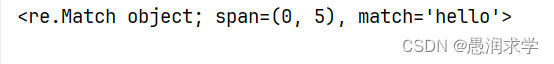文章目录
01match方法的使用.py
02常用字符的使用.py
03匹配手机号码.py
04重复数量符号.py
05重复数量限定符的使用.py
06转义字符的使用.py
07边界字符的使用.py
08search方法的使用.py
09匹配多个字符.py
10择一匹配符合列表使用差异.py
11匹配分组.py
12其他函数的使用.py
13贪婪模式和非贪婪模式.py
import re
s= 'hello python'
pattern= 'hello'
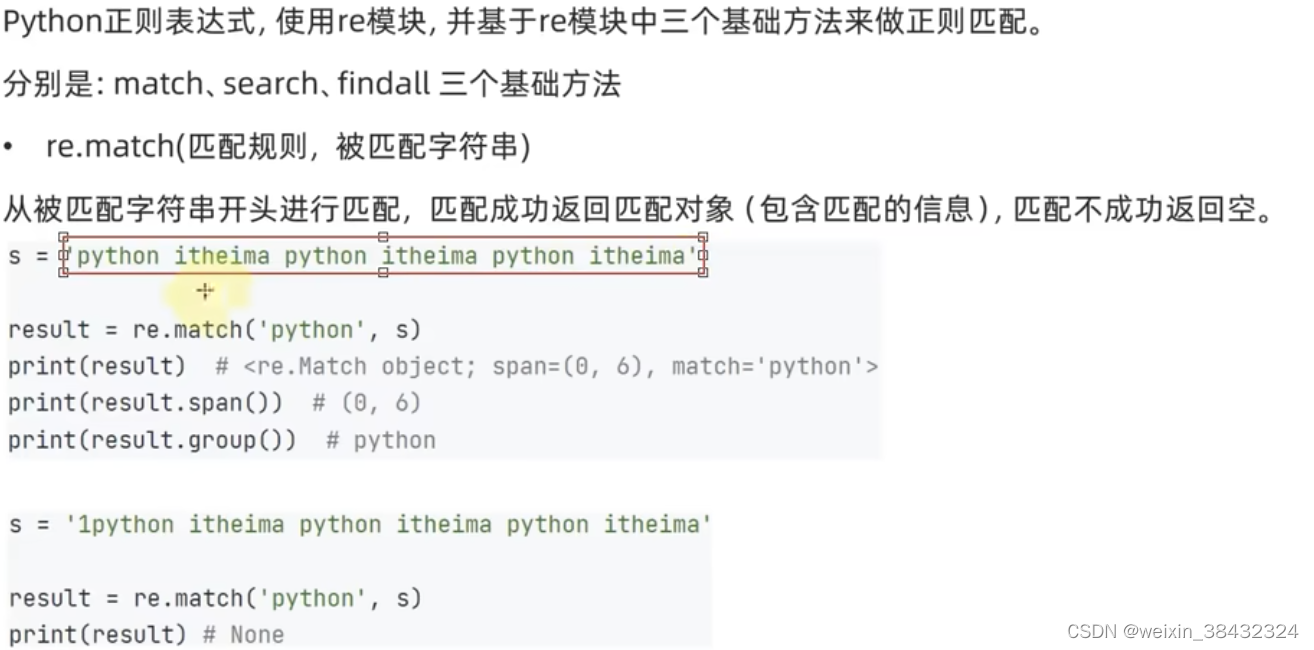
o= re. match ( pattern, s)
print ( o)
print ( dir ( o) )
print ( o. group( ) )
print ( o. span( ) )
print ( o. start( ) )
print ( 'flags参数的使用' )
s= 'hello python'
pattern= 'Hello'
o= re. match ( pattern, s, flags= re. I)
print ( o)
print ( o. group( ) )
'''
. 匹配任意一个字符(除了\n)
[] 匹配列表中的字符
\w 匹配字母、数字、下划线,即a-z,A-Z,0-9,_
\W 匹配不是字母、数字、下划线
\s 匹配空白字符,即空格(\n,\t)
\S 匹配不是空白的字符
\d 匹配数字,即0-9
\D 匹配非数字的字符
'''
import re
print ( '--------.的使用--------' )
s= 'a'
s= 'A'
s= '8'
s= '_'
s= '\n'
pattern= '.'
o= re. match ( pattern, s)
print ( o)
print ( '---------\d的使用------------' )
s= '0'
s= '5'
s= '9'
s= 'a'
pattern= '\d'
o= re. match ( pattern, s)
print ( o)
print ( '---------\D的使用------------' )
s= '0'
s= '9'
s= 'a'
pattern= '\D'
o= re. match ( pattern, s)
print ( o)
print ( '--------\s的使用-----------' )
s= ' '
s= '\n'
s= '\t'
s= '_'
pattern= '\s'
o= re. match ( pattern, s)
print ( o)
print ( '--------\S的使用-----------' )
s= ' '
s= '\n'
s= '\t'
s= '_'
pattern= '\S'
o= re. match ( pattern, s)
print ( o)
print ( '---------\w的使用------------' )
s= 'z'
s= 'A'
s= '8'
s= '_'
s= '#'
pattern= '\w'
o= re. match ( pattern, s)
print ( o)
print ( '---------\W的使用------------' )
s= 'z'
s= '8'
s= '_'
s= '#'
s= '+'
pattern= '\W'
o= re. match ( pattern, s)
print ( o)
print ( '---------[]的使用----------' )
pattern= '[2468]'
s= '2'
s= '3'
s= '4'
s= '6'
o= re. match ( pattern, s)
print ( o)
import re
pattern= '1[35789]\d\d\d\d\d\d\d\d\d'
s= '13456788765'
o= re. match ( pattern, s)
print ( o)
'''
* :0次或多次
?:0次或1次
+:至少1次
{m}:重复m次
{m,n}:重复m到n次
{m}:至少重复m次
'''
import re
print ( '--------*的使用------------' )
pattern= '\d*'
s= '123qwe'
s= '123456qwe'
s= 'qwe'
o= re. match ( pattern, s)
print ( o)
print ( '--------+的使用------------' )
pattern= '\d+'
s= 'qwe'
o= re. match ( pattern, s)
print ( o)
print ( '--------?的使用------------' )
pattern= '\d?'
s= '123qwe'
s= '1qwe'
s= '123456qwe'
s= 'qwe'
o= re. match ( pattern, s)
print ( o)
print ( '---------{m}-----------' )
pattern= '\d{2}'
pattern= '\d{3}'
pattern= '\d{4}'
s= '123qwe'
o= re. match ( pattern, s)
print ( o)
print ( '---------{m,n}-----------' )
pattern= '\d{2,5}'
s= '123qwe'
s= '123456qwe'
s= 'qwe'
o= re. match ( pattern, s)
print ( o)
print ( '---------{m,}-----------' )
pattern= '\d{2,}'
s= '123qwe'
s= '123456qwe'
s= 'qwe'
o= re. match ( pattern, s)
print ( o)
import re
print ( '------案例1------' )
pattern= '[A-Z][a-z]*'
s= 'Hello'
s= 'HEllo'
o= re. match ( pattern, s)
print ( o)
print ( '------案例2------' )
pattern= '[a-zA-Z_]\w*'
s= 'userName'
s= 'age'
s= 'a'
s= '_qwe'
o= re. match ( pattern, s)
print ( o)
print ( '-------案例3----------' )
pattern= '[1-9]\d?'
s= '2'
s= '99'
s= '100'
s= '0'
o= re. match ( pattern, s)
print ( o)
print ( '----------案例4--------------' )
pattern= '\w{8,20}'
s= '123456789'
s= 'abc123qwe_'
s= '1234567#'
o= re. match ( pattern, s)
print ( o)
print ( 'd:\\a\\b\\c' )
print ( '\nabc' )
print ( '\\nabc' )
print ( '\t123' )
print ( '\\t123' )
import re
s= '\\t123'
pattern= r'\\t\d*'
o= re. match ( pattern, s)
print ( o)
s= '\\\\t123'
pattern= r'\\\\t\d*'
o= re. match ( pattern, s)
print ( o)
import re
qq= '8656707@qq.com'
qq= '8656707@qq.com.cn'
qq= '8656707@qq.com.126.com'
pattern= r'[1-9]\d{4,9}@qq.com$'
o= re. match ( pattern, qq)
print ( o)
print ( '----------^开始------------' )
s= 'hello python'
s= 'hepython'
pattern= r'^hello.*'
o= re. match ( pattern, s)
print ( o)
print ( '-------\\b匹配单词的左边界------------' )
pattern= r'.*\bab'
s= '12345 abc'
o= re. match ( pattern, s)
print ( o)
print ( '-------\\b匹配单词的右边界------------' )
pattern= r'.*ab\b'
s= '12345 abc'
s= '12345 ab'
o= re. match ( pattern, s)
print ( o)
print ( '-------\\B匹配非单词的边界------------' )
pattern= r'.*ab\B'
s= '12345 abc'
s= '12345 ab'
o= re. match ( pattern, s)
print ( o)
import re
pattern= 'hello'
s= 'hello python'
m= re. match ( pattern, s)
print ( m)
print ( m. group( ) )
print ( '-------macth和search的区别----------' )
pattern= 'love'
s= 'I love you'
m= re. match ( pattern, s)
print ( '使用match进行匹配' , m)
o= re. search( pattern, s)
print ( '使用search进行匹配' , o)
import re
pattern= 'aa|bb|cc'
s= 'aa'
o= re. match ( pattern, s)
print ( o)
s= 'bb'
o= re. match ( pattern, s)
print ( o)
s= 'my name is cc'
o= re. search( pattern, s)
o= re. match ( pattern, s)
print ( o)
print ( '匹配0-100之间所有的数字' )
pattern= r'[1-9]?\d$|100$'
s= '1'
s= '11'
s= '99'
s= '100'
s= '1000'
o= re. match ( pattern, s)
print ( o)
import re
pattern= 'ab|cd'
s= 'ad'
s= 'ac'
o= re. match ( pattern, s)
print ( o)
'''
(ab) 将括号中的字符作为一个分组
\num 引用分组num匹配到的字符串
(?p<name>) 分别起组名
(?p=name) 引用别名为name分组匹配到的字符串
'''
import re
print ( '匹配座机号码' )
pattern= r'\d{3,4}-[1-9]\d{4,7}$'
pattern= r'(\d{3,4})-([1-9]\d{4,7}$)'
s= '010-786545'
o= re. match ( pattern, s)
print ( o)
print ( o. group( ) )
print ( o. group( 1 ) )
print ( o. group( 2 ) )
print ( '匹配出网页标签内的数据' )
pattern= r'<(.+)><(.+)>.+</\2></\1>'
s= '<html><title>head部分</head></body>'
o= re. match ( pattern, s)
print ( o)
print ( '(?P<name>) 分别起组名' )
pattern= r'<(?P<k_html>.+)><(?P<k_head>.+)>.+</(?P=k_head)></(?P=k_html)>'
s= '<html><head>head部分</head></html>'
s= '<html><title>head部分</head></body>'
o= re. match ( pattern, s)
print ( o)
import re
print ( '--------sub-------------' )
phone= '2004-959-559 # 这是一个国外电话号码'
pattern= r'#.*$'
result= re. sub( pattern, '' , phone)
print ( 'sub:' , result)
pattern= r'#\D*'
result= re. sub( pattern, '' , phone)
print ( 'sub:' , result)
print ( '---------subn-----------' )
result= re. subn( pattern, '' , phone)
print ( result)
print ( result[ 0 ] )
print ( result[ 1 ] )
print ( '---------compile------------' )
s= 'first123 line'
pattern= r'\w+'
regex= re. compile ( pattern)
o= regex. match ( s)
print ( o)
print ( '---------findall-------------' )
s= 'first 1 second 2 third 3'
pattern= r'\w+'
result= re. findall( pattern, s)
print ( result)
print ( '---------finditer-------------' )
s= 'first 1 second 2 third 3'
pattern= r'\w+'
result= re. finditer( pattern, s)
print ( result)
for i in result:
print ( i. group( ) , end= '\t' )
print ( )
print ( '----------split-------------' )
s= 'first 11 second 22 third 33'
pattern= r'\d+'
result= re. split( pattern, s)
print ( result)
result= re. split( pattern, s, maxsplit= 2 )
print ( result)
import re
v = re. match ( r'(.+)(\d+-\d+-\d+)' , 'This is my tel:133-1234-1234' )
print ( '----------贪婪模式---------' )
print ( v. group( 1 ) )
print ( v. group( 2 ) )
print ( '----------非贪婪模式---------' )
v = re. match ( r'(.+?)(\d+-\d+-\d+)' , 'This is my tel:133-1234-1234' )
print ( v. group( 1 ) )
print ( v. group( 2 ) )
print ( '-------实例2--------' )
print ( '贪婪模式' )
v= re. match ( r'abc(\d+)' , 'abc123' )
print ( v. group( 1 ) )
print ( '非贪婪模式' )
v= re. match ( r'abc(\d+?)' , 'abc123' )
print ( v. group( 1 ) )