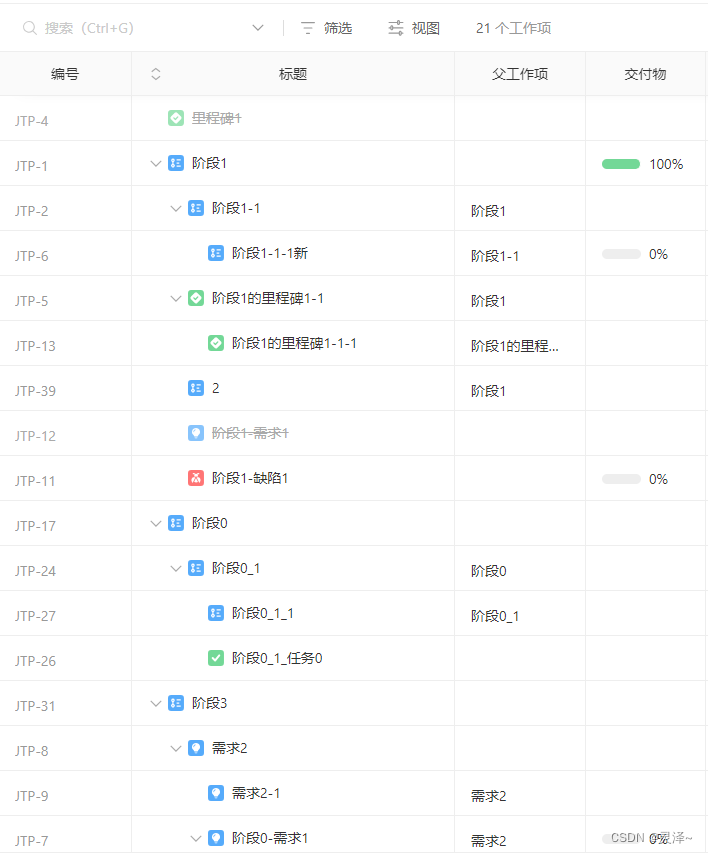
有需要实验报告的可CSDN 主页个人私信
《大数据统计分析软件(R语言)》
实 验 报 告
指导教师:
专 业:
班 级:
姓 名:
学 号:
完成时间:
实验目的
掌握数据读入的各类函数;简单的数据处理:新变量的生成,数据集筛选排序,数据集合并。
掌握dplyr包中的主要函数。
掌握绘图的主要函数。
掌握数据整理、描述性统计分析、回归等,较为完整的数据分析过程。
实验内容
读入数据集:“(1)2002-2022年网民数量.csv”
- 计算半年度网民数量增长率;
# 引入所需的库
library(readr)
library(dplyr)
library(lubridate)
# 读取数据
# data <- read_csv("(1)2002-2022年网民数量.csv")
data <- read_csv("(1)2002-2022年网民数量.csv", locale = locale(encoding = "GB2312"))
# 使用head函数查看数据前10行
head(data, 10)
# 重命名列名
data <- data %>%
rename(
时间 = 时间,
网民数量 = `网民数量(万人)`,
互联网普及率 = `互联网普及率`
)
# 将时间转换为日期
data$时间 <- dmy(paste0("01-", data$时间), tz = "UTC")
# 将互联网普及率转换为数值类型
data$互联网普及率 <- as.numeric(gsub("%", "", data$互联网普及率)) / 100
# 计算半年度网民数量增长率
data <- data %>%
arrange(时间) %>%
mutate(增长率 = (网民数量 - lag(网民数量)) / lag(网民数量))
# 使用head函数查看数据前10行
head(data, 10)- 根据网民数量、网民数量增长率绘制双轴图,网民数量用柱状图表示,网民数量增长率用折线图表示;
双轴图如图1所示:
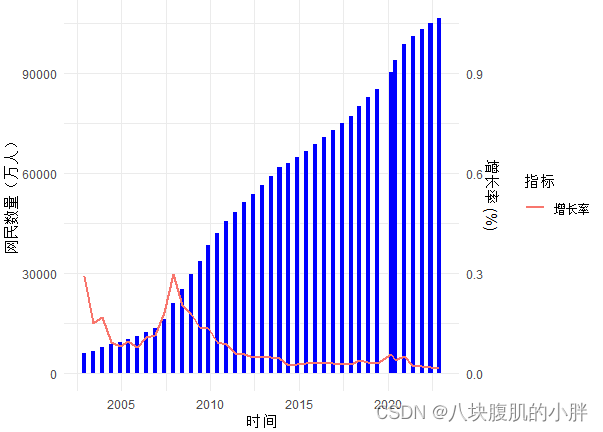
图1双轴图
代码如下:
# 将增长率列转换为数值类型
data$增长率 <- as.numeric(data$增长率)
# 移除第一个NA值
data <- data[-1, ]
# 绘制图表
# 输出增长率的数值
print(data$增长率)
ggplot(data, aes(x = 时间)) +
geom_col(aes(y = 网民数量), fill = "blue") +
geom_line(aes(y = 增长率 * 100000, color = "增长率"), size = 1) + # 增大增长率的显示范围
scale_y_continuous(name = "网民数量(万人)", sec.axis = sec_axis(~./100000, name = "增长率 (%)")) +
theme_minimal() +
labs(color = "指标")- 根据图形说明我国网民规模的变化趋势与特征。
从图形可以看出,我国网民数量呈现出明显的增长趋势。从2002年到2022年底,网民数量从约4580万人增长到约106744万人,增长了近23倍。这表明互联网的普及程度不断提高,越来越多的人开始使用互联网。
增长率特征:增长率是描述网民数量增长速度的指标。从图形中可以看出,增长率在不同时间段内有所波动。初期增长率较高,随着网民数量的增加,增长率逐渐趋于平缓。可以观察到,在2002年到2007年初期,增长率呈现出较大的波动,而在2014年后增长率相对较稳定。
互联网普及率变化:互联网普及率是衡量互联网在整个人口中普及程度的指标。根据数据,互联网普及率从2002年的0.036增长到2022年底的0.756。这显示了互联网的普及程度不断提高,越来越多的人开始接触和使用互联网。
综上所述,通过观察图形,我们可以看到我国网民规模的变化趋势是逐年增长,并且增长率逐渐稳定。互联网普及率也在不断提高,显示出我国互联网发展的活跃态势。
读入数据集:“(2)2007-2022年接入方式.csv”
与“(1)2002-2022年网民数量.csv”进行合并
代码如下:
# 读取数据集
data1 <- read.csv("(1)2002-2022年网民数量.csv")
data2 <- read.csv("(2)2007-2022年接入方式.csv")
# 合并数据集
merged_data <- merge(data1, data2, by = "时间")
head(merged_data, 10)
# 保存合并后的数据集为CSV文件
write.csv(merged_data, "合并后数据.csv", row.names = FALSE)前十个数据结果显示如图2所示:

图2合并后前十条数据
- 计算出手机上网比例、电视网民数、台式电脑网民数、笔记本电脑网民数、平板电脑网民数(不同接入方式人数有重合,总数会大于真实网民数量)
代码如下:
# 读取合并后的数据集
merged_data <- read.csv("合并后数据.csv")
# 计算手机上网比例
merged_data$手机上网比例 <- as.numeric(gsub("%", "", merged_data$手机网民数量.万人.)) / merged_data$网民数量.万人. * 100
# 将因子列转换为数值型
merged_data$电视网民数 <- as.numeric(gsub("%", "", merged_data$电视上网比例))
merged_data$台式电脑网民数 <- as.numeric(gsub("%", "", merged_data$台式电脑上网比例))
merged_data$笔记本电脑网民数 <- as.numeric(gsub("%", "", merged_data$笔记本电脑上网比例))
merged_data$平板电脑网民数 <- as.numeric(gsub("%", "", merged_data$平板电脑上网比例))
# 打印计算结果
print(merged_data[, c("时间", "手机上网比例", "电视网民数", "台式电脑网民数", "笔记本电脑网民数", "平板电脑网民数")])数据展示前十条,如图3所示:
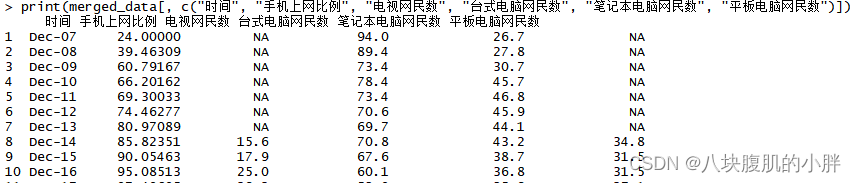
图3合并后前十条数据
- 根据数据绘制各种接入方式比例的折线图,并比较说明每种接入方式的变化趋势与特征。
各种接入方式变化的折线图如图4所示;

图4 接入方式折线图
在整体趋势上,电视上网比例呈现下降趋势,从高达94.00%逐渐下降至约31.10%左右。从7-Dec到8-Dec有较大幅度的下降,之后逐渐下降至最低点,之后保持相对稳定。
台式电脑上网比例呈现下降趋势,从26.70%逐渐下降至约29.80%左右。从7-Dec到8-Dec有轻微上升,之后逐渐下降至最低点,之后保持相对稳定。
笔记本电脑上网比例呈现下降趋势,从26.70%逐渐下降至约28.30%左右。从7-Dec到8-Dec有较大幅度的上升,之后逐渐下降至最低点,之后保持相对稳定。
平板电脑上网比例呈现下降趋势,从34.80%逐渐下降至约27.50%左右。从14-Dec到15-Dec有轻微的上升,之后逐渐下降至最低点,之后保持相对稳定。
各种接入方式的变化趋势都呈现下降的特征,其中电视上网比例下降幅度最大,而台式电脑、笔记本电脑和平板电脑的下降趋势相对较缓。这可能反映了手机和移动设备的普及,以及人们更多地倾向于使用便携式设备进行上网。
-
- 读入数据集:“(3)2008-2022年网民结构.csv”
与“(1)2002-2022年网民数量.csv”进行合并; 代码: # 读取数据集 data1 <- read.csv("(3)2008-2022年网民结构.csv", header = TRUE, stringsAsFactors = FALSE) data2 <- read.csv("(1)2002-2022年网民数量.csv", header = TRUE, stringsAsFactors = FALSE) # 合并数据集 merged_data <- merge(data1, data2, by = "时间") # 修改列名 colnames(merged_data)[colnames(merged_data) == "X10岁以下"] <- "10岁以下" colnames(merged_data)[colnames(merged_data) == "X10.19岁"] <- "10-19岁" colnames(merged_data)[colnames(merged_data) == "X20.29岁"] <- "20-29岁" colnames(merged_data)[colnames(merged_data) == "X30.39岁"] <- "30-39岁" colnames(merged_data)[colnames(merged_data) == "X40.49岁"] <- "40-49岁" colnames(merged_data)[colnames(merged_data) == "X50.59岁"] <- "50-59岁" colnames(merged_data)[colnames(merged_data) == "X60岁及以上"] <- "60岁及以上" colnames(merged_data)[colnames(merged_data) == "小学及以下"] <- "小学及以下" # 显示前10条数据 head(merged_data, 10) # 将合并后的数据保存到CSV文件 write.csv(merged_data, file = "合并后的数据.csv", row.names = FALSE)
- 读入数据集:“(3)2008-2022年网民结构.csv”
运行结果如图5所示:
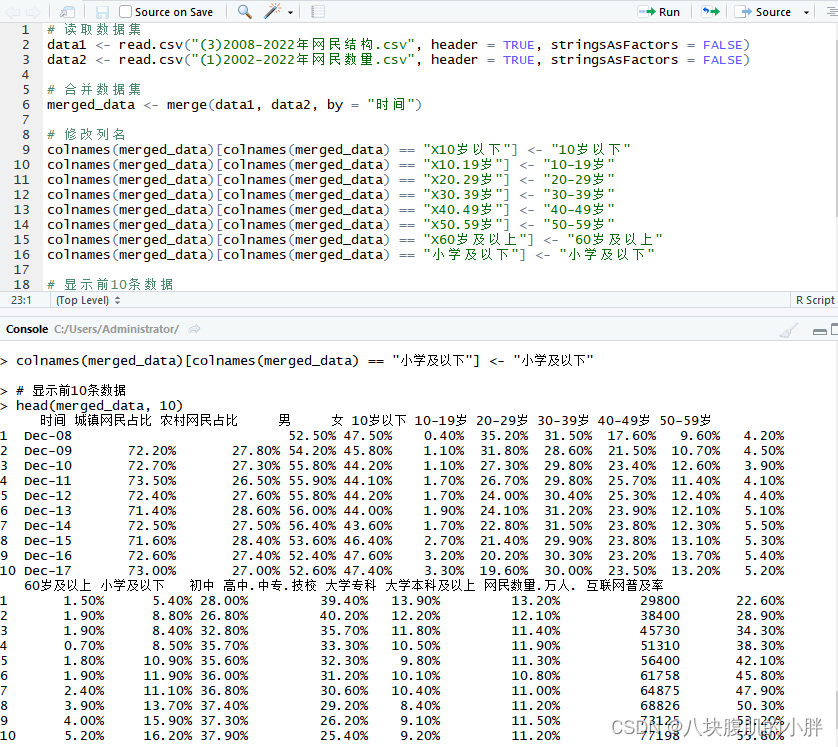
图5 合并后数据前10条
- 编写函数计算出城镇网民数量、农村网民数量、男性网民数量、女性网民数量、各年龄层网民数量、各学历网民数量(可以编写函数通过apply族函数进行批量处理,也可以直接编写循环函数直接一次性得到所有结果);
......运行结果如图6所示:
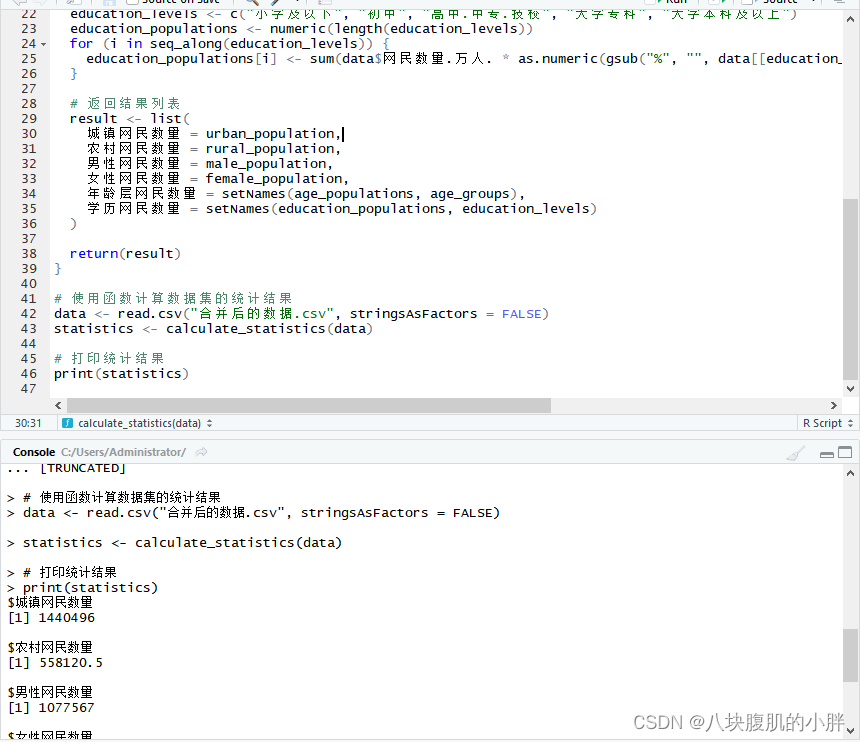
图6 程序运行界面
- 进一步计算网民性别比(以女性网民为100,男性对女性的比例)、城乡比(以农村网民为100,城镇对农村的比例)、年龄比(以19岁以下网民为100,其他年龄层对19岁以下的比例)、学历比(以初中及以下网民为100,其他学历对初中及以下的比例);
代码如下:
......
......
......
......
......
......