大、小端字节序
一个整形数据在内存中的存储方式是该数据的补码;
该数据本事的数据是从高地址位到低地址位的,而计算机的内存中刚好相反!
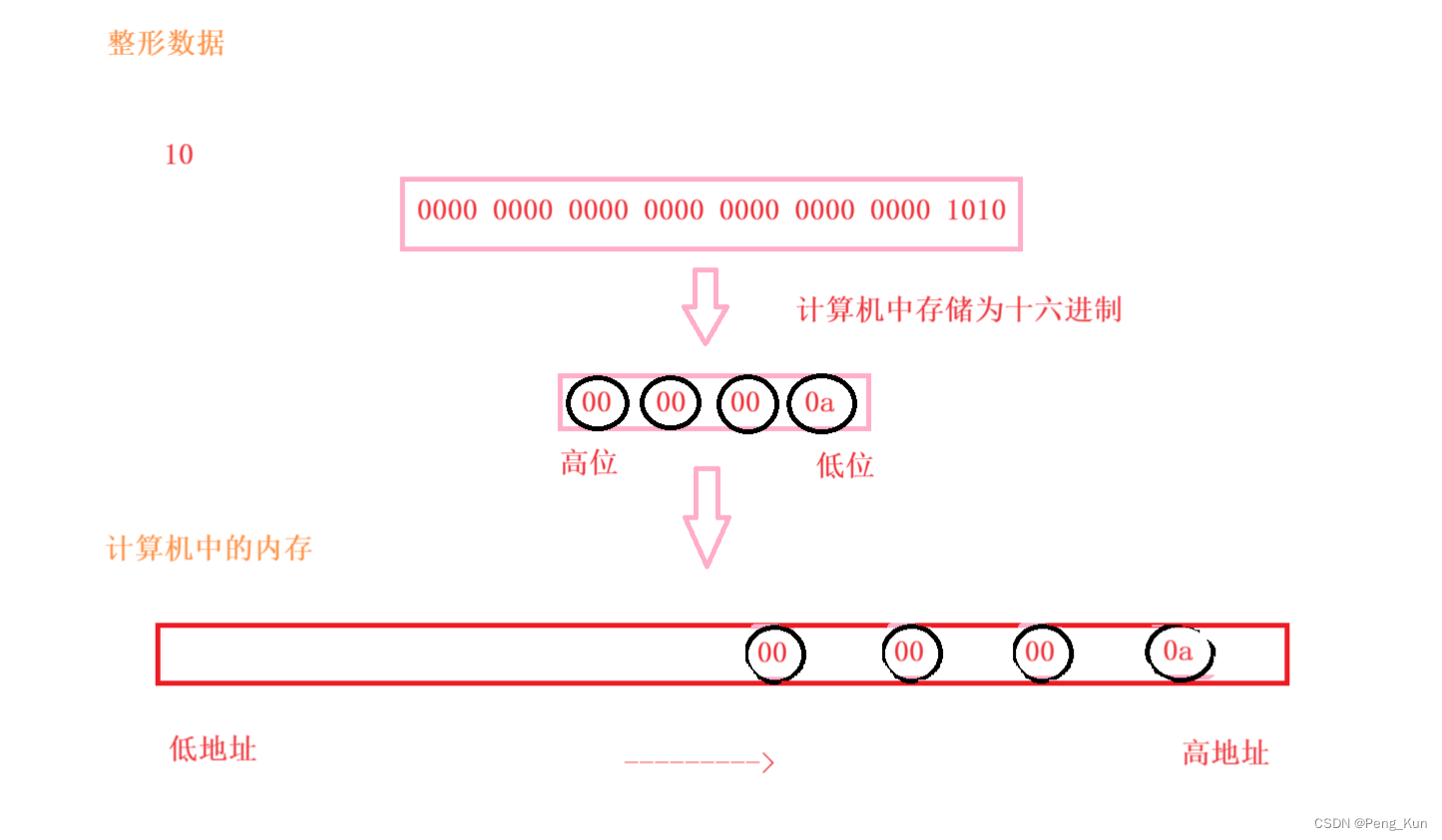
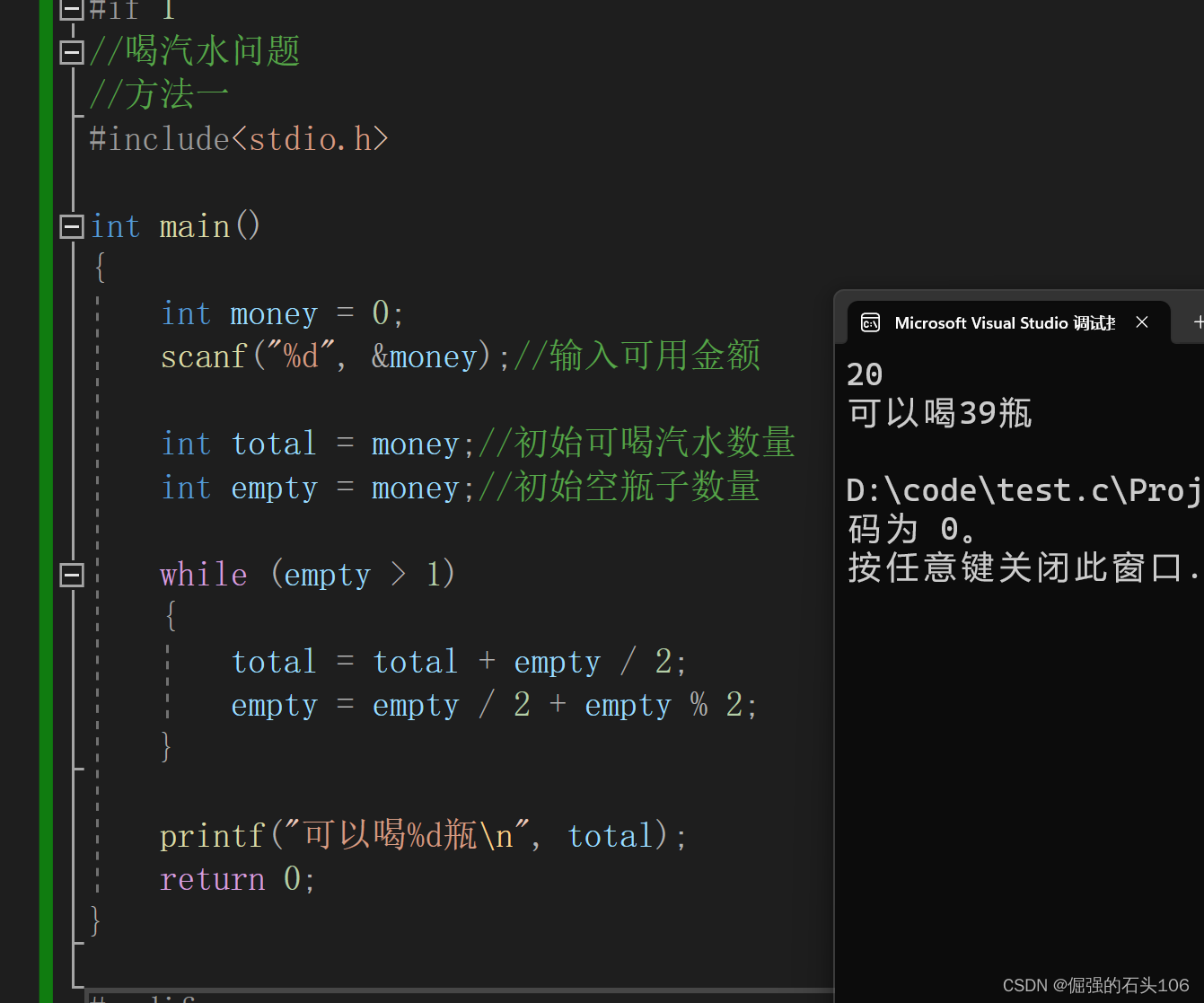
以数字10为例:
补码:0000 0000 0000 0000 0000 0000 0000 1010
补码的十六进制数为:0x00 00 00 0a
而在编译器中查看为:0a 00 00 00
以CLion为例:
#include<stdio.h>
int main()
{
int a = 10;
int b = -10;
return 0;
}
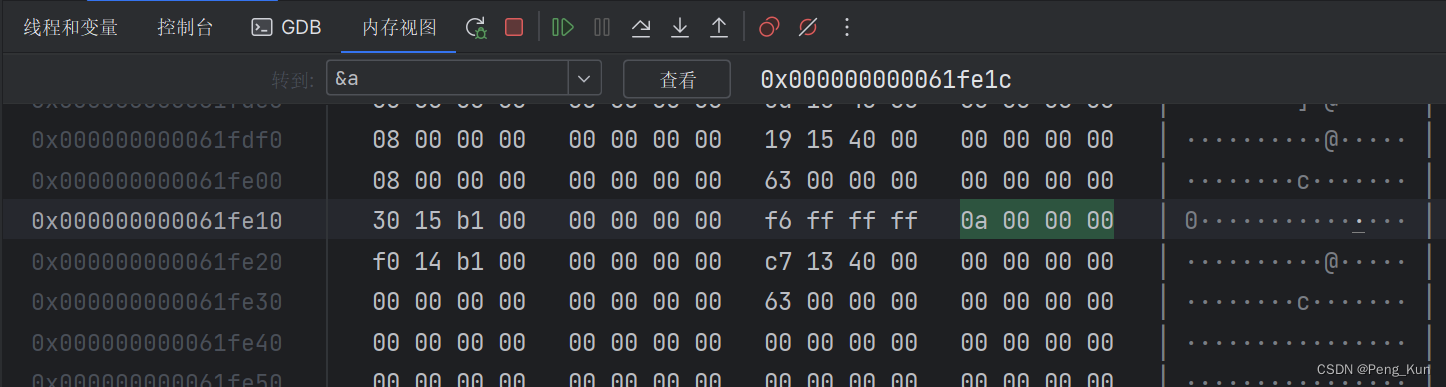
a在内存中为
0a 00 00 00
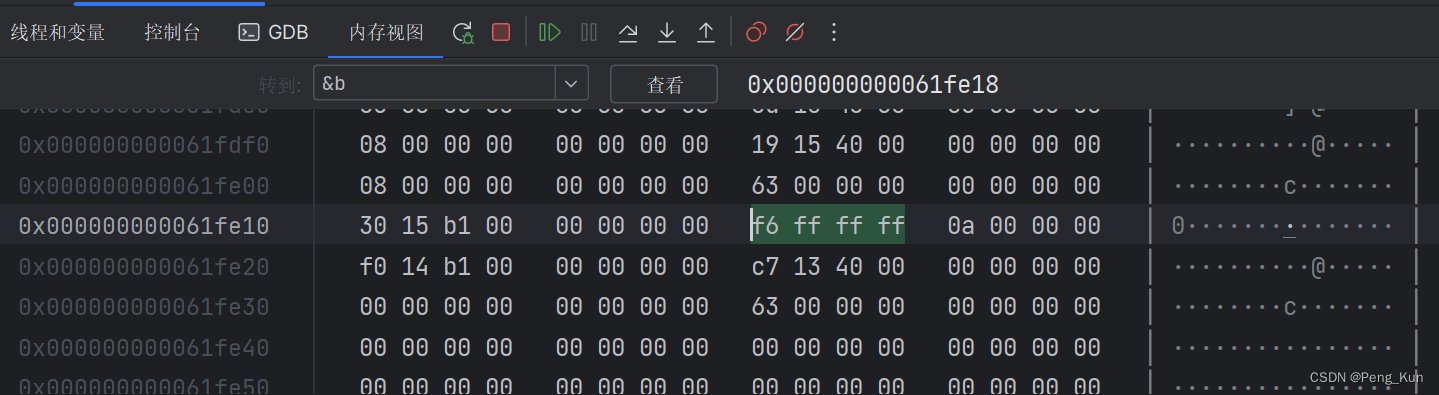
b在内存中为
f6 ff ff ff
介绍
大端字节序
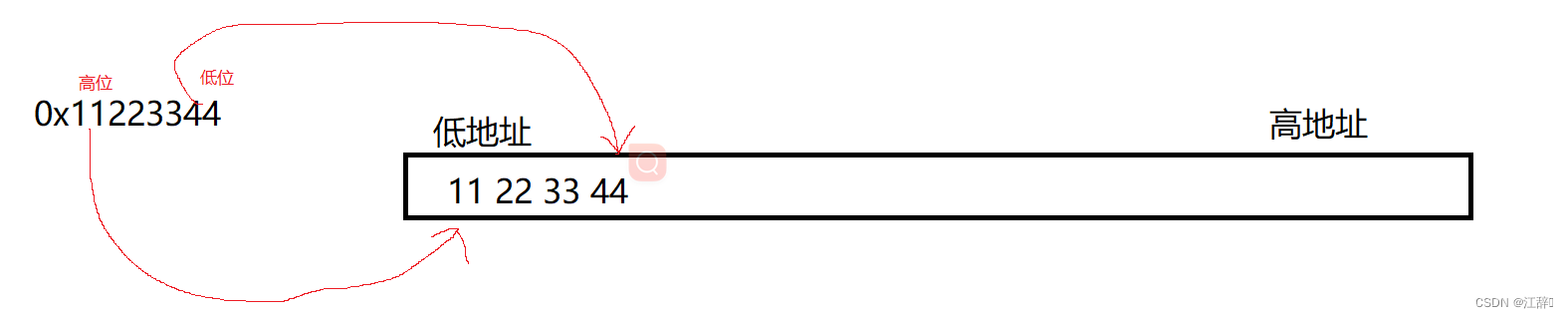
数据的低位保存在内存的高地址位中,而数据的高位保存到低地址位中;
小端字节序
数据的低位保存在内存的低地址位中,而数据的高位保存到高地址位中;

编写程序来判度当前机器是大端还是小端字节序
C语言
1)首先创建一个整形变量
int a = 1;2)如果当前机器是以小端字节序来存储的,那么整形变量a在内存中为
01 00 00 00,第一个字节为01;反之为00;*(char*)&a; // &a取a的第一个字节3)通过判断
*(char*)&a的值来判断结果;if (*(char*)&a ) printf("小端!\n"); else printf("大端!\n");
完整代码:
#include<stdio.h>
int check_system()
{
int test_data = 1;
return *(char*)&test_data;
}
int main()
{
if (check_system())
printf("小端!");
else
printf("大端!");
return 0;
}
Python
由于经常使用Python来进行工作,在了解完大小端之后就想着使用Python来完成一下判断大小端。
但是在准备使用与C语言同样的思想来实现的时候,发现Python无法像C语言那样充分的调用底层来实现。
经过不断的查找发现Python中拥有更为方便的封装方法!
代码
import sys print(sys.byteorder)
运行结果
little
总结
通过判断当前机器是大端还是小端字节序的过程中再次感受到了
更为底层的C语言,以及简洁且强大的Python

![[C语言]数据<span style='color:red;'>的</span><span style='color:red;'>存储</span>_数据类型:整形<span style='color:red;'>存储</span>和<span style='color:red;'>大小</span><span style='color:red;'>端</span>](https://img-blog.csdnimg.cn/direct/d3166bc06e9b41a8860259edb4e3b60a.png)



![[嵌入式系统-45]:图解内存访问<span style='color:red;'>的</span><span style='color:red;'>大小</span><span style='color:red;'>端</span><span style='color:red;'>模式</span>:小<span style='color:red;'>端</span>顺、<span style='color:red;'>大端</span>逆](https://img-blog.csdnimg.cn/direct/6f36b522fbcb4f8eae79d2a870081bf7.png)






















![[word] word大小写快捷键是什么? #知识分享#学习方法#笔记](https://img-blog.csdnimg.cn/img_convert/584150bc5f8f7a5882d9b6c06cc755eb.jpeg)



![[word] word页面视图放大后,影响打印吗? #笔记#学习方法](https://img-blog.csdnimg.cn/img_convert/b0f507e3421d4317b2c4620b0ffc2d28.jpeg)