Lab: locks
Memory allocator
程序user/kalloctest强调xv6的内存分配器:三个进程增加和缩小它们的地址空间,导致对kalloc和kfree的多次调用。Kalloc和kfree获取kmem.lock。对于kmem锁和其他一些锁,Kalloctest打印(作为“#test-and-set”)由于试图获取另一个核心已经持有的锁而导致的acquire中的循环迭代次数。acquire中的循环迭代次数是锁争用的粗略度量。
Acquire为每个锁维护为该锁获取的调用计数,以及Acquire中的循环尝试设置锁但失败的次数。Kalloctest调用一个系统调用,使内核输出kmem和bcache锁(这是本实验的重点)和5个争用最多的锁的计数。如果存在锁争用,则获取循环迭代的次数将会很大。系统调用返回kmem和bcache锁的循环迭代次数的总和。
kalloctest中锁争用的根本原因是kalloc()只有一个空闲列表,由一个锁保护。要消除锁争用,必须重新设计内存分配器,以避免使用单个锁和列表。基本思想是为每个CPU维护一个空闲列表,每个列表都有自己的锁。不同CPU上的分配和释放可以并行运行,因为每个CPU将对不同的列表进行操作。主要的挑战将是处理这样的情况:一个CPU的空闲列表是空的,但另一个CPU的列表有空闲内存;在这种情况下,一个CPU必须“窃取”另一个CPU的空闲列表的一部分。窃取可能会引入锁争用,但希望这种情况不会经常发生。
您的工作是实现每个CPU的自由列表,并在CPU的空闲列表为空时窃取。您必须为所有锁提供以“kmem”开头的名称。也就是说,您应该为每个锁调用initlock,并传递一个以“kmem”开头的名称。运行kalloctest,看看您的实现是否减少了锁争用。要检查它是否仍然可以分配所有内存,请运行usertests sbrkmuch。您的输出将类似于下面所示,在kmem锁上的争用总量大大减少,尽管具体的数字会有所不同。确保usertests -q中的所有测试都通过。Make grade应该说kallocets通过了。
一些提示:
- 您可以使用kernel/param.h中的常量NCPU
- 让freerange将所有空闲内存分配给运行freerange的CPU。
- 函数cpuid返回当前的核心编号,但是只有在中断关闭时调用它并使用它的结果才是安全的。您应该使用push_off()和pop_off()来关闭和打开中断。
- 请查看kernel/sprintf.c中的snprintf函数,了解字符串格式化的想法。不过,将所有锁命名为“kmem”是可以的。
- 可以选择使用xv6的竞争检测器运行解决方案
$ make clean $ make KCSAN=1 qemu $ kalloctest
这里要求降低锁的粒度,原本内存分配是一把大锁保平安,现在需要拆分成让每个CPU都有一把锁来管理各自的空闲列表来进行内存分配,有NCPU个CPU那么就有NCPU个锁。为每个CPU分配一个空闲链表,kalloc和kfree都在本核心的链表上进行,只有当当前核心的链表为空时才去访问其他核心的链表。
因此定义NCPU个kmem结构体,并在kinit函数中对锁进行初始化。
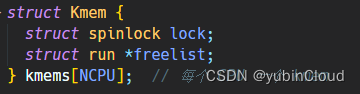
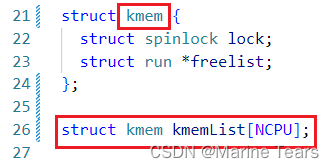
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];
char *kmem_lock_names[] = {
"kmem_cpu_0",
"kmem_cpu_1",
"kmem_cpu_2",
"kmem_cpu_3",
"kmem_cpu_4",
"kmem_cpu_5",
"kmem_cpu_6",
"kmem_cpu_7",
};
void
kinit()
{
for(int i=0;i<NCPU;i++) {
initlock(&kmem[i].lock, kmem_lock_names[i]);
}
freerange(end, (void*)PHYSTOP);
}kfree() 用于回收物理页到当前CPU的 freelist (keme[i].freelist)。在初始时 freearrange() 将空闲内存分配给当前运行 CPU 的 freelist。而 freearrange() 内部就是调用 kfree() 进行的内存回收,也就是说最开始所有的空闲页面都分配给了CPU0的freelist,kfree()要做的就是哪个CPU调用它,它就把要回收的页面给哪个CPU的freelist。修改方法即使用 cpuid() 函数获取当前 CPU 核心的序号, 使用 kmems 中对应的锁和 freelist 进行回收,根据提获取当前CPU的id时要关中断。
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
push_off();
int cpu = cpuid();
pop_off();
acquire(&kmem[cpu].lock);
r->next = kmem[cpu].freelist;
kmem[cpu].freelist = r;
release(&kmem[cpu].lock);
}对于分配空闲内存的kalloc(),由上得知最开始所有的空闲内存都在CPU0的freelist,这个时候其他CPU的freelist是空的,提示说当CPUfreelist为空时,需要从其他CPU的freelist那里获取空闲内存,具体流程就是循环遍历CPU列表,如果哪个CPU的freelist不为空,那么就获取它的一个空闲页面,然后让它的freelist指向下一个页面,这里要注意需要获取对方CPU的锁。非常关键的一点是在获取其他CPU的锁前需要释放当前CPU的锁,不然如果此时其他CPU也因为缺少内存而遍历CPU到当前CPU时,由于当前CPU的锁没有释放,就会发生死锁。
void *
kalloc(void)
{
struct run *r;
push_off();
int cpu = cpuid();
pop_off();
acquire(&kmem[cpu].lock);
r = kmem[cpu].freelist;
if(r){
kmem[cpu].freelist = r->next;
release(&kmem[cpu].lock);
}else{ //获取其他CPU的freelist
int free_cpu;
for(int i = i;i<NCPU;i++){
free_cpu=(cpu+i)%NCPU;
if(kmem[free_cpu].freelist!=0)//如果freelist是有值的,退出遍历CPU freelist的循环
break;
}
release(&kmem[cpu].lock);//这里一定要释放当前CPU的锁,不然如果有其他CPU也在遍历CPU寻找freelist,那就会发生死锁
acquire(&kmem[free_cpu].lock);
r = kmem[free_cpu].freelist;
if(r)
kmem[free_cpu].freelist = r->next;
release(&kmem[free_cpu].lock);//释放cpu j的锁
}
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}Buffer cache
如果多个进程密集地使用文件系统,它们很可能会竞争
bcache.lock,该锁用于保护内核中的磁盘块缓存,具体在kernel/bio.c中。bcachetest创建了多个进程,它们不断地读取不同的文件以生成对bcache.lock的争夺;如果您查看kernel/bio.c中的代码,您将看到bcache.Lock保护缓存的块缓冲区列表,每个块缓冲区中的引用计数(b->refcnt),以及缓存块的标识(b->dev和b->blockno)。
修改块缓存,以便在运行bachetest时,bcache中所有锁的获取循环迭代次数接近于零。理想情况下,块缓存中涉及的所有锁的计数之和应该为零,但如果总和小于500也没关系。修改bget和brelse,使bcache中不同块的并发查找和释放不太可能在锁上发生冲突(例如,不必等待bcache.lock)。您必须维护每个块最多缓存一个副本的不变性。完成后,输出应该与下面显示的类似(尽管不完全相同)。确保“usertests -q”仍然通过。当你完成所有的测试时,你应该通过评分。
请提供所有以“bcache”开头的锁名。也就是说,您应该为每个锁调用initlock,并传递一个以“bcache”开头的名称。
减少块缓存中的争用比减少kalloc更棘手,因为bcache缓冲区实际上是在进程(以及cpu)之间共享的。对于kalloc,可以通过为每个CPU分配自己的分配器来消除大多数争用;这对块缓存不起作用。我们建议您使用每个哈希桶都有一个锁的哈希表在缓存中查找块号。
在某些情况下,如果你的解决方案有锁冲突是可以的:
当两个进程同时使用相同的块号时:
bcachetest的 test0 没有这种情况,所以在这种情况下存在锁冲突是可以接受的。当两个进程同时在缓存中未命中,并需要找到一个未使用的块进行替换时:
bcachetest的 test0 没有这种情况,所以在这种情况下存在锁冲突是可以接受的。当两个进程同时使用在你用于分割块和锁的方案中冲突的块:
- 例如,如果两个进程使用的块的块号散列到哈希表中的相同槽位。
bcachetest的 test0 可能会出现这种情况,这取决于你的设计,但是你应该尽量调整方案的细节以避免冲突(例如,更改哈希表的大小)。Bcachetest的test1使用了比缓冲区更多的不同块,并执行了许多文件系统代码路径。
以下是一些提示:
- 请阅读xv6书中关于块缓存的描述(第8.1-8.3节)。
- 使用固定数量的桶而不动态调整哈希表的大小是可以的。使用素数的桶(例如,13)来减少哈希冲突的可能性。
- 在哈希表中搜索缓冲区并在没有找到缓冲区时为该缓冲区分配条目必须是原子式的。
- 删除所有缓冲区的列表(bcache.head等),不实现LRU。有了这个修改,bcache就不需要获取bcache锁了。在bget中,您可以选择refcnt == 0的任何块,而不是最近最少使用的块。
- 您可能无法自动检查缓存的buf并(如果未缓存)找到未使用的buf;如果缓冲区不在缓存中,您可能必须删除所有锁并从头开始。在bget中序列化查找一个未使用的buf是可以的(即,当在缓存中查找失败时,bget中选择一个缓冲区重新使用的部分)。
- 在某些情况下,您的解决方案可能需要持有两个锁;例如,在清除期间,您可能需要持有bcache锁和每个桶的锁。确保避免死锁。
- 当替换一个块时,您可能会将一个结构体从一个桶移动到另一个桶,因为新块散列到另一个桶。您可能遇到一个棘手的情况:新块可能散列到与旧块相同的桶中。在这种情况下,请确保避免死锁。
- 一些调试提示:实现桶锁,但保留全局bcache。在对象的开始/结束处锁定获取/释放,以序列化代码。一旦您确定它是正确的,没有竞争条件,删除全局锁并处理并发问题。您还可以运行make cpu =1 qemu来使用一个核心进行测试。
- 使用xv6的竞争检测器来查找潜在的竞争(请参阅上面如何使用竞争检测器)。
在解题前建议先看一下有关xv6文件系统中缓存部分的知识,理解bio.c中各种结构体和函数的定义是什么。
原版 xv6 的设计中,使用双向链表存储所有的区块缓存,由main()调用的函数binit使用静态数组buf中的NBUF个缓冲区初始化列表。对缓冲区缓存的所有访问都是通过bcache.head来引用链表,该链表被一把大锁保护,每当一个进程获取块缓存的时候都会获取该锁,为了减少竞争我们需要修改其数据结构,改用哈希桶来存储buf。
我的思路是把原本的大链表分割成BKSIZE个小链表,也就是一共有BKSIZE个锁,原本有NBUF个buf,那么现在每个小链表也就是每个哈希桶中就有NBUF/BKSIZE个buf,这样加锁的时候给小链表加锁就行,降低了锁的粒度。
我这里设了十个哈希桶,因为NBUF是30,30/10整除得3,即每个哈希桶有3个buf。
#define BKSIZE 10
struct {
//struct spinlock lock;
struct buf buf[NBUF];
struct buf bucket[BKSIZE];//哈希桶
struct spinlock lock[BKSIZE];//为每个桶配一把锁
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
struct buf head;
} bcache;binit()中原本的大锁被我去掉了,初始化每个桶的锁就行。剩下的步骤和原版代码差不多,对每个桶初始化双向链表。
void
binit(void)
{
struct buf *b;
//initlock(&bcache.lock, "bcache");
for(int i = 0; i < BKSIZE; i++)
initlock(&bcache.lock[i], "bcache");//初始化自旋锁
int num = NBUF/BKSIZE;
for(int i = 0; i < BKSIZE; i++){
bcache.bucket[i].prev = &bcache.bucket[i];
bcache.bucket[i].next = &bcache.bucket[i];
for(b = bcache.buf+num*i; b < bcache.buf+num*(i+1); b++){//每个桶有NBUF/BKSIZE个元素
b->next = bcache.bucket[i].next;
b->prev = &bcache.bucket[i];
initsleeplock(&b->lock, "buffer");
bcache.bucket[i].next->prev = b;
bcache.bucket[i].next = b;
}
}
}根据xv6_book的描述,bread(4402)调用bget,以获得给定扇区(4406)的缓冲。Bget(4366)使用给定的设备和扇区编号扫描缓冲区列表以获取缓冲区(4373-4384)。当调用方使用缓冲区完成时,它必须调用brelse释放它。
因此对于bget(),首先得到该blockno对应桶的锁,然后在这个桶中查找buf,如果给定扇区没有缓存缓冲区,那么就创建一个,思路和原版代码差不多,唯一的区别也就是原本的大链表变成了小链表仅此而已。原本我还考虑到当前桶中的空闲buf不够分配,是不是类似上一题的kalloc()可以从别的桶中偷一点,后来否决了这个想法,因为每个桶都是根据blockno作为key来索引value的,如果偷其他桶的空闲buf下次再根据blockno索引就算有对应的buf也找不到(比如这个buf在桶0但是你根据blockno索引到桶1)。
int
getHashVal(uint key)
{
return key%BKSIZE;
}
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
int hashval=getHashVal(blockno);
acquire(&bcache.lock[hashval]);
// Is the block already cached?
for(b = bcache.bucket[hashval].next; b != &bcache.bucket[hashval]; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.lock[hashval]);
acquiresleep(&b->lock);
return b;
}
}
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
for(b = bcache.bucket[hashval].prev; b != &bcache.bucket[hashval]; b = b->prev){
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcache.lock[hashval]);
acquiresleep(&b->lock);
return b;
}
}
panic("bget: no buffers");
}xv6_books描述,当调用方使用缓冲区完成时,它必须调用brelse释放它。这里的修改也比较少,就是把原本的获取大锁变成获取桶的锁就行,释放的buf插入每个桶的buf链表中。bpin()和bunpin()同理。
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
int hashval=getHashVal(b->blockno);
acquire(&bcache.lock[hashval]);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.bucket[hashval].next;
b->prev = &bcache.bucket[hashval];
bcache.bucket[hashval].next->prev = b;
bcache.bucket[hashval].next = b;
}
release(&bcache.lock[hashval]);
}
void
bpin(struct buf *b) {
int hashval = getHashVal(b->blockno);
acquire(&bcache.lock[hashval]);
b->refcnt++;
release(&bcache.lock[hashval]);
}
void
bunpin(struct buf *b) {
int hashval = getHashVal(b->blockno);
acquire(&bcache.lock[hashval]);
b->refcnt--;
release(&bcache.lock[hashval]);
}
相较于链表,我觉得这题也可以用数组来实现哈希桶,每个哈希桶是一个buf数组,这样struct buf中的prev和next字段可以去掉,这样代码要比链表实现的要简洁。
Lab: file system
Large files
在这个任务中,您将增加一个xv6文件的最大大小。目前,xv6文件被限制为268块,或268*BSIZE字节(在xv6中BSIZE为1024)。这个限制来自这样一个事实,即一个xv6 inode包含12个“直接”块号和一个“单间接”块号,它指的是一个块最多可容纳256个块号,总共12+256=268个块。
您将修改xv6文件系统代码,以便在每个索引节点中支持一个“双间接”块,其中包含256个单间接块地址,每个单间接块最多可以包含256个数据块地址。结果将是一个文件将能够由多达65803个块组成,或者256*256+256+11块(11而不是12,因为我们将牺牲一个直接块号来获得双间接块)。
mkfs程序创建xv6文件系统磁盘映像,并确定文件系统总共有多少块;这个大小由kernel/param.h中的FSSIZE控制。您将看到本实验的存储库中的FSSIZE设置为200,000块。在make命令的输出中,你应该看到mkfs/mkfs的如下输出:
nmeta 70 (boot, super, log blocks 30 inode blocks 13, bitmap blocks 25) blocks 199930 total 200000这一行描述了mkfs/mkfs构建的文件系统:它有70个元数据块(用于描述文件系统的块)和199,930个数据块,总计200,000个块。
如果在实验过程中的任何时候,您发现自己不得不从头开始重新构建文件系统,您可以运行make clean,这将迫使make重新构建fs.img。磁盘上索引节点的格式由fs.h中的struct dinode定义。您对结构体dinode的NDIRECT、NINDIRECT、MAXFILE和addrs[]元素特别感兴趣。查看xv6文本中的图8.3,了解标准xv6 inode的示意图。
查找磁盘上文件数据的代码在fs.c中的bmap()中。看一下它,确保你明白它在做什么。Bmap()在读取和写入文件时都被调用。当写入时,bmap()根据需要分配新的块来保存文件内容,如果需要的话,还会分配一个间接块来保存块地址。
Bmap()处理两种类型的块号。bn参数是一个“逻辑块号”——文件中的一个块号,相对于文件的开头。ip->addrs[]中的块号和bread()的参数都是磁盘块号。您可以将bmap()视为将文件的逻辑块编号映射到磁盘块编号。
修改bmap(),使其实现除了直接块和单间接块之外的双间接块。你只需要有11个直接块,而不是12个,就可以为新的双间接块腾出空间;不允许更改磁盘上索引节点的大小。ip-> address[]的前11个元素应该是直接块;第12个应该是一个单一的间接块(就像当前的);13号应该是你新的双间接block。当bigfile写入65803块并且usertests -q运行成功时,你就完成了这个练习:
提示
- 确保您理解了bmap()。写出ip->addrs[]、间接块、双间接块和它指向的单间接块以及数据块之间的关系图。确保您理解为什么添加双间接块会使最大文件大小增加256*256块(实际上是-1,因为您必须将直接块的数量减少1)。
- 考虑一下如何用逻辑块号对双间接块及其指向的间接块进行索引。
- 如果你改变了NDIRECT的定义,你可能需要改变file.h中struct inode中的addrs[]声明。确保struct inode和struct dinode在它们的adders[]数组中具有相同数量的元素。
- 如果您更改了NDIRECT的定义,请确保创建一个新的fs。因为mkfs使用NDIRECT来构建文件系统。
- 如果您的文件系统进入不良状态(可能是崩溃),请删除fs。img(在Unix上执行此操作,而不是在xv6上)。Make将为您构建一个新的干净的文件系统映像。
- 不要忘记brese()你bread()的每个块。
- 您应该只在需要时分配间接块和双间接块,就像最初的bmap()一样。
- 确保itrunc释放文件的所有块,包括双间接块。
- 与以前的实验相比,usertest需要更长的时间来运行,因为在这个实验中,FSSIZE更大,大文件更大。
做这题之前需要看一下Lecture 14 - File Systems ,当然文字版的也可以,很多信息都涉及到了这次lab。
根据xv6_books中的描述,xv6文件系统里定义了2个版本的inode。一个是硬盘上面存储的版本struct dinode,在fs.h里定义;另一个是内存里存储的版本struct inode,起到缓存的作用,在file.h里定义。两个结构都有成员ref和nlink。nlink是inode在文件系统里面的链接数,如果nlink为0,说明inode对应的文件已经被删除;ref是此inode被进程引用的次数,如果ref为0,就说明没有进程使用这个inode了,这时操作系统就不用继续在内存里缓存它,可以将它驱逐到硬盘。操作系统可以使用iupdate()更新硬盘里面的inode,用iget()增加一次ref,iput()减少一次ref。
未修改前,xv6 文件系统中的每一个 inode 结构体中,采用了混合索引的方式记录数据的所在具体盘块号。每个文件所占用的前 12 个盘块的盘块号是直接记录在 inode 中的(每个盘块1KB),所以对于任何文件的前 12 KB 数据,都可以通过访问 inode 直接得到盘块号。这一部分称为直接记录盘块。对于大于 12 个盘块的文件,会分配一个额外的一级索引表(一盘块大小,1KB),用于存储这部分数据的所在盘块号。由于块号的大小是4b,因此一级索引表可以包含 1KB / 4B= 256 个盘块号,加12 个直接记录盘块,一个文件最多可以使用 12+256 = 268 个盘块,也就是 268KB。

而题目要求的就是给 inode 加入一个二级的间接块指针来增大文件大小,将其中一个直接记录块编号作为double-indirectly的块,即该块存储256个间接引用块,每个间接引用块可以存储256个文件块,故一共有256*256个引用块,因此一个文件则可以存储(256*256+256+11)个块,即65803个块,大小为65803KB。修改后的inode结构和下图差不多,只使用二级索引。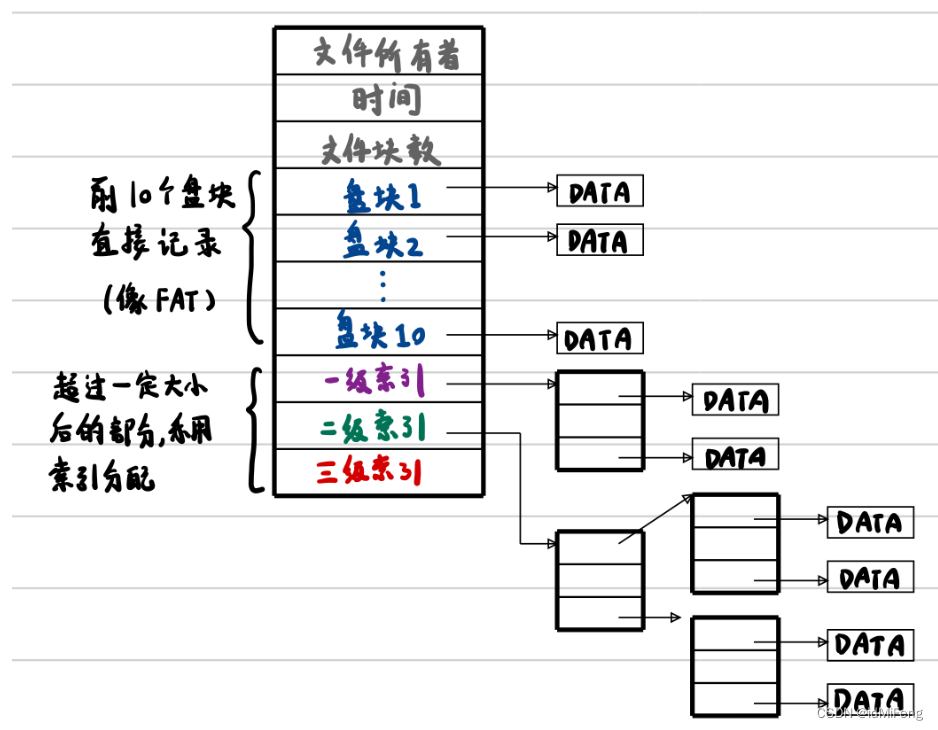
分析代码,每个inode结构中,前12个元素(addrs[0] 到 addrs[11])用于存储直接块的地址,因此 NDIRECT 表示直接块的数量为12。单间接块是一个块,其中包含一组块地址,每个地址指向一个数据块,单间接块可以包含 BSIZE / sizeof(uint) 个块地址。MAXFILE 的值等于直接块的数量(NDIRECT)加上单间接块中包含的块地址的数量(NINDIRECT),因此 MAXFILE 表示一个inode结构中最多能够包含的块地址的总数。
#define NDIRECT 12 // 表示直接块的数量
#define NINDIRECT (BSIZE / sizeof(uint)) // 表示单间接块(indirect block)中包含的块地址的数量
#define MAXFILE (NDIRECT + NINDIRECT) // 表示一个文件inode结构中最多能够包含的块地址的总数
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses 数据块地址数组,包括直接块和一个可能的单/双间接块
};修改这些常量,实现二级间接块索引的 inode 结构,现在要求改成:前11个块是直接块,第12个块是一级间接块,第13个块是二级间接块。所以inode 中原本 12 个直接块号被修改为 了 11 个,对struct dinode和struct inode的addrs字段也要进行修改,修改后的代码为:
#define NDIRECT 11 // 表示直接块的数量
#define NINDIRECT (BSIZE / sizeof(uint)) // 表示单间接块(indirect block)中包含的块地址的数量
#define NBI_INDIRECT NINDIRECT * NINDIRECT // 二级间接块中包含的块地址的数量
#define MAXFILE (NDIRECT + NINDIRECT + NBI_INDIRECT) // 表示一个文件inode结构中最多能够包含的块地址的总数
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+2]; // Data block addresses 数据块地址数组,包括直接块和一个可能的单/双间接块
};
//在file.h
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+2];
};接下来要修改bmap()函数,使其支持二级块表,其实就是重复一次块表的查询过程。bmap()用于返回 inode 的逻辑块号对应的磁盘中的块号,也就是获取 inode 中第 bn 个块的磁盘块号。由于 inode 结构中前12 个块号与修改前是一致的, 因此只需要添加对第 13 个块的二级间接索引的处理代码,处理的方法与处理一级间接块号的方法是类似的, 只是需要索引两次,在查出一级块号后,需将一级块中的数据读入,然后再次查询代码中很多写法可以参考前面对一级间接块的处理。注意函数调用bread()之后的处理方法:bread()读取硬盘块,把硬盘块缓存在内存里一个struct buf类型的结构体里面,我们需要的数据在此结构体的data成员中。
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
// 如果逻辑块号在直接块范围内
if(bn < NDIRECT){
// 如果直接块地址为0,表示该块尚未分配
if((addr = ip->addrs[bn]) == 0){
// 分配一个新块
addr = balloc(ip->dev);
if(addr == 0)
return 0; // 分配失败,返回0表示磁盘空间不足
// 将新块的地址存储在inode中
ip->addrs[bn] = addr;
}
// 返回直接块的地址
return addr;
}
// 如果逻辑块号在单间接块范围内
bn -= NDIRECT;
if(bn < NINDIRECT){
// 加载单间接块,如果需要的话进行分配
if((addr = ip->addrs[NDIRECT]) == 0){
// 分配一个新块
addr = balloc(ip->dev);
if(addr == 0)
return 0; // 分配失败,返回0表示磁盘空间不足
// 将新块的地址存储在inode中
ip->addrs[NDIRECT] = addr;
}
// 读取单间接块
bp = bread(ip->dev, addr);
// 获取单间接块中的块地址数组
a = (uint*)bp->data;
// 如果单间接块中的块地址为0,表示该块尚未分配
if((addr = a[bn]) == 0){
// 分配一个新块
addr = balloc(ip->dev);
if(addr){
// 将新块的地址存储在单间接块的对应位置
a[bn] = addr;
// 将修改写回磁盘
log_write(bp);
}
}
// 释放单间接块
brelse(bp);
// 返回块的地址
return addr;
}
//从这里开始是二级块的查询过程
bn -= NINDIRECT;
if(bn < NBI_INDIRECT){
// 加载二级间接块,如果需要的话进行分配
if((addr = ip->addrs[NDIRECT + 1]) == 0){
addr = balloc(ip->dev);
if(addr == 0)
return 0;
ip->addrs[NDIRECT+1] = addr;
}
bp = bread(ip->dev, addr);
a = (uint *)bp->data;
uint idx_b1 = bn / NINDIRECT; // 获取二级块的一级索引
if((addr = a[idx_b1]) == 0){
addr = balloc(ip->dev);
if(addr){
a[idx_b1] = addr;
log_write(bp);
}
}
brelse(bp); // 释放块缓存
bp = bread(ip->dev, addr);
a = (uint *)bp->data;
uint idx_b2 = bn % NINDIRECT;
if((addr = a[idx_b2]) == 0){
addr = balloc(ip->dev);
if(addr){
a[idx_b2] = addr;
log_write(bp);
}
}
brelse(bp);
return addr;
}
// 如果逻辑块号超出了范围,发生了错误
panic("bmap: out of range");
}最后修改itrunc函数使其能够释放二级块表对应的块, 此函数会清理 inode 中的所有块,或者可以理解成删除一个文件。这个函数内实际上是在不停的调用 brelse() 和 bfree()。其中 brelse() 释放一个块缓存,而 bfree() 则通过修改磁盘上 bitmap 块的数据来释放磁盘上的一个块。释放的方式同一级间接块号的结构, 仿照一级块表的处理就行了。
void
itrunc(struct inode *ip)
{
int i, j;
struct buf *bp;
uint *a;
for(i = 0; i < NDIRECT; i++){
if(ip->addrs[i]){
bfree(ip->dev, ip->addrs[i]);
ip->addrs[i] = 0;
}
}
if(ip->addrs[NDIRECT]){
bp = bread(ip->dev, ip->addrs[NDIRECT]);
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++){
if(a[j])
bfree(ip->dev, a[j]);
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT]);
ip->addrs[NDIRECT] = 0;
}
if(ip->addrs[NDIRECT+1]){
bp = bread(ip->dev, ip->addrs[NDIRECT+1]);
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++){
if(a[j]) {
struct buf *bp2 = bread(ip->dev, a[j]);
uint *a2 = (uint*)bp2->data;
for(int k = 0; k < NINDIRECT; k++){
if(a2[k])
bfree(ip->dev, a2[k]);
}
brelse(bp2);
bfree(ip->dev, a[j]);
}
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT+1]);
ip->addrs[NDIRECT] = 0;
}
ip->size = 0;
iupdate(ip);
}Symbolic links
在本练习中,您将向xv6添加符号链接。符号链接(或软链接)指的是通过路径名链接的文件;当一个符号链接被打开时,内核沿着这个链接指向被引用的文件。符号链接类似于硬链接,但硬链接仅限于指向同一磁盘上的文件,而符号链接可以跨磁盘设备。尽管xv6不支持多设备,但是实现这个系统调用是理解路径名查找如何工作的一个很好的练习。
您将实现symlink(char *target, char *path)系统调用,它将在path上创建一个新的符号链接,该链接指向以target命名的文件。有关更多信息,请参阅手册页符号链接。要进行测试,请将symlinktest添加到Makefile并运行它。
提示
- 首先,为symlink创建一个新的系统调用号,在user/usys.pl、user/user.h中添加一个条目,并在kernel/sysfile.c中实现一个空的sys_symlink。
- 在kernel/stat.h中添加一个新的文件类型(T_SYMLINK)来表示符号链接。
- 在kernel/fcntl.h中添加一个新的标志(O_NOFOLLOW),可以用于开放系统调用。请注意,传递给open的标志是使用按位或操作符组合的,因此新标志不应与任何现有标志重叠。这将允许您在将user/symlinktest.c添加到Makefile后编译它。
- 实现symlink(target, path)系统调用,在path上创建一个指向target的新符号链接。注意,系统调用成功并不需要目标存在。您需要选择一个位置来存储符号链接的目标路径,例如,在索引节点的数据块中。Symlink应该返回一个表示成功(0)或失败(-1)的整数,类似于link和unlink。
- 修改打开系统调用以处理路径引用符号链接的情况。如果文件不存在,打开必须失败。当进程在标志中指定O_NOFOLLOW要打开时,open应该打开符号链接(而不是跟随符号链接)。
- 如果链接的文件也是一个符号链接,则必须递归地跟踪它,直到到达非链接文件。如果链接形成一个循环,则必须返回一个错误代码。如果链接深度达到某个阈值(例如,10),您可以通过返回错误代码来近似地实现这一点。
- 其他系统调用(例如,link和unlink)不能跟随符号链接;这些系统调用对符号链接本身进行操作。
- 在本实验中,您不必处理指向目录的符号链接。
硬链接:
- 共享相同的inode和数据块。
- 不能跨越文件系统。
- 如果一个链接被删除,其他链接仍然存在,直到最后一个链接被删除。
软链接:
- 有独立的inode和数据块。
- 可以跨越文件系统。
- 如果原始文件被删除,软链接仍然存在,但指向的目标文件无效。
根据题目的描述可以知道符号链接是一种特殊文件类型(T_SYMLINK),文件中只有一个表明链接对象路径的字符串,就像是一个文件的“指针”,如果我们打开某个符号链接文件,实际打开的是那个链接指向的文件,这样就可以实现某个目录打开实际储存在不同目录的文件。一旦建立了符号链接,删除操作删除的是符号链接文件,其它所有操作都访问符号链接引用的文件。也就是说在使用 open 系统调用的时候,如果打开的是一个符号连接,那么 file system 就会找到这个符号连接指向的目标文件,再去打开目标文件(如果指定了 O_NOFOLLOW 标识,那么 fs 就会直接打开符号连接,而不会去追踪到目标文件)。
要如何实现符号链接呢?符号链接的本质其实也是一个文件,我们只要在这个文件(在 inode)中储存此链接指向的文件的路径就行了。符号链接与普通的文件一样,需要占用 inode 块。这里使用 inode 中的第一个直接块来存储符号链接指向的文件。symlink的系统调用就是创建一个inode,设置类型为T_SYMLINK,然后向这个inode中写入目标文件的路径就行了。
首先是添加一个系统调用的基本流程
user/usys.pl
entry("symlink");user/user.h
int symlink(char*,char*);kernel/syscall.c
extern uint64 sys_symlink(void);
//...
[SYS_symlink] sys_symlink,kernel/syscall.h
#define SYS_symlink 22Makefile
$U/_symlinktest\在 kernel/stat.h 中添加 T_SYMLINK 来标识一个 inode 类型是符号连接,在 kernle/fcntl.h 中添加一个新的标识符 O_NOFOLLOW,以让 open 系统调用判断是要打开一个符号连接还是追踪符号连接的目标文件。
symlink(target, path)在指定的path处创建一个新的符号链接,该链接引用target指定的文件。在各种文件相关的系统调用中,我们都需要使用begin_op() 和 end_op() 把这些系统调用包裹起来,其代表,在这个区间内的任何操作会先被记录到日志系统中。可以先参考一下硬链接的代码,将新的路径(new)链接到与旧路径(old)相同的inode上,他们之中有相似之处。
uint64
sys_link(void)
{
char name[DIRSIZ], new[MAXPATH], old[MAXPATH];
struct inode *dp, *ip;
// 解析用户提供的路径字符串
if(argstr(0, old, MAXPATH) < 0 || argstr(1, new, MAXPATH) < 0)
return -1;
// 开始文件系统操作
begin_op();
// 获取旧路径的inode
if((ip = namei(old)) == 0){
end_op();
return -1;
}
// 对inode进行锁定
ilock(ip);
// 如果inode类型为目录,释放锁并返回-1
if(ip->type == T_DIR){
iunlockput(ip);
end_op();
return -1;
}
// 增加inode的链接数,更新inode信息,解锁inode
ip->nlink++;
iupdate(ip);
iunlock(ip);
// 获取新路径的父目录inode
if((dp = nameiparent(new, name)) == 0)
goto bad;
ilock(dp);
// 检查设备号和创建硬链接
if(dp->dev != ip->dev || dirlink(dp, name, ip->inum) < 0){
iunlockput(dp);
goto bad;
}
// 解锁并释放父目录inode
iunlockput(dp);
// 释放旧路径的inode
iput(ip);
// 结束文件系统操作
end_op();
// 返回成功
return 0;
bad:
// 错误处理:减少旧路径的inode的链接数,更新inode信息,解锁并释放inode
ilock(ip);
ip->nlink--;
iupdate(ip);
iunlockput(ip);
end_op();
return -1;
}
那么符号链接也差不多,先将两个参数拿到,接着开启一个事务,在事务中完成 inode 的创建和写入。调用 create 函数创建 inode,然后再通过 writei() 将链接的目标文件的路径写入 inode 的block中即可,并且在事务结束时要调用 iunlockput 函数来释放锁并且取消一次引用。
需要注意的是关于文件系统的一些加锁释放的规则. 函数 create() 会返回创建的 inode, 此时也会持有其 inode 的锁. 而后续 writei() 是需要在持锁的情况下才能写入. 在结束操作后(不论成功与否), 都需要调用 iunlockput() 来释放 inode 的锁和其本身, 该函数是 iunlock() 和 iput() 的组合, 前者即释放 inode 的锁; 而后者是减少一个 inode 的引用(对应字段 ref, 记录着内存中指向该 inode 的指针数, 这里的 inode 实际上是内存中的 inode, 是从内存的 inode 缓存 icache 分配出来的, 当 ref 为 0 时就会回收到 icache 中), 表示当前已经不需要持有该 inode 的指针对其继续操作了。
uint64 sys_symlink(void) {
char target[MAXPATH], path[MAXPATH];
struct inode *ip;
if ((argstr(0, target, MAXPATH)) < 0|| argstr(1, path, MAXPATH) < 0) {
return -1;
}
begin_op();
if((ip = create(path, T_SYMLINK, 0, 0)) == 0) {
end_op();
return -1;
}
int n = strlen(target);
if(writei(ip, 0, (uint64)target, 0, n) != n) {
iunlockput(ip);
end_op();
return -1;
}
iunlockput(ip);
end_op();
return 0;
}
为了实现链接的效果,在 open() 函数中,需要去根据链接中储存的路径,递归的找到最终指向的文件(因为可能会有一个符号链接指向另一个符号链接)。在sys_open中添加对符号链接的处理,判断一下是不是符号链接,如果加了O_NOFOLLOW,则按照普通文件处理,当模式不是O_NOFOLLOW的时候就对符号链接进行循环处理,搜索到非符号链接文件为止,或者搜索深度达到10为止。用readi()读取取文件里的字符串,用namei()搜索相应的inode,如果循环超过了一定的次数(10),就说明可能发生了循环链接,就返回-1。这里主要就是要注意namei函数不会对ip上锁,需要使用ilock来上锁。
uint64
sys_open(void)
{
...
if(ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){
...
}
if(ip->type == T_SYMLINK){
if(!(omode & O_NOFOLLOW)){
int cycle = 0;
char target[MAXPATH];
while(ip->type == T_SYMLINK){
if(cycle == 10){
iunlockput(ip);
end_op();
return -1;
}
cycle++;
memset(target, 0, sizeof(target));
readi(ip, 0, (uint64)target, 0, MAXPATH);
iunlockput(ip);
if((ip = namei(target)) == 0){
end_op();
return -1;
}
ilock(ip);
}
}
}
if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){
...
}
Lab: mmap
mmap和munmap系统调用允许UNIX程序对它们的地址空间施加详细的控制。它们可用于在进程之间共享内存,将文件映射到进程地址空间,并作为用户级页面故障方案(如讲座中讨论的垃圾收集算法)的一部分。在本实验中,您将向xv6添加mmap和munmap,重点关注内存映射文件。
手册页(run man 2 mmap)显示了mmap的声明:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);Mmap可以通过多种方式调用,但是本实验只需要它与文件的内存映射相关的功能的一个子集。您可以假设addr将始终为零,这意味着内核应该决定映射文件的虚拟地址。Mmap返回该地址,如果失败则返回0xffffffffffffffff。Length是要映射的字节数;·它可能与文件的长度不同。Prot表示内存是否应该映射为可读、可写和/或可执行;您可以假设prot是PROT_READ或PROT_WRITE,或者两者都是。标志可以是MAP_SHARED,这意味着对映射内存的修改应该被写回文件,或者是MAP_PRIVATE,这意味着不应该被写回文件。你不需要在标志中实现任何其他的位。Fd是要映射的文件的打开文件描述符。您可以假设offset为零(它是要映射的文件中的起始点)。
如果映射相同MAP_SHARED文件的进程不共享物理页面,则没关系。Munmap (addr, length)应该删除指定地址范围内的mmap映射。如果进程修改了内存并将其映射为MAP_SHARED,则应该首先将修改写入文件。munmap调用可能只覆盖映射区域的一部分,但是您可以假设它将在开始或结束时取消映射,或者整个区域(但不会在区域中间打孔)。具体来说,
munmap可以用来解除对内存的映射,但是它要么从映射的开始处解除映射,要么从映射的结束处解除映射,要么整个区域都解除映射。这确保了在映射的中间不会留下未映射的空间或“洞”。您应该实现足够的mmap和munmap功能,以使mmaptest测试程序工作。如果mmaptest不使用mmap特性,则不需要实现该特性。
以下是一些提示:
- 首先将_mmaptest添加到UPROGS,以及mmap和munmap系统调用,以便编译user/mmaptest.c。现在,只从mmap和munmap返回错误。我们在kernel/fcntl.h中为您定义了PROT_READ等。运行mmaptest,它将在第一次mmap调用时失败。
- 惰性地填充页表,以响应页错误。也就是说,mmap不应该分配物理内存或读取文件。相反,应该在usertrap中(或由usertrap调用)的页面错误处理代码中这样做,就像在惰性页面分配实验室中一样。偷懒的原因是为了确保对大文件的mmap是快速的,并且对大于物理内存的文件的mmap是可能的。
- 跟踪mmap为每个进程映射的内容。定义一个与第15讲中描述的VMA(虚拟内存区域)相对应的结构,记录地址、长度、权限、文件等。对于由mmap创建的虚拟内存范围。由于xv6内核在内核中没有内存分配器,因此可以声明一个固定大小的vma数组,并根据需要从该数组进行分配。16号的就足够了。
- 实现mmap:在要映射文件的进程地址空间中找到一个未使用的区域,并将VMA添加到映射区域的进程表中。VMA应该包含指向被映射文件的struct文件的指针;Mmap应该增加文件的引用计数,这样当文件关闭时结构就不会消失(提示:参见filedup)。运行mmaptest:第一个mmap应该会成功,但是第一次访问映射后的内存将导致页面错误并终止mmaptest。
- 添加代码以在映射区域中导致页面错误,从而分配物理内存页,将4096字节的相关文件读入该页,并将其映射到用户地址空间。使用readi读取文件,它接受一个偏移量参数,在该参数处读取文件(但是必须锁定/解锁传递给readi的inode)。不要忘记在页面上正确设置权限。mmaptest运行;它应该到达第一个munmap。
- 实现munmap:查找地址范围的VMA并取消指定页面的映射(提示:使用uvmunmap)。如果munmap删除前一个mmap的所有页面,它应该减少相应结构文件的引用计数。如果未映射的页面被修改,并且该文件被映射为MAP_SHARED,则将该页写回该文件。从filewrite中寻找灵感。
- 理想情况下,您的实现只回写程序实际修改过的MAP_SHARED页面。RISC-V PTE中的脏位D (dirty bit)表示页面是否被写入。然而,mmaptest并不检查非脏页是否没有回写;因此,您可以在不查看D位的情况下写回页面。
- 修改exit以取消进程的映射区域,就像调用了munmap一样。mmaptest运行;Mmap_test应该可以通过,但可能不能通过fork_test。
- 修改fork以确保子进程具有与父进程相同的映射区域。不要忘记增加VMA结构文件的引用计数。在子进程的页面错误处理程序中,可以分配一个新的物理页面,而不是与父进程共享一个页面。后者会更酷,但需要更多的执行工作。mmaptest运行;它应该同时通过mmap_test和fork_test。
先实现添加系统调用的基本流程
user/user.h
void* mmap(void *addr, int length, int prot, int flags, int fd, uint offset);
int munmap(void *addr, int length);
usys.pl
entry("mmap");
entry("munmap");
syscall.h
#define SYS_mmap 22
#define SYS_munmap 23
kernel/syscall.c
extern uint64 sys_mmap(void);
extern uint64 sys_munmap(void);
...
[SYS_mmap] sys_mmap,
[SYS_munmap] sys_munmap,Makefile
$U/_mmaptest\对于mmap,建议看一下这篇博客,让我对mmap的了解非常透彻。
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);从描述符为 fd 的文件的offset处映射length 个字节到 addr 开始的位置。
prot 和 flags 都是一些标志位,prot 有以下的选项:
- PROT_NONE
- PROT_READ
- PROT_WRITE
- PROT_EXEC
规定了能对映射后文件做的操作。
flags 则决定,如果在内存映射文件中做了修改,是否要在取消映射时,把这些修改更新到文件中:
- MAP_SHARED
- MAP_PRIVATE
首先需要在用户的地址空间内,找到一片空闲的区域,用于映射 mmap 页。根据xv6进程的地址空间,为了尽量使得 mmap 的文件使用的地址空间不要和进程所使用的地址空间产生冲突,这里选择将 mmap 映射进来的文件 map 到尽可能高的位置,也就是刚好在 trapframe 下面,并且若有多个 mmap 的文件,则向下生长。如果从heap开始处使用的话,进程刚好又要sbrk()使用堆区,那么就会造成相互覆盖。
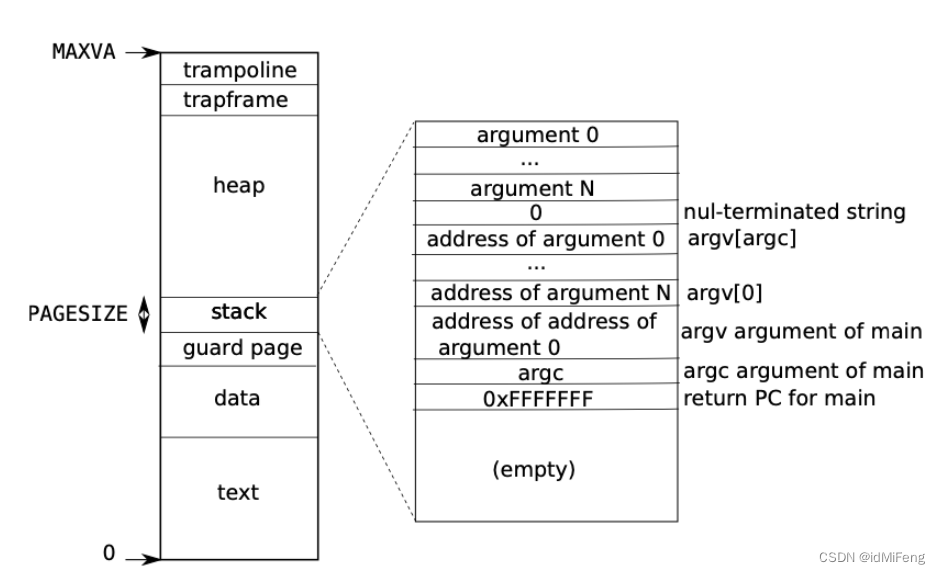
定义vma结构体,并且在 proc 结构体末尾为每个进程加上 16 个 vma 空槽(struct proc 添加 struct vma vmas[16]字段)。
struct vma {
int valid; // 标志位,如未使用为0,使用为1
uint64 start; // 映射开始的地方
uint64 length; // 映射长度
struct file *f; // 映射文件
int prot;
int flags;
uint64 offset;
};实现sys_mmap(),大概思路就是用 TRAPFRAME 作为所使用的最高地址(end),那么对于每个映射文件,它的起始地址就是end - sz(文件大小) 并向下对页面取整。若要加入下一个文件,那么下一个文件就用上一个文件的起始地址作为end,起始地址同样为end-sz。最后记得调用fileup()增加文件引用计数。
uint64
sys_mmap(void)
{
uint64 addr, sz, offset;
int prot, flags, fd;
struct file *f;
argaddr(0, &addr);
argaddr(1, &sz);
argint(2, &prot);
argint(3, &flags);
argfd(4, &fd, &f);
argaddr(5, &offset);
// 阻止了对以只读模式打开的文件进行读写映射
if((!f->readable && (prot & (PROT_READ))) || (!f->writable && (prot & PROT_WRITE) && !(flags & MAP_PRIVATE)))
return -1;
struct proc *p = myproc();
uint64 end = PGROUNDDOWN(TRAPFRAME);
struct vma *v;
for(int i=0;i<16;i++) {
v = &p->vmas[i];
if(v->valid == 0){
v->valid = 1;
break;
}else if(v->start < end){
end = PGROUNDDOWN(v->start);
}
}
v->length = sz;
sz = PGROUNDUP(sz);
v->start = end-sz;
v->prot = prot;
v->flags = flags;
v->f = f;
v->offset = offset;
filedup(v->f);
return v->start;
}
此时这些虚拟地址还没有映射到实际的物理地址,需要对映射的页实行懒加载,仅在访问到的时候才从磁盘中加载出来,在中断处理程序trap.c的usertrap()进行修改,和之前COW的lab差不多。r_scause() 的值为13或15说明发生了读写过程的缺页错误。对发生缺页的虚拟地址调用mmap_hander()处理函数,逻辑就是先调用kalloc()分配一个物理页,并把物理页全部设置为0,因为根据要求在页面中除了映射的文件内容,其他部分都要为0。然后调用readi()把文件内容读要物理页中,最后调用mappages()映射该物理页。注意vma结构体和相关辅助函数声明都要添加到defs.h。
//trap.c
//...
else if((which_dev = devintr()) != 0){
// ok
} else if(r_scause() == 13 || r_scause() == 15){
uint64 va = r_stval();
struct vma *vma = 0;
for (int i = 0; i < 16; i++) {
if (p->vmas[i].valid == 1 && va >= p->vmas[i].start && va < p->vmas[i].start + p->vmas[i].length) {
vma = &p->vmas[i];
break;
}
}
if(vma) {
va = PGROUNDDOWN(va);
if(mmap_hander(p->pagetable,va,vma) != 0){
panic("usertrap: mmap_hander");
};
}
} else {
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
setkilled(p);
}
//...
//sysfile.c
int
mmap_hander(pagetable_t pagetable,uint64 va,struct vma *vma)
{
uint64 offset = va - vma->start;
uint64 mem = (uint64)kalloc();
memset((void*)mem, 0, PGSIZE);
ilock(vma->f->ip);
readi(vma->f->ip, 0, mem, offset, PGSIZE);
iunlock(vma->f->ip);
int flag = PTE_U;
if(vma->prot & PROT_READ) flag |= PTE_R;
if(vma->prot & PROT_WRITE) flag |= PTE_W;
if(vma->prot & PROT_EXEC) flag |= PTE_X;
if(mappages(pagetable, va, PGSIZE, mem, flag) != 0) {
kfree((void*)mem);
return -1;
}
return 0;
}照此逻辑,读文件映射内容的时候会读到页面中数据是0的那部分,此时不应该报错,所以要修改vm.c,遇到这些地址直接跳过即可。
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
...
if((*pte & PTE_V) == 0)
continue;
//panic("uvmunmap: not mapped");
...
}
最后实现 munmap(),取消虚拟地址的映射关系。
- 通过
argaddr和argint函数获取传入参数addr和length的值,并对其进行舍入处理。 - 通过循环遍历当前进程的 VMA列表,找到包含给定地址的 VMA。
- 如果找到了对应的 VMA,则根据 VMA 的属性进行相应的处理:
- 更新 VMA 的起始地址和长度,并根据 VMA 的属性执行相应操作,如写回文件(如果是共享映射)、取消页面映射等。
- 如果 VMA 的长度变为 0,则表示映射已经被完全取消,此时关闭关联的文件,并将 VMA 标记为无效。
uint64
sys_munmap(void)
{
uint64 addr;
int length;
struct proc *p = myproc();
struct vma *vma = 0;
argaddr(0, &addr);
argint(1, &length);
addr = PGROUNDDOWN(addr);
length = PGROUNDUP(length);
for(int i = 0; i < 16; i++) {
if (addr >= p->vmas[i].start || addr < p->vmas[i].start + p->vmas[i].length) {
vma = &p->vmas[i];
break;
}
}
if(vma == 0) return 0;
vma->start += length;
vma->length -= length;
if(vma->flags & MAP_SHARED)
filewrite(vma->f, addr, length);
uvmunmap(p->pagetable, addr, length/PGSIZE, 1);
if(vma->length == 0) {
// 如果munmap删除前一个mmap的所有页面,它应该减少相应结构文件的引用计数
fileclose(vma->f);
vma->valid = 0;
}
return 0;
}
fork 和 exit 函数。在进程创建和退出时,需要复制和清空相应的文件映射,这样子进程尝试访问 mmap 页的时候,会重新触发懒加载,重新分配物理页以及建立映射。
//fork()
//...
memmove(&np->vmas, &p->vmas,sizeof(p->vmas));
for(int i=0;i<16;i++)
{
if(p->vmas[i].valid!=0)//如果存在映射
{
filedup(p->vmas[i].f);
}
}
//...
//exit()
//...
for(int i = 0; i < 16; i++) {
if(p->vmas[i].valid) {
if(p->vmas[i].flags & MAP_SHARED)
filewrite(p->vmas[i].f, p->vmas[i].start, p->vmas[i].length);
fileclose(p->vmas[i].f);
uvmunmap(p->pagetable, p->vmas[i].start, p->vmas[i].length/PGSIZE, 1);
p->vmas[i].valid = 0;
}
}
//...