使用opencv实现KNN
前言
KNN算法,即K-Nearest Neighbor,是一种简单的机器学习算法。它的基本思想是:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法通过计算待分类样本与已知类别样本的距离,找出距离最近的K个样本,根据这K个样本的类别,通过投票的方式确定待分类样本的类别。
在KNN算法中,距离的度量方式主要有欧式距离、曼哈顿距离、余弦相似度等。其中,欧式距离是最常用的距离度量方式,计算的是两点之间的直线距离。
KNN算法的优点包括简单直观、易于实现、对异常点不敏感等。但同时,KNN算法也存在一些局限性,如对数据分布敏感、K值选择主观等。此外,对于大规模数据集和高维数据,KNN算法的效率可能会较低。
总的来说,KNN算法是一种基础且重要的机器学习算法,在数据分类、回归分析、聚类等领域都有广泛的应用。
OpenCV实现KNN
生成随机数据
import numpy as np
def generate_data(num_samples, num_features=2):
data_size = (num_samples, num_features)
train_data = np.random.randint(0, 100, size=data_size)
labels_size = (num_samples, 1)
labels = np.random.randint(0, 2, size=labels_size)
return train_data.astype(np.float32), labels
我们构建了一个函数来生成数据集,num_samples代表的是数据量,num_features默认为2代表的是数据有两个特征。通过随机数生成数据和标签。
train_data, labels = generate_data(11)
train_data
生成的数据如下:

- 注:由于随机种子的不同生成的数据很有可能不同,以实际运行结果为准(下面的画图也一样)
下面以第0个数据为例看一下数据和标签的对应
train_data[0], labels[0]
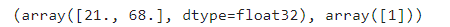
使用matplotlib绘制数据
import matplotlib.pyplot as plt
plt.style.use('ggplot')
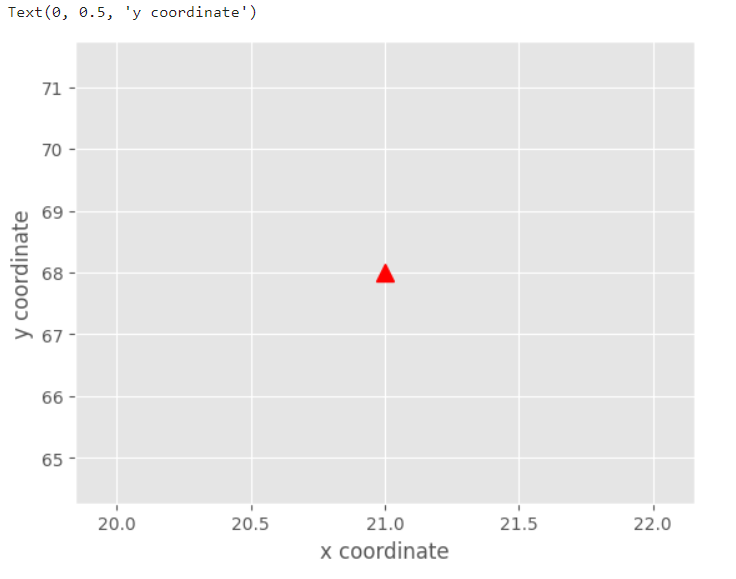
plt.plot(train_data[0, 0], train_data[0, 1], color='r', marker='^', markersize=10)
plt.xlabel('x coordinate')
plt.ylabel('y coordinate')
在代码中plt.style.use(‘ggplot’)的作用是为了使得画图更加好看。随后随便画了数据中的一个点的效果如下:
为了方便展示数据,我们在下面构建一个绘图函数用不同的颜色和不同的形状表示不同类别的数据。
def plot_data(all_blue, all_red):
plt.figure(figsize=(10, 6))
plt.scatter(all_blue[:, 0], all_blue[:, 1], c='b', marker='s', s=180)
plt.scatter(all_red[:, 0], all_red[:, 1], c='r', marker='^', s=180)
plt.xlabel('x coordinate')
plt.ylabel('y coordinate')
现在我们有了数据和展示函数,那么如何区分数据的类别呢,我们可以根据标签(labels)来选择不同类别的数据。不过生成的标签使用其实并不方便,在这里我们使用ravel()将数据展平。效果对比如下:
labels, labels.ravel()

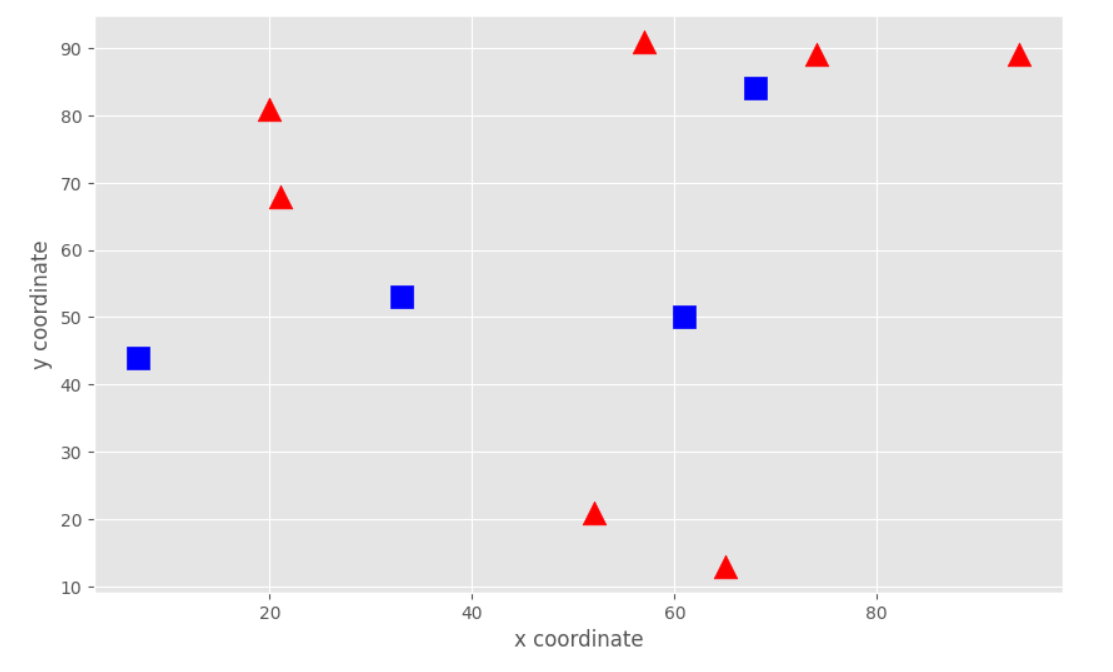
现在我们已经有了数据的选择方式和画图方式,现在我们来画一下不同类别的数据。
blue = train_data[labels.ravel()==0]
red = train_data[labels.ravel()==1]
plot_data(blue, red)
OpenCV用于KNN训练
在cv2中的ml模块中有一些常见的机器学习方法,使用KNearest_create可以创建一个KNN的分类器,训练时需要传入的数据有数据、数据组织方式、标签
import cv2
knn = cv2.ml.KNearest_create()
knn.train(train_data, cv2.ml.ROW_SAMPLE, labels)
在代码中使用的数据组织方式为cv2.ml.ROW_SAMPLE,即每一行就是一条数据。
生成新数据并观察
训练完之后我们再生成一个不含标签的数据
newcomer, _ = generate_data(1)
newcomer

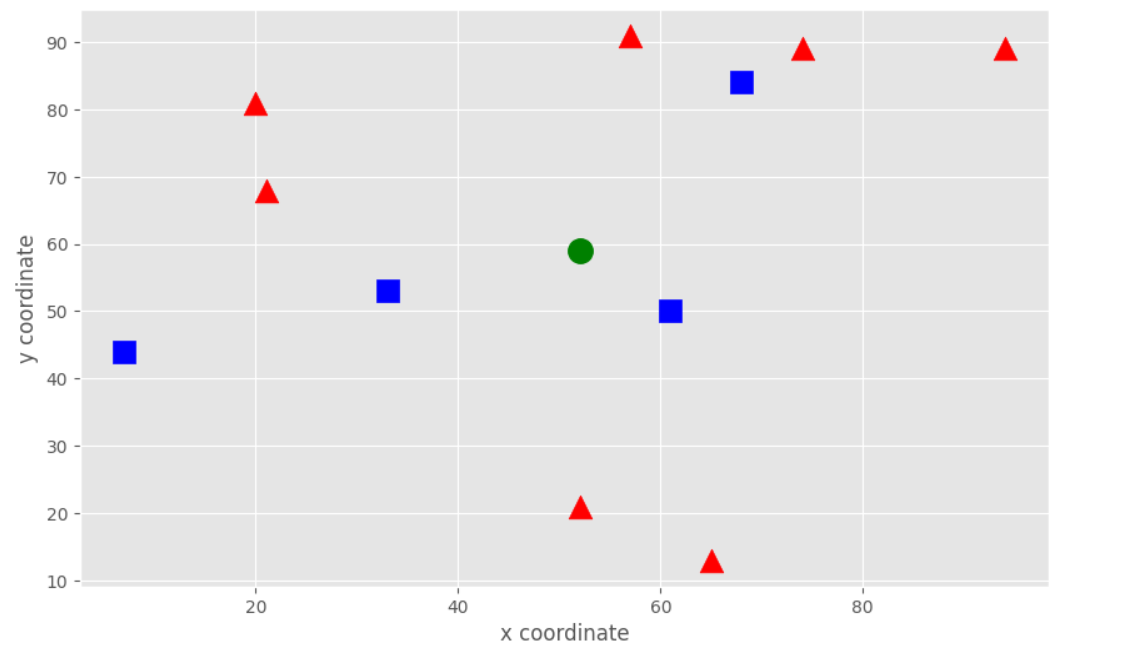
画出原始数据和新生成的不含标签的数据,一起进行对比。
plot_data(blue, red)
plt.plot(newcomer[0, 0], newcomer[0, 1], 'go', markersize=14)
在下面的图中,绿色的圆形就是新的数据,这个数据不含标签。我们观察到这个数据和蓝色方块很近,所以大概率是属于蓝色方块的。即属于第0类。
预测
我们先来使用最近的一个点来进行预测,这里findNearest第二个参数是1
ret, results, neighbor, dist = knn.findNearest(newcomer, 1)
results, neighbor, dist

然后使用最近的三个点来进行预测,这里findNearest第二个参数是3
ret, results, neighbor, dist = knn.findNearest(newcomer, 3)
results, neighbor, dist

可以看到预测结果是正确的
与此同时我们也可以使用predict方法进行预测。但是,首先我们需要设置k,我们要根据最近的k个
数据点来判断新数据具体属于哪一类。
使用方式如下:
knn.setDefaultK(1)
knn.predict(newcomer)

knn.setDefaultK(3)
knn.predict(newcomer)
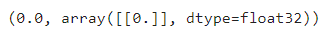



![[<span style='color:red;'>机器</span><span style='color:red;'>学习</span>]<span style='color:red;'>KNN</span>——K邻近算法<span style='color:red;'>实现</span>](https://img-blog.csdnimg.cn/direct/8054effd5f304dc99ac5db8e954295f0.png)























![[word] 如何利用word制表位快速排版菜单? #职场发展#学习方法#媒体](https://img-blog.csdnimg.cn/img_convert/4491b553bcdbe932bb71ad51e359d16a.png)

![[蓝桥杯难题总结-Python]乘积最大](https://img-blog.csdnimg.cn/direct/50d5b5988e83442289edc556482dba67.png)