Flink理论—容错之状态后端(State Backends)
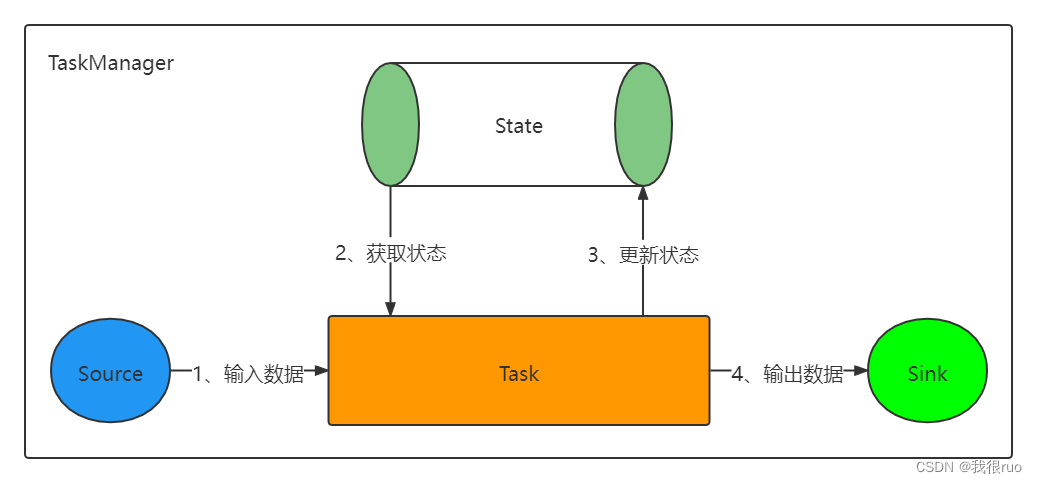
Flink 使用流重放和 检查点的组合来实现容错。检查点标记每个输入流中的特定点以及每个运算符的相应状态。通过恢复运算符的状态并从检查点点重放记录,可以从检查点恢复流数据流,同时保持一致性
容错机制不断地绘制分布式流数据流的快照。对于小状态的流式应用程序来说,这些快照非常轻量,可以频繁绘制,而不会对性能产生太大影响。流应用程序的状态存储在可配置的位置,通常存储在分布式文件系统中。
状态后端的分类
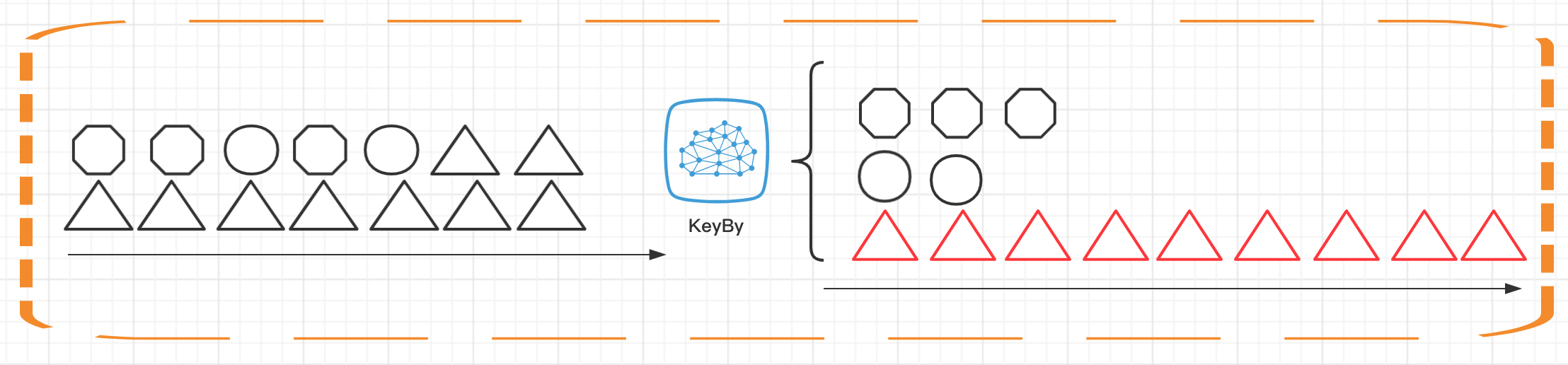
由 Flink 管理的 keyed state 是一种分片的键/值存储,每个 keyed state 的工作副本都保存在负责该键的 taskmanager 本地中。另外,Operator state 也保存在机器节点本地。Flink 定期获取所有状态的快照,并将这些快照复制到持久化的位置,例如分布式文件系统。
如果发生故障,Flink 可以恢复应用程序的完整状态并继续处理,就如同没有出现过异常。
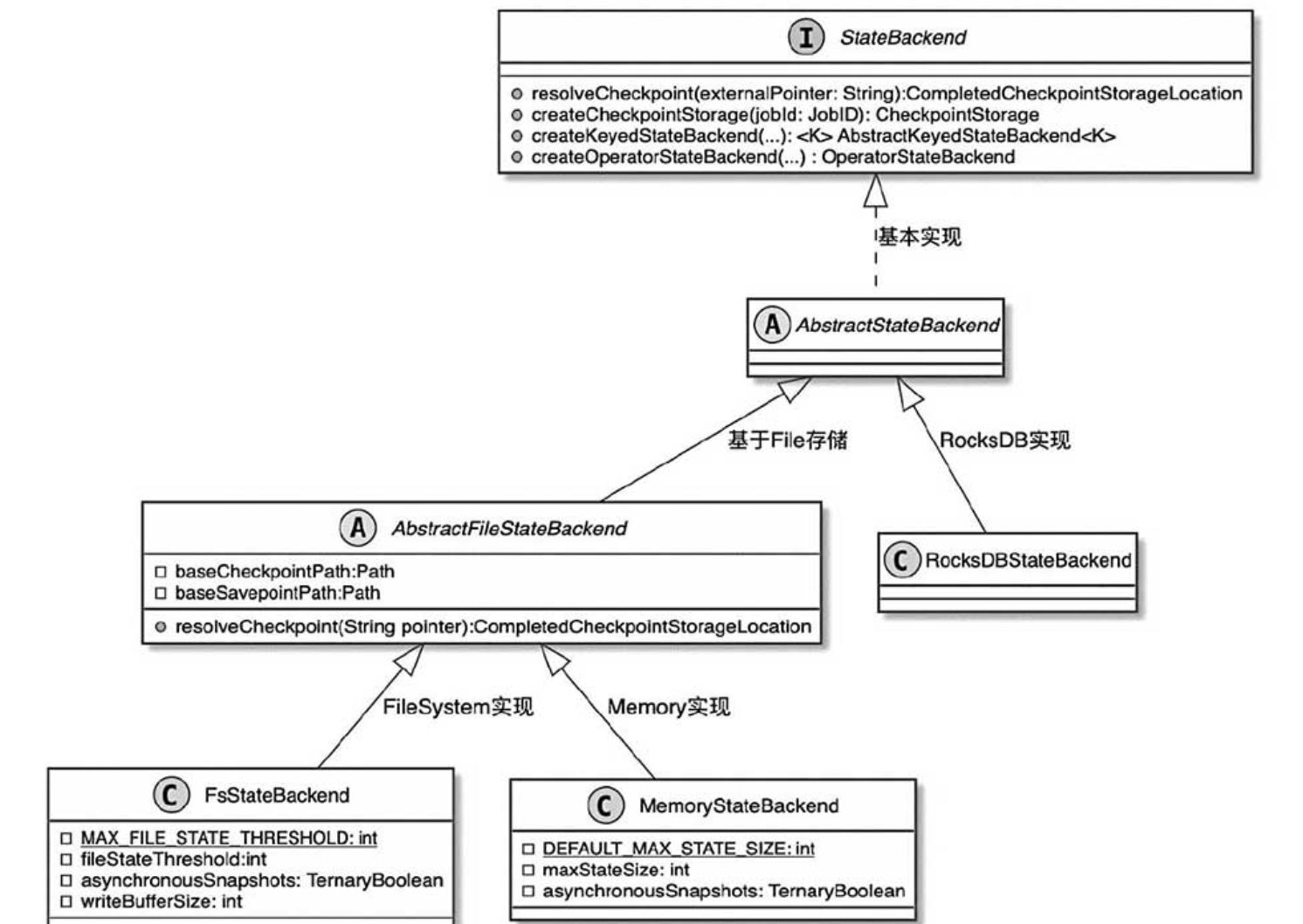
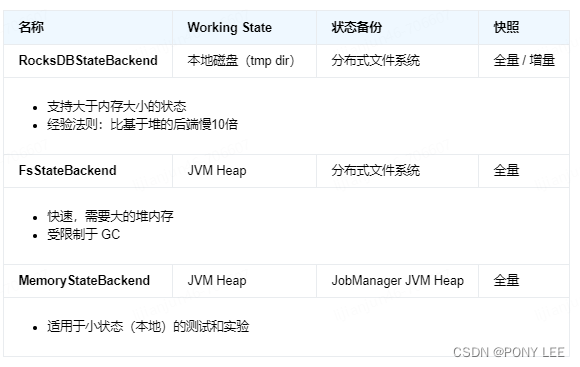
Flink 管理的状态存储在 state backend 中。Flink 有两种 state backend 的实现 – 一种基于 RocksDB 内嵌 key/value 存储将其工作状态保存在磁盘上的,另一种基于堆的 state backend,将其工作状态保存在 Java 的堆内存中。
这种基于堆的 state backend 有两种类型:
- FsStateBackend,将其状态快照持久化到分布式文件系统
- MemoryStateBackend,它使用 JobManager 的堆保存状态快照。
| 名称 | Working State | 状态备份 | 快照 |
|---|---|---|---|
| RocksDBStateBackend | 本地磁盘(tmp dir) | 分布式文件系统 | 全量 / 增量 |
| 支持大于内存大小的状态经验法则:比基于堆的后端慢10倍 | |||
| FsStateBackend | JVM Heap | 分布式文件系统 | 全量 |
| 快速,需要大的堆内存受限制于 GC | |||
| MemoryStateBackend | JVM Heap | JobManager JVM Heap | 全量 |
| 适用于小状态(本地)的测试和实验 |
当使用基于堆的 state backend 保存状态时,访问和更新涉及在堆上读写对象。但是对于保存在 RocksDBStateBackend 中的对象,访问和更新涉及序列化和反序列化,所以会有更大的开销。
但 RocksDB 的状态量仅受本地磁盘大小的限制。还要注意,只有 RocksDBStateBackend 能够进行增量快照,这对于具有大量变化缓慢状态的应用程序来说是大有裨益的。
所有这些 state backends 都能够异步执行快照,这意味着它们可以在不妨碍正在进行的流处理的情况下执行快照。
状态快照
Checkpoint Storage
Flink 定期对每个算子的所有状态进行持久化快照,并将这些快照复制到更持久的地方,例如分布式文件系统。 如果发生故障,Flink 可以恢复应用程序的完整状态并恢复处理,就好像没有出现任何问题一样。
这些快照的存储位置是通过作业_checkpoint storage_定义的。 有两种可用检查点存储实现:一种持久保存其状态快照 到一个分布式文件系统,另一种是使用 JobManager 的堆。
| 名称 | 状态备份 |
|---|---|
| FileSystemCheckpointStorage | 分布式文件系统 |
| 支持非常大的状态大小高度可靠推荐用于生产部署 | |
| JobManagerCheckpointStorage | JobManager JVM Heap |
| 适合小状态(本地)的测试和实验 |
定义
- 快照 – 是 Flink 作业状态全局一致镜像的通用术语。快照包括指向每个数据源的指针(例如,到文件或 Kafka 分区的偏移量)以及每个作业的有状态运算符的状态副本,该状态副本是处理了 sources 偏移位置之前所有的事件后而生成的状态。
- Checkpoint – 一种由 Flink 自动执行的快照,其目的是能够从故障中恢复。Checkpoints 可以是增量的,并为快速恢复进行了优化。
- 外部化的 Checkpoint – 通常 checkpoints 不会被用户操纵。Flink 只保留作业运行时的最近的 n 个 checkpoints(n 可配置),并在作业取消时删除它们。但你可以将它们配置为保留,在这种情况下,你可以手动从中恢复。
- Savepoint – 用户出于某种操作目的(例如有状态的重新部署/升级/缩放操作)手动(或 API 调用)触发的快照。Savepoints 始终是完整的,并且已针对操作灵活性进行了优化。
状态快照如何工作
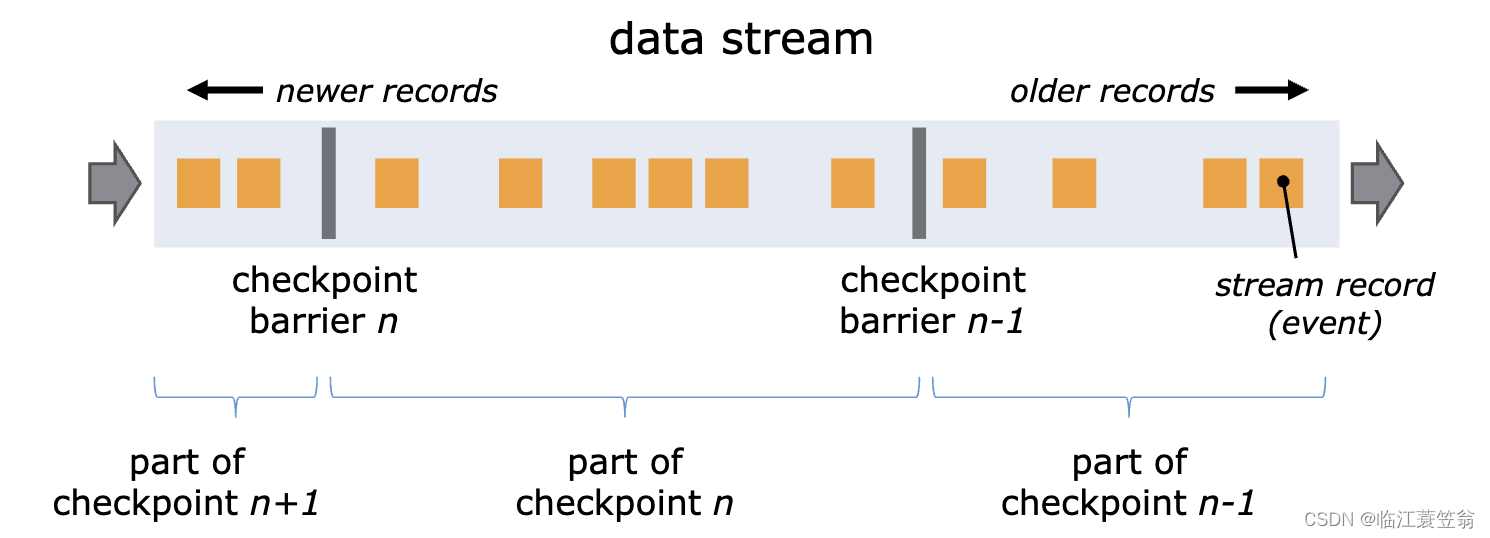
Flink 使用 Chandy-Lamport algorithm 算法的一种变体,称为异步 barrier 快照(asynchronous barrier snapshotting)。
当 checkpoint coordinator(job manager 的一部分)指示 task manager 开始 checkpoint 时,它会让所有 sources 记录它们的偏移量,并将编号的 checkpoint barriers 插入到它们的流中。这些 barriers 流经 job graph,标注每个 checkpoint 前后的流部分。
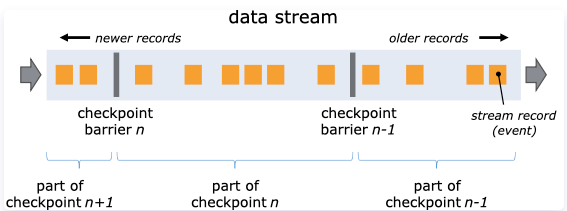
Checkpoint n 将包含每个 operator 的 state,这些 state 是对应的 operator 消费了严格在 checkpoint barrier n 之前的所有事件,并且不包含在此(checkpoint barrier *n*)后的任何事件后而生成的状态。
当 job graph 中的每个 operator 接收到 barriers 时,它就会记录下其状态。拥有两个输入流的 Operators(例如 CoProcessFunction)会执行 barrier 对齐(barrier alignment) 以便当前快照能够包含消费两个输入流 barrier 之前(但不超过)的所有 events 而产生的状态。
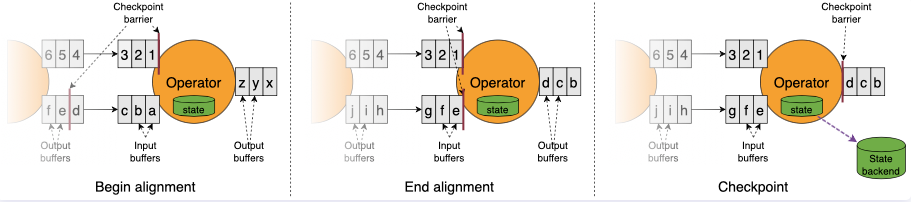
Flink 的 state backends 利用写时复制(copy-on-write)机制允许当异步生成旧版本的状态快照时,能够不受影响地继续流处理。只有当快照被持久保存后,这些旧版本的状态才会被当做垃圾回收。
精确性保证
确保精确一次(exactly once)
当流处理应用程序发生错误的时候,结果可能会产生丢失或者重复。Flink 根据你为应用程序和集群的配置,可以产生以下结果:
- Flink 不会从快照中进行恢复(at most once)
- 没有任何丢失,但是你可能会得到重复冗余的结果(at least once)
- 没有丢失或冗余重复(exactly once)
Flink 通过回退和重新发送 source 数据流从故障中恢复,当理想情况被描述为精确一次时,这并不意味着每个事件都将被精确一次处理。相反,这意味着 每一个事件都会影响 Flink 管理的状态精确一次。
Barrier 只有在需要提供精确一次的语义保证时需要进行对齐(Barrier alignment)。如果不需要这种语义,可以通过配置 CheckpointingMode.AT_LEAST_ONCE 关闭 Barrier 对齐来提高性能。
端到端精确一次
为了实现端到端的精确一次,以便 sources 中的每个事件都仅精确一次对 sinks 生效,必须满足以下条件:
- 你的 sources 必须是可重放的,并且
- 你的 sinks 必须是事务性的(或幂等的)
状态后端配置
我们在上面的内容中讲到了 Flink 的状态数据可以存在 JVM 的堆内存或者堆外内存中,当然也可以借助第三方存储。默认情况下,Flink 的状态会保存在 taskmanager 的内存中,Flink 提供了三种可用的状态后端用于在不同情况下进行状态后端的保存。
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
MemoryStateBackend
顾名思义,MemoryStateBackend 将 state 数据存储在内存中,一般用来进行本地调试用,我们在使用 MemoryStateBackend 时需要注意的一些点包括:
每个独立的状态(state)默认限制大小为 5MB,可以通过构造函数增加容量
状态的大小不能超过 akka 的 Framesize 大小
聚合后的状态必须能够放进 JobManager 的内存中
MemoryStateBackend 可以通过在代码中显示指定:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new MemoryStateBackend(DEFAULT_MAX_STATE_SIZE,false));
其中,new MemoryStateBackend(DEFAULT_MAX_STATE_SIZE,false) 中的 false 代表关闭异步快照机制。关于快照,我们在后面的课时中有单独介绍。
很明显 MemoryStateBackend 适用于我们本地调试使用,来记录一些状态很小的 Job 状态信息。
FsStateBackend
FsStateBackend 会把状态数据保存在 TaskManager 的内存中。CheckPoint 时,将状态快照写入到配置的文件系统目录中,少量的元数据信息存储到 JobManager 的内存中。
使用 FsStateBackend 需要我们指定一个文件路径,一般来说是 HDFS 的路径,例如,hdfs://namenode:40010/flink/checkpoints。
我们同样可以在代码中显示指定:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints", false));
FsStateBackend 因为将状态存储在了外部系统如 HDFS 中,所以它适用于大作业、状态较大、全局高可用的那些任务。
RocksDBStateBackend
RocksDBStateBackend 和 FsStateBackend 有一些类似,首先它们都需要一个外部文件存储路径,比如 HDFS 的 hdfs://namenode:40010/flink/checkpoints,此外也适用于大作业、状态较大、全局高可用的那些任务。
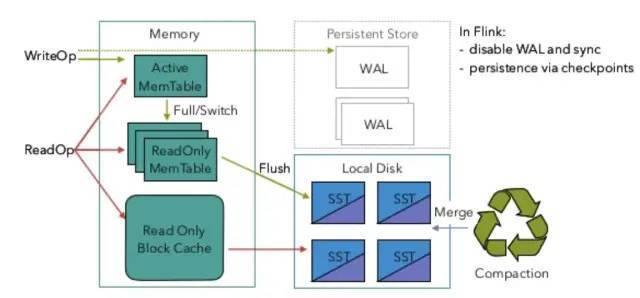
但是与 FsStateBackend 不同的是,RocksDBStateBackend 将正在运行中的状态数据保存在 RocksDB 数据库中,RocksDB 数据库默认将数据存储在 TaskManager 运行节点的数据目录下。
这意味着,RocksDBStateBackend 可以存储远超过 FsStateBackend 的状态,可以避免向 FsStateBackend 那样一旦出现状态暴增会导致 OOM,但是因为将状态数据保存在 RocksDB 数据库中,吞吐量会有所下降。
此外,需要注意的是,RocksDBStateBackend 是唯一支持增量快照的状态后端。