注:由于上篇帖子(Python进阶--爬取下载人生格言(基于格言网的Python3爬虫)-CSDN博客)篇幅长度的限制,此篇帖子对上篇做一个拓展延伸。
目录
一、爬取格言网中想要内容的url
1、找到想要的内容
在格言网中,里面包含大量类型的格言、经典语录、句子、对联、成语等内容。上篇帖子仅仅只是爬取了人生格言这一部分,如果想要爬取下载其他内容,只需要将上篇帖子的全部代码中的url方面的代码做一个修改,即可爬取你想要的内容。
查看格言网的所有类型的内容步骤如下:
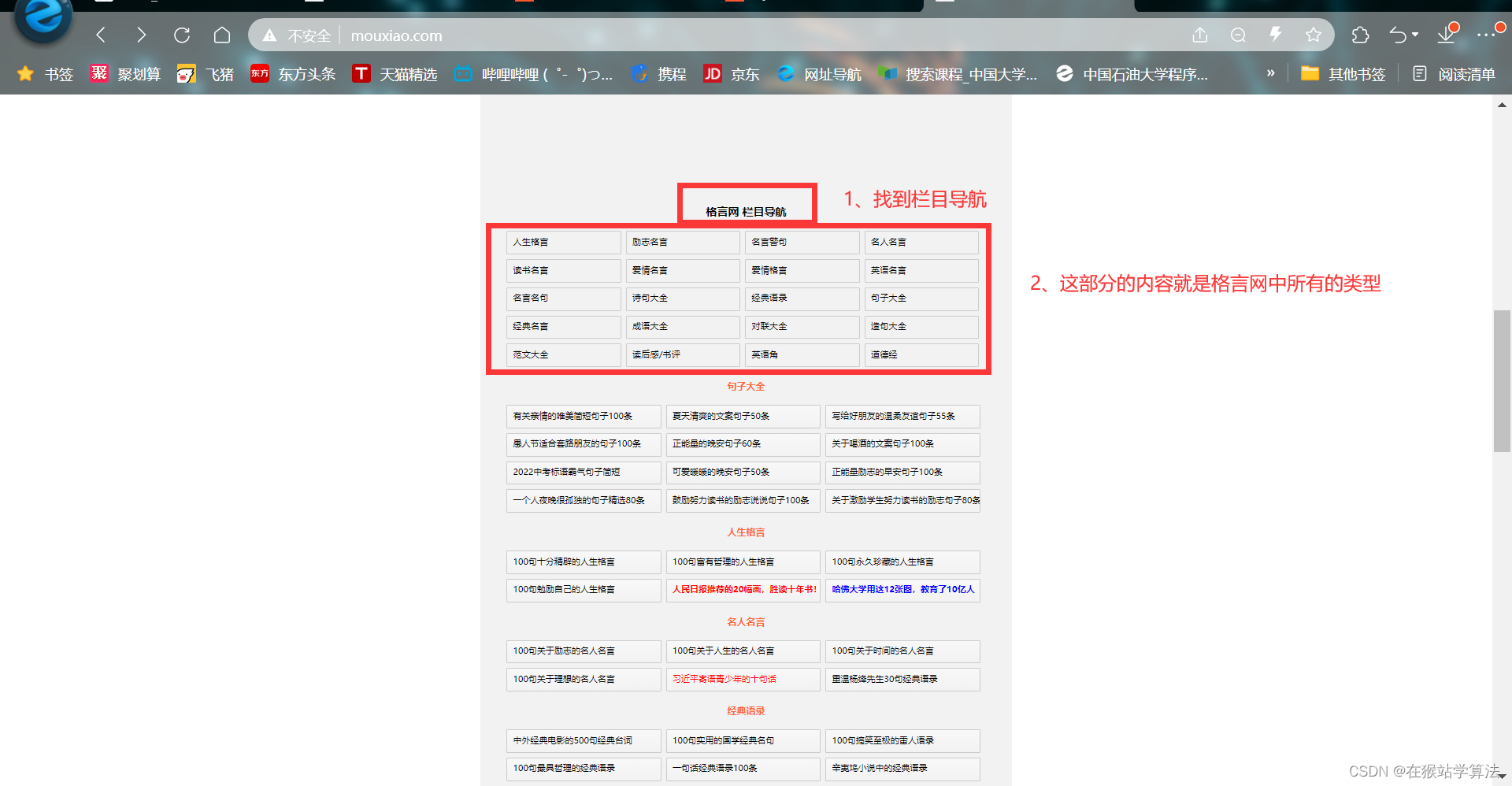
1、打开格言网首页(http://www.mouxiao.com/)
2、往下翻找到栏目导航
3、此部分就是格言网所有类型的内容
注:格言网中其他部分的内容都是此部分的子节点
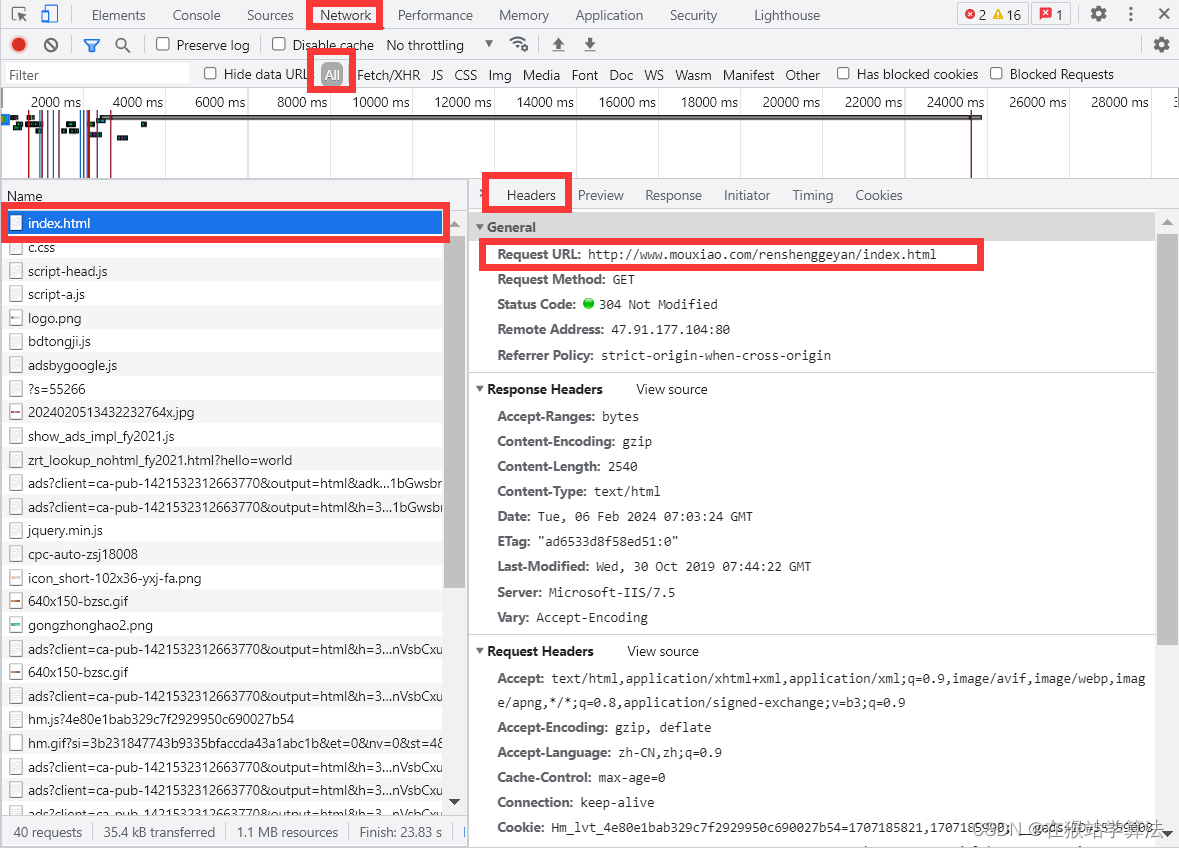
2、抓包分析,找到想要内容的url
根据上篇帖子抓包分析的方式,在此处继续根据此方式进行抓包分析,定位到想要内容的url。

此处,定位到想要内容的url。(开心!!!)
3、改写爬虫代码
思路:将想要内容的url赋给上篇博客代码中的url部分即可
上篇帖子中的所有代码:
import re
import requests
from lxml import etree
# 获取user-agent,用于身份识别
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
# 1、获取具体格言内容和标题
# 封装成一个函数,输入具体人生格言页的地址,获取其具体的人生格言和标题
def get_content(url):
# 请求当前网页的源代码
r = requests.get(url,headers=header)
# 拒绝requests的自动编码,保留源代码
r.encoding = r.apparent_encoding
# 解析源代码提取具体格言内容和标题
# 获取网页源代码
html = etree.HTML(r.text)
# 获取格言内容
content = html.xpath('//div[@class="maike"]/p[@class="p"]/text()')
# 使用 join() 方法将列表中的元素用换行符连接起来
content = '\n'.join(content)
# 获取标题
title = html.xpath('//div[@class="maike"]/h1[@class="title_l"]/text()')[0]
# 返回标题和内容
return title,content
# 当前页面
index_url = 'http://www.mouxiao.com/renshenggeyan/index.html'
# 2、获取各种类型的人生格言链接并下载其具体人生格言内容和标题
# 输入当前人生格言的目录页地址,获取各种类型的人生格言链接并下载其具体人生格言内容和标题
def pageupload_play(index_url):
# 请求当前网页的源代码
r = requests.get(index_url,headers=header)
# 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。
# 故采用apparent_encoding方法,禁止requests模块自动编码。
r.encoding = r.apparent_encoding
# 采用xpath的方式定位获取链接所在位置
html = etree.HTML(r.text)
links = html.xpath('//ul[@class="readers-list"]//a/@href')
# 要匹配所有以数字开头,后面跟 '.html' 的元素,可以遍历列表
matched_links = []
for link in links:
# 采用正则表达式筛选出我们所需要的链接,将其保存到matched_links中
if re.findall(r'^\d+\.html', link):
matched_links.append(link)
# 遍历每个类型人生格言的具体人生格言内容和标题,对其进行下载
for link in matched_links:
# link中获取的链接是相对地址,需要补全前面的地址
link1 = 'http://www.mouxiao.com/renshenggeyan/'+link
# 调用get_content方法下载内容和标题并保存到本地
title, content = get_content(link1)
with open(f'格言/{title}.txt','w',encoding='utf-8') as f:
f.write('\t'+title + '\n\n')
f.write(content)
print(f'已下载...{title}')
# 3、获取下一页的地址
# 封装成一个函数,输入当前页面的url,返回下一页的url
def get_nextpage(url):
#请求当前网页的源代码
r = requests.get(url, headers=header)
# 拒绝requests的自动编码,保留源代码
r.encoding = r.apparent_encoding
# 定位到下一页的url地址
html = etree.HTML(r.text)
next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a/@href')[3]
# 因为所获取的下一页地址是相对地址,故进行补全
next_page = 'http://www.mouxiao.com/renshenggeyan/'+ next_page
# 如果下一页地址和当前页地址不相等,则将下一页地址返回
if next_page != url:
return next_page
# 4、将以上函数排放好顺序进行调用,下载人生格言的全部内容及标题
n = 1
while 1:
print(f"正在下载第{n}页...")
print("下载地址为:"+index_url)
pageupload_play(index_url)
page = get_nextpage(index_url)
index_url = page
if index_url==None:
break
n+=1此处以爬取励志格言为例,只需要将上面部分代码中的url改为励志格言的url即可。
代码如下:
import re
import requests
from lxml import etree
# 获取user-agent,用于身份识别
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
# 1、获取具体格言内容和标题
# 封装成一个函数,输入具体人生格言页的地址,获取其具体的人生格言和标题
def get_content(url):
# 请求当前网页的源代码
r = requests.get(url,headers=header)
# 拒绝requests的自动编码,保留源代码
r.encoding = r.apparent_encoding
# 解析源代码提取具体格言内容和标题
# 获取网页源代码
html = etree.HTML(r.text)
# 获取格言内容
content = html.xpath('//div[@class="maike"]/p[@class="p"]/text()')
# 使用 join() 方法将列表中的元素用换行符连接起来
content = '\n'.join(content)
# 获取标题
title = html.xpath('//div[@class="maike"]/h1[@class="title_l"]/text()')[0]
# 返回标题和内容
return title,content
# 当前页面
index_url = 'http://www.mouxiao.com/lizhimingyan/index.html'
# 2、获取各种类型的人生格言链接并下载其具体人生格言内容和标题
# 输入当前人生格言的目录页地址,获取各种类型的人生格言链接并下载其具体人生格言内容和标题
def pageupload_play(index_url):
# 请求当前网页的源代码
r = requests.get(index_url,headers=header)
# 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。
# 故采用apparent_encoding方法,禁止requests模块自动编码。
r.encoding = r.apparent_encoding
# 采用xpath的方式定位获取链接所在位置
html = etree.HTML(r.text)
links = html.xpath('//ul[@class="readers-list"]//a/@href')
# 要匹配所有以数字开头,后面跟 '.html' 的元素,可以遍历列表
matched_links = []
for link in links:
# 采用正则表达式筛选出我们所需要的链接,将其保存到matched_links中
if re.findall(r'^\d+\.html', link):
matched_links.append(link)
# 遍历每个类型人生格言的具体人生格言内容和标题,对其进行下载
for link in matched_links:
# link中获取的链接是相对地址,需要补全前面的地址
link1 = 'http://www.mouxiao.com/lizhimingyan/'+link
# 调用get_content方法下载内容和标题并保存到本地
title, content = get_content(link1)
with open(f'励志格言/{title}.txt','w',encoding='utf-8') as f:
f.write('\t'+title + '\n\n')
f.write(content)
print(f'已下载...{title}')
# 3、获取下一页的地址
# 封装成一个函数,输入当前页面的url,返回下一页的url
def get_nextpage(url):
#请求当前网页的源代码
r = requests.get(url, headers=header)
# 拒绝requests的自动编码,保留源代码
r.encoding = r.apparent_encoding
# 定位到下一页的url地址
html = etree.HTML(r.text)
next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a/@href')[3]
# 因为所获取的下一页地址是相对地址,故进行补全
next_page = 'http://www.mouxiao.com/lizhimingyan/'+ next_page
# 如果下一页地址和当前页地址不相等,则将下一页地址返回
if next_page != url:
return next_page
# 4、将以上函数排放好顺序进行调用,下载人生格言的全部内容及标题
n = 1
while 1:
print(f"正在下载第{n}页...")
print("下载地址为:"+index_url)
pageupload_play(index_url)
page = get_nextpage(index_url)
index_url = page
if index_url==None:
break
n+=1二、输入想要的内容即可下载到本地
1、抓包分析
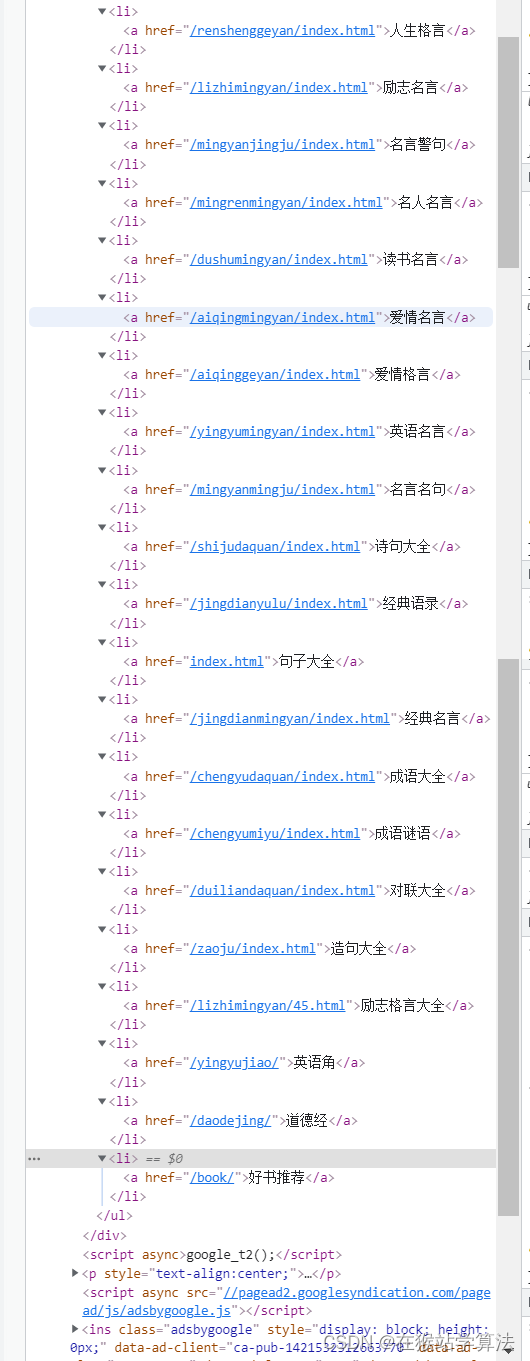
根据上面的抓包分析,可知栏目导航部分内容的url如下图所示:
根据以上情况,可以分析得出:
- 栏目导航的链接地址是以下构造
http://www.mouxiao.com/{你想要的内容的中文拼音} 注:好书推荐为book,不为中文拼音:haoshutuijian注:/index.html或者/index-数字.html或者数字.html是属于子页节点,它被包括在以上url的地址中。(此处我们只要找到父页节点,即可访问到其子页节点)
思路:想要通过输入想要的内容来下载,则可以通过读取键盘消息,来填充此部分内容的url。
点击栏目导航中所有部分的类型链接跳转到其目录页,查看其目录页的布局情况。据此发现:
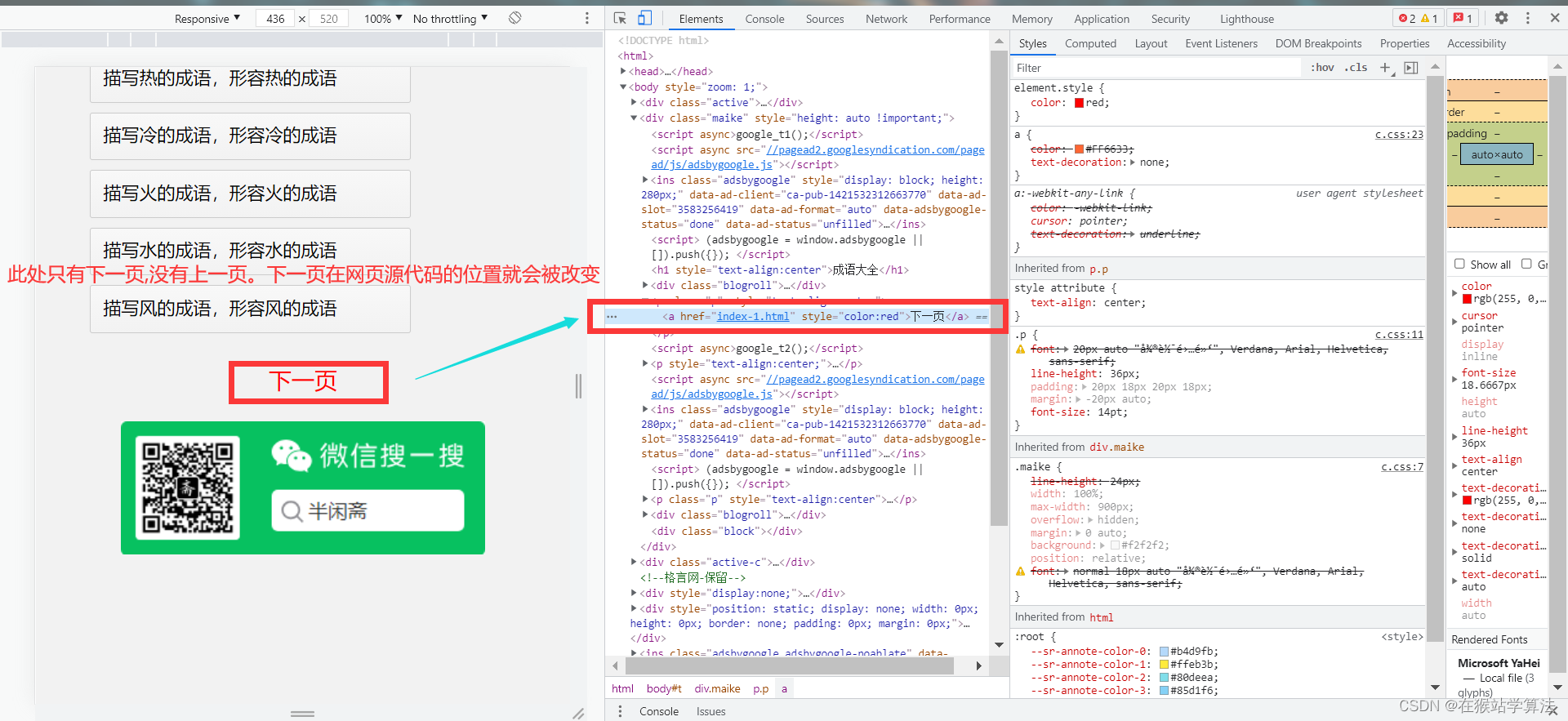
- 如果要下载的某个内容的目录页只有下一页选项的情况,其获取下一页的所在源代码的链接位置有所改变,获取下一页的链接地址的代码需要做相应修改。
- 正常的网页应具备上一页和下一页,这样下一页的url位置不会改变,可以适用上篇帖子获取下一页的函数代码
2、具备上一页和下一页的正常目录页下载内容代码
具备上一页和下一页的正常目录页下载的代码为:
import os
import re
import requests
from lxml import etree
# 获取user-agent,用于身份识别
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
# 1、获取具体格言内容和标题
# 封装成一个函数,输入具体人生格言页的地址,获取其具体的人生格言和标题
def get_content(url):
# 请求当前网页的源代码
r = requests.get(url,headers=header)
# 拒绝requests的自动编码,保留源代码
r.encoding = r.apparent_encoding
# 解析源代码提取具体格言内容和标题
# 获取网页源代码
html = etree.HTML(r.text)
# 获取格言内容
content = html.xpath('//div[@class="maike"]/p[@class="p"]/text()')
# 使用 join() 方法将列表中的元素用换行符连接起来
content = '\n'.join(content)
# 获取标题
title = html.xpath('//div[@class="maike"]/h1[@class="title_l"]/text()')[0]
# 返回标题和内容
return title,content
# 当前页面
keyword = input("情输入你想要的内容(拼音):")
index_url = f'http://www.mouxiao.com/{keyword}'
regular_part = f'http://www.mouxiao.com/{keyword}/'
dictionary = f'../{keyword}'
os.makedirs(dictionary, exist_ok=True)
# 2、获取各种类型的人生格言链接并下载其具体人生格言内容和标题
# 输入当前人生格言的目录页地址,获取各种类型的人生格言链接并下载其具体人生格言内容和标题
def pageupload_play(index_url):
# 请求当前网页的源代码
r = requests.get(index_url,headers=header)
# 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。
# 故采用apparent_encoding方法,禁止requests模块自动编码。
r.encoding = r.apparent_encoding
# 采用xpath的方式定位获取链接所在位置
html = etree.HTML(r.text)
links = html.xpath('//ul[@class="readers-list"]//a/@href')
# 要匹配所有以数字开头,后面跟 '.html' 的元素,可以遍历列表
matched_links = []
for link in links:
# 采用正则表达式筛选出我们所需要的链接,将其保存到matched_links中
if re.findall(r'^\d+\.html', link):
matched_links.append(link)
# 遍历每个类型人生格言的具体人生格言内容和标题,对其进行下载
for link in matched_links:
# link中获取的链接是相对地址,需要补全前面的地址
link1 = regular_part+link
# 调用get_content方法下载内容和标题并保存到本地
title, content = get_content(link1)
with open(f'../{keyword}/{title}.txt','w',encoding='utf-8') as f:
f.write('\t'+title + '\n\n')
f.write(content)
print(f'已下载...{title}')
# 3、获取下一页的地址
# 封装成一个函数,输入当前页面的url,返回下一页的url
def get_nextpage(url):
#请求当前网页的源代码
r = requests.get(url, headers=header)
# 拒绝requests的自动编码,保留源代码
r.encoding = r.apparent_encoding
# 定位到下一页的url地址
html = etree.HTML(r.text)
next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a/@href')[3]
# 因为所获取的下一页地址是相对地址,故进行补全
next_page = regular_part+ next_page
# 如果下一页地址和当前页地址不相等,则将下一页地址返回
if next_page != url:
return next_page
# 4、将以上函数排放好顺序进行调用,下载人生格言的全部内容及标题
n = 1
while 1:
print(f"正在下载第{n}页...")
print("下载地址为:"+index_url)
pageupload_play(index_url)
page = get_nextpage(index_url)
index_url = page
if index_url==None:
break
n+=1输入你想要的内容,即可下载获得!!!
3、只具备下一页的非正常目录页下载内容代码
这种情况下,下一页所在的源代码的url位置发生了变化,抓包分析出此时下一页url所在位置,修改这部分代码即可。
注:
- 在调试的时候发现,这种情况下在处于最后一页时,没有下一页的选项反而出现上一页的选项,且上一页选项的链接所在源代码的位置与下一页选项的链接所在源代码的位置一致。
- 在正常页面中,处于最后一页时,上一页和下一页选项仍然出现,且链接所在位置都没有发生改变,下一页的链接地址与当前页面的链接地址一致。
基于以上情况,返回下一页url时需要使用不同的条件。
代码如下:
import os
import re
import requests
from lxml import etree
# 获取user-agent,用于身份识别
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
# 1、获取具体格言内容和标题
# 封装成一个函数,输入具体人生格言页的地址,获取其具体的人生格言和标题
def get_content(url):
# 请求当前网页的源代码
r = requests.get(url,headers=header)
# 拒绝requests的自动编码,保留源代码
r.encoding = r.apparent_encoding
# 解析源代码提取具体格言内容和标题
# 获取网页源代码
html = etree.HTML(r.text)
# 获取格言内容
content = html.xpath('//div[@class="maike"]/p[@class="p"]/text()')
# 使用 join() 方法将列表中的元素用换行符连接起来
content = '\n'.join(content)
# 获取标题
title = html.xpath('//div[@class="maike"]/h1[@class="title_l"]/text()')[0]
# 返回标题和内容
return title,content
# 当前页面
keyword = input("情输入你想要的内容(拼音):")
index_url = f'http://www.mouxiao.com/{keyword}'
regular_part = f'http://www.mouxiao.com/{keyword}/'
dictionary = f'../{keyword}'
os.makedirs(dictionary, exist_ok=True)
# 2、获取各种类型的人生格言链接并下载其具体人生格言内容和标题
# 输入当前人生格言的目录页地址,获取各种类型的人生格言链接并下载其具体人生格言内容和标题
def pageupload_play(index_url):
# 请求当前网页的源代码
r = requests.get(index_url,headers=header)
# 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。
# 故采用apparent_encoding方法,禁止requests模块自动编码。
r.encoding = r.apparent_encoding
# 采用xpath的方式定位获取链接所在位置
html = etree.HTML(r.text)
links = html.xpath('//ul[@class="readers-list"]//a/@href')
# 要匹配所有以数字开头,后面跟 '.html' 的元素,可以遍历列表
matched_links = []
for link in links:
# 采用正则表达式筛选出我们所需要的链接,将其保存到matched_links中
if re.findall(r'^\d+\.html', link):
matched_links.append(link)
# 遍历每个类型人生格言的具体人生格言内容和标题,对其进行下载
for link in matched_links:
# link中获取的链接是相对地址,需要补全前面的地址
link1 = regular_part+link
# 调用get_content方法下载内容和标题并保存到本地
title, content = get_content(link1)
with open(f'../{keyword}/{title}.txt','w',encoding='utf-8') as f:
f.write('\t'+title + '\n\n')
f.write(content)
print(f'已下载...{title}')
# 3、获取下一页的地址
# 封装成一个函数,输入当前页面的url,返回下一页的url
def get_nextpage(url):
#请求当前网页的源代码
r = requests.get(url, headers=header)
# 拒绝requests的自动编码,保留源代码
r.encoding = r.apparent_encoding
# 定位到下一页的url地址
html = etree.HTML(r.text)
next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a[text()="下一页"]/@href')
if len(next_page)==0:
return
# 因为所获取的下一页地址是相对地址,故进行补全
next_page = regular_part + ''.join(next_page)
return next_page
# 如果下一页地址和当前页地址不相等,则将下一页地址返回
# 4、将以上函数排放好顺序进行调用,下载人生格言的全部内容及标题
n = 1
while 1:
print(f"正在下载第{n}页...")
print("下载地址为:"+index_url)
pageupload_play(index_url)
page = get_nextpage(index_url)
index_url = page
if index_url==None:
break
n+=14、针对以上情况都适用的完整代码
将以上两种情况用if语句做一个判断,即可。完整代码如下:
import os
import re
import requests
from lxml import etree
# 获取user-agent,用于身份识别
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
# 1、获取具体格言内容和标题
# 封装成一个函数,输入具体人生格言页的地址,获取其具体的人生格言和标题
def get_content(url):
# 请求当前网页的源代码
r = requests.get(url,headers=header)
# 拒绝requests的自动编码,保留源代码
r.encoding = r.apparent_encoding
# 解析源代码提取具体格言内容和标题
# 获取网页源代码
html = etree.HTML(r.text)
# 获取格言内容
content = html.xpath('//div[@class="maike"]/p[@class="p"]/text()')
# 使用 join() 方法将列表中的元素用换行符连接起来
content = '\n'.join(content)
# 获取标题
title = html.xpath('//div[@class="maike"]/h1[@class="title_l"]/text()')[0]
# 返回标题和内容
return title,content
# 当前页面
keyword = input("情输入你想要的内容(拼音):")
index_url = f'http://www.mouxiao.com/{keyword}'
regular_part = f'http://www.mouxiao.com/{keyword}/'
dictionary = f'../{keyword}'
os.makedirs(dictionary, exist_ok=True)
# 2、获取各种类型的人生格言链接并下载其具体人生格言内容和标题
# 输入当前人生格言的目录页地址,获取各种类型的人生格言链接并下载其具体人生格言内容和标题
def pageupload_play(index_url):
# 请求当前网页的源代码
r = requests.get(index_url,headers=header)
# 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。
# 故采用apparent_encoding方法,禁止requests模块自动编码。
r.encoding = r.apparent_encoding
# 采用xpath的方式定位获取链接所在位置
html = etree.HTML(r.text)
links = html.xpath('//ul[@class="readers-list"]//a/@href')
# 要匹配所有以数字开头,后面跟 '.html' 的元素,可以遍历列表
matched_links = []
for link in links:
# 采用正则表达式筛选出我们所需要的链接,将其保存到matched_links中
if re.findall(r'^\d+\.html', link):
matched_links.append(link)
# 遍历每个类型人生格言的具体人生格言内容和标题,对其进行下载
for link in matched_links:
# link中获取的链接是相对地址,需要补全前面的地址
link1 = regular_part+link
# 调用get_content方法下载内容和标题并保存到本地
title, content = get_content(link1)
with open(f'../{keyword}/{title}.txt','w',encoding='utf-8') as f:
f.write('\t'+title + '\n\n')
f.write(content)
print(f'已下载...{title}')
# 3、获取下一页的地址
# 封装成一个函数,输入当前页面的url,返回下一页的url
def get_nextpage(url):
#请求当前网页的源代码
r = requests.get(url, headers=header)
# 拒绝requests的自动编码,保留源代码
r.encoding = r.apparent_encoding
# 定位到下一页的url地址
html = etree.HTML(r.text)
next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a/@href')
# 如果是具有上一页和下一页的正常目录页面
if len(next_page) > 2:
next_page = next_page[3]
next_page = regular_part + next_page
if next_page != url:
return next_page
# 如果只有下一页的目录页面
else:
next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a[text()="下一页"]/@href')
if len(next_page)==0:
return
next_page = regular_part + ''.join(next_page)
return next_page
n = 1
while 1:
print(f"正在下载第{n}页...")
print("下载地址为:"+index_url)
pageupload_play(index_url)
page = get_nextpage(index_url)
index_url = page
if index_url==None:
break
n+=1运行以上代码需要注意的地方:
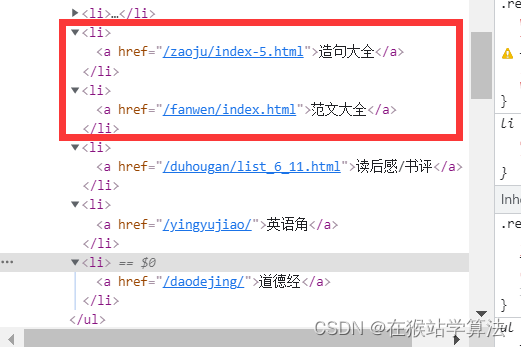
- 造句大全和成语大全,需要输入的是zaoju和fanwen。而不是zaojudaquan和chengyudaquan
- 英语角和道德经的目录页布局跟其他内容的目录页布局不同,内容和所在标签都不是跟以上情况处于网页源代码的相同位置。如果需要爬取则需根据上篇贴子进行抓包分析,修改其相应代码即可。
- 书评的页面布局与以上布局类似,但所有的内容在网页源代码的的位置与以上情况有所不同。如果需要爬取,需要抓包分析修改其xpath所定位到的部分。
注:本帖只用于学习交流,禁止商用!