文章信息
论文题目:FINN: Fingerprinting Network Flows using Neural Networks
期刊(会议):Annual Computer Security Applications Conference
时间:2021
级别:CCF B
文章链接:https://dl.acm.org/doi/pdf/10.1145/3485832.3488010
概述
有关流量分析的工作分为两类。一些工作重点是被动地分析网络流量,这需要相对较长的流量才能表现良好。另一种方法是扰乱网络流量的某些特征以嵌入一位或多位信息。这种方法被称为主动流量分析。主动流量分析更高效,需要更短的流量来链接流量。然而,它们可能会给数据包引入较大的延迟,这可能会影响正常用户的活动,也可能会暴露它们。在这项工作中,我们专注于主动流量分析。
主动流量分析中比较常见的是水印,它试图将单一比特信息嵌入到流量中。在水印中,涉及到两个实体:水印生成器和检测器。水印制作者接收流量并插入单一比特数据,传达有关流量是否被加水印的信息。检测器在网络的另一侧接收消息并试图解码这个消息。最近提出的(并且研究较少)一种主动流量分析的变体称为流指纹识别。指纹识别用于将多个比特信息嵌入到流量中,传达更复杂的数据,例如流量的来源。在这项工作中,我们提出了一种新颖的流指纹识别技术,如下所述。
我们通过提出一种名为FINN的新系统,迈出了设计实用的盲流指纹识别技术的第一步。我们的工作受到DeepCorr的启发,后者利用神经网络对网络流进行被动相关操作。FINN通过轻微延迟数据包并保持指纹不可见(以逃避检测和避免干扰良性流量)将指纹插入流中。FINN使用在大型网络流语料库上训练的DNN来决定如何为每个目标连接生成这种指纹延迟。我们进行了FINN的模拟以评估其性能,并使用统计量来评估其不可见性。为了确保我们的指纹延迟的隐形性,我们还设计了一种新颖的基于GAN的技术,利用拉普拉斯分布生成指纹延迟,以便与自然网络噪音不可区分。
威胁模型
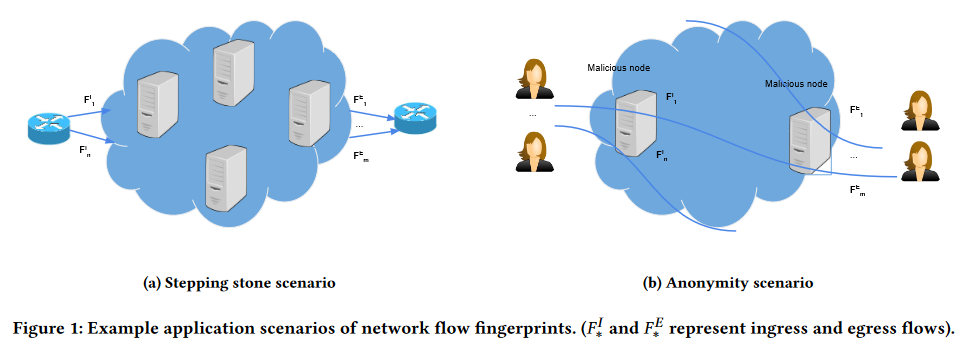
本文研究的问题是流指纹技术。流指纹技术有两个主要应用:去匿名化Tor和跳板检测。流指纹系统由两个实体组成:指纹生成器(编码器)和提取器(解码器)。指纹生成器将消息插入到网络流中,解码器尝试从流中提取插入的消息。
检测跳板攻击者是我们的主要攻击场景。跳板攻击者通过企业中的受损机器中继其流量,以隐藏其身份。图1a展示了这种情景,指纹生成器放在在企业的边界路由器上,并向传入的流中插入指纹。然后,它尝试从企业的传出流中提取插入的指纹。在部署攻击中涉及了两个受损实体。
此外,Tor通过三个节点(入口、中间和出口节点)隧道化网络流量,以实现匿名通信。在Tor情景中,攻击者控制一些入口和出口节点。然后,它将消息插入入口节点的传入流,并在出口节点中提取插入的消息。这样做将入口和出口节点中的流关联起来,从而破坏了Tor的匿名性。例如,图1b中的攻击者可以使用两个受损的卫兵和出口中继来去匿名化Tor连接。
本文方案
在这一部分中,我们使用神经网络设计了一种流指纹技术。对于企业,流指纹技术可以检测被用于中继入侵者流量的受损机器。我们的系统通过延迟流中的数据包来嵌入秘密指纹。先前的方法使用统计方法来进行指纹识别,这需要仔细选择要操纵以嵌入指纹的特征。我们在设计中利用神经网络来避免使用手动过程来嵌入和提取指纹的限制。神经网络学习流量并从中提取复杂特征,而不是使用精心设计的特征。在设计我们的系统时,我们遵循几个主要目标:不可见性(Invisibility)、鲁棒性(Robustness)、可伸缩性(Scalability)、速度(Speed)。
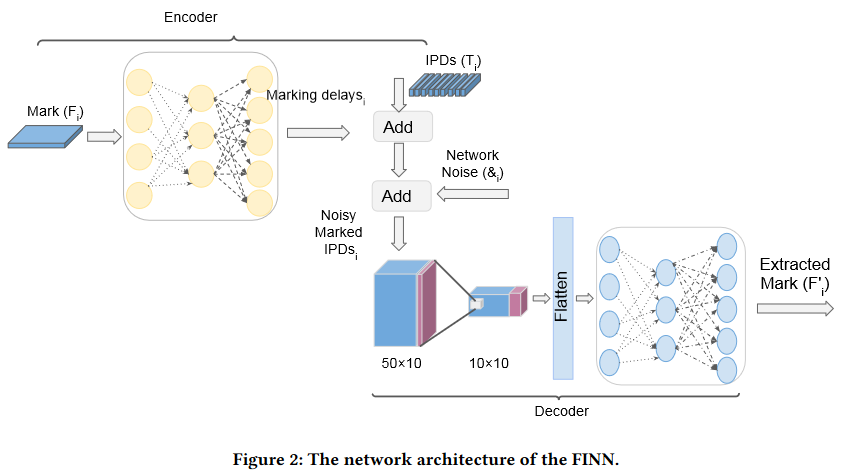
接下来,我们介绍FINN的设计,它由两个主要组件组成:指纹器(编码器)和提取器(解码器)。编码器将秘密指纹嵌入流中。解码器从流中提取指纹。图2显示了这两个组件的架构。
模型的输入如下:
I n p u t = [ F i , & i ] Input=[F_{i},\&_{i}] Input=[Fi,&i]
其中 F i F_{i} Fi是我们打算嵌入到流i中的指纹, & i \&_{i} &i是流i上的网络噪声。注意 T i T_{i} Ti和 & i \&_{i} &i的大小为N,而 F i F_{i} Fi的长度为 l l l。 F i F_{i} Fi是一个全零向量,只有一个1。
编码器:一个全连接的网络。 它将 F i F_{i} Fi和 & i \&_{i} &i传递给一个具有四个隐藏层的全连接网络,以生成指纹延迟。 这个指纹延迟用于延迟流i中的数据包,以嵌入 F i F_{i} Fi的秘密指纹。 全连接网络的层大小为1000、2000、2000和1000,并且有一个输出N,这是我们的指纹延迟。指纹延迟和包间延迟(IPD) T i T_{i} Ti、网络噪声 & i \&_{i} &i相加形成新的向量,以创建带有噪声的带有指纹的IPD,这将成为解码器的输入。
解码器:当流(IPD)通过网络并累积网络噪音时,解码器接收这些流。我们的解码器由两部分组成:卷积部分和全连接部分。卷积部分负责去噪和去除流中添加的额外网络噪音。全连接部分负责解码嵌入的指纹。卷积层的核大小都为10,卷积核的数量分别为50和10。 卷积部分的输出被展开(flatten layer)以馈送到全连接网络。 第一个全连接层的大小为256,第二个全连接层的大小为指纹长度。 我们使用Softmax函数来规范解码器的输出。 Softmax将输出缩放在0和1之间。 输出向量的每个元素都是相应元素为1的概率。为了获得一个One-hot格式的提取指纹,我们让最大的元素为1,其余为0。该输出是 F i ′ F_{i}' Fi′,它是提取的指纹。
训练
正如我们前面提到的,FINN有两个主要组成部分:编码器和解码器。编码器负责为每个流生成指纹延迟,解码器负责从指纹流中提取指纹。我们定义了两个损失函数:解码器损失和编码器损失,以控制每个任务的工作效果。对于第一个任务,我们使用平均绝对误差(MAE)来试图减少指纹生成中的错误。对于第二个任务,我们使用分类交叉熵来最小化解码所嵌指纹时的错误。编码器损失是一个MAE损失。我们调整这些损失函数的权重( K w K_{w} Kw和 I w I_{w} Iw)以达到所需的鲁棒性和隐形性。随着 K w K_{w} Kw的增加,我们将更多的权重放在减少指纹提取错误上。
在损失函数中,n是训练数据的大小,K是可能指纹的数量,y是观测值o属于类c(1或0)的二进制指示器,p是观测值属于类c的概率。我们使用Adam优化器来最小化损失:
L = I w n ∣ ∑ i = 1 n I ^ i ∣ + K w n ∑ i = 1 n ∑ c = 1 K − y o , c i log p o , c \mathcal{L}=\frac{I_{w}}{n}\left|\sum_{i=1}^{n} \hat{I}_{i}\right|+\frac{K_{w}}{n} \sum_{i=1}^{n} \sum_{c=1}^{K}-y_{o, c}^{i} \log p_{o, c} L=nIw
i=1∑nI^i
+nKwi=1∑nc=1∑K−yo,cilogpo,c
实验设置
数据集
编码器采用IPD和指纹以生成指纹延迟。 解码器接收嵌入了指纹的IPD(将指纹延迟和IPD相加的产物)并提取所嵌入的指纹。 我们有额外的网络噪声输入,以便从带指纹的流中进行鲁棒地提取指纹。要训练我们的模型,我们需要用五元组(IPD,指纹,指纹延迟,网络噪声)喂给我们的网络。 接下来,我们将解释我们为每个五元组组成部分使用的数据集。
IPD:我们使用CAIDA的2016年和2018年的匿名跟踪来构建我们的IPD数据集。我们使用CAIDA,因为我们希望拥有真实网络跟踪的IPD,以模拟实际的网络流量。我们基于端点主机的IP地址、端口号和协议类型提取此数据库中的流,这足以区分网络连接。请注意,我们构建每个流时只考虑两个端点主机之间的流量的一侧,因为在指纹识别中,我们只能访问连接的一侧。
指纹: 指纹是我们嵌入每个流中的消息。关于指纹有两种选择要考虑:二进制或one-hot表示法。我们使用one-hot编码来构建我们的指纹数据集。one-hot是K个比特的集合,其中只有一个1。假设我们想要在每个流中嵌入2位信息。使用二进制表示,我们有以下选项作为秘密消息:01、00、11、10。对于one-hot表示法,我们编码时有以下选项:0001、0010、0100、1000。我们选择第二种格式来作为我们的指纹,因为它能给我们更好的性能。这是因为我们正在使用分类损失作为解码器损失,当其数据具有one-hot表示法时,效果更好。在我们上述的one-hot示例中,指纹长度K为4,这使我们能够在每个流中嵌入 log 2 K \log_{2}{K} log2K位。
指纹延迟:为了训练我们的模型,我们需要为许多(流,指纹)对构建指纹延迟。在这里,我们描述如何生成这些指纹延迟。假设我们有一个具有以下时序的网络流: f i = { t 0 , t 1 , ⋯ , t n } f_{i}=\{t_{0},t_{1},\cdots ,t_{n}\} fi={ t0,t1,⋯,tn}。我们计算数据包之间的延迟: i p d i = { t 1 − t 0 , t 2 − t 1 , ⋯ , t n − t n − 1 } ipd_{i}=\{t_{1}-t_{0},t_{2}-t_{1},\cdots ,t_{n}-t_{n-1}\} ipdi={ t1−t0,t2−t1,⋯,tn−tn−1},并延迟数据包,使得 i p d i ipd_{i} ipdi的第j个元素变为 i p d i j = i p d i j + α i j ipd_{ij}=ipd_{ij}+\alpha_{ij} ipdij=ipdij+αij。指纹延迟的组成部分如下:
指纹延 迟 i = { α i 0 , α i 1 , ⋯ , α i ( n − 1 ) } 指纹延迟_{i}=\{\alpha_{i0},\alpha_{i1},\cdots ,\alpha_{i(n-1)}\} 指纹延迟i={ αi0,αi1,⋯,αi(n−1)}
其中 α i j \alpha_{ij} αij来自标准差为 α i \alpha_{i} αi的拉普拉斯分布。我们根据每个网络连接中噪声的标准差来选择 α i \alpha_{i} αi。为了将指纹嵌入流中,指纹生成器使用以下公式延迟第i个流中的第j个数据包,也就是前面的数据包的 α i n \alpha_{in} αin求和:
∑ n = 0 n = ( j − 1 ) α i n \sum_{n=0}^{n=(j-1)} \alpha _{in} ∑n=0n=(j−1)αin
我们需要选择足够大的 α i 0 \alpha_{i0} αi0来避免数据包出现负延迟。此外,我们必须尽量选择小的 α i \alpha_{i} αi以避免被对手检测到指纹。如上所述,我们为每一对(流,指纹)生成指纹延迟。由于我们为每一对随机生成全部的 α i \alpha_{i} αi,因此我们期望实现高不可见性。
网络噪声:网络噪声是我们指纹模型的主要输入之一。由于网络抖动会延迟数据包并可能最终移除嵌入的消息,我们需要将其输入我们的模型进行去噪。如果链接的抖动很大,我们需要嵌入更高幅度的指纹来抵抗网络抖动,反之亦然。我们通过发送多个数据包到链路中来估计这种抖动,并使用抖动的标准差作为我们指纹的幅度。
评估指标
- 提取率(ER): 从指纹流中成功提取的指纹数与所有指纹流数量的比率。这个度量标准显示了由于网络噪音而丢失其嵌入式指纹的指纹流的数量。
- 误比特率(BER): 每个错误提取的指纹所发生的错误比特数。我们将每个指纹转换为其二进制表示以计算比特率错误。这个度量标准显示了由于网络噪声引起的波动而改变的比特数。
超参数选择
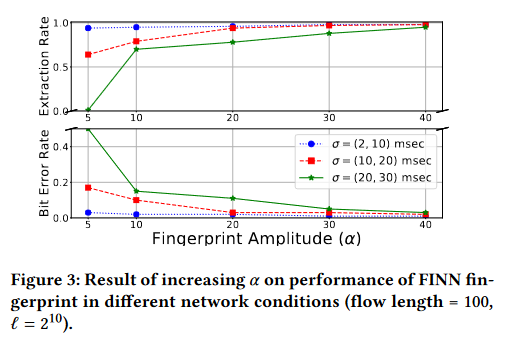
表1显示了FINN的主要参数,包括 I w I_{w} Iw和 K w K_{w} Kw。 I w I_{w} Iw是我们编码器损失的权重,选择较大的 I w I_{w} Iw可以增强FINN的隐蔽性。 K w K_{w} Kw是解码器损失的权重,选择较大的数字可以提高FINN的性能。此外,我们使用噪声的标准偏差( σ \sigma σ)在 ( 2 , 10 ) (2,10) (2,10)毫秒的范围内训练我们的模型。这是因为我们在实验中使用的节点显示出这个范围的噪声标准偏差。此外,在我们的实验中,对于 α \alpha α的值,我们也选择这个范围内的值。
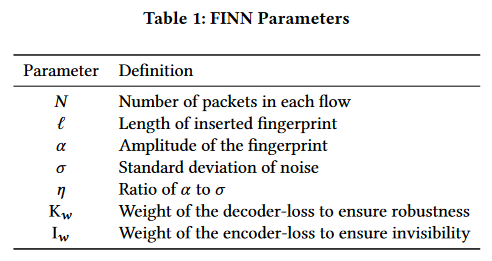
表2详细显示了编码器和解码器的结构。

仿真
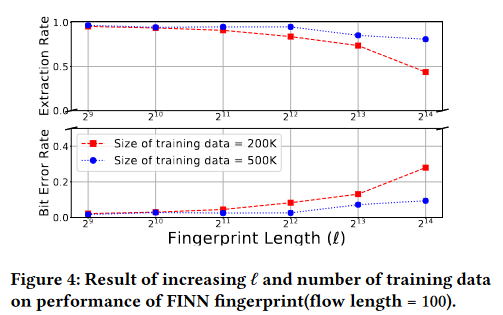
指纹长度l对性能的影响
图4显示了增加l和训练数据大小对FINN性能的影响。
指纹幅度( α \alpha α)对性能的影响
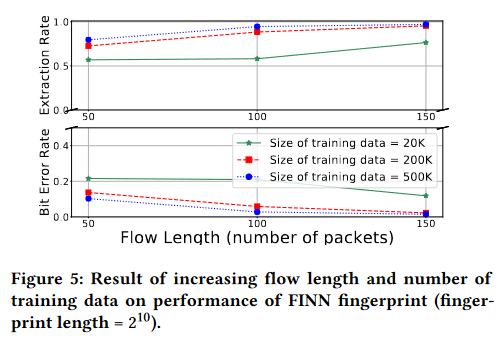
增加流长度的影响
流长度是FINN的另一个主要参数。正如预期的那样,增加它会提高系统的性能。我们的目标是找到在固定其他参数(指纹长度为1024、 σ ∈ ( 2 , 10 ) \sigma \in (2,10) σ∈(2,10))时用于指纹嵌入的最佳数据包数量。图5显示了我们实验的结果。
FINN作为一个水印
这里,我们用两个密钥(0和1)来训练我们的模型,以区分带水印的(真实流)和无水印的流(虚假流)。当密钥为0时,我们不给流加水印,当密钥为1时,我们向流添加水印。图12展示了我们的水印系统。如图所示,该系统由两个组件组成:编码器和解码器,从FINN指纹系统中借鉴而来。我们在这里介绍三个参数:选择器, f w f_{w} fw和 t w t_{w} tw。选择器将模型分为两部分:水印和非水印。选择器是一个由全为1或0的向量,取决于相应流的类型。它将乘以水印延迟,其结果加到IPD中。它确保真实流通过将在全为1的数组中乘以它,加到水印延迟中以生成带水印的IPD,并且假流加到0上保持完整。

评估系统的两个指标是真阳(TP)和假阳(FP)。另外,我们使用两个权重来指定每个类的重要性。我们用 f w f_{w} fw来衡量FP类,用 t w t_{w} tw来衡量TP类。增加这些权重意味着我们更关注特定的指标。
对于特定的链路,错误率是水印振幅( α \alpha α)和流长度( l l l)的函数。选择适当的水印振幅取决于链路的抖动。对于抖动大的链路,我们需要使用较大的振幅,而对于抖动小的链路,我们需要使用较小的振幅。我们定义 η \eta η为水印振幅与链路抖动标准偏差的比值。通过增加这个参数,我们预期可以获得更好的真阳性和假阳性。在选择这个参数时,我们需要记住增加这个参数会降低系统的隐匿性。图15显示了在 η \eta η取值为[2, 1, 0.75, 0.5, 0.25]时的结果。

现实世界实施
我们实时应用FINN来评估它在实际网络流中的效果。我们在Ubuntu Linux上实施FINN(版本5.4.0-58-generic),使用iptables(版本1.8.4),以及使用libnetfilter_queue库(版本1.0.4)。我们向iptables的OUTPUT链添加规则以保留数据包,并且我们的程序利用libnetfilter_queue库对其进行指纹识别。为了评估FINN的性能,我们在校园内建立了一个编码器和一个译码器,译码器是位于班加罗尔的一个Digital Ocean节点。我们的目标是看看FINN在实时设置中是否有效。请注意,我们使用的网络流是从CAIDA数据集中提取的重放SSH连接。为了在不同的网络条件下评估我们的系统,我们将班加罗尔节点替换为全球的七个Amazon EC2节点,并进行相同的实验证。此外,我们在蜂窝网络上测试FINN,以确保它在不同的网络设置上运行。
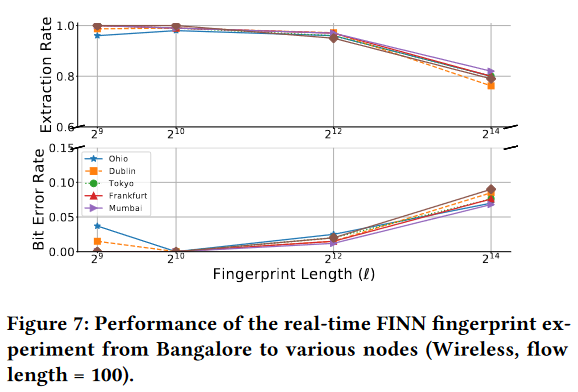
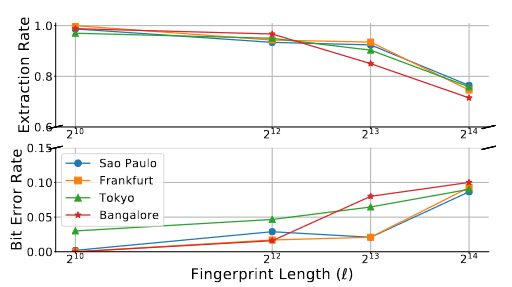
指纹长度对性能的影响
图7显示了全球八个不同节点的实验结果。编码器(指纹生成器)位于校园内的个人电脑上,而解码器位于七个亚马逊EC2节点和孟买的一个数字海洋节点上。
无线接入点上的实验
为此,我们使用2.4GHz带宽热点连接手机网络,并将PC连接到该网络(编码器)。解码器设置在班加罗尔节点上。图8显示了我们在班加罗尔和法兰克福两个节点的不同l实验的结果。
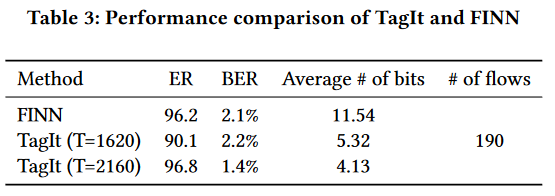
比较FINN与先前的方法
FINN的可扩展性
CICS的研究生员工和教职员工人数约为450人。我们唯一存储的是训练模型,其大小约为3MB。我们计算从流中解码指纹所需的时间,在最坏的情况下,每个人都有一个连接。在3.5 GHz的Ubuntu机器上,对 N = 100 N=100 N=100和 l = 2 12 l=2^{12} l=212的450个流进行FINN的解码,需要1.57秒。请注意,随着组织规模的增大,这个时间是线性增加的。对于规模更大的组织,我们可能需要一个普通的个人电脑。对于更大的组织,每个子网络都可以运行自己的指纹系统。我们的系统在网关上运行,路由器连接到网关发送IPD。然后,网关运行编码器模型并返回其输出,指纹延迟,给路由器。路由器使用接收到的指纹延迟来延迟当前数据包。我们的指纹系统所需的平均流量大小和时间分别为155KB和6.2秒。
指纹不可见性
为了研究我们系统的隐身性,我们使用KS检验,该检验已经被用于检测在流中添加的IPD的水印。
生成对抗网络
生成对抗网络是一种机器学习模型,由Ian Goodfellow等人提出。在GAN框架中,两个模型竞争赢得零和博弈。在学习结束时,模型学习以与训练数据相同统计特性生成新数据。GAN框架由两个竞争者组成:鉴别器和生成器。鉴别器通过真实数据和假数据进行训练。真实数据是我们有兴趣生成的数据。假数据是一组随机生成的数据。鉴别器试图区分真实和假数据。生成器试图生成类似真实数据以愚弄鉴别器的数据。GAN已被用于生成逼真的图像、人脸、图像到图像的转换、文本到图像的转换等。在这里,我们使用GAN来创建拉普拉斯指纹延迟。这样可以提高系统的隐形性,因为添加到流中的指纹延迟在网络抖动中丢失,而流抖动也具有拉普拉斯分布。生成器和提取器借用自我们的原始模型。鉴别器是一个大小为100的单层的全连接网络。鉴别器使用二元交叉熵作为其损失函数。图9显示了使用GAN时的FINN的架构。
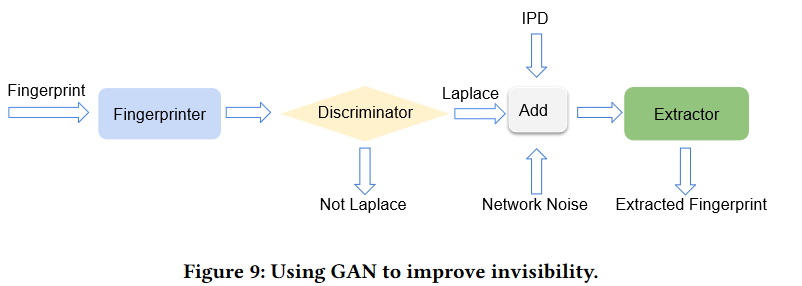
结构细节:
- 使用拉普拉斯和均匀数据来训练鉴别器。
- 冻结鉴别器并训练生成器(指纹生成器)以生成拉普拉斯指纹延迟。
- 冻结生成器和鉴别器。将噪声和IPD输入到提取器中。有一个Add层将IPD、噪声和生成器的输出相加。训练提取器。
KS相似性检验
K-S检验用于确定一个流是否来自特定分布,或者通过测量流之间的最大距离来确定两个流是否属于同一分布。在第二种情况下,K-S统计是:
D n , m = s u p x ∣ F 1 , n ( x ) − F 1 , m ( x ) ∣ D_{n,m}=\underset{x}{sup} \left | F_{1,n}(x)-F_{1,m}(x) \right | Dn,m=xsup∣F1,n(x)−F1,m(x)∣
F 1 , n F_{1,n} F1,n和 F 1 , m F_{1,m} F1,m是第一和第二个流的经验分布。如果 D n , m > c ( α ) n + m n m D_{n,m}>c(\alpha)\sqrt{\frac{n+m}{nm} } Dn,m>c(α)nmn+m,就要在水平 α \alpha α下拒绝零假设(两个流来自同一个分布)。其中n和m是两个流的大小, c ( α ) = − 0.5 ln α c(\alpha)=\sqrt{-0.5\ln_{}{\alpha } } c(α)=−0.5lnα。
我们的参数设置为流长度为100和指纹长度为1024,并使用500个带指纹和不带指纹的流来评估我们指纹系统的隐形性。我们在班加罗尔节点进行调查,噪声的标准偏差为2-10毫秒。图10显示了我们数据的K-S检验结果。

聚类
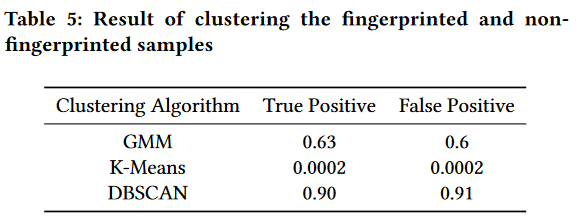
我们使用聚类算法来查看已指纹化和未指纹化的样本是否可以分为两组。我们使用Python Scikit-learn软件包中的三种主要聚类算法:基于分布、基于中心和基于密度的聚类。
基于分布的聚类是指最有可能属于相同分布的样本将被聚类到同一组。这种类型的聚类生成了捕捉属性相关性和依赖性的复杂模型。这种技术的缺点是许多真实数据集可能没有简洁的数学模型。我们使用被称为高斯混合模型的著名方法来对数据集进行聚类。GMM假设数据由若干高斯分布组成。
对于基于中心的聚类,我们使用K-Means算法。K-Means用单个均值向量表示每个聚类,并具有一些有趣的理论属性:它将数据空间分区为称为Voronoi图的结构。它可以被视为基于分布的聚类的一种变体。
DBSCAN是一种基于密度的空间聚类,该方法将连通的密集区域视为一类。在这种方法中,稀疏空间中的数据被视为噪音和异常值,因此被忽略。这种聚类算法适用于发现具有任意形状的聚类。我们使用包间延迟作为聚类任务的特征向量。在我们的指纹实验中使用特征向量的长度为100。为了将特征表示为二维,我们使用主成分分析来降低特征空间的维度。图11显示了指纹化和非指纹化的样本。如图所示,指纹和非指纹流不容易分开。

表5显示了这些聚类算法的结果。所有这三种聚类算法都无法正确地对数据进行分组并提供随机分组。换句话说,它们无法找到一个明确的模式来将指纹流与非指纹流分开。
总结
FINN通过训练学习网络噪声,因此能够给噪声指纹流去噪以解码嵌入的消息。我们通过模拟和实验对我们的系统的性能进行了评估,并在实时网络连接上进行了实验。我们评估了不同参数的影响,并找到了不同设置的最佳值。我们计算FINN的容量为每十个数据包中的0.96位,这几乎是现有技术的两倍。此外,我们表明FINN在实时噪声与训练时不同的条件下表现良好。这一点很重要,因为它使我们不需要为每个不同的网络抖动连接重新训练模型。最后,我们使用K−S检验来测量我们系统的隐形性,并表明攻击者极难检测到我们指纹的存在。
























![力扣精选算法100道——和为 K 的子数组[前缀和专题]](https://img-blog.csdnimg.cn/direct/e60879024ea04c999c08a27af48be633.png)