文章迁移,待整理
2. 状态和Checkpoint调优
2.1 大状态调优
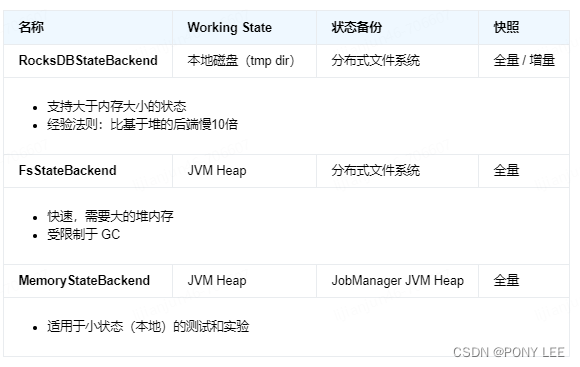
我们生产大多数会使用 fsState ,memState程序挂了状态就丢了,应该没人会在生产使用,但是涉及到一些大状态,fsState效率很低,这时候会选择 rocksDbState
1. RocksDb 为什么效率高
基于 LSM Tree 实现,类似 Hbase 的读写方式,
state.backend.local-recovery: true写数据内存即返回,查数据先查 blockCache,
2. 开启 state 性能访问监控
开启监控会对性能有影响,但是对 rocksDbStateBackend 来说影响不大,大概 1%,但是有监控可以快速定位问题
-Dstate.backend.latency-track.keyed-state-enabled=true3. 开启增量检查点
state.backend.incremental: true #默认 false,改为 true。4. 开启本地恢复
Flink任务失败时,可以基于本地的状态信息恢复任务
state.backend.incremental: true #默认 false,改为 true。5. 多目录设置
有多块磁盘,可以考虑设置多目录
state.backend.rocksdb.localdir:
/data1/flink/rocksdb,/data2/flink/rocksdb,/data3/flink/rocksdb2.2 checkpoint 间隔时长设置
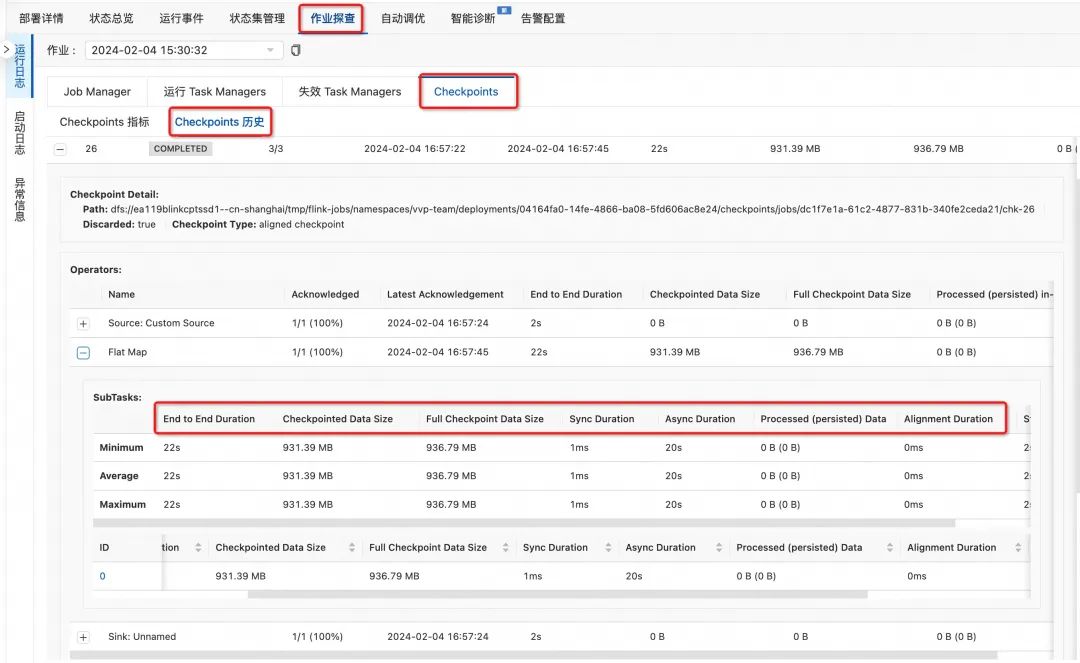
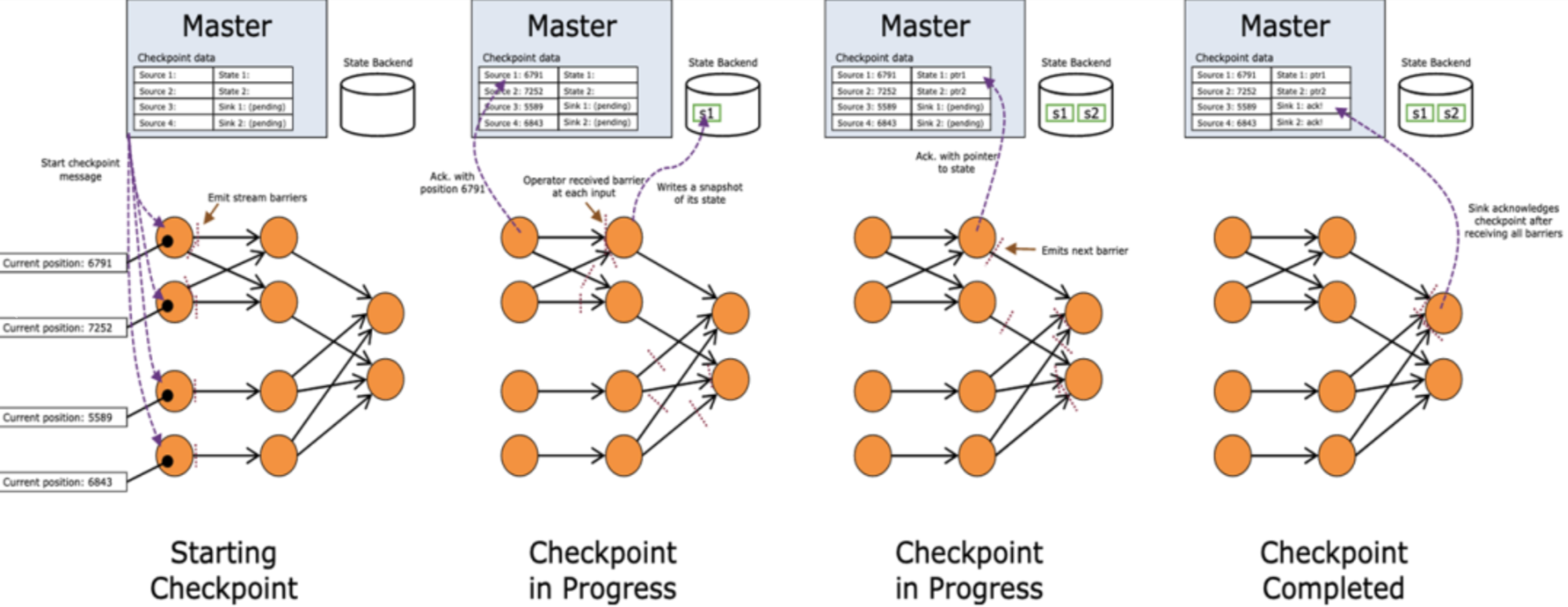
一般checkpoint 间隔时长设置为 1-5分钟,比如阿里云我们都使用默认的 180S,但是对于一些大状态尤其是 Hdfs 储存时比较慢,可以设置 5-10分钟,并且设置两次 Checkpoint 至少间隔 4-8分钟























![【PyTorch][chapter 15][李宏毅深度学习][Neighbor Embedding-LLE]](https://img-blog.csdnimg.cn/direct/9d72ccd5676c451c95c01f55c2d1ba36.png)