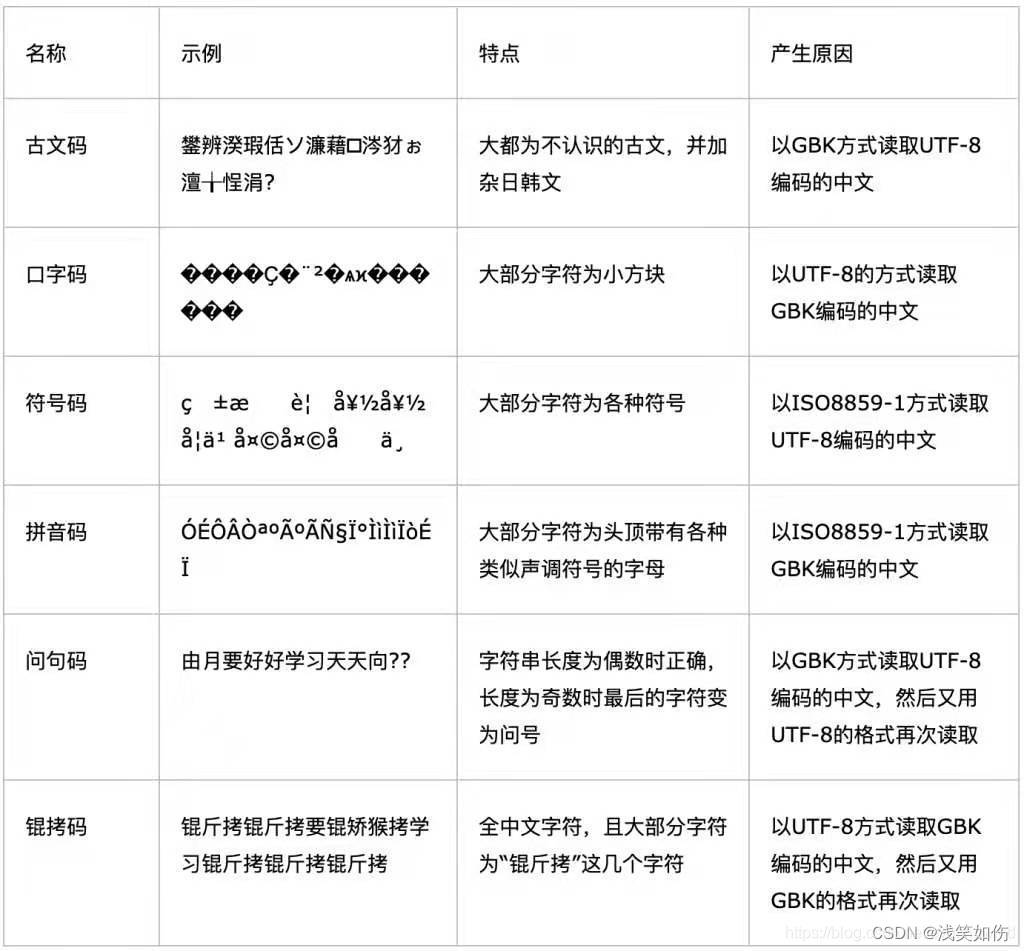
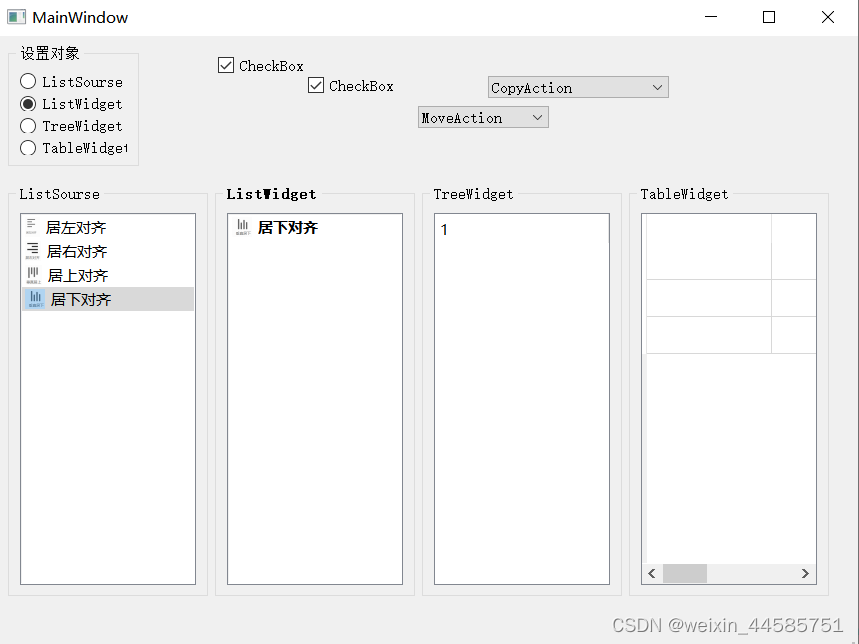
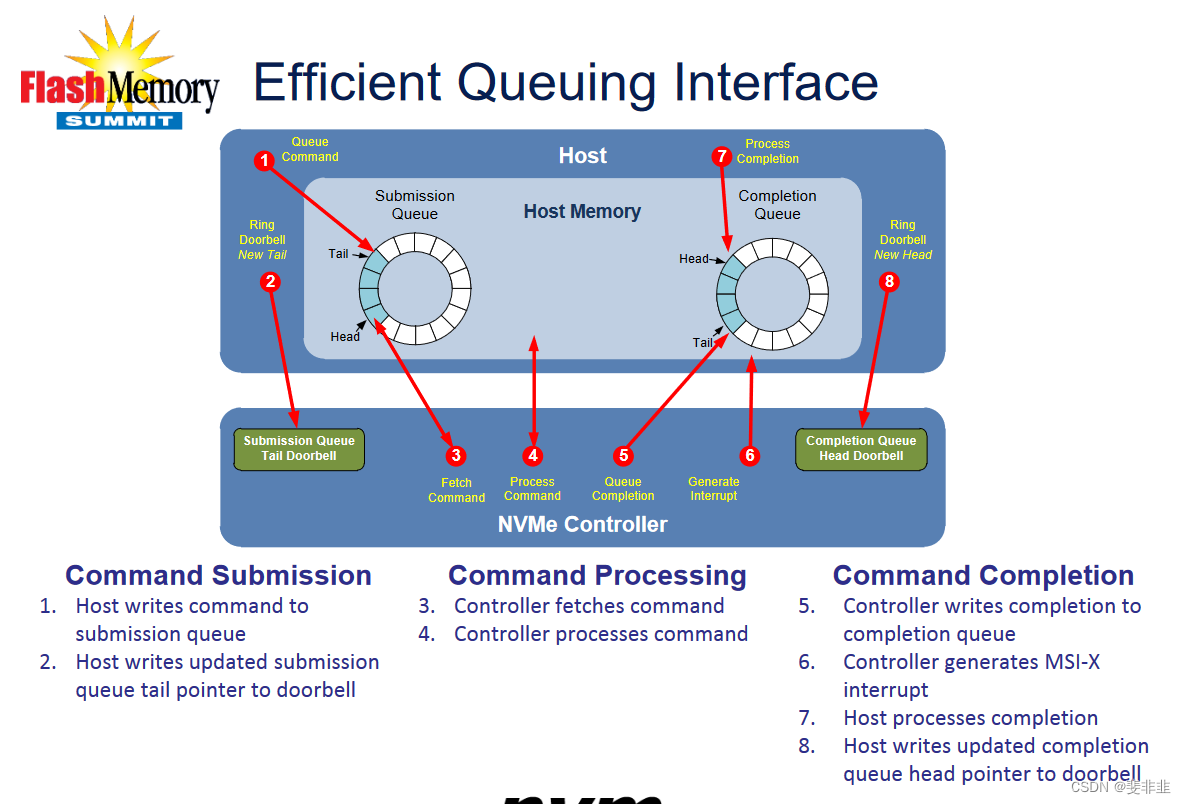
原因有两种
1.解码格式和编码格式一致
2.编码格式不支持中文
由于测试时使用了测试工具,字符串转字节的时候应该是用了Default的格式进行转换的,所以转出的时候使用同样的方式才能正确转换。
然后我针对UTF8和Default 两种格式进行了测试
| string | 转为byte[]时使用的格式 | 转回string时使用的格式 | Console |
|---|---|---|---|
| 你好你好你好123abcAbc | UTF8 | Default | 浣犲ソ浣犲ソ浣犲ソ123abcAbc |
| 你好你好你好123abcAbc | Default | UTF8 | ???123abcAbc |
结论:我在使用工具软件时它把字符串转换为byte[]默认使用的编码格式为Default,而我在解析时使用了UTF-8的编码格式,所以出现乱码。
可以参考地址:
1..Net对编码的说明