为什么做「Bug分析」?
Bug分析是QA的一项主要技能,需要针对项目中遇到的经典问题进行分类分析, 直达问题本质。 并且能够给团队其他项目或者成员起到典型的借鉴作用。 当然也有一些非常经典的问题可以进行技术深挖, 以供参考。 个人认为比较典型的「Bug分析」是stackoverflow, 当然, 一个完善的bug分析库, 可以进行问题分类总结。 对于测试新人是有很大的帮助的。
本质上, 在测试领域很多问题是可重现可整理可规避的。
另外, bug分析本身是为了拓宽每个人的认知边界, 缩小团队间的乔哈里窗以达到最佳的合作状态。
什么是「好的Bug分析」?
一个「好的Bug分析」应该具备几个主要的部分:
详细的bug描述, 包含可以复现的环境准备(比如测试包、有问题的commit、现场录频、coredump文件、监控报表等等)
- 详细的bug定位过程
- 详细的bug原因分析
- bug真正借鉴意义总结
通过阅读和分享这些bug分析, 能够比较快速的理解bug产生的过程和修复方案。
如何做Bug分析?
首先拿到一个bug, 应该自行头脑风暴:看一下自己在这个bug背后看到了哪些技术。在这个环节, 需要做的事情,是不需要关心真正问题背后使用的技术。举个例子:一个因为服务端字段下发错误导致的客户端crash。 应该包含哪些内容呢?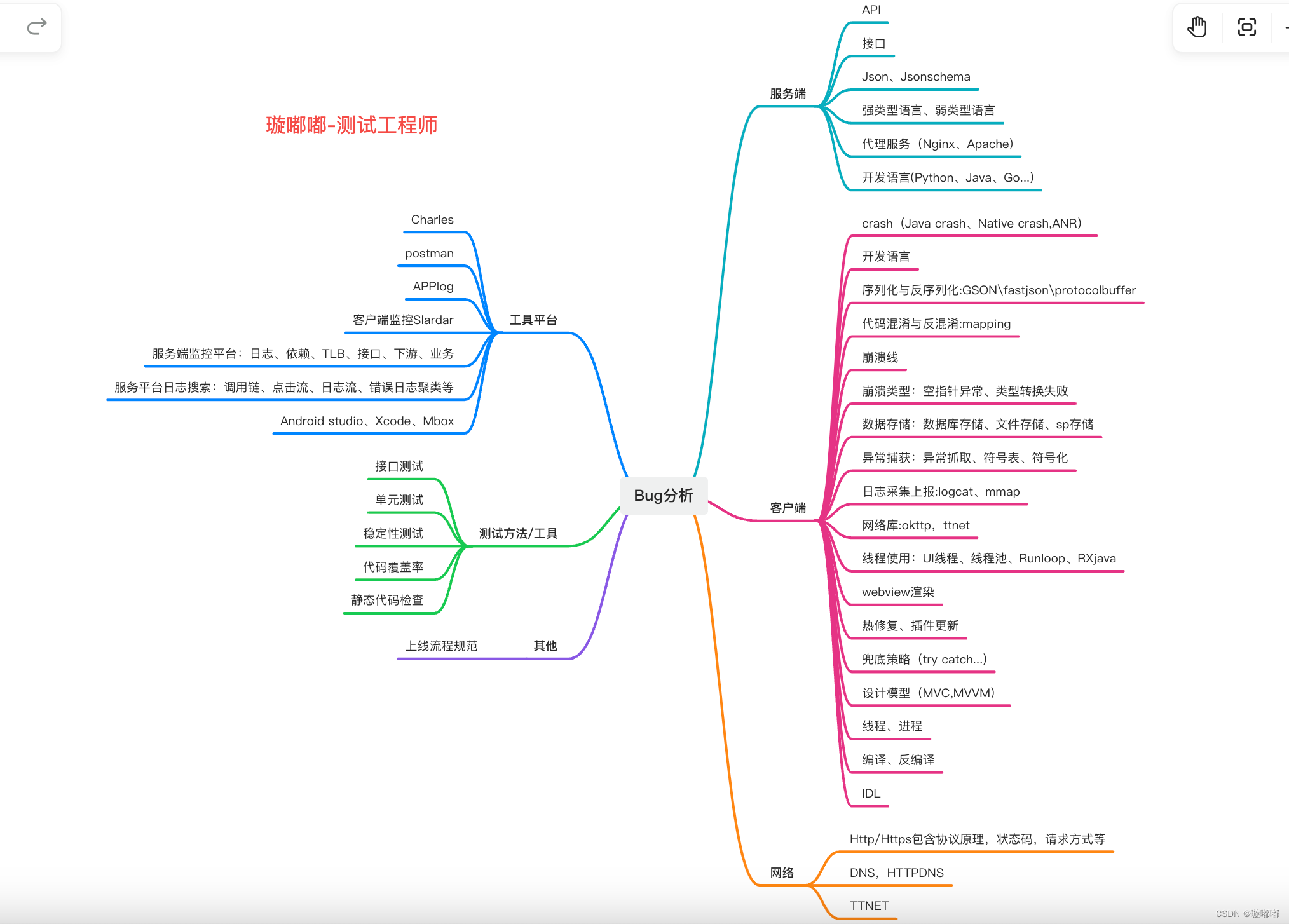
这张图并没有反应出这个bug背后所有的知识点(大家可以继续补充), 但是在做bug分析的时候, 首先需要把这些知识点先全部罗列出来(不管你是否了解背后的真实原理)
有了需要了解的技术背后的原理之后, 开始分解:
- 哪些是目前你了解的技术
- 针对这部分内容可以看一下目前bug分析的读者是否都了解并且是共识, 可以针对性的介绍。 如果有相关的wiki, 可以直接进行链接(特别是业务系统介绍, 比如头条feed原理等等)
- 针对一些通用知识点, 比如http协议, 这些也应该针对性的进行分析。
- 哪些是你目前知道的技术(但是不了解原理)
- 大部分同学对于现有bug的分析遇到的问题, 都集中在这部分。很多知识点或者技术都仅限听说或者「我认识它, 它不认识我」的状态。所以这部分的信息输入(在bug分析中)是非常重要的。 通过bug分析,去真正理解你知道的技术背后的原理, 是对个人技术的一个很好提升。
- 了解技术本身并不难, 这里有一个提升点:需要通过这个技术, 去写一段demo程序或者详细的技术文章去解释。
- 哪些是你目前不知道的技术?(可能是你在分析这个bug过程当中听别人介绍的)
- 这一部分内容一般情况下分两类:
- 一类是Bug的关键技术点(导致bug的主要技术), ok, 那就需要和第二部分一样做详细的技术理解和分析
- 一类是发散性的技术点:比如由于还是NP这个case, 里面可能涉及到「PB技术」 , 这个技术本身是能够解决由于字段类型问题导致的crash的, 就需要去深入理解, 如果有可能, 就需要和rd沟通, 引入这项技术。 如果只是扩展性的知识点, 可以稍加展开。
- 这一部分内容一般情况下分两类:
有了上面几类技术点的拆分和分析, 大致对于bug分析所需要的技术储备就足够了。 再结合上面提到的一个「好的Bug分析」应该包含哪几部分进行「码字」
- 详细的bug描述, 包含可以复现的环境准备(比如测试包、有问题的commit、现场录频、coredump文件、监控报表等等)
- 这一步非常重要, 对于查看bug分析或者新人学习用, 如果没有可以复现的现场或者数据, 是很难直观的理解bug到底是怎么回事。 所以保留有问题的包, 或者保留现场录像, 是非常重要的。 当然, 如果bug提交的足够清晰, 也可以直接链接一下jira。
- 详细的bug定位过程
这一步可以不是具体的时间点(比如xx时间, 有用户反馈xx问题这一类的描述)。 更多的是定位过程中使用到的主要工具和方法的介绍, 比如通过Charles进行接口返回模拟(这里就可以详细链接到对应的Charles使用教程), 或者通过hardcode模拟接口返回空的数据, 或者通过mockserver(原理和Charles相同)修改返回数据, 甚至直接修改server代码返回空, 修改测试DB、Cache返回空等多种手段。
- 还有可以介绍过程中用到的各类内部平台, 比如测试频道后台、Session RPC接口等等。
- 有了前置的复现过程和定位过程介绍, 中间使用到了其他工具平台, 最好都一一介绍一下。
- 详细的bug原因分析
- 有了上面的准备工作, 真正的主角登场:详细的bug原因分析。这里必须有流程图、时序图、系统模块图、或者架构图。 第一眼就能让大家清楚的知道这个bug发生的真实原因。
- 里面可以有code diff的代码, 但是一定要解释清楚出问题的代码是哪个模块, 哪个文件的哪一个函数, 而不是一个截图。
- 如果有足够的时间, 可以再详细介绍一下出问题的系统架构(这里可以进行link到对应的项目设计wiki中)
- bug真正借鉴意义总结
- 上面更多是从现象到本质的分析, 这一部分更多是通过本质提升到理论高度, 如果通过这个bug, 在未来的项目中起到重要的借鉴意义:
- 更好的case设计:如何通过这个bug反应到未来的case设计当中, 比如NP问题, 几乎是所有项目的都会遇到的问题, case设计的时候, 必须考虑接口返回空导致的程序异常(crash不能容忍/功能依然不能容忍、功能不完善可以接受、功能无损但是有上报是最理想的)
- 更好的技术方案进行问题拦截
- 比如引入IDL进行数据格式硬性标注
- 比如引入代码扫码对NP问题进行提前拦截等等。
- 比如更优化的架构设计(是同JSONModel进行数据预处理?)
- 上面更多是从现象到本质的分析, 这一部分更多是通过本质提升到理论高度, 如果通过这个bug, 在未来的项目中起到重要的借鉴意义:
本质上,上面的这些「有用的废话」是希望能够指导大家更好的做分析, 总结下来就是几个方法:
- 头脑风暴:先不要管具体技术细节, 把bug涉及的技术点全部罗列出来, 如果你列不出来, 要么你是真大神, 要么你是真不会。
- 知识点拆解:整理会的知识、弄清楚仅知道的知识、扩张不知道的知识。
- 按着模板来分析。
最后, 多问几个为什么, 就可以看到曙光了。
有哪些误区?
- Bug分析不是提bug。
- Bug分析不是描述bug, 然后湊一些技术点。
- Bug分析不是贴代码, 不是贴code diff。
好的bug分析有哪些?
- https://docs.google.com/document/d/1oBYQmpBthPfxMvW0XgHn7Bu918n6eFLlQM7nVhEdF_0/edit
- https://codeascraft.com/2012/05/22/blamelessa-postmortems/
- https://github.com/danluu/post-mortems
- https://vimeo.com/77206751
- https://github.com/etsy/morgue
- https://blog.github.com/2016-02-03-january-28th-incident-report/
- https://blog.github.com/2014-01-18-dns-outage-post-mortem/