Flink State 设计详解
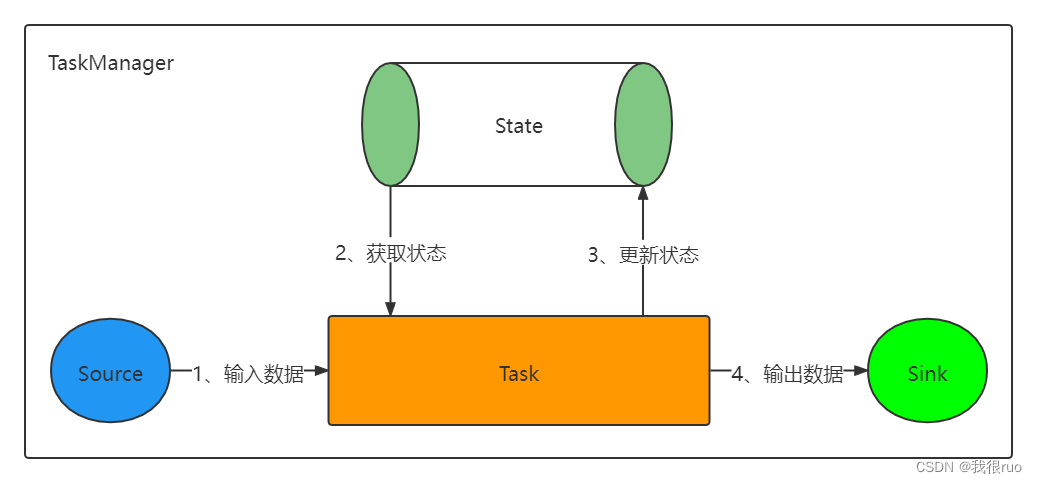
State 简单说,就是 Flink Job 的 Task 在运行过程中,产生的一些状态数据。这些状态数据,会辅助 Task 执行某些有状态计算,同时也涉及到 Flink Job 的重启状态恢复。所以,保存和管理每个 Task 的状态是非常重要的一种机制。这也是 Flink 有别于其他分布式计算引擎的最重要的区别。
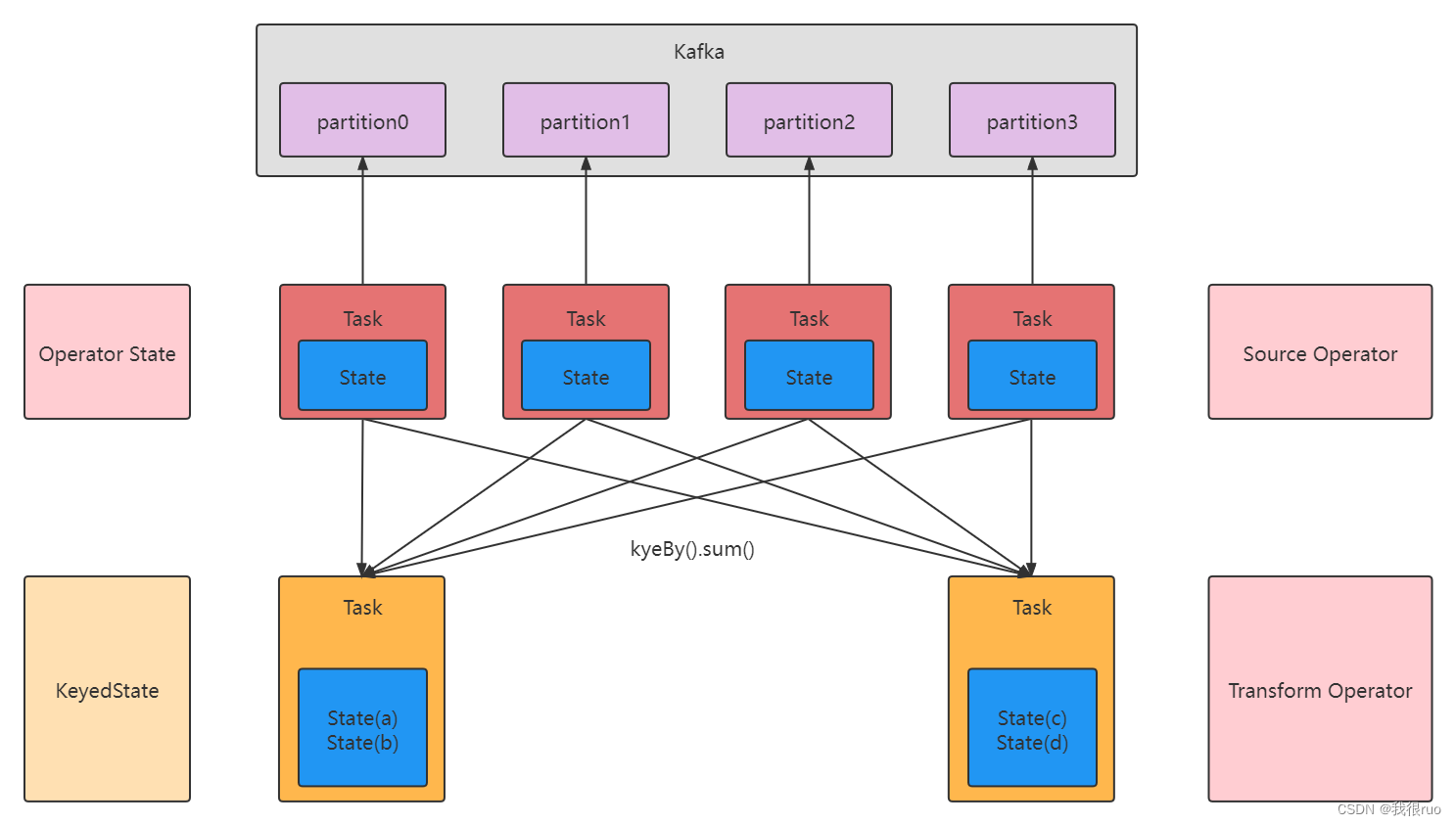
Flink 中的状态分为两类,Keyed State 和 Operator State 。
- Keyed State 和具体的 Key 是相绑定的,只能在 KeyedStream 上的函数和算子中使用。
- Opeartor State 则是和 Operator 的一个特定的并行实例相绑定的,例如 Kafka Connector 中,每一个并行的 Kafka Consumer 都在 Operator State 中维护当前 Consumer 订阅的 partiton 和 offset。
- Keyed State 也可以看作是 Operator State 的一种分区(partitioned)形式。
另外,对于 Keyed State 和 Operator State,在 Flink 中都可以以两种形式存在:原始状态 (raw state) 和 托管状态(managed state)。
- 托管状态:由 Flink 框架管理的状态,我们通常使用的就是这种。
- 原始状态:由用户自行管理状态具体的数据结构,框架在做 checkpoint 的时候,使用 byte[] 来读写状态内容,对其内部数据结构一无所知。
通常在 DataStream 上的状态推荐使用托管的状态,当实现一个用户自定义的 operator 时,会使用到原始状态。但是我们工作中一般不常用,所以我们不考虑。
Flink 的 State 类型,通过一张图来理解:
Keyed State 托管状态有五种类型:
- ValueState 单个值(Integer, String, Tuple10, Student)
- ListState 多个值的(List)
- MapState key-value 类型的值的
- ReducingState 聚合逻辑
- AggregatingState 聚合逻辑
Flink StateBackend 深入剖析和应用
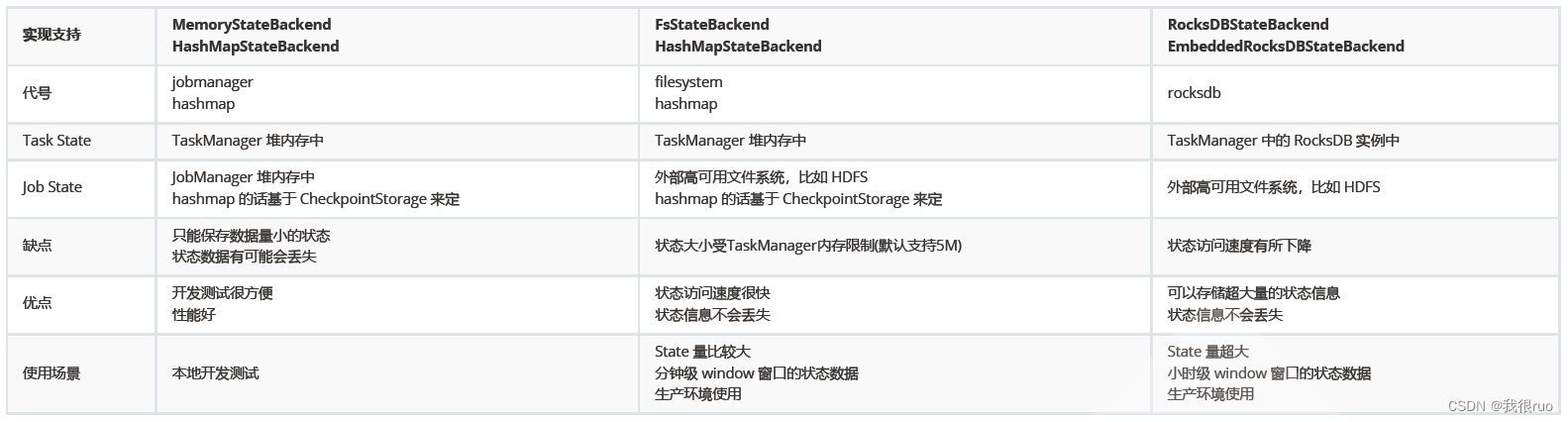
StateBackend 定义了状态是如何存储的,不同的 State Backend 会采用不同的方式来存储状态,核心入口是: StateBackend, Flink 提供了三种不同形式的存储后端,分别是 MemoryStateBackend, FsStateBackend 和 RocksDBStateBackend。
- MemoryStateBackend 会将工作状态(Task State)存储在 TaskManager 的内存中,将检查点(Job State)存储在 JobManager 的内存中,速度很快,不支持持久化,通常用来存储一些 state 量小的情况下的 state。这种方式是非常不安全的,且受限于 JobManager 的内存大小,主要在开发调试中使用。
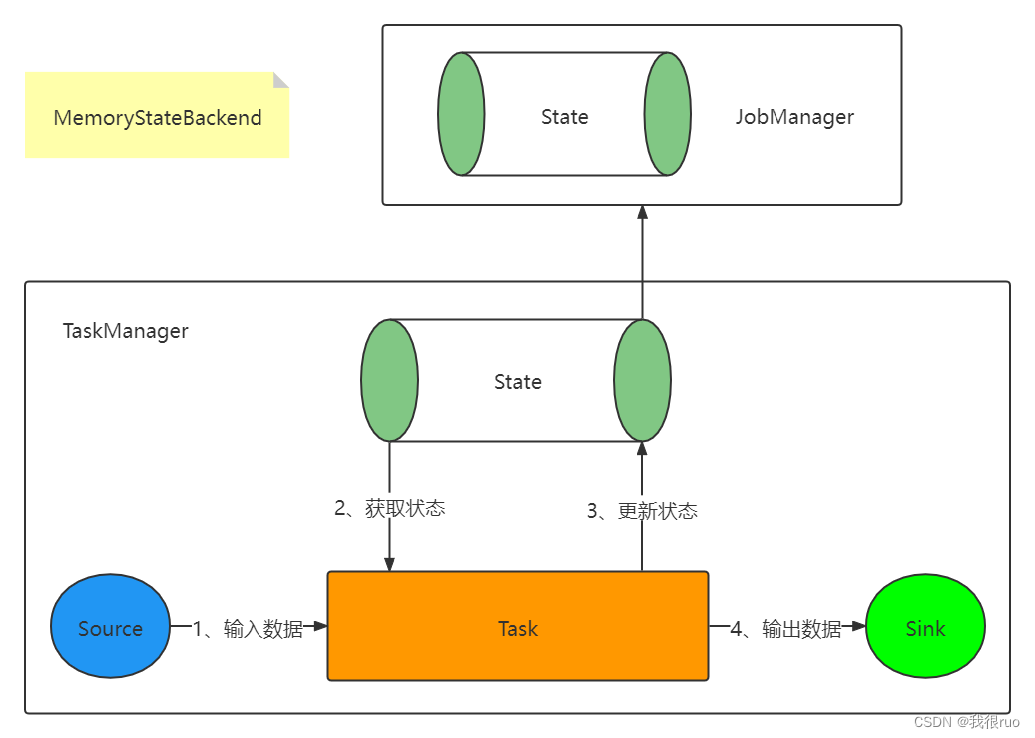
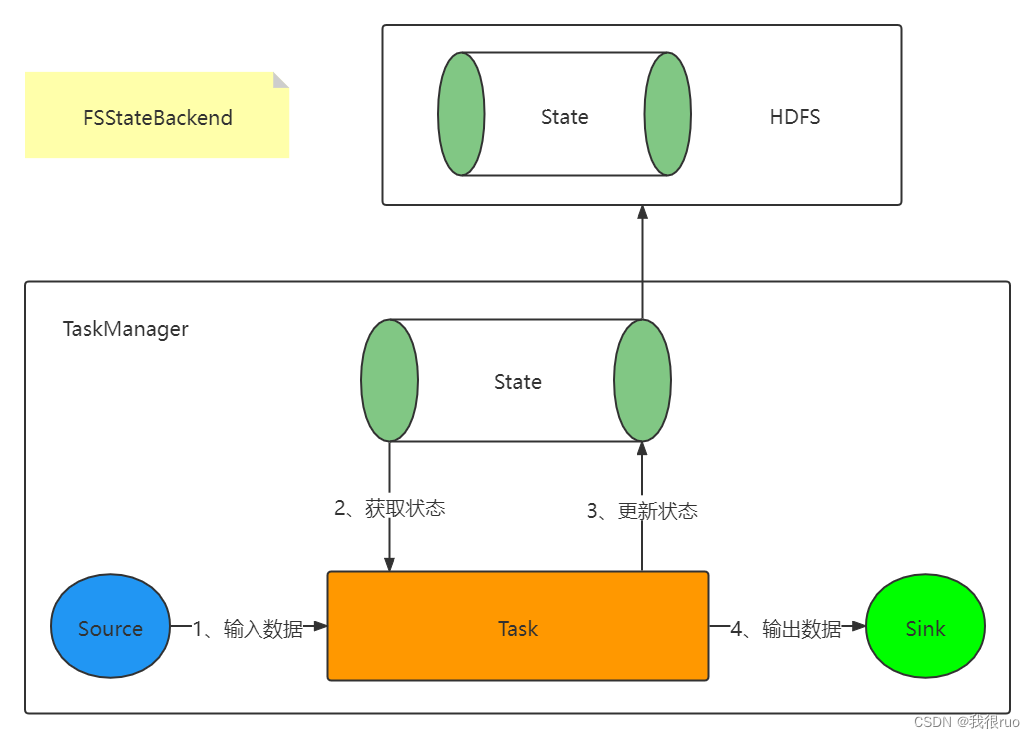
- FsStateBackend 会将工作状态存储在 TaskManager 的内存中,将检查点存储在文件系统中(通常是分布式文件系统),用来存储 state 量比较大的,window 窗口很长的一些 job 的 state 比较合适。生产环境常用此方案。
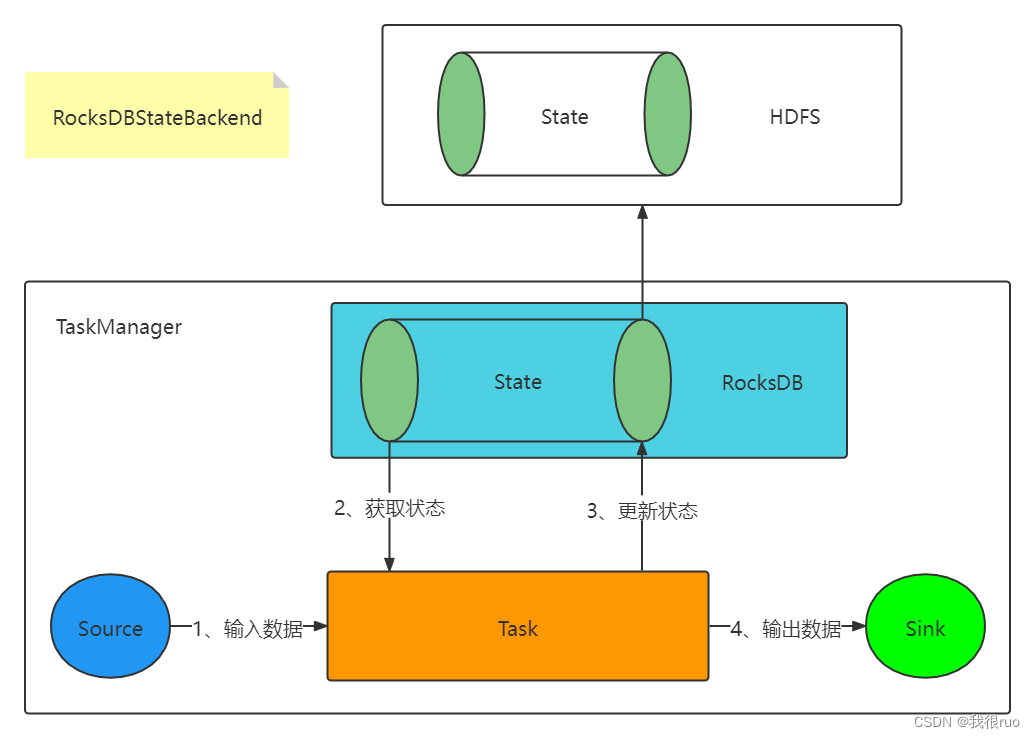
- RocksDBStateBackend 会把状态存储在 RocksDB 中,将检查点存储在文件系统中(类似 FsStateBackend),和 MemoryStateBackend 对比是速度快,GC 少,支持异步 Snapshot 持久化。用来存储 state 量比较大的,window 窗口很长的一些 job 的 state 比较合适。
综上所述,MemoryStateBackend 和 FsStateBackend 都是在内存中进行状态管理,所以可以获取较低的读写延迟,但会受限于 TaskManager 的内存大小;而 RocksDBStateBackend 直接将 State 存储到 RocksDB 数据库中,所以不受 JobManager 的内存限制,但会有读写延迟,同时 RocksDBStateBackend 支持增量备份,这是其他两个都不支持的特性。一般来说,如果不是对延迟有极高的要求,RocksDBStateBackend 是更好的选择。
Task State
- 细粒度的 State。
- 一个 Application 会运行很多的 Task, 每个 Task 运行的时候,都有自己的状态。
- 故障转移 = FailOverStrategy。
- 要么是存储在 TaskManager 的堆内存,要么是存储在 RocksDB 中。
Job State
- 粗粒度的 State。
- 在某个时候,通过某种手段(checkpoint)把这个 job 的所有 Task 的 state 做一个持久化,就形成了 job 的 state。
- 重启策略 = RestartStrategy。
- 要么是存储在 JobManager 的堆内存,要么是存储在 HDFS。
Flink StateBackend 使用方式
老版本写法(1.10 之前)
第一种:单任务调整 —— 修改当前任务代码
env.setStateBackend(new FsStateBackend("hdfs://hadoop33ha/flink/checkpoints"));
env.setStateBackend(new MemoryStateBackend());
env.setStateBackend(new RocksDBStateBackend(filebackend, true));
第二种:全局调整 —— 修改 flink-conf.yaml
state.backend: filesystem
state.checkpoints.dir: hdfs://hadoop33ha/flink/checkpoints
新版本写法(1.10 之后)
HashMapStateBackend
// HashMapStateBackend 替代 MemoryStateBackend
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置使用 HashMapStateBackend,Task State 存储在 TaskManager 的堆内存中
env.setStateBackend(new HashMapStateBackend());
// 还需要设置 checkpoint 的 state 存储方式:把 job State 存储在 JObManager 的堆内存中
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());
// HashMapStateBackend 替代 FsStateBackend
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置使用 HashMapStateBackend,Task State 存储在 TaskManager 的堆内存中
env.setStateBackend(new HashMapStateBackend());
// 设置一个外部高可用文件系统的 存储路径用来保存 Job State
env.getCheckpointConfig().setCheckpointStorage("hdfs://checkpoints");
EmbeddedRocksDBStateBackend
// EmbeddedRocksDBStateBackend
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置使用 EmbeddedRocksDBStateBackend,Task State 存储在 RocksDB 中(内存+磁盘)
env.setStateBackend(new EmbeddedRocksDBStateBackend());
// 设置一个外部高可用文件系统的 存储路径用来保存 Job State
env.getCheckpointConfig().setCheckpointStorage("hdfs://checkpoints");
如果使用 RocksDB 的方式,需要引入依赖:
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-statebackend-rocksdb -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.12</artifactId>
<version>1.14.2</version>
</dependency>
Flink Checkpoint 算法原理深入剖析
概述
Flink 提供了 Exactly once 特性,是依赖于带有 barrier 的分布式快照 + 可部分重发的数据源 + 幂等写入/2PC 功能实现的。
Flink 容错机制的核心是对数据流做连续的分布式快照(snapshots),我们把每一次 take snapshot 动作称之为 Checkpoint。Checkpoint 是 Flink 实现容错机制最核心的功能,它能够根据配置周期性地基于 Stream 中各个 Operator/Task 的状态来生成快照,从而将这些状态数据定期持久化存储下来,当 Flink 程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。
Flink 的 Checkpoint 机制基于 chandy-lamport 算法,在某一个时刻,对一个 Flink Job 的所有 Task 做一个快照拍摄(逻辑解释),并且将快照保存在 内存/磁盘 中永久保存,这样子,如果 Flink Job 重启恢复,就可以从故障前最近一次的成功快照中进行状态恢复,从而实现保证 Flink 数据流式数据的一致性。当然,为了配合 Flink 能实现状态快照,并且 job 状态恢复,必须数据源具备数据回放的功能。
实现 Checkpoint 的核心是:Stream Barrier,它和普通消息无异,Stream barrier 作为一种标记信息插入到数据流和正常数据一起流动。barriers 永远不会超过记录,数据流严格有序,barrier 将数据流中的记录隔离成一系列的记录集合,并将一些集合中的数据加入到当前的快照中,而另一些数据加入到下一个快照中。每个 barrier 都带有快照的 ID,并且 barrier 之前的记录都进入了该快照。
Flink 应用程序中的消息抽象其实是:BufferOrEvent(DataStream 数据流中的每条 记录 的数据抽象对象),它包含两个方面的信息:
01、Buffer:正常的待处理的数据
02、Event:嵌入到数据流中增强引擎流处理能力的特殊消息,包含 CheckpointBarrier 和 WaterMark
03、一个 DataStream 数据流中的数据其实有多种类型: data,checkpointbarrier,watermark
Flink 的 Checkpoint Coordinator 在需要触发检查点的时候要求数据源向数据流中注入 Stream Barrier(具体实现: CheckpointBarrier(checkpointID, timestamp)),当执行 Task 的 Operator 从他所有的 InputChannel 中都收到了 Stream Barrier 则会触发当前的 Operator 的快照拍摄,并向其下游 Operator 发送 Stream Barrier。当所有的 SinkOperator 都反馈完成了快照之后, Flink Checkpoint Coordinator 认为 Checkpoint 创建成功。
官网介绍图
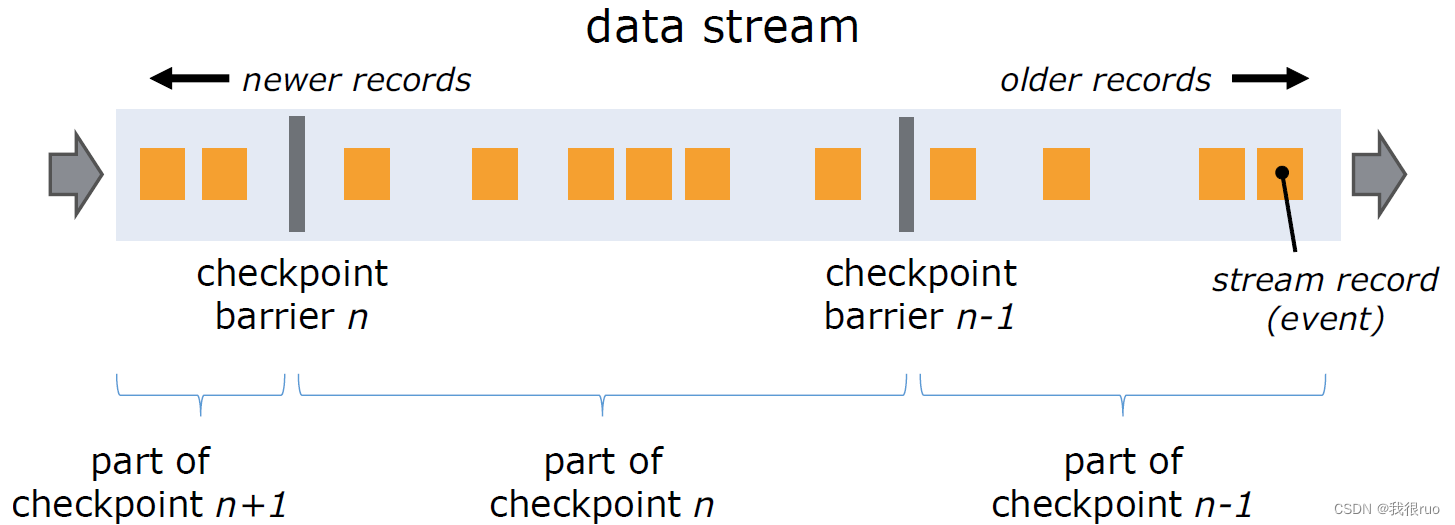
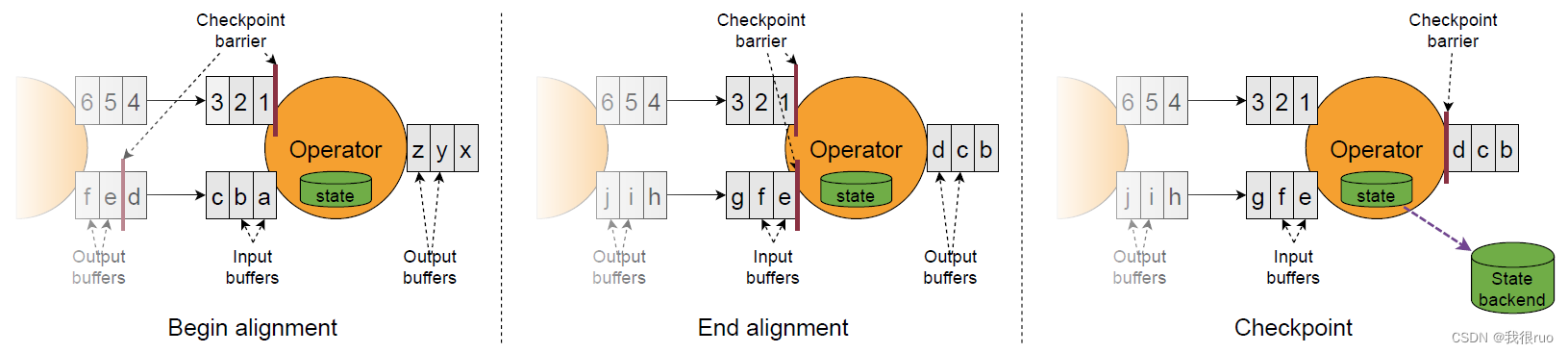
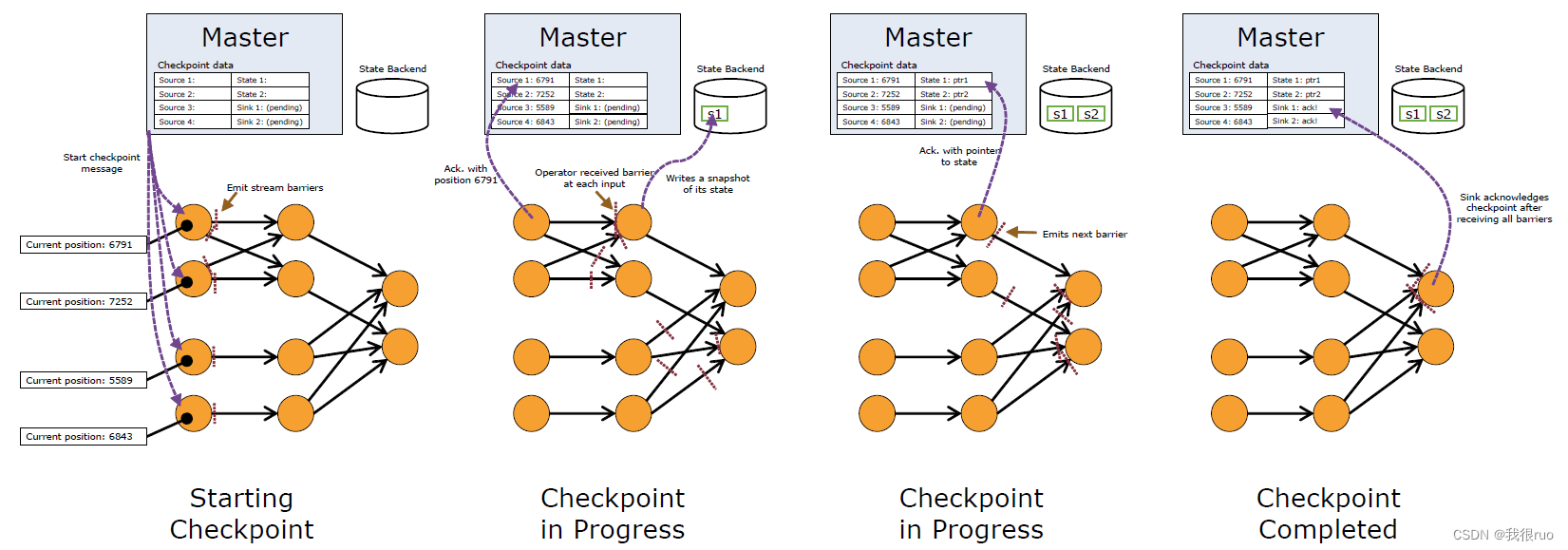
Chandy-Lamport 算法详细图解
任务开启
JobMananger 发起 Checkpoint
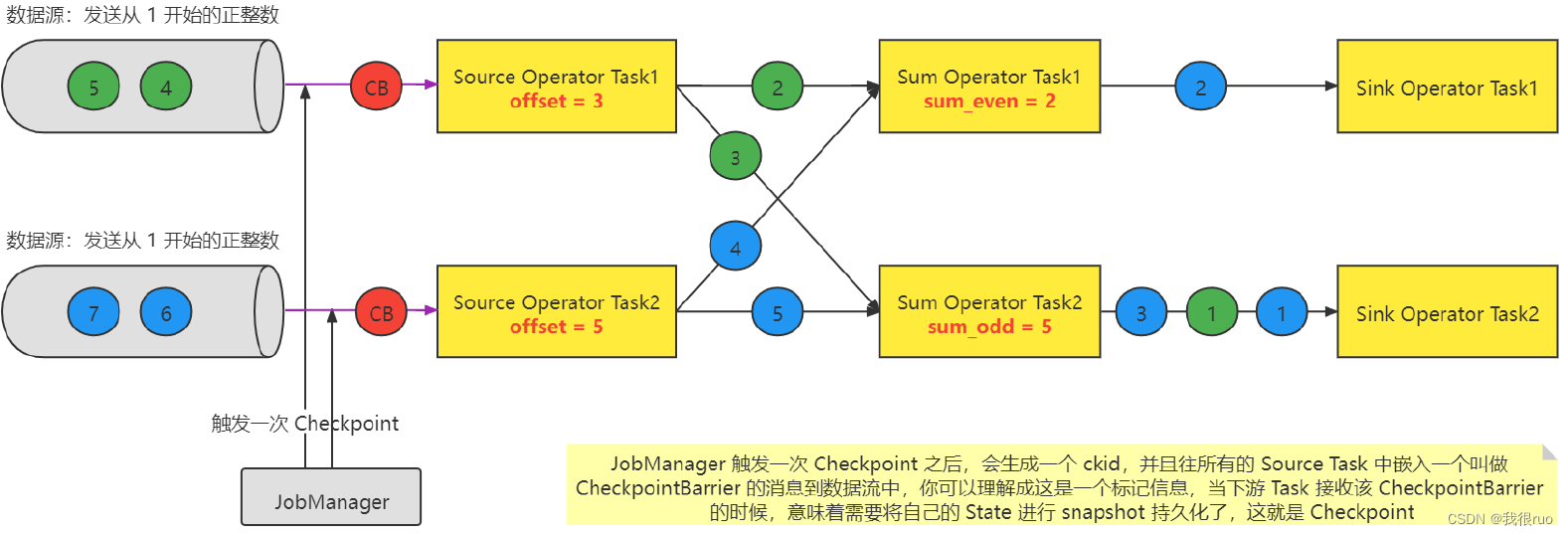
Source 上报 Checkpoint
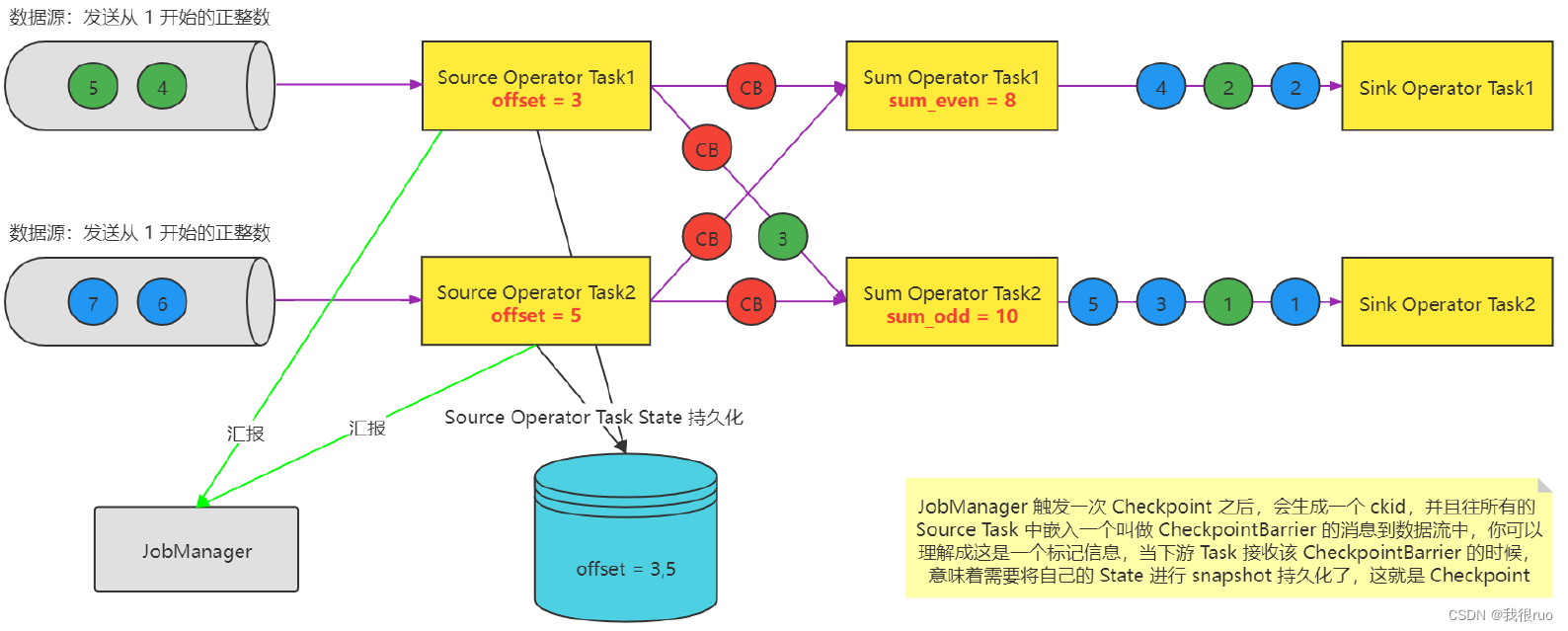
Task 的数据处理
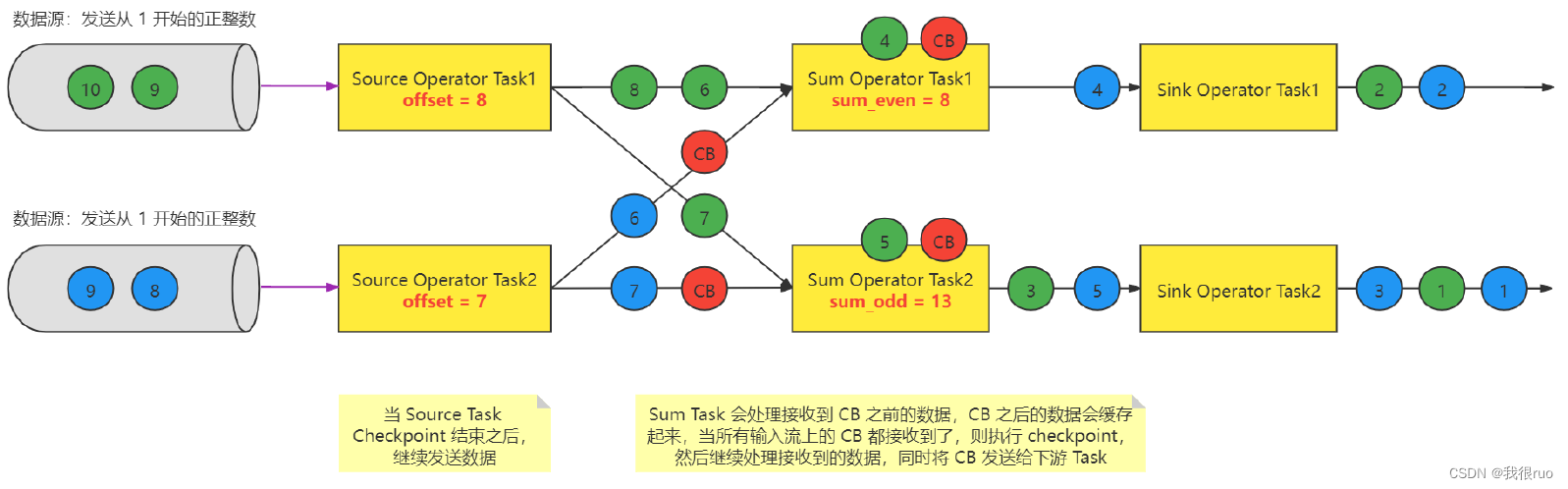
CheckpointBarrier 对齐
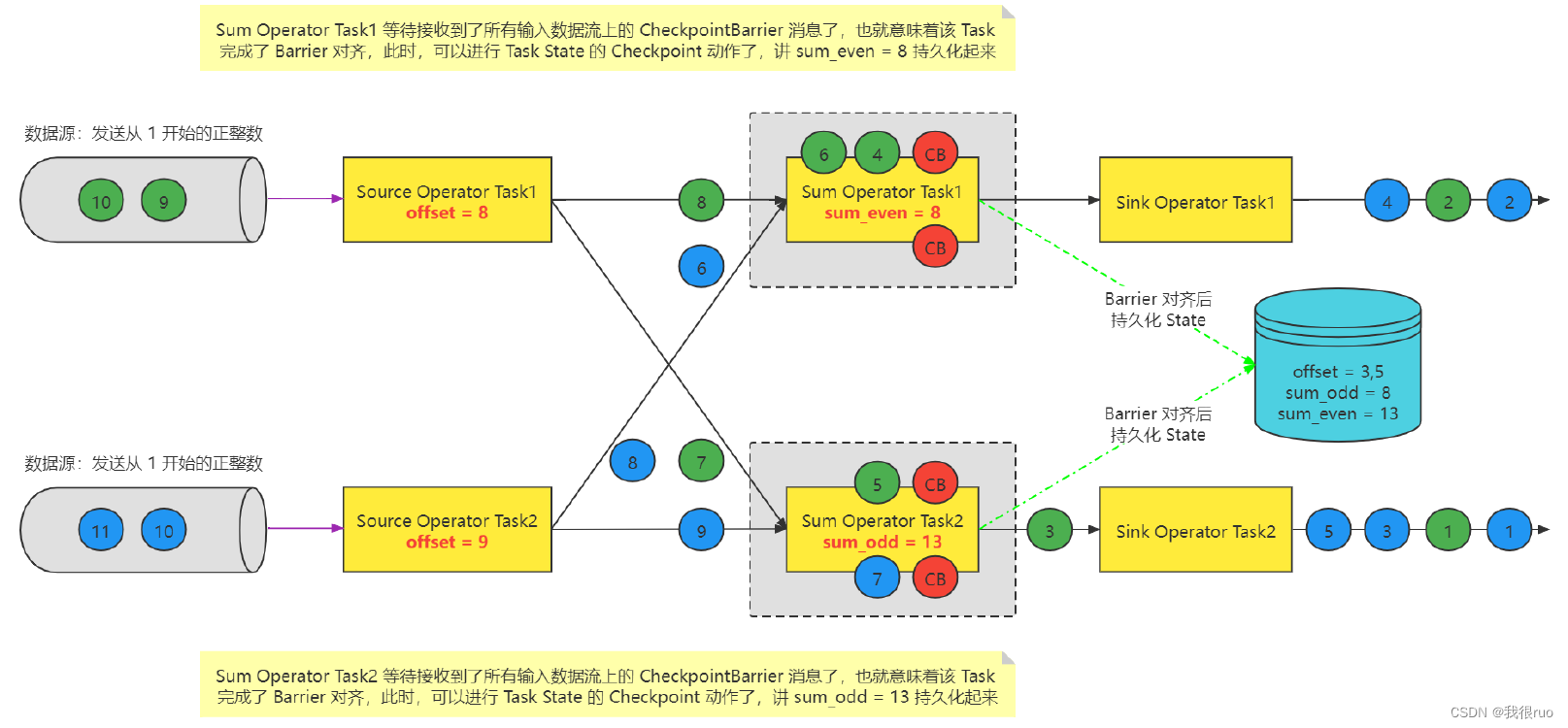
Task 处理缓存数据
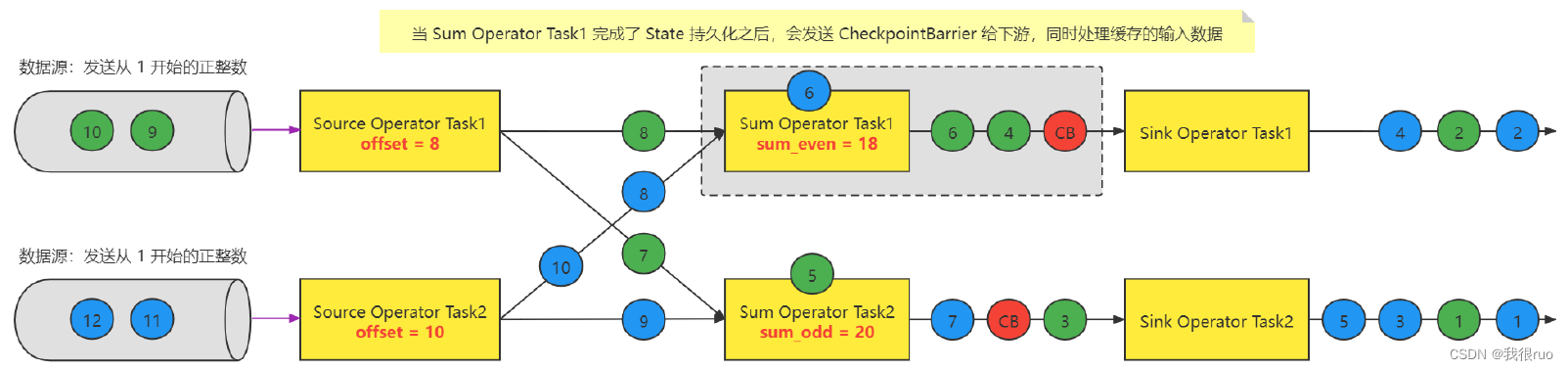
Sink 上报 Checkpoint
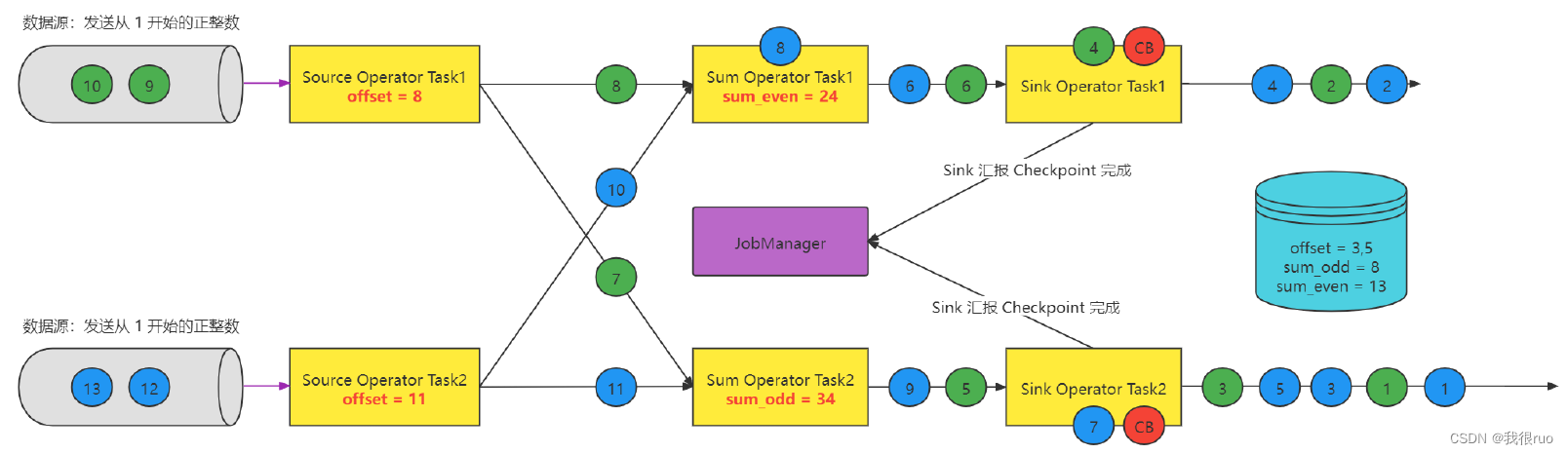
简单阐述 Checkpoint 的执行:
- 微观:每个 Task 只要接收到了所有的 CheckpointBarrier 就完成一个该 Task 自己的 Checkpoint(事实上,就是把 State 做持久化),该 Task 会不停的接受到 CB ,同时也是每次接收到 CB 的时候,就会执行一次 checkpoint,当前 Task 要不要执行 Checkpoint 跟其他 Task 没有任何关系; Task 自己做 checkpoint 唯一的条件:当前这个 Task 的所有的 输入流上的 同一次 checkpoint(拥有相同 checkponitID) Barrier 都被收到了之后就会执行 checkpoint。
- 宏观:所有的 Source Task 和 Sink Task 都得向 JobManager 中的一个 CheckpointCoordinator 去汇报,如果 CheckpointCoordinator 通过统计,发现某一次 checkpoint(有一个全局唯一的 checkpointID)的所有 Source Task 和 Sink Task 都汇报成功,则意味着这次 checkpoint 就是一次成功的 checkpoint。
Flink Checkpoint 源码级配置详解
Flink 默认 Checkpoint 功能是 disabled 的,想要使用的时候需要先启用,checkpoint 开启之后,checkPointMode 有两种,Exactly-once 和 At-least-once,默认的 checkPointMode 是 Exactly-once,Exactly-once 对于大多数应用来说是最合适的。At-least-once 可能用在某些延迟超低的应用程序(始终延迟为几毫秒)。
// 默认 checkpoint 功能是 disabled 的,想要使用的时候需要先启用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 在 StreamExecutionEnvironment 里面会有一个变量(存储配置的容器)
// 每隔 1000ms 进行启动一个检查点【设置checkpoint的周期】
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为 exactly-once (这是默认值) 端到端的 exactly once
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 检查点必须在一分钟内完成,或者被丢弃【checkpoint 的超时时间】
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同时允许多少个 checkpoint, 推荐不要改,就是 1 ,不仅就是1,还是设置俩次checkpoint 之间的时间间隔
// 假设每 5 分钟做一次 checkpoint : 一次 checkpoint 需要 6 分钟, 同时会运行两个 Checkpoint
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 确保检查点之间有至少 500ms 的间隔【checkpoint 最小间隔】
// 不仅不要同时运行多个 Checkpoint 而且最好还要设置两次 checkpoint 的一个停顿时间
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 表示一旦 Flink 处理程序被 cancel 后,会保留 Checkpoint 数据,以便根据实际需要恢复到指定的 Checkpoint【详细解释见备注】
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
上述代码中,设置的关于 checkpoint 的参数,最终都是给 Jobmanager 中的 CheckpointCoordinator 去使用。
每个版本的参数有点不太一样,具体参照源码中的参数和解释:
// 该方法就是帮助我们去解析 checkpoint 有关的所有的配置
public class CheckpointConfig{
public void configure(ReadableConfig configuration) {
// TODO_MA 马中华 注释: checkpoint 的模式 = CheckpointingMode.EXACTLY_ONCE
configuration.getOptional(ExecutionCheckpointingOptions.CHECKPOINTING_MODE)
.ifPresent(this::setCheckpointingMode);
// TODO_MA 马中华 注释: 两次 cehckpoint 之间的间隔时间: checkpoint
// TODO_MA 马中华 注释: 可以通过 execution.checkpointing.interval 这个参数来配置
configuration.getOptional(ExecutionCheckpointingOptions.CHECKPOINTING_INTERVAL)
.ifPresent(i -> this.setCheckpointInterval(i.toMillis()));
// TODO_MA 马中华 注释: execution.checkpointing.timeout = 10min
configuration.getOptional(ExecutionCheckpointingOptions.CHECKPOINTING_TIMEOUT)
.ifPresent(t -> this.setCheckpointTimeout(t.toMillis()));
// TODO_MA 马中华 注释: execution.checkpointing.max-concurrent-checkpoints = 1
configuration.getOptional(ExecutionCheckpointingOptions.MAX_CONCURRENT_CHECKPOINTS)
.ifPresent(this::setMaxConcurrentCheckpoints);
// TODO_MA 马中华 注释: execution.checkpointing.min-pause = Duration.ZERO
configuration.getOptional(ExecutionCheckpointingOptions.MIN_PAUSE_BETWEEN_CHECKPOINTS)
.ifPresent(m -> this.setMinPauseBetweenCheckpoints(m.toMillis()));
// TODO_MA 马中华 注释: execution.checkpointing.tolerable-failed-checkpoints 没有默认值
configuration.getOptional(ExecutionCheckpointingOptions.TOLERABLE_FAILURE_NUMBER)
.ifPresent(this::setTolerableCheckpointFailureNumber);
// TODO_MA 马中华 注释: execution.checkpointing.externalized-checkpoint-retention 没有默认值
configuration.getOptional(ExecutionCheckpointingOptions.EXTERNALIZED_CHECKPOINT)
.ifPresent(this::enableExternalizedCheckpoints);
// TODO_MA 马中华 注释: execution.checkpointing.unaligned = false
configuration.getOptional(ExecutionCheckpointingOptions.ENABLE_UNALIGNED)
.ifPresent(this::enableUnalignedCheckpoints);
// TODO_MA 马中华 注释: execution.checkpointing.recover-without-channel-state.checkpoint-id = -1
configuration.getOptional(ExecutionCheckpointingOptions.CHECKPOINT_ID_OF_IGNORED_IN_FLIGHT_DATA)
.ifPresent(this::setCheckpointIdOfIgnoredInFlightData);
// TODO_MA 马中华 注释: execution.checkpointing.aligned-checkpoint-timeout = 0
configuration.getOptional(ExecutionCheckpointingOptions.ALIGNED_CHECKPOINT_TIMEOUT)
.ifPresent(this::setAlignedCheckpointTimeout);
// TODO_MA 马中华 注释: execution.checkpointing.unaligned.forced = false
configuration.getOptional(ExecutionCheckpointingOptions.FORCE_UNALIGNED)
.ifPresent(this::setForceUnalignedCheckpoints);
}
}
默认情况下,如果设置了 Checkpoint 选项,则 Flink 只保留最近成功生成的 1 个 Checkpoint,而当 Flink 程序失败时,可以从最近的这个 Checkpoint 来进行恢复。但是,如果我们希望保留多个 Checkpoint,并能够根据实际需要选择其中一个进行恢复,这样会更加灵活,比如,我们发现最近 4 个小时数据记录处理有问题,希望将整个状态还原到 4 小时之前 Flink 可以支持保留多个 Checkpoint,需要在 Flink 的配置文件 conf/flink-conf.yaml 中,添加如下配置,指定最多需要保存
Checkpoint 的个数:
state.checkpoints.num-retained: 5
这样设置以后就查看对应的 Checkpoint 在 HDFS 上存储的文件目录
hdfs dfs -ls hdfs://hadoop33ha/flink/checkpoints
如果希望回退到某个 Checkpoint 点,只需要指定对应的某个 Checkpoint 路径即可实现。
如果 Flink 程序异常失败,或者最近一段时间内数据处理错误,我们可以将程序从某一个 Checkpoint 点进行恢复。
bin/flink run -s hdfs://hadoop33ha/flink/checkpoints/467e17d2cc343e6c56255d222bae3421/chk-56/_metadata flink-job.jar
程序正常运行后,还会按照 Checkpoint 配置进行运行,继续生成 Checkpoint 数据。
当然恢复数据的方式还可以在自己的代码里面指定 Checkpoint 目录,这样下一次启动的时候即使代码发生了改变就自动恢复数据了。
Flink SavePoint 企业生产实践方案
SavePoint 可以认为是用户手动触发的 checkpoint , 而 checkpoint 是系统自动触发的一个定期执行的工作。
SavePoint 是一个重量级的 Checkpoint,你可以把它当做在某个时间点程序状态全局镜像,以后程序在进行升级,或者修改并发度等情况,还能从保存的状态位继续启动恢复。可以保存数据源 offset,Operator 操作状态等信息,可以从应用在过去任意做了 SavePoint 的时刻开始继续消费。

SavePoint 由用户手动执行,是指向 Checkpoint 的指针,不会过期,在集群升级/代码迁移等情况下使用。
注意:为了能够在作业的不同版本之间以及 Flink 的不同版本之间顺利升级,强烈推荐程序员通过 uuid(String) 方法手动的给算子赋予 ID,这些 ID 将用于确定每一个算子的状态范围。如果不手动给各算子指定 ID,则会由 Flink 自动给每个算子生成一个 ID。只要这些 ID 没有改变就能从保存点(savepoint)将程序恢复回来。
而这些自动生成的 ID 依赖于程序的结构,并且对代码的更改是很敏感的。因此,强烈建议用户手动的设置 ID。
Flink SavePoint 的使用
1:在 flink-conf.yaml 中配置 Savepoint 存储位置
不是必须设置,但是设置后,后面创建指定 Job 的 Savepoint 时,可以不用在手动执行命令时指定 Savepoint 的位置
state.savepoints.dir: hdfs://hadoop33ha/flink1142/savepoints
2:触发一个 Savepoint【直接触发或者在 cancel 的时候触发】
停止程序:bin/flink cancel -s [targetDirectory] jobId [-yid yarnAppId]【针对 on yarn 模式需要指定 -yid 参数】
3:从指定的 Savepoint 启动 job
bin/flink run -s savepointPath [runArgs]
Flink RestartStrategy 和 FailoverStrategy
重启策略概述
Flink 支持不同的重启策略,以在故障发生时控制作业如何重启,集群在启动时会伴随一个默认的重启策略,在没有定义具体重启策略时会使用该默认策略。 如果在工作提交时指定了一个重启策略,该策略会覆盖集群的默认策略,默认的重启策略可以通过 Flink 的配置文件 flink-conf.yaml 指定。
配置参数 RestartStrategyOptions.restart-strategy 定义了哪个策略被使用。
常用的重启策略
- 固定间隔 (Fixed delay)
- 指数间隔 (Exponential delay)
- 失败率 (Failure rate)
- 无重启 (No restart)
如果没有启用 checkpointing,则使用无重启 (no restart) 策略。 如果启用了 checkpointing,但没有配置重启策略,则使用固定间隔 (fixed-delay) 策略, 尝试重启次数默认值是:Integer.MAX_VALUE,重启策略可以在 flink-conf.yaml 中配置,表示全局的配置。也可以在应用代码中动态指定,会覆盖全局配置。
重启策略详解
固定间隔 (Fixed delay)
第一种:全局配置 flink-conf.yaml
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
第二种:应用代码设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(10, TimeUnit.SECONDS) // delay
));
指数间隔 (Exponential delay)
第一种:全局配置 flink-conf.yaml
restart-strategy: fixed-delay: exponential-delay
restart-strategy.exponential-delay.initial-backoff: 10 s
restart-strategy.exponential-delay.max-backoff: 2 min
restart-strategy.exponential-delay.backoff-multiplier: 2.0
restart-strategy.exponential-delay.reset-backoff-threshold: 10 min
restart-strategy.exponential-delay.jitter-factor: 0.1
第二种:应用代码设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.exponentialDelayRestart(
Time.milliseconds(1),
Time.milliseconds(1000),
1.1, // exponential multiplier
Time.milliseconds(2000), // threshold duration to reset delay to its initial value
0.1 // jitter
));
失败率 (Failure rate)
第一种:全局配置 flink-conf.yaml
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
第二种:应用代码设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // max failures per interval
Time.of(5, TimeUnit.MINUTES), //time interval for measuring failure rate
Time.of(10, TimeUnit.SECONDS) // delay
));
无重启 (No restart)
第一种:全局配置 flink-conf.yaml
restart-strategy: none
第二种:应用代码设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
FailoverStrategy 故障转移策略
FailoverStrategy 有两种实现:
- Restart All Failover Strategy,代号 full,表示 Application 的 Task 出现异常,则直接全部 Task 重启。
- Restart Pipelined Region Failover Strategy,代号 region,这是默认实现,如果一个 Task 出现异常,则重启最小代价的 Region 集合。
flink 中通过 JobManagerOptions.EXECUTION_FAILOVER_STRATEGY = jobmanager.execution.failover-strategy 来配置,Flink 在判断需要重启的 Region 时,采用了以下的判断逻辑:
- 发生错误的 Task 所在的 Region 需要重启;
- 如果当前 Region 的依赖数据出现损坏或者部分丢失,那么生产数据的 Region 也需要重启;
- 为了保证数据一致性,当前 Region 的下游 Region 也需要重启。