1. 分析实例
源码:
#include<time.h>
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<cuda_runtime.h>
#include<cublas_v2.h>
#include<cusolverDn.h>
#define BILLION 1000000000L;
void print_vector(float* tau, int n){
for(int i=0; i<n; i++)
printf("%7.4f ", tau[i]);
}
void print_matrix(float* A, int m, int n, int lda){
for(int i=0; i<m; i++) {
for(int j=0; j<n; j++){
printf("%7.4f, ", A[i + j*lda]);
}
printf("\n");
}
}
void init_matrix(float* A, int m, int n, int lda, int seed){
srand(seed);
for(int j=0; j<n; j++) {
for(int i=0; i<m; i++){
A[i + j*lda] = (rand()%1000)/750.0f;
}
}
}
void tau_matrix(float* A, int m, int n, int lda)
{
printf("\ntuu = ");
for(int j=0; j<n-1; j++){
float tau, dot;
tau = 0.0f;
dot = 0.0f;
for(int i=j+1; i<m; i++){
dot += A[i + j*lda]*A[i + j*lda];
}
dot += 1.0f;
tau = 2.0f/dot;
printf("%7.4f ", tau);
}
}
int main(int argc, char *argv[]){
struct timespec start, stop; // variables for timing
double accum; // elapsed time variable
cusolverDnHandle_t cusolverH;
cublasHandle_t cublasH;
cublasStatus_t cublas_status = CUBLAS_STATUS_SUCCESS;
cusolverStatus_t cusolver_status = CUSOLVER_STATUS_SUCCESS;
cudaError_t cudaStat = cudaSuccess;
const int m = 7;//8192; // number of rows of A
const int n = 7;//8192; // number of columns of A
const int lda = m; // leading dimension of A
// declare matrices A and Q,R on the host
float *A, *Q, *R;
// prepare host memeory
A = (float *)malloc(lda * n * sizeof(float)); // matr . A on the host
Q = (float *)malloc(lda * n * sizeof(float)); // orthogonal factor Q
R = (float *)malloc(n * n * sizeof(float)); // R=I-Q^T*Q
init_matrix(A, m, n, lda, 2003);
float *d_A, *d_R; // matrices A, R on the device
float *d_tau; // scalars defining the elementary reflectors
int *devInfo; // info on the device
float *d_work; // workspace on the device
// workspace sizes
int lwork_geqrf = 0;
int lwork_orgqr = 0;
int lwork = 0;
int info_gpu = 0; // info copied from the device
const float h_one = 1; // constants used in
const float h_minus_one = -1; // computations of I-Q^T*Q
// create cusolver and cublas handles
cusolver_status = cusolverDnCreate(&cusolverH);
cublas_status = cublasCreate(&cublasH);
// prepare device memory
cudaStat = cudaMalloc((void **)&d_A, sizeof(float) * lda * n);
cudaStat = cudaMalloc((void **)&d_tau, sizeof(float) * n);
cudaStat = cudaMalloc((void **)&devInfo, sizeof(int));
cudaStat = cudaMalloc((void **)&d_R, sizeof(float) * n * n);
cudaStat = cudaMemcpy(d_A, A, sizeof(float) * lda * n,
cudaMemcpyHostToDevice); // copy d_A <- A
// compute working space for geqrf and orgqr
cusolver_status = cusolverDnSgeqrf_bufferSize(cusolverH,
m, n, d_A, lda, &lwork_geqrf); // compute Sgeqrf buffer size
cusolver_status = cusolverDnSorgqr_bufferSize(cusolverH,
m, n, n, d_A, lda, d_tau, &lwork_orgqr); // and Sorgqr b. size
lwork = (lwork_geqrf > lwork_orgqr) ? lwork_geqrf : lwork_orgqr;
// device memory for workspace
cudaStat = cudaMalloc((void **)&d_work, sizeof(float) * lwork);
// QR factorization for d_A
clock_gettime(CLOCK_REALTIME, &start); // start timer
cusolver_status = cusolverDnSgeqrf(cusolverH, m, n, d_A, lda,
d_tau, d_work, lwork, devInfo);
cudaStat = cudaDeviceSynchronize();
clock_gettime(CLOCK_REALTIME, &stop); // stop timer
accum = (stop.tv_sec - start.tv_sec) + // elapsed time
(stop.tv_nsec - start.tv_nsec) / (double)BILLION;
printf(" Sgeqrf time : %lf sec .\n", accum); // print elapsed time
cudaStat = cudaMemcpy(&info_gpu, devInfo, sizeof(int),
cudaMemcpyDeviceToHost); // copy devInfo -> info_gpu
// check geqrf error code
printf("\n after geqrf : info_gpu = %d\n", info_gpu);
///
printf("\nA =\n");print_matrix(A, m, n, lda);
cudaStat = cudaMemcpy(A, d_A, sizeof(float) * lda * n,
cudaMemcpyDeviceToHost);
printf("\nV+R-I =\n");print_matrix(A, m, n, lda);
float* tau = nullptr;
tau = (float*)malloc(n*sizeof(float));
cudaStat = cudaMemcpy(tau, d_tau, n*sizeof(float), cudaMemcpyDeviceToHost);
printf("\ntau = ");print_vector(tau, n);
tau_matrix(A, m, n, lda);
free(tau);
///
// apply orgqr function to compute the orthogonal matrix Q
// using elementary reflectors vectors stored in d_A and
// elementary reflectors scalars stored in d_tau ,
cusolver_status = cusolverDnSorgqr(cusolverH, m, n, n, d_A,
lda, d_tau, d_work, lwork, devInfo);
cudaStat = cudaDeviceSynchronize();
cudaStat = cudaMemcpy(&info_gpu, devInfo, sizeof(int),
cudaMemcpyDeviceToHost); // copy devInfo -> info_gpu
// check orgqr error code
printf("\n after orgqr : info_gpu = %d\n", info_gpu);
cudaStat = cudaMemcpy(Q, d_A, sizeof(float) * lda * n,
cudaMemcpyDeviceToHost); // copy d_A ->Q
memset(R, 0, sizeof(double) * n * n); // nxn matrix of zeros
for (int j = 0; j < n; j++)
{
R[j + n * j] = 1.0f; // ones on the diagonal
}
cudaStat = cudaMemcpy(d_R, R, sizeof(float) * n * n,
cudaMemcpyHostToDevice); // copy R-> d_R
// compute R = -Q**T*Q + I
cublas_status = cublasSgemm_v2(cublasH, CUBLAS_OP_T, CUBLAS_OP_N,
n, n, m, &h_minus_one, d_A, lda, d_A, lda, &h_one, d_R, n);
float dR_nrm2 = 0.0; // norm value
// compute the norm of R = -Q**T*Q + I
cublas_status = cublasSnrm2_v2(cublasH, n * n, d_R, 1, &dR_nrm2);
printf("||I - Q^T*Q|| = %E\n", dR_nrm2); // print the norm
// free memory
cudaFree(d_A);
cudaFree(d_tau);
cudaFree(devInfo);
cudaFree(d_work);
cudaFree(d_R);
cublasDestroy(cublasH);
cusolverDnDestroy(cusolverH);
cudaDeviceReset();
return 0;
}
// Sqeqrf time : 0.434779 sec .
// after geqrf : info_gpu = 0
// after orgqr : info_gpu = 0
//|I - Q**T*Q| = 2.515004E -04
//
//
Makefile:
TARGETS = qr_cusolver_sgeqrf
all: $(TARGETS)
LD_FLAGS = -L/usr/local/cuda/lib64 \
-lcudart -lcudadevrt \
-lcusolver -lcublas \
-lcublasLt -lpthread
%: %.cpp
g++ -o $@ $< -I/usr/local/cuda/include $(LD_FLAGS) -fopenmp -I./cblas_source -L./cblas_source/CBLAS/lib -lcblas_LINUX -L/usr/local/lib -lblas -lgfortran
.PHONY:clean
clean:
-rm -f $(TARGETS)2. 运行
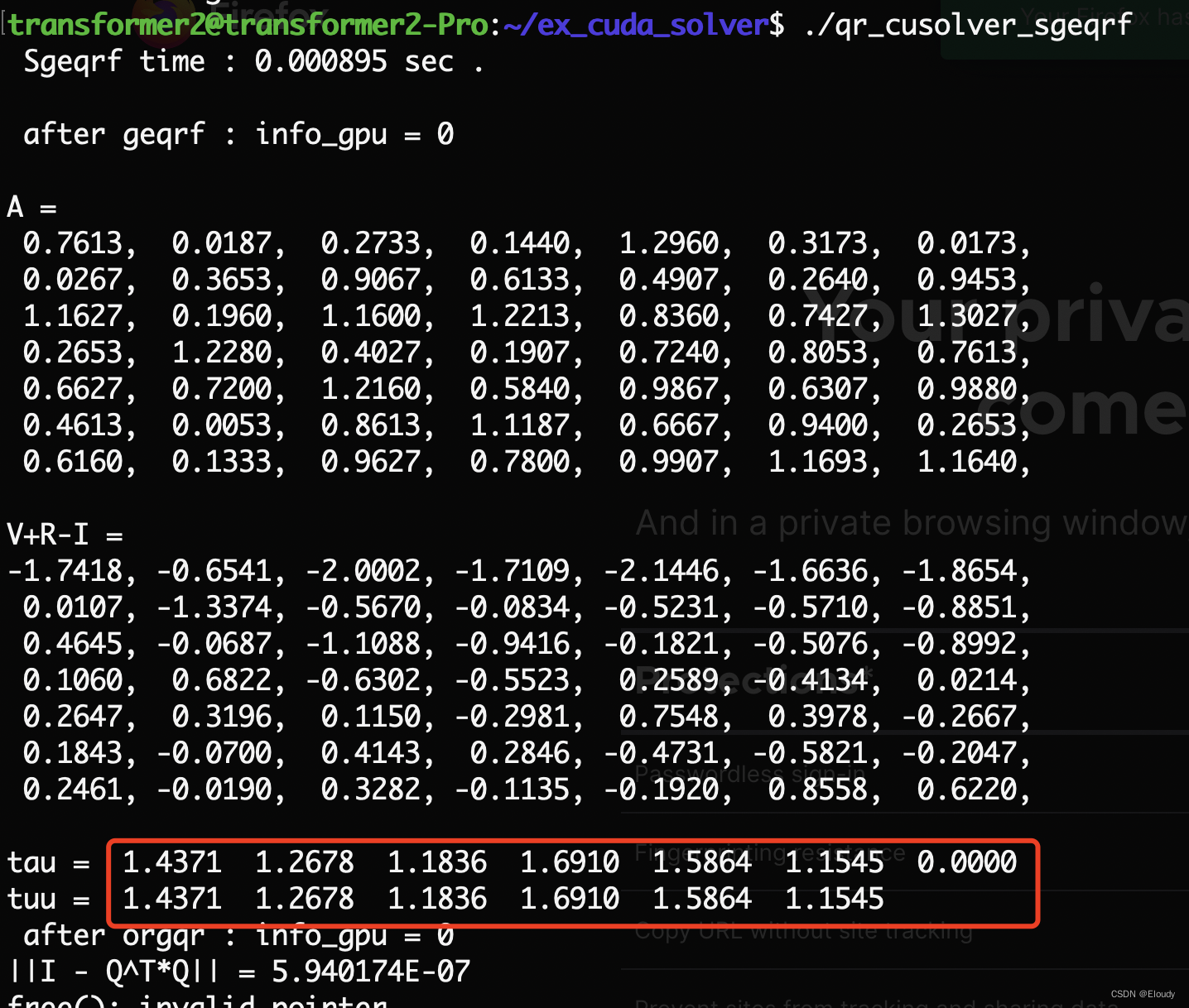
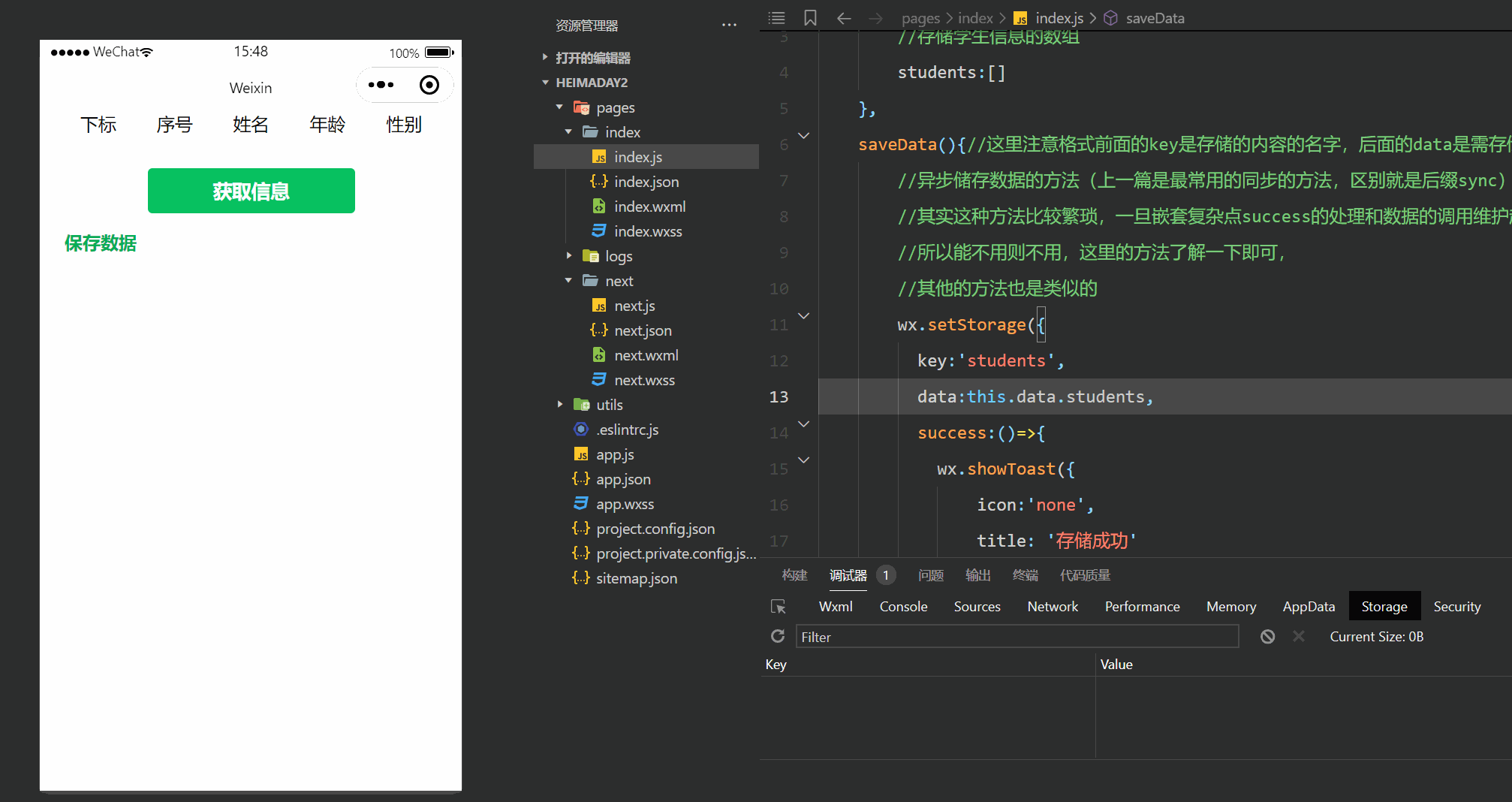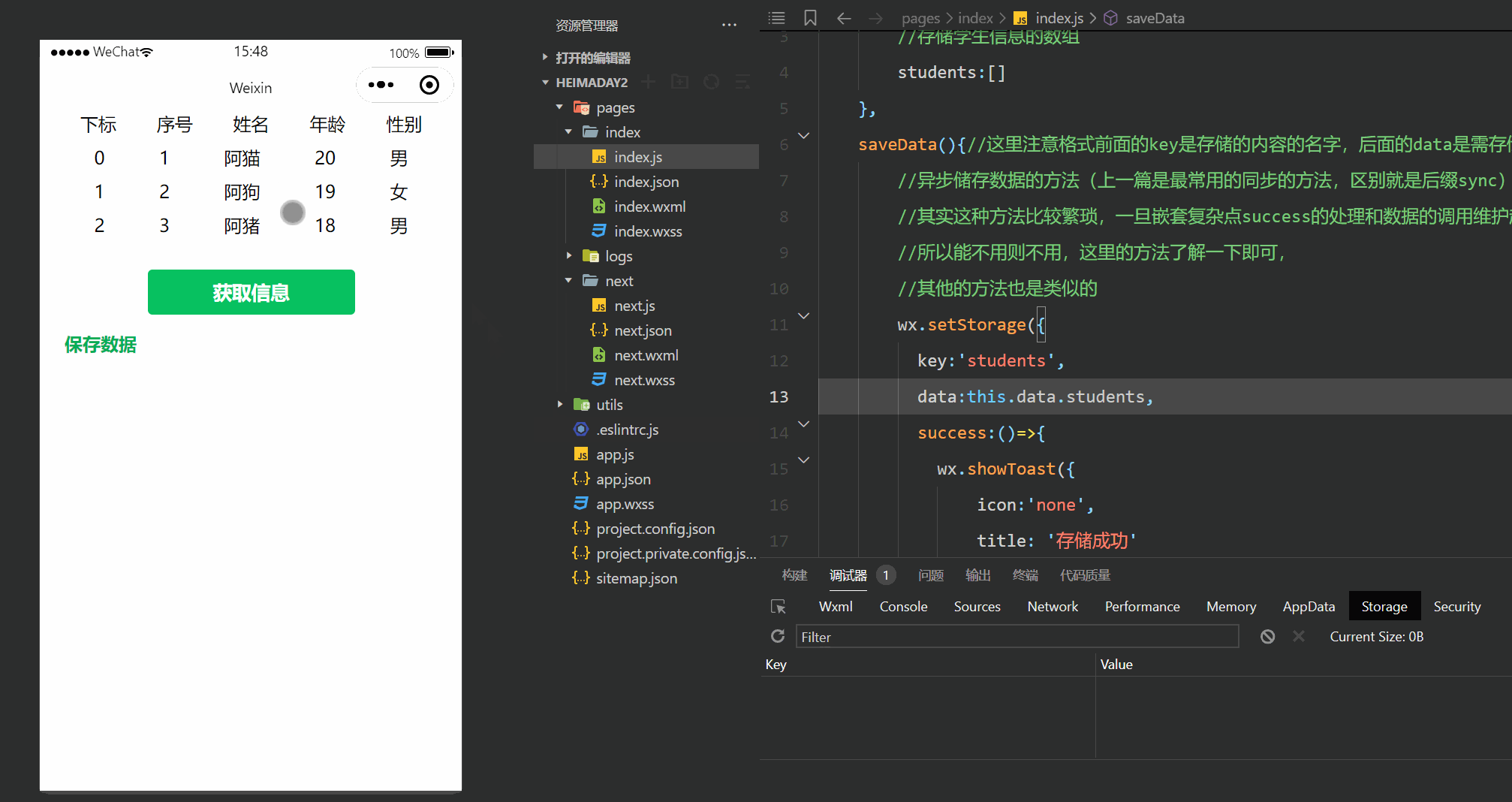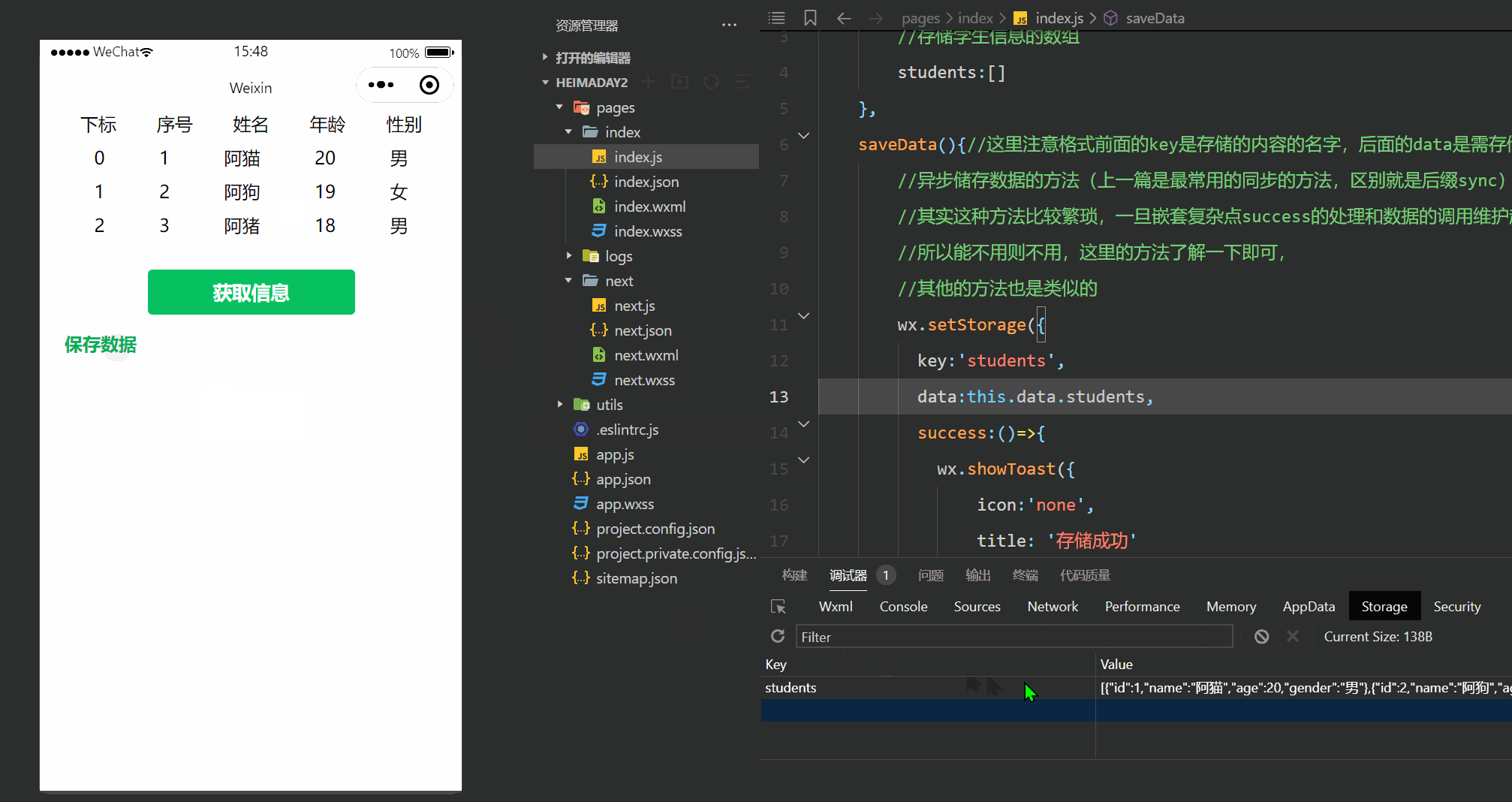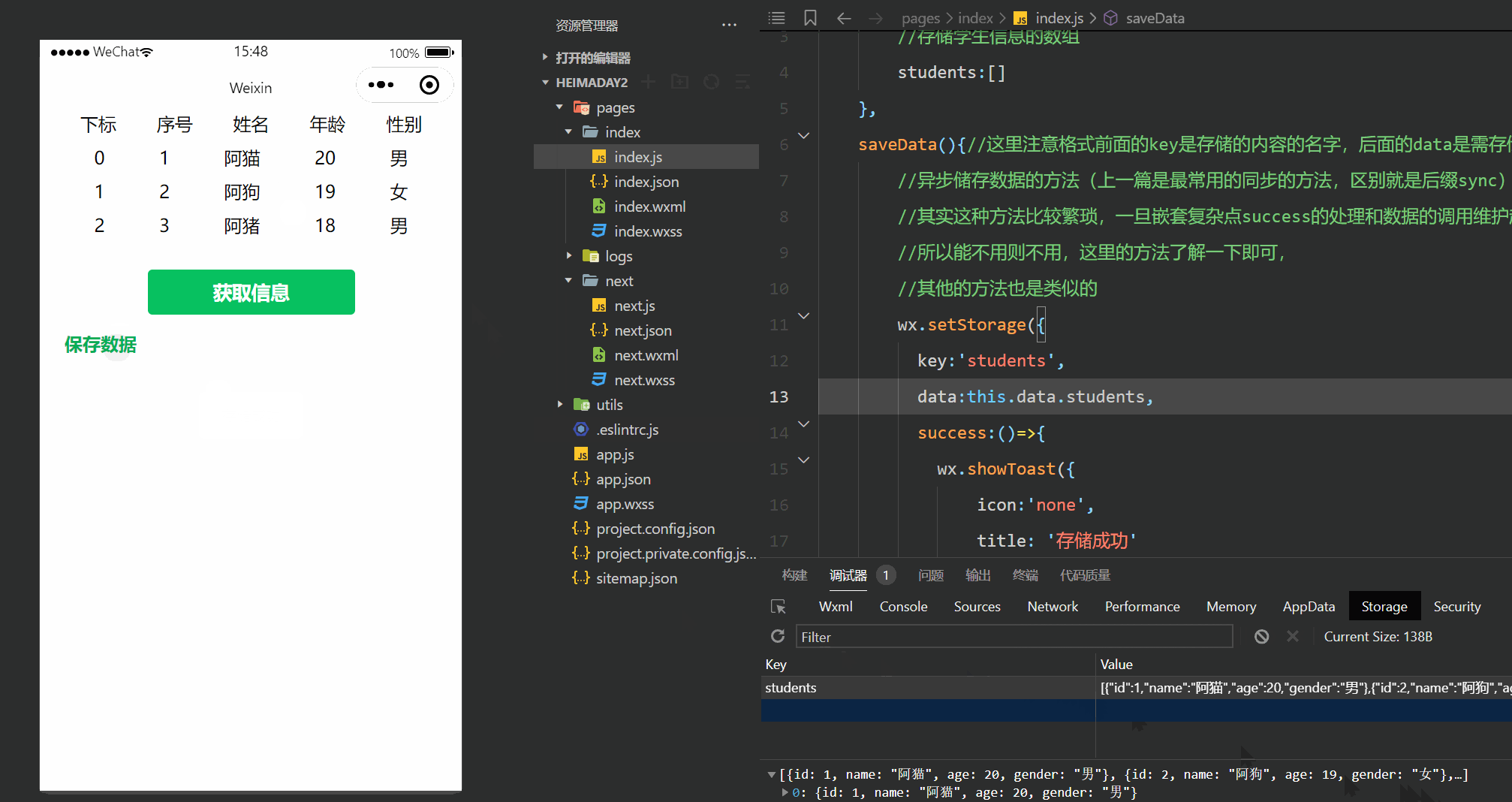
可知 tau的计算公式如代码中所示。



























![[嵌入式AI从0开始到入土]5_炼丹炉的搭建(基于wsl2_Ubuntu22.04)](https://img-blog.csdnimg.cn/direct/356bc33ef232468fb658928460612957.png)