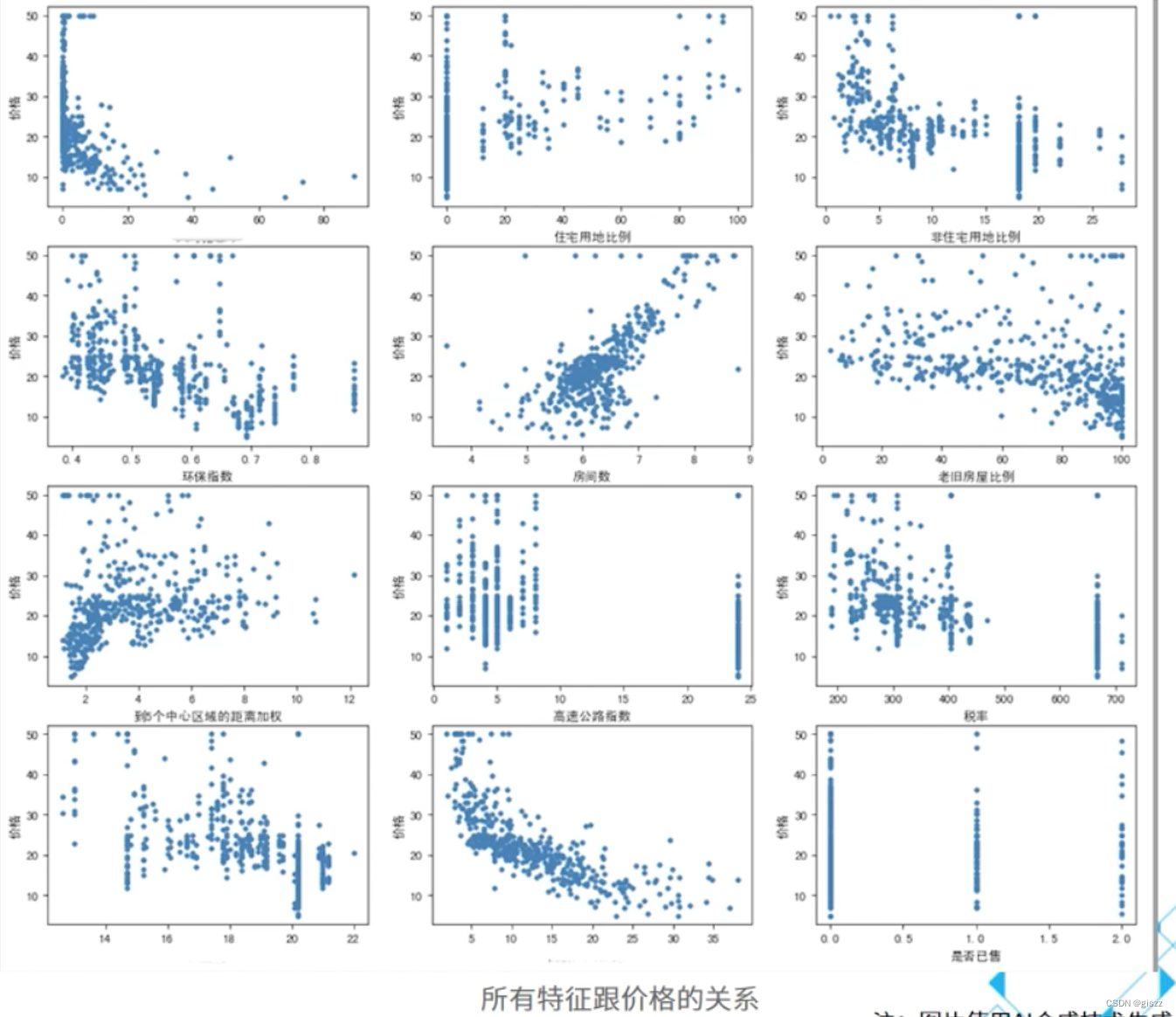
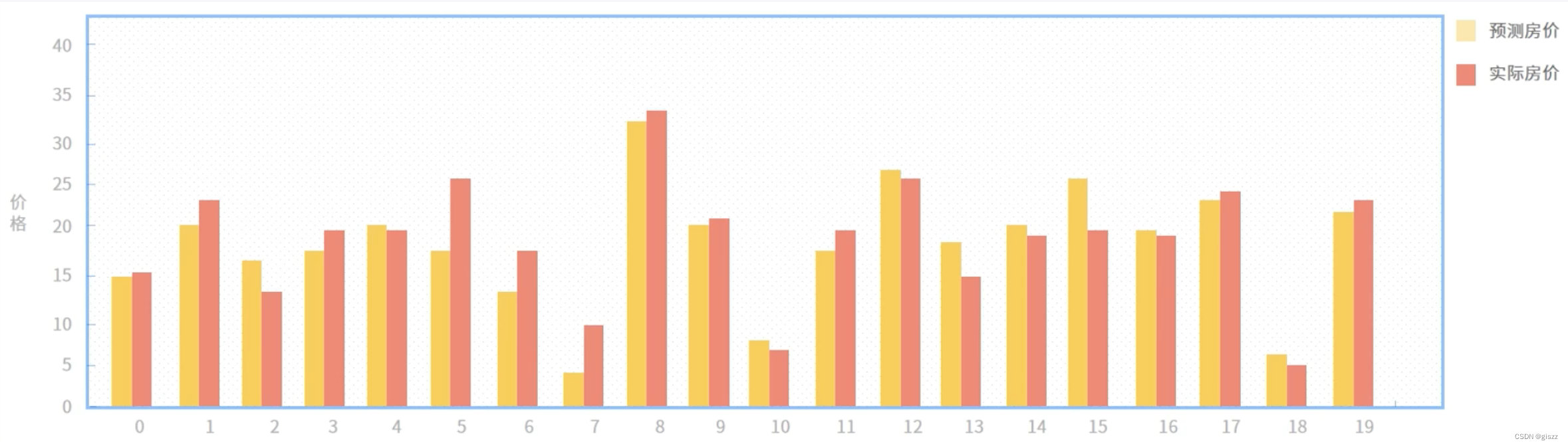
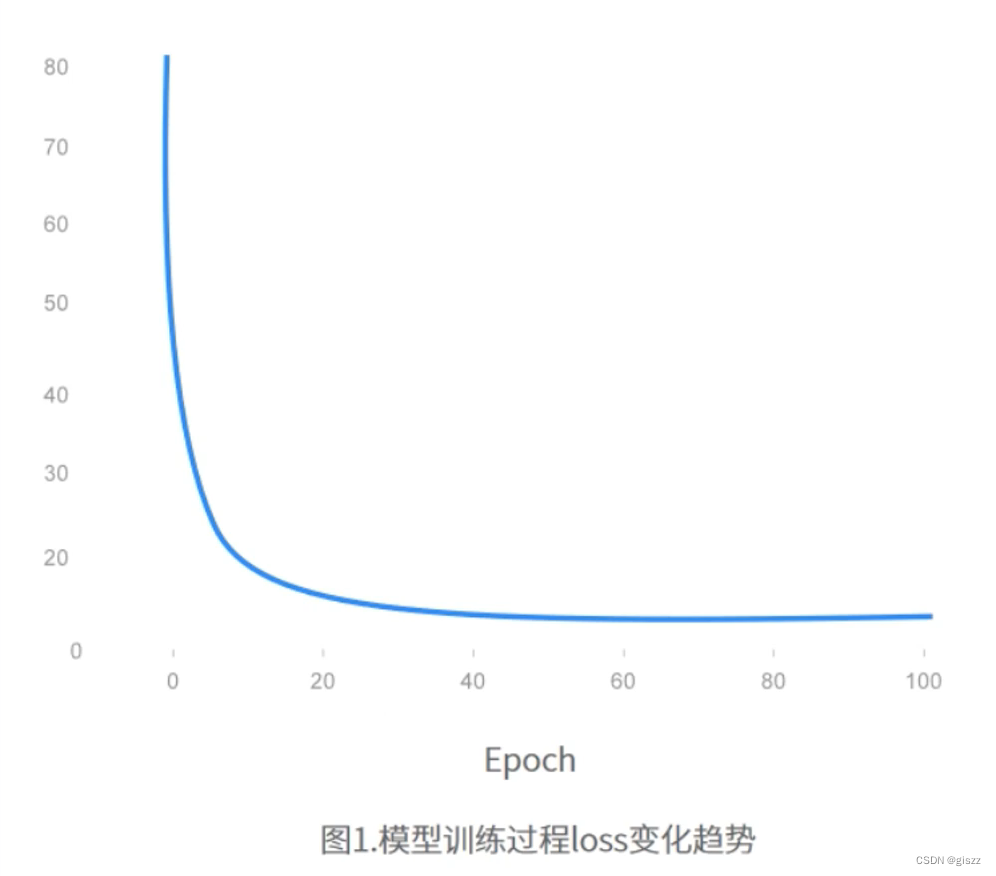
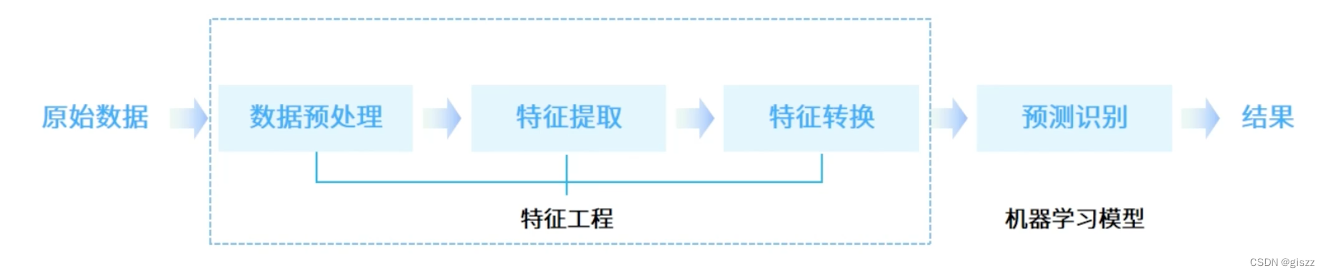
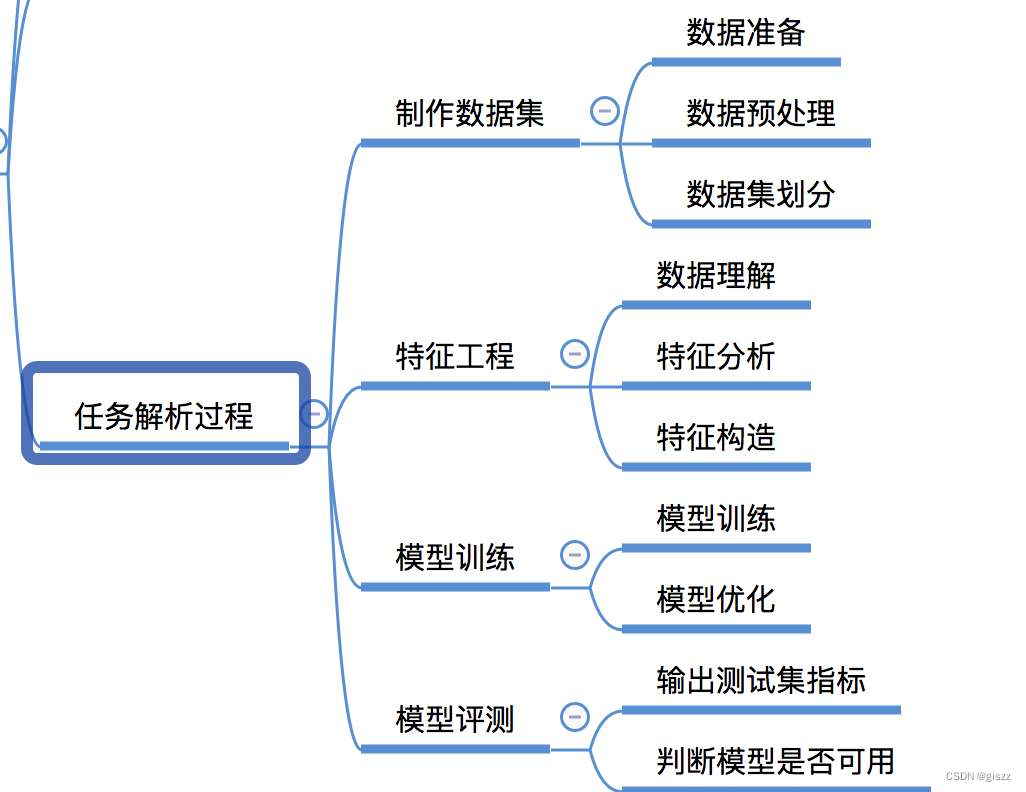
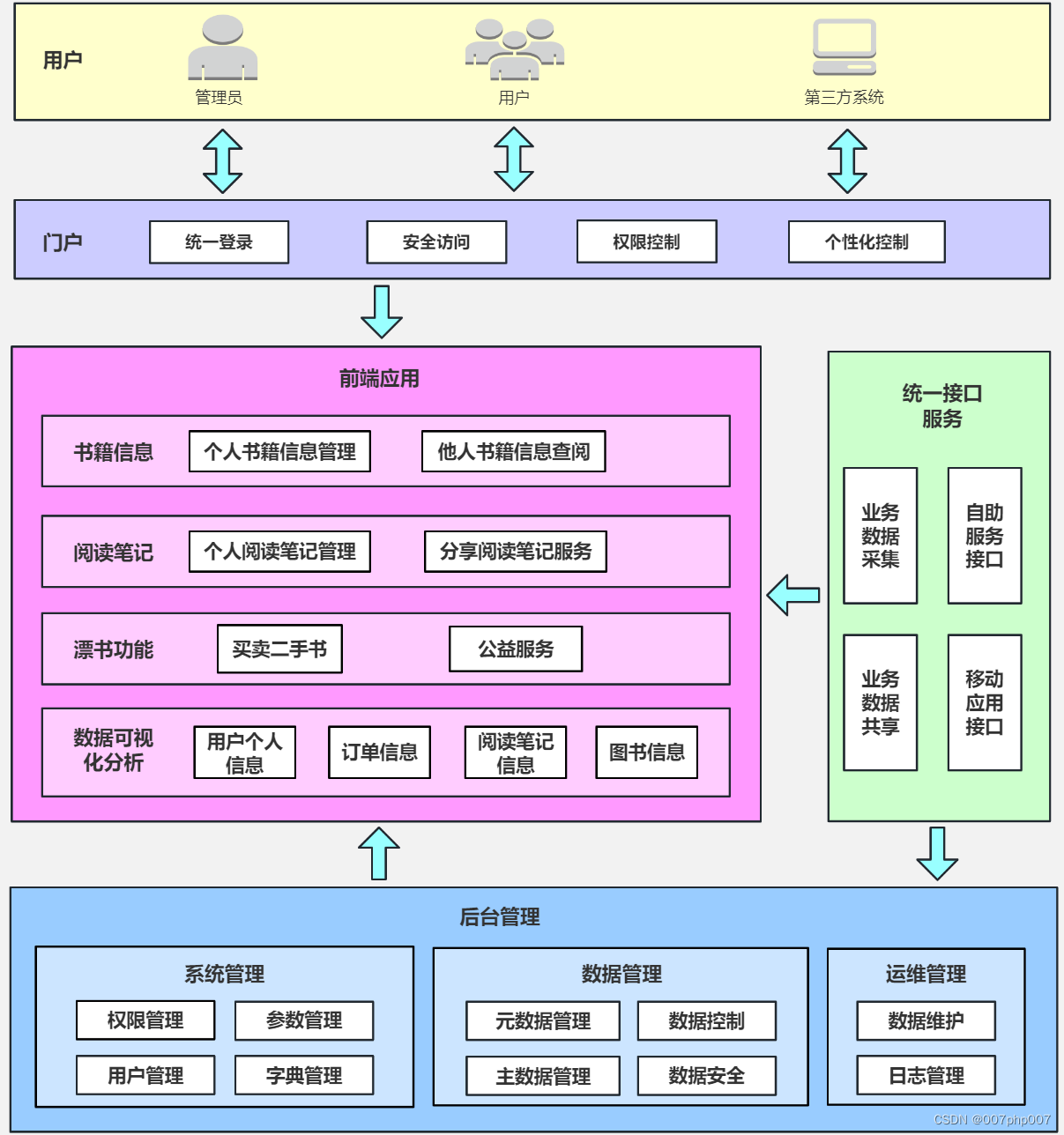
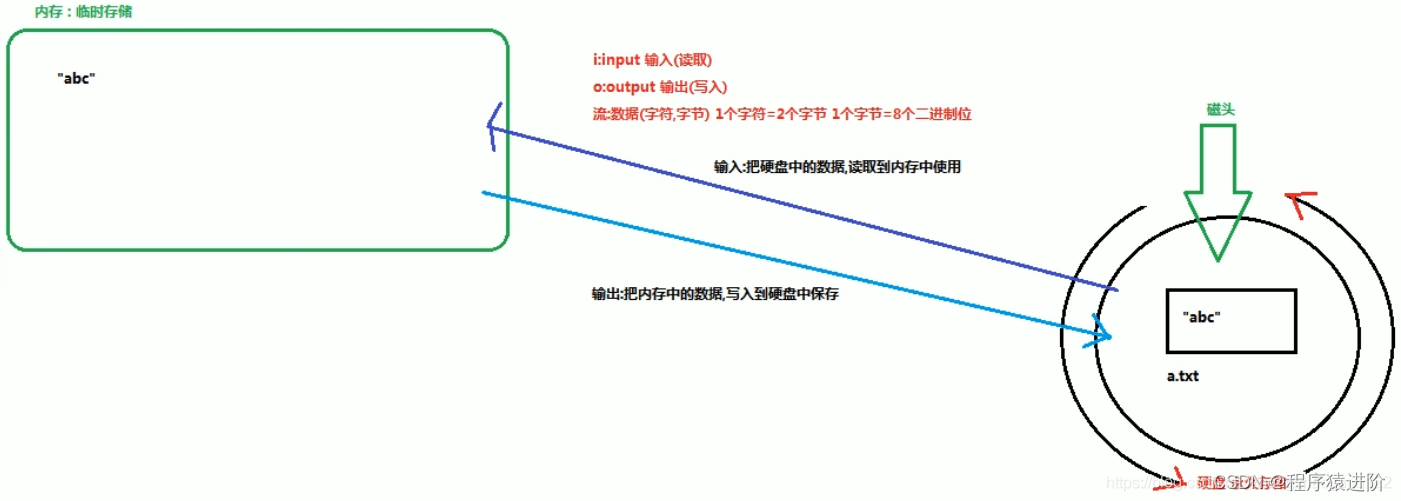
项目开始,首先要进行数据准备和数据预处理。
数据准备的核心是找到这些数据,观察数据的问题。
数据预处理就是去掉脏数据。
缺失值的处理,格式转换等。

延伸学习:
在人工智能(AI)的众多工作流程中,数据准备与预处理占据着举足轻重的地位。这两个步骤不仅影响着模型的训练效率和准确性,更是确保AI系统能够在实际应用中发挥效能的基石。
一、数据准备
数据准备的核心在于找到合适的数据源,并确保这些数据能够充分反映所要解决的问题或任务。这一步骤通常涉及以下几个方面:
数据收集:这是数据准备的第一步,需要从各种可能的来源(如数据库、日志文件、公开数据集、API接口等)中收集原始数据。在收集数据时,应特别注意数据的多样性、代表性和均衡性,以确保训练出的模型具有良好的泛化能力。
数据观察与分析:在收集到数据后,需要对其进行初步的观察和分析,以理解数据的结构、分布和潜在问题。这一步骤有助于后续的数据预处理和特征工程决策。
数据标注:对于监督学习任务,数据标注是必不可少的一步。这通常涉及为每条数据分配一个或多个标签,以便模型在训练过程中学习如何将这些输入映射到正确的输出。
二、数据预处理
数据预处理是在模型训练之前对原始数据进行清洗、转换和增强的过程,旨在提高数据的质量和可用性。具体来说,数据预处理包括以下几个方面:
去除脏数据:脏数据是指那些不完整、不准确或格式不正确的数据。这些数据可能会对模型的训练产生负面影响,因此需要被识别并去除或修正。常见的脏数据包括缺失值、异常值、重复值和错误格式的数据等。
缺失值处理:对于包含缺失值的数据,可以采取多种策略进行处理,如删除含有缺失值的行或列、使用均值、中位数或众数等统计量进行填充,或使用插值方法(如线性插值、多项式插值等)进行估计和填充。
格式转换:为了便于模型处理和计算,原始数据通常需要转换成特定的格式或数据类型。例如,将文本数据转换为数值向量(如词袋模型、TF-IDF表示等),将图像数据转换为张量格式等。此外,还可能需要对数据进行标准化或归一化,以消除不同特征之间的量纲差异和数值范围差异。
特征工程:特征工程是数据预处理中的一个重要环节,旨在从原始数据中提取出对模型训练有用的特征。这可以包括特征选择(从众多特征中选择出最相关或最具代表性的特征)、特征构造(根据已有特征组合或变换生成新的特征)和特征降维(通过主成分分析、因子分析等方法减少特征的维度和冗余性)等。
通过有效的数据准备和预处理,可以大大提高AI模型的训练效率和准确性,为后续的模型训练和部署奠定坚实的基础。因此,作为人工智能专家,应充分重视这两个步骤,并投入足够的时间和精力进行优化和改进。