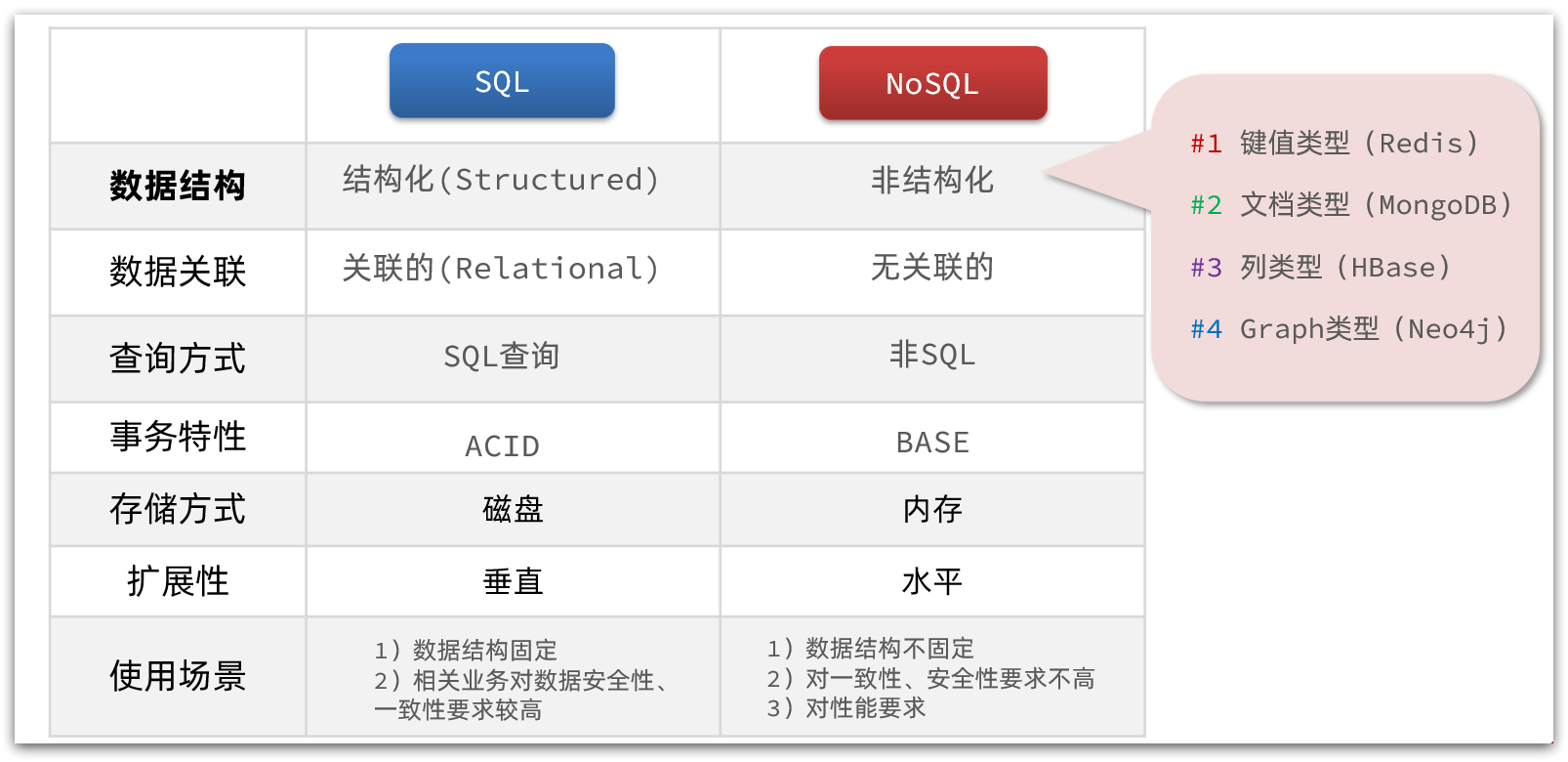
1 Scaled Dot-Product Attention中为什么要除以 d k \sqrt{d_k} dk?
1. 从纯数学上考虑:对于输入均值为0,方差为1的分布,点乘后结果其方差为dk,所以需要缩放一下。下图为原论文注释。

2. 从神经网络上考虑:防止在计算点积时数值过大,导致后续应用 softmax 函数时出现梯度消失的问题。
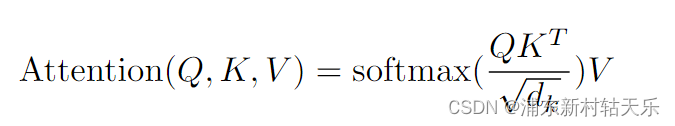
计算点积时,如果Q K的元素值和dk的值都很大,那么点积的结果可能会非常大,导致 softmax 函数的输入变得非常大。
softmax 函数在处理很大的输入值时,会使输出的概率分布接近0或1,这会造成梯度非常小,难以通过梯度下降有效地训练模型,即出现梯度消失问题。
通过使用dk缩放点积的结果,可以使点积的数值范围被适当控制。
2 Transformer 的基本组成是什么?
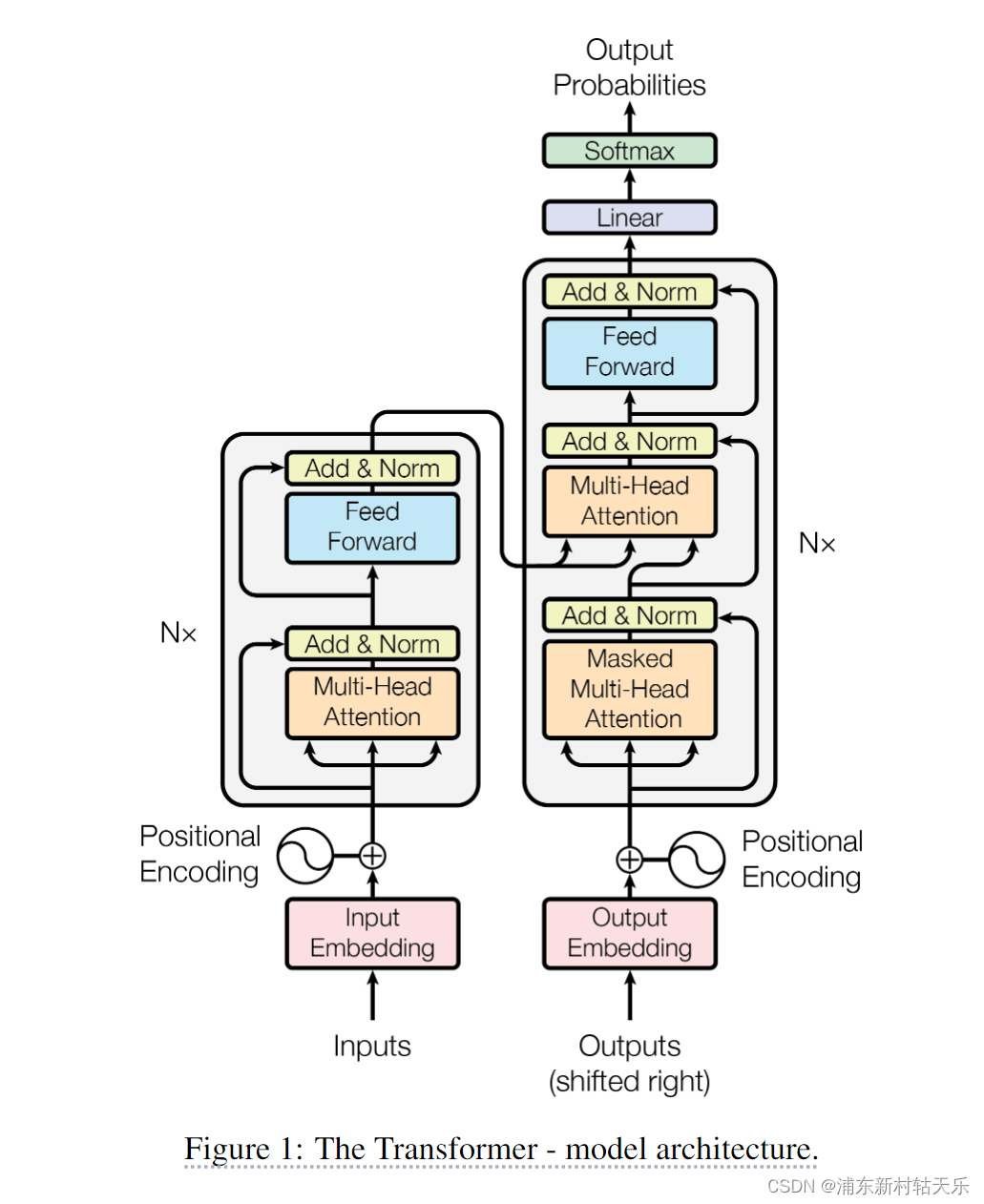
Transformer分为encoder和decoder两个部分。
Encode包含self-attention和前馈神经网络,用于提取特征;
Decoder在自注意力和前馈神经网络中间多了一个cross-attention,用于和encoder的输出做交互。
3 多头注意力机制如何实现?
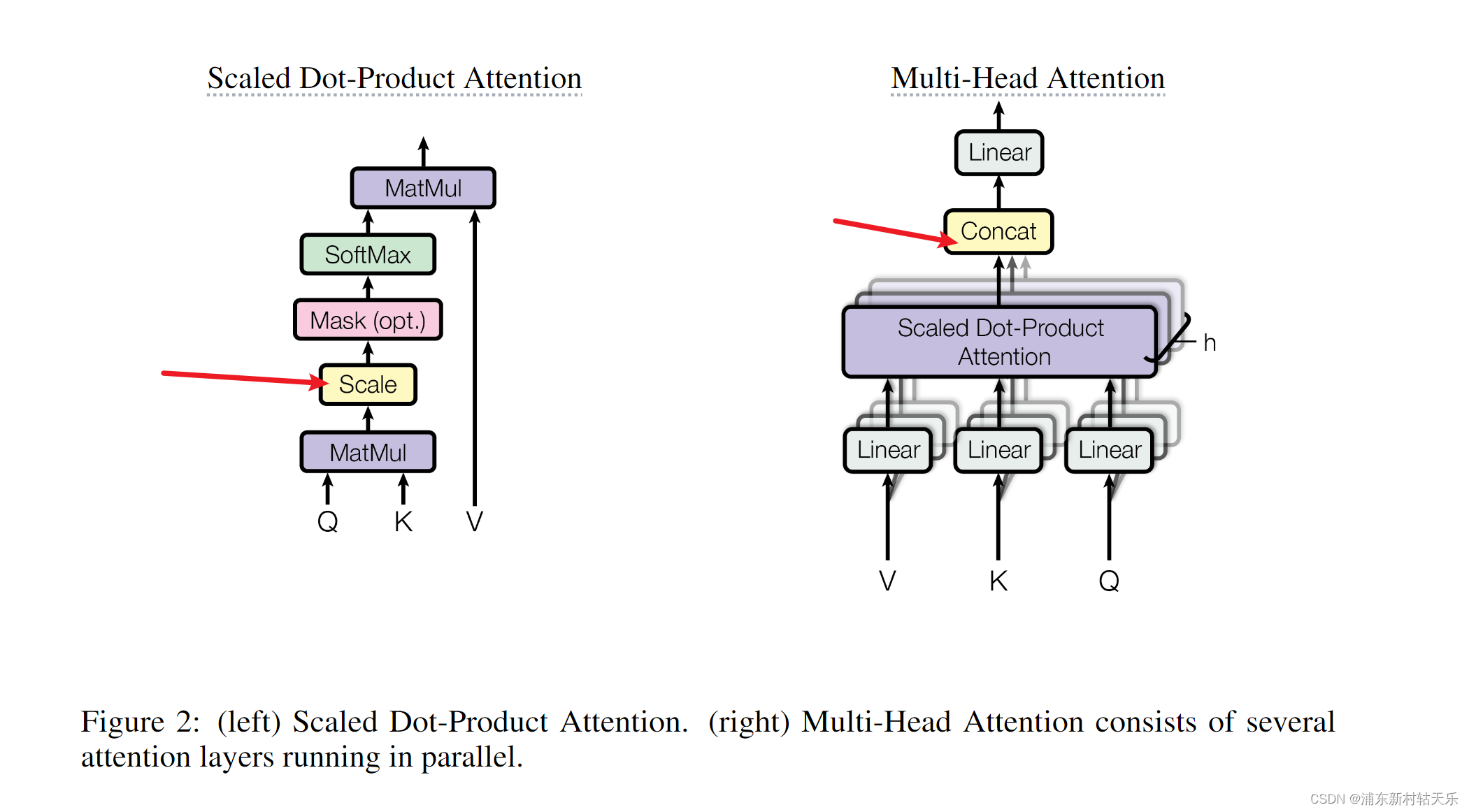
每个头独立地在相同的输入上计算注意力权重,最后把所有头的输出合并。每个头关注一部分的特征,类似于卷积中通道的作用。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
# Separate linear layers for values, keys, and queries for each head
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query):
N = query.shape[0] # Number of examples
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split embeddings into self.heads pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
# Apply linear transformation (separately for each head)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Attention mechanism (using torch.matmul for batch matrix multiplication)
# Calculate attention score
attention = torch.matmul(queries, keys.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
attention = F.softmax(attention, dim=-1)
# Apply attention weights to values
out = torch.matmul(attention, values)
# Concatenate heads
out = out.reshape(N, query_len, self.heads * self.head_dim)
# Final linear layer
out = self.fc_out(out)
return out
# Example usage
embed_size = 256
heads = 8
N = 1 # Batch size
sentence_length = 5 # Length of the input sequence
model = MultiHeadAttention(embed_size, heads)
# Dummy input (batch size, sentence length, embedding size)
x = torch.rand((N, sentence_length, embed_size))
# Forward pass
out = model(x, x, x) # In self-attention, queries, keys, values are all the same
print("Input shape:", x.shape)
print("Output shape:", out.shape)
4 训练过程为什么需要 Mask 机制?
两个原因。
- 屏蔽未来信息,防止未来帧参与训练。
- 处理不同长度的序列,在批处理时对较短的序列进行填充(padding),并确保这些填充不会影响到模型的输出。
5 mask机制如何实现?
屏蔽未来信息的 Mask:在自注意力层中,通过构造一个上三角矩阵(对于解码器),其中上三角部分(包括对角线,取决于具体实现)被设置为非常大的负数,这样在通过 softmax 层时,这些位置的权重接近于0,从而在计算加权和时不考虑未来的词。
Padding Mask:将填充位置的值设置为一个大的负数,使得经过 softmax 层后,这些位置的权重接近于0。
6 Transformer 中的Positional Encoding有什么作用?
保证attention机制考虑序列的顺序,否则无法区分不同的位置的相同的输入。
7 Transformer 如何处理长距离依赖问题?
Transformer 通过自注意力机制直接计算序列中任意两个位置之间的依赖关系,从而有效地解决了长距离依赖问题。
8 Layer Normalization的作用是什么?
Layer Normalization有助于稳定深层网络的训练,通过对输入的每一层进行标准化处理(使输出均值为0,方差为1),可以加速训练过程并提高模型的稳定性。它通常在自注意力和前馈网络的输出上应用。
9 能否用Batch Normalizatioin?
在 Transformer 架构中,层归一化(Layer Normalization,简称 LayerNorm)是首选的归一化方法,主要用于模型内部的每一层之后。理论上,层归一化可以被批归一化(Batch Normalization,简称 BatchNorm)替换,但是这两种归一化技术在应用上有着本质的不同,这些差异导致了在 Transformer 中通常优先选择层归一化而不是批归一化。
层归一化(Layer Normalization)
- 层归一化是对每个样本的所有特征执行归一化操作,独立于其他样本。这意味着,无论批次大小如何,LayerNorm 的行为都是一致的。
- 在处理序列数据和自注意力机制时,LayerNorm 更加有效,因为它能够适应不同长度的输入,这在自然语言处理任务中尤为重要。
- LayerNorm 直接在每个样本的维度上工作,使得它在序列长度变化的情况下更为稳定。
批归一化(Batch Normalization)
- 批归一化是在一个小批量的维度上进行归一化,这意味着它依赖于批次中所有样本的统计信息。因此,BatchNorm的行为会随着批次大小和内容的变化而变化,这在训练和推理时可能导致不一致的表现。
- 在处理变长序列和自注意力结构时,BatchNorm可能不如 LayerNorm 高效,因为变长输入使得批次间的统计信息更加不稳定。
- BatchNorm在训练时计算当前批次的均值和方差,在推理时使用整个训练集的移动平均统计信息。这种依赖于批次统计信息的特性使得 BatchNorm在小批量或在线学习场景中表现不佳。
10 手写Transformer中的Encoder模块
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadSelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, queries):
N = queries.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]
# Split the embedding into self.heads different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = queries.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Attention mechanism
#attention = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
attention = torch.matmul(queries, keys.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
attention = F.softmax(attention / (self.embed_size ** (1 / 2)), dim=3)
out = torch.matmul(attention, values).reshape(N, query_len, self.heads * self.head_dim)
# out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadSelfAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size),
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query):
attention = self.attention(value, key, query)
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out
class Encoder(nn.Module):
def __init__(
self,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansion=forward_expansion,
)
for _ in range(num_layers)
]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = self.dropout(x)
for layer in self.layers:
out = layer(out, out, out)
return out
# Hyperparameters
embed_size = 512
num_layers = 6
heads = 8
device = "cuda" if torch.cuda.is_available() else "cpu"
forward_expansion = 4
dropout = 0.1
# Example
encoder = Encoder(embed_size, num_layers, heads, device, forward_expansion, dropout).to(device)