数据类型和结构体的字节大小,这种问题在面试的时候,如果是刚工作不久那被问到的记录就很大,工作久了离职再面试的时候遇到的概率也不是没有。这个问题不难但是答不上来就很尴尬 …
以下示例在都是Qt Creator 5.13.1,Mscv 2017 X64编译器下测试输出,不同的编译器计算结构可能不一样。
数据类型字节大小
数据类型的字节大小,全靠死记硬背,也还好数据类型不多,面试的时候瞥一眼就行。
参考: C++ 数据类型 - 菜鸟教程
C++数据类型大小
| 类型 | 关键字 | 大小 |
|---|---|---|
| 布尔型 | bool | 1 字节 |
| 字符型 | char | 1 字节 |
| 整型 | int | 2 字节或 4字节 |
| 浮点型 | float | 4 字节 |
| 双浮点型 | double | 8 字节 |
| 无类型 | void | 0 字节 |
| 宽字符型 | wchar_t | 2 字节 |
C ++修改的数据类型列表
在64位系统上,指针大小通常为8字节,因为64位系统使用64位地址来访问内存。在32位系统上,指针大小通常为4字节。
| 类型 | 位 | 范围 |
|---|---|---|
| char | 1 个字节 | -128 到 127 或者 0 到 255 |
| unsigned char | 1 个字节 | 0 到 255 |
| signed char | 1 个字节 | -128 到 127 |
| int | 4 个字节 | -2147483648 到 2147483647 |
| unsigned int | 4 个字节 | 0 到 4294967295 |
| signed int | 4 个字节 | -2147483648 到 2147483647 |
| short int | 2 个字节 | -32768 到 32767 |
| unsigned short int | 2 个字节 | 0 到 65,535 |
| signed short int | 2 个字节 | -32768 到 32767 |
| long int | 4 个字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 |
| signed long int | 8 个字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 |
| unsigned long int | 8 个字节 | 0 到 18,446,744,073,709,551,615 |
| float | 4 个字节 | 精度型占4个字节(32位)内存空间,+/- 3.4e +/- 38 (~7 个数字) |
| double | 8 个字节 | 双精度型占8 个字节(64位)内存空间,+/- 1.7e +/- 308 (~15 个数字) |
| long double | 16 个字节 | 长双精度型 16 个字节(128位)内存空间,可提供18-19位有效数字。 |
| wchar_t | 2 或 4 个字节 | 1 个宽字符 |
Qt 数据类型字节
| 类型名称 | 注释 | 备注 | 字节大小 |
|---|---|---|---|
| qint8 | signed char | 有符号8位数据类型 | 1 字节 |
| qint16 | signed short | 有符号16位数据类型 | 2 字节 |
| qint32 | signed int | 有符号32位数据类型 | 4 字节 |
| qint64 | long long int(或__int64) | 有符号64位数据类型 | 8 字节 |
| qintptr | qint32 或 qint64 | 指针类型,用于带符号整型。 (32位系统为qint32、64位系统为qint64) | 8 字节 |
| qlonglong | long long int 或(__int64) | 和qint64定义一样 | 8 字节 |
| qptrdiff | qint32 或 qint64 | 表示指针差异的整型。32位系统为qint32、64位系统为qint64 | 8 字节 |
| qreal | double | 除非配置了-qreal float选项,否则默认为double | 8 字节 |
| quint8 | unsigned char | 无符号8位数据类型 | 1 字节 |
| quint16 | unsigned short | 无符号16位数据类型 | 2 字节 |
| quint32 | unsigned int | 无符号32位数据类型 | 4 字节 |
| quint64 | unsigned long long int 或 (unsigned __int64) | 无符号64位数据类型,Windows中定义为unsigned __int64 | 8 字节 |
| quintptr | quint32 或 quint64 | 指针类型,用于无符号整型。32位系统为quint32、64位系统为quint64 | 8 字节 |
| qulonglong | unsigned long long int 或 (unsigned __int64) | 和quint64定义一样 | 8 字节 |
| uchar | unsigned char | 无符号字符类型 | 1 字节 |
| uint | unsigned int | 无符号整型 | 4 字节 |
| ulong | unsigned long | 无符号长整型 | 4 字节 |
| ushort | unsigned short | 无符号短整型 | 2 字节 |
注 :
数据类型字节大小,这个问题简单但是又不可忽视。
就在去年6月份的时候,我面试长安外包的一个岗位的时候,
我听到排在我前面一个面试,被问到设计模式中的观察者模式,当时我还觉得这面试官有点东西,这问题有点深度,当时还不慌,设计模式我也会两个。
结果到我时候。就问了我两个问题:
int 类型占几个字节,我回答大概四个字节。
double 类型占几个字节,忘了占几个字节,没答上了,沉默。
后面要不是另外一个面试官给了个台阶,我都不知道说啥,
当时但凡问我命令模式,单例模式,生产者消费者模式,哪怕是观察者模式我都答上两句。
就因为这么个简单的问题,我痛失了一个offer!
各位引以为戒啊!
结构体字节大小
在测试计算结构体字节大小的时候,我发现sizeof 输出的结构体大小在使用
__pragma(pack(push, 16)) [将结构体的字节对齐方式设置为16字节对齐]
__pragma(pack(pop)) [指令将字节对齐方式恢复为默认值。]
对齐到16位时 ,计算出来的结果就和文言一心,老北鼻AI自能助手计算出来的结果不一致了。
结构体字节计算方式
这里的结构体字节计算方式参考的是文言一心的计算方式:
结构体的大小计算需要遵循几个原则:
结构体变量的首地址,必须是结构体“最宽基本类型成员”大小的整数倍。
结构体每个成员相对于结构体首地址的偏移量,都是该成员的整数倍。
结构体的总大小,为结构体“最宽基本类型成员”(将嵌套结构体里的基本类型也算上,得出的最宽基本类型)大小的整数倍。
计算结构体的大小时,需要考虑其包含的所有成员的大小,并将它们相加。同时,需要注意对齐问题,即结构体的总大小必须是其“最宽基本类型成员”的整数倍。这是为了确保结构体在内存中的布局是有效和高效的。
具体计算步骤如下:
- 确定结构体中每个成员的大小,并将其记录下来。
- 找出这些成员中最大的一个,即“最宽基本类型成员”。
将所有成员的大小与“最宽基本类型成员”进行比较,确定需要进行对齐的偏移量。- 根据对齐原则,计算出结构体的总大小。
- 需要注意的是,如果结构体中包含指针类型或数组类型的成员,其大小可能会因为内存对齐规则而增加。此外,不同的编译器和平台可能会有不同的对齐规则和内存布局方式,因此在实际应用中需要注意兼容性和可移植性问题。
简单示例1
//__pragma(pack(push, 1))
//__pragma(pack(push, 4))
//__pragma(pack(push, 16))
struct studentA
{
double Ad; //8字节
double bD; //8字节
int A; //4字节
int b; //4字节
char C[10]; //10字节
float F; //4字节
};
//__pragma(pack(pop))
结构体studentA的 float数据类型 前面为34字节 不是4的整数倍 .
要符合(结构体每个成员相对于结构体首地址的偏移量,都是该成员的整数倍)
所以 填充2为36字节加 4字节=40字节 。实际输出也是为40字节
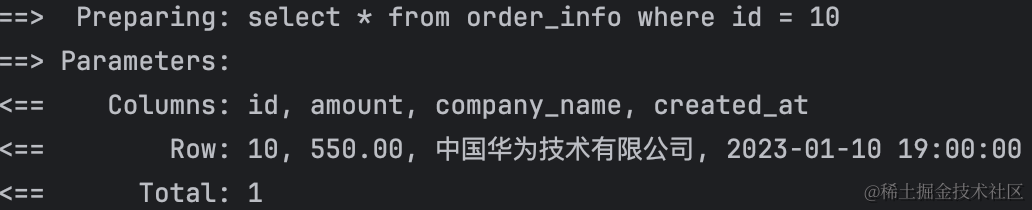
qDebug()<<"studentA size : "<<sizeof (struct studentA);
在使用
__pragma(pack(push, 1))
__pragma(pack(pop))
对齐结构体后,不填充直接为紧靠上部分内容
8+8+4+4+10+4=38字节,实际输出也是38字节,
而当我尝试到对齐16位时,sizeof输出的结果就不一样了:
/*! 老北鼻Ai智能助手
根据您提供的代码,使用__pragma(pack(push, 16))和__pragma(pack(pop))来指定结构体的字节对齐方式为16字节。
根据结构体的定义,studentA结构体包含了多个成员变量,每个成员变量的大小如下所示:
double Ad:8字节
double bD:8字节
int A:4字节
int b:4字节
char C[10]:10字节
float F:4字节
根据成员变量的大小,可以计算出结构体的总大小为8 + 8 + 4 + 4 + 10 + 4 = 38字节。
然而,由于使用了__pragma(pack(push, 16))指定了16字节的对齐方式,结构体的对齐大小将会是16字节的倍数。这意味着结构体的实际大小将会是16的倍数,而不是简单地将所有成员变量的大小相加。
在这种情况下,结构体studentA的大小将会是16字节的倍数中大于或等于38字节的最小值,即48字节。
*/
/* 文心一言
使用__pragma(pack(push, 16))指定了16字节的对齐方式。这意味着结构体中的每个成员都应该在16字节的边界上对齐。
按照这种方式,结构体的大小计算如下:
double Ad; 和 double bD; 会被对齐到16字节的边界,因此总大小为16 + 8 = 24字节。
int A; 和 int b; 会被对齐到16字节的边界,因此总大小为16 + 4 = 20字节。
char C[10]; 由于是一个字符数组,它的大小为10字节。
float F; 通常为4字节。
现在我们需要考虑填充字节,以确保整个结构体的大小是16字节的倍数。从前面的计算中,我们知道总大小为24 + 20 + 10 + 4 = 58字节。为了使结构体大小为16字节的倍数,我们需要添加7个填充字节,使其达到64字节。
*/
/* 实际__pragma(pack(push, 16)) 输出为40 */
简单示例2
//__pragma(pack(push, 1))
//__pragma(pack(push, 4))
//__pragma(pack(push, 16))
struct studentB
{
int A; //4字节
int B; //4字节
int C; //4字节
double D; //8字节
qint16 E; //2字节
long F; //4字节
};
//__pragma(pack(pop))
double类型 前面有12字节,不是8字节的整数倍 填充4 12+4+8=24字节
long类型 前面有26 字节 不是4的整数倍 填充2 26+2+4=32字节
使用 __pragma(pack(push, 1)) 对齐后 不填充26字节
使用 __pragma(pack(push, 4)) 对齐到4的整数倍 所以为28字节
使用 __pragma(pack(push, 16)) 对齐到16的整数倍 所以为32字节
而在文言一心和老北鼻AI智能助手中:
/* 老北鼻Ai智能助手
根据你提供的代码,结构体studentB的字节大小应该是32字节。
在这段代码中,__pragma(pack(push, 16))指令将结构体的字节对齐方式设置为16字节,这意味着结构体的成员将按照16字节对齐。接着,结构体studentB包含了6个成员变量,每个变量的大小如下:
int A: 4字节
int B: 4字节
int C: 4字节
double D: 8字节
qint16 E: 2字节
long F: 4字节
将这些成员变量的大小相加,得到结构体studentB的总大小为32字节。
最后,__pragma(pack(pop))指令将字节对齐方式恢复为默认值。
*/
/* 文心一言
首先,我们需要明确qint16的大小。qint16通常是一个16位的有符号整数,因此其大小是2字节。
在使用__pragma(pack(push, 16))时,我们指定了16字节的对齐方式。这意味着结构体中的每个成员都应该在16字节的边界上对齐。编译器会在必要的地方插入填充字节,以确保满足这个对齐要求。
按照这种方式,结构体的大小计算如下:
int A; 占用4字节。
int B; 占用4字节。
int C; 占用4字节。
double D; 通常为8字节,但由于对齐规则是16字节,它可能不会紧接在C后面,因为它的大小超过了8字节。它可能会在A、B和C后面留下一些填充,以确保其位于16字节的边界上。
qint16 E; 占用2字节。
long F; 通常为4字节,但由于对齐规则是16字节,它可能不会紧接在E后面,因为它的大小小于8字节。它也可能会在E后面留下一些填充,以确保其位于16字节的边界上。
结构体的大小计算为:
A、B和C的总大小是 4 + 4 + 4 = 12字节。
由于D和F都需要填充到16字节的边界,所以它们之间的填充取决于编译器如何处理这种情况。如果D和F都紧接在A、B和C后面,那么它们之间的填充将是必要的,以确保D和F都在16字节的边界上。这个填充的大小将取决于编译器和目标架构的实现。
要获得确切的大小,最好使用sizeof(struct studentB)来计算实际的大小,因为这会考虑到特定编译器和目标架构的填充和对齐要求。
*/
/* 实际__pragma(pack(push, 16)) 输出 32字节*/
参考:
涉及的一个项目案例
当我在测试时结构体对齐的时候,我想到我以前做过的一个报文数据处理的项目。
报文数据都是按照指定的结构生成的,这意味着可以直接将数据流转换成结构体数据,
这样一来读取数据和处理数据的方式将变得更加简单,能更快提升数据的处理方式,这在超大数据量的数据处理里面更有效。
测试数据:
/*一个txt文本的报文数据
000000 000000 02000 0000000000000001
000000 000000 01000 0000000000000002
000000 000000 04000 0000000000000003
000000 000000 05000 0000000000000024
000000 000000 03000 0000000000000005
000000 000000 01000 0000000000000036
000000 000000 05000 0000000000000007
000000 000000 04000 0000000000000008
000000 000000 03000 0000000000000009
000000 000000 04000 0000000000000010
000000 000000 05000 0000000000000011
000000 000000 06000 0000000000000012
000000 000000 07000 0000000000000013
000000 000000 08000 0000000000000014
000000 000000 06000 0000000000000015
*/
值得注意的是,使用char[]类型获取的数据是从字节开始位置截断的,又没有’\0’截断所以会打印出整个后续字符串;字符串的长度和结构体的字节大小也必须一致
测试无符号字符串转结构体代码:
//!
//! \brief Read_Sector_Buffer
//! \param 开始大小
//! \param pBuf
//! \return
//!
bool Read_Sector_Buffer(HANDLE hFile,DWORD SectorSize,void *pBuf)
{
BOOL r = FALSE;
LARGE_INTEGER ptr;
DWORD Size;
if (pBuf == NULL) {
qDebug("没有分配内存!");
goto out;
}
if(SectorSize > 0xFFFFFFFFUL)
{
qDebug("读取数据太多!\n");
goto out;
}
Size = SectorSize;
///从头开始读取
ptr.QuadPart=0;
///https://learn.microsoft.com/zh-cn/windows/win32/api/fileapi/nf-fileapi-setfilepointerex
if(!SetFilePointerEx(hFile, ptr, NULL, FILE_BEGIN))
{
qDebug("read_sectors: Could not SetFilePointerEx!");
return -1;
}
///https://learn.microsoft.com/zh-cn/windows/win32/api/fileapi/nf-fileapi-readfile
r=(ReadFile(hFile, pBuf, Size, &Size, NULL));
if(!r)
qDebug()<<"ReadFile is Losed! Size : "<<Size;
out:
return r;
}
//https://www.thinbug.com/q/32612881
//https://blog.51cto.com/u_14615453/5704406
//https://learn.microsoft.com/zh-cn/cpp/c-runtime-library/reference/aligned-malloc?view=msvc-170
//https://blog.csdn.net/u013001137/article/details/131810867
void readText_WindowsApi()
{
qDebug()<<"[vData] "<<sizeof(vData);
HANDLE hFile;
QString text_Read="C:\\Users\\admin\\Desktop\\text.txt";
hFile=CreateFileW(_utf8_to_wchar(text_Read.toStdString().c_str()), GENERIC_READ|GENERIC_WRITE,
FILE_SHARE_READ|FILE_SHARE_WRITE,
NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);
DWORD Size=0;
LARGE_INTEGER fileSize;
if (!GetFileSizeEx(hFile, &fileSize))
Size=1024;
else
Size=fileSize.QuadPart;
unsigned char* buffer = (unsigned char*)_mm_malloc(Size, 16);
//https://blog.csdn.net/qq_40830407/article/details/80279134
//strlen(char*)函数求的是字符串的实际长度,它求得方法是从开始到遇到第一个'\0',如果你只定义没有给它赋初值,这个结果是不定的,它会从aa首地址一直找下去,直到遇到'\0'停止
// buffer[Size]='\0';
int lenth=strlen((char*)buffer);
qDebug()<<" buffer length :"<< lenth;
Read_Sector_Buffer( hFile,Size,buffer);
char* Data=( char*)_mm_malloc(36, 16);
qDebug()<<"Data length: "<< strlen((char*)Data);
int Row=1;
int column=0;
for(int i=0;i<Size;i++)
{
// qDebug()<<buffer[i];
//CRLF 换行 占两字节
if((int)buffer[i]==13 && i+1<lenth && (int)buffer[i+1]==10)
{
if(Data!=nullptr && column>0)
{
qDebug()<<"[column] "<<column;
Data[column]='\0';
printf("%s\n", (char*)Data);
PData tryPData ;
memcpy(tryPData, Data, sizeof(vData));
if(tryPData!=nullptr)
{
// printf("A_2: %s\n", (char*)tryPData->A_2);
// printf("C_3: %d\n", tryPData->C_3);
qDebug()<<"[A] "<<tryPData->A;
qDebug()<<"[B] "<<tryPData->B;
qDebug()<<"[C] "<<tryPData->C;
qDebug()<<"[E] "<<tryPData->E;
qDebug()<<"[D] "<<tryPData->D;
qDebug()<<"[C_3] "<<tryPData->C_3;
}
_mm_free(Data);
Data=nullptr;
Data=(char*)_mm_malloc(36, 16);
Row++;
qDebug()<<"行 : "<<Row;
column=0;
}
//跳过换行符
i=i+1;
continue;
}
if(Data!=nullptr)
{
// if((int)buffer[i]==32)
// Data[column]='\0';
// else
Data[column]= (char)buffer[i];
column++;
}
}
if(Data!=nullptr)
{
qDebug()<<"[column] "<<column;
Data[column]='\0';
printf("%s\n", (char*)Data);
_mm_free(Data);
Data[36]={
0};
}
qDebug()<<"[buffer] "<<buffer;
_mm_free(buffer);
CloseHandle(hFile);
}
无符号字符串转结构体两种写法:
PData tryPData ; memcpy(tryPData, Data, sizeof(vData));
PData tryPData = (PData )(void*)Data;
涉及的一个面试题
我记得去年有次电话面试的时候,有个面试官问我一个问题,
如何在一篇混杂着中文或者其他符号的英文文章中提取去完整的英文,
我回答的是:
读取文件所有内容,循环文本内容再内循环ABCDEF…的字符串去匹配,
很好,又错失一个offer…
现在我再一想,这不就是一个字节操作吗,
读取文章的所有字节,在用匹配英文的ASCII字符代码不就行了。
数据示例,简单混淆的内容:
/*
Title: The Vibrant Beauty of Nature
【
Nature is a masterpiece 2 of magnificent landscapes that leaves a lasting impression on anyone who takes the time to observe it. From the serene beauty of a quiet lake to 混淆文章 the breathtaking grandeur of a mountain range, nature's landscapes offer a myriad of experiences that are both humbling and inspiring. 0】
中文
One of the most captivating aspects of nature is the dynamic range of colors it displays. 3 The lush green of forests, the 5 vibrant hues of flowers, and the warm golden rays of the 9 sun create 8 a canvas that is both visually appealing and soothing to the soul. As the sun rises and sets, nature's colors transform, bathing the landscape in a soft pink glow or a fiery orange hue that is simply breathtaking.、
【
Another element that adds to nature's beauty is the sense 9 of tranquility it exudes. Whether it's the calming sound of a babbling brook or the gentle rustling of leaves in the wind0, nature has a way of soothing the soul and washing away the stresses of the day. It's in these moments of serenity that we can find peace and clarity, allowing us to reconnect with our inner selves and the world around us.、
用清晰、准=
Nature's landscapes are also a showcase of biodiversity. 0 From the smallest blade of grass to the tallest tree, each species plays an integral role in creating the intricate web of life that characterizes our planet. The flora and fauna that inhabit these landscapes are a testament to the wonders of creation, 欣赏 and 6 their presence adds a layer of richness and complexity that is truly awe-inspiring. 风景-
=
Moreover, nature's landscapes serve as a reminder of our place in the universe. From the vast expanse of the ocean to the soaring peaks of mountains, nature's grandeur can make us feel small yet alsoconnected to something grea-ter than ourselves. It's in these moments of reflection that we can gain a deeper understanding of our place in the world and appreciate the beauty and fragility of our planet.+
理解 ;
In conclusion, nature's landscapes are more than just & pretty views; * they are a canvas upon which the stories of life are painted. They are a reminder of our shared humanity and our responsibility to preserve and prote=ct the natural world that sustains us. It's only by experiencing and appreciating nature's beauty that we can truly understand its value and ensure its survival for generations to come.
*/
代码示例:
///英文识别
void readEnglish_Clearconfusion()
{
HANDLE hFile;
QString text_Read="C:\\Users\\admin\\Desktop\\Clearconfusion.txt";
hFile=CreateFileW(_utf8_to_wchar(text_Read.toStdString().c_str()), GENERIC_READ|GENERIC_WRITE,
FILE_SHARE_READ|FILE_SHARE_WRITE,
NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);
DWORD Size=0;
LARGE_INTEGER fileSize;
//获取文件大小
if (!GetFileSizeEx(hFile, &fileSize))
Size=1024*1024;
else
Size=fileSize.QuadPart;
unsigned char* buffer = (unsigned char*)_mm_malloc(Size, 16);
Read_Sector_Buffer( hFile,Size,buffer);
unsigned char* new_buffer=new unsigned char[Size]();
int colume=0;
for(int i=0;i<Size;i++)
{
if( (65<= (int)buffer[i] && (int)buffer[i]<=90) ||
(97<=(int)buffer[i] && (int)buffer[i]<=122) ||
(int)buffer[i]==44 || //","
(int)buffer[i]==46 || //"."
(int)buffer[i]==32 || //" "
(int)buffer[i]==10 || //"LF"
(int)buffer[i]==13 //"CR"
)
{
new_buffer[colume]=buffer[i];
colume++;
}
}
printf(" %s\n", (char*)new_buffer);
_mm_free(buffer);
free(new_buffer);
CloseHandle(hFile);
}
当然,这只是现在我能想到的好办法,在力扣或者其他文章中应该有更好的解决办法。





![[C++]深入解析:如何<span style='color:red;'>计算</span>C++类或<span style='color:red;'>结构</span><span style='color:red;'>体</span>的<span style='color:red;'>大小</span>](https://img-blog.csdnimg.cn/direct/0b09226a6fd34ed9a7f3cd2cdf60f090.png)





















![[Python] 什么是逻辑回归模型?使用scikit-learn中的LogisticRegression来解决乳腺癌数据集上的二分类问题](https://img-blog.csdnimg.cn/direct/3585c45763514fecb1b95de83c3a0084.png)