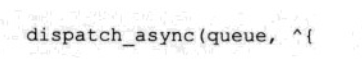前言
如何实现与AI大模型的对话?一种选择是登陆AI大模型厂商提供的对话网站或者App。另外,目前网络上还有很多开源的实现,比如Chatbox,Chathub,ChatALL等等。这些项目大多使用Typescript, Javascript,提供配置功能,大模型人设等功能。
这篇文章里,我们使用Python的几十行代码来实现一个简单的AI 大模型对话对比器。
功能介绍
这个AI大模型对话对比器包含与大模型对话和多个大模型对比的功能。
- 提供浏览器界面,供用户输入提示词和显示对话生成结果。
- 可以对比多个大模型 (目前代码示例为GPT3和GPT4)。
- 保存对话上下文直至手动清空。
界面如下:

大模型本身没有记忆功能。从截图中可以看到,程序本身可以记忆上下文,上文中的英文被输入给大模型,并在用户的要求下被大模型翻译成下文中的中文。
代码实现
这里要介绍一下Streamlit,使用它根本不需要任何前端代码,只需要纯Python就可以快速构建漂亮的Web应用。Streamlit很流行,甚至AI大模型也支持Streamlit代码。
文中这个简单的系统-AI 大模型对话对比器,只使用了几十行的Python代码,按照前端功能和后端功能分成两个文件。
你可以通过访问我的Github直接下载代码。
前端功能
前端功能主要包括输入提示词和显示大模型对话生成内容。在用户清空对话之前,保存对话的上下文,并作为输入调用后端功能。
首先确保在调试运行之前安装了streamlit:
$ pip install streamlit
前端功能的python文件 - aitalk.py
__author__ = 'liyane'
import streamlit as st
from aibackend import models, get_chat_response_from_all_models
# define page / 定义页面
st.set_page_config(layout="wide")
st.title("🤖 AI大模型对话&对比器")
# save chat context by default / 默认可保存对话上下文
# clean chat context after click the reset button / "点击“清空所有对话”按钮后将清空上下文
reset_button = st.button("清空所有对话(Reset)")
if reset_button:
st.session_state.messages = {
model_id: [] for model_id in models}
# initialize column for each model / 初始化大模型对话栏
st_all_columns = st.columns(len(models))
model_to_column_map = {
}
for i, model_id in enumerate(models):
model_to_column_map[model_id] = st_all_columns[i]
for model_id, column in model_to_column_map.items():
column_subheader=model_id+"("+models[model_id]+")"
column.subheader(column_subheader)
# initialize streamlit session messages / 初始化会话
if "messages" not in st.session_state:
st.session_state.messages = {
model_id: [] for model_id in models}
# display chat history / 显示历史会话内容
for model_id, messages in st.session_state.messages.items():
column = model_to_column_map[model_id]
for message in messages:
column.chat_message(message["role"]).write(message["content"])
# handle the prompt / 处理用户提示词
prompt = st.chat_input()
if prompt:
# save and display the prompt / 将用户提示词储存在会话中,并显示在对话栏中
for model_id, column in model_to_column_map.items():
st.session_state.messages[model_id].append({
"role": "user", "content": prompt})
column.chat_message("user").write(prompt)
# call backend function and save&display the output from AI model / 调用后端大模型生成接口,并存储和显示大模型的输出
with st.spinner("AI正在思考中,请稍等..."):
response = get_chat_response_from_all_models(st.session_state.messages)
for model_id, column in model_to_column_map.items():
content = response[model_id]
st.session_state.messages[model_id].append({
"role": "assistant", "content": content})
column.chat_message("assistant").write(content)
后端功能
后端功能主要包括定义大模型字典和与大模型的对话生成接口通信。
在运行示例文件之前,取保你将OPENAI_API_KEY和其他需要的环境变量写入到同目录的如下隐藏文件中。
.env
OPENAI_API_KEY="..."
OPENAI_BASE_URL="..."
我使用的是GPT3 和 GPT4, 如果你需要使用其他的大模型,需要添加相关的代码。
apibackend.py
__author__ = 'liyane'
import os
from openai import OpenAI
# load .env for OPENAI_API_KEY / 加载 .env 到环境变量,其中包含OPENAI_API_KEY
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# configure OpenAI client/ 配置 OpenAI 服务
client = OpenAI()
# define dict for all AI models / 定义大模型ID和对应的实际名称
models = {
"GPT4": "gpt-4-turbo-preview", "GPT3": "gpt-3.5-turbo"}
# loop all defined AI models / 循环调用所有大模型
def get_chat_response_from_all_models(messages):
response_from_models = {
}
for model_id, model_dict in models.items():
response = get_chat_response_from_gpt(messages[model_id], models[model_id])
response_from_models[model_id] = response
return response_from_models
# call OpenAI chat completioin API / 调用GPT大模型对话生成接口
def get_chat_response_from_gpt(messages, model):
response = client.chat.completions.create(
messages=messages,
model=model
)
return response.choices[0].message.content
启动步骤
使用下面的命令启动:
$ streamlit run aitalk.py
然后访问如下地址:
http://localhost:8501/
streamlit还支持将项目免费部署于streamlit community cloud上边,通过互联网访问。
其他问题
如何只使用一个大模型?
代码调用GPT的接口是通用的。如果希望只使用GPT的模型之一,可以修改aibackend.py中models的定义。
修改之前:
# define dict for all AI models / 定义大模型ID和对应的实际名称
models = {
"GPT4": "gpt-4-turbo-preview", "GPT3": "gpt-3.5-turbo"}
修改之后界面将只显示一个模型的对话栏。model的ID(比如GPT4)也可以修改。
# define dict for all AI models / 定义大模型ID和对应的实际名称
models = {
"GPT4": "gpt-4-turbo-preview"}