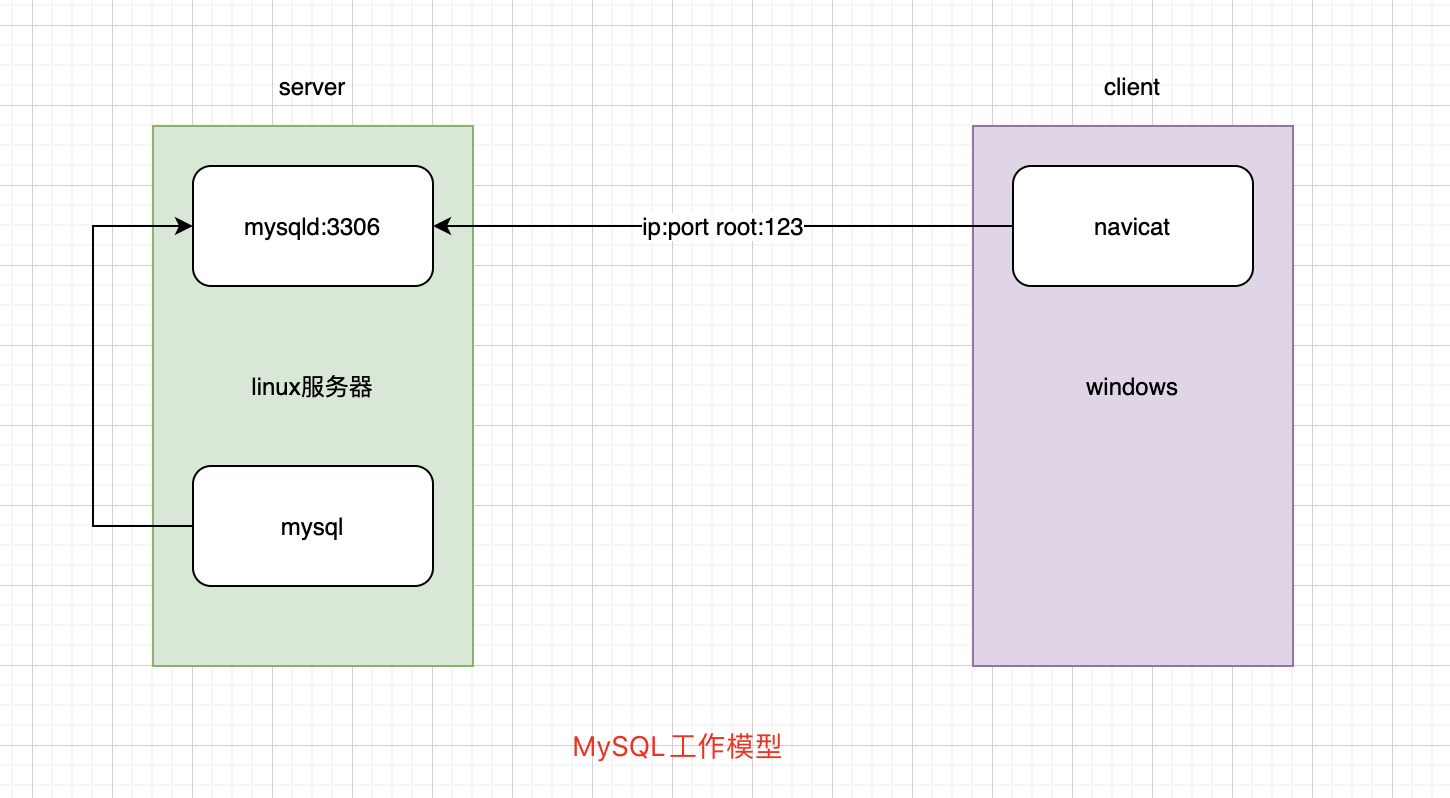
#下厨房的菜谱搜索(多个请求参数),注:只支持搜索功能,不具备多页爬取功能
import requests
#请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'
}
title = input('请输入菜名:')
params = {
'keyword':title,
'cat':'1001'
}
#1.指定url
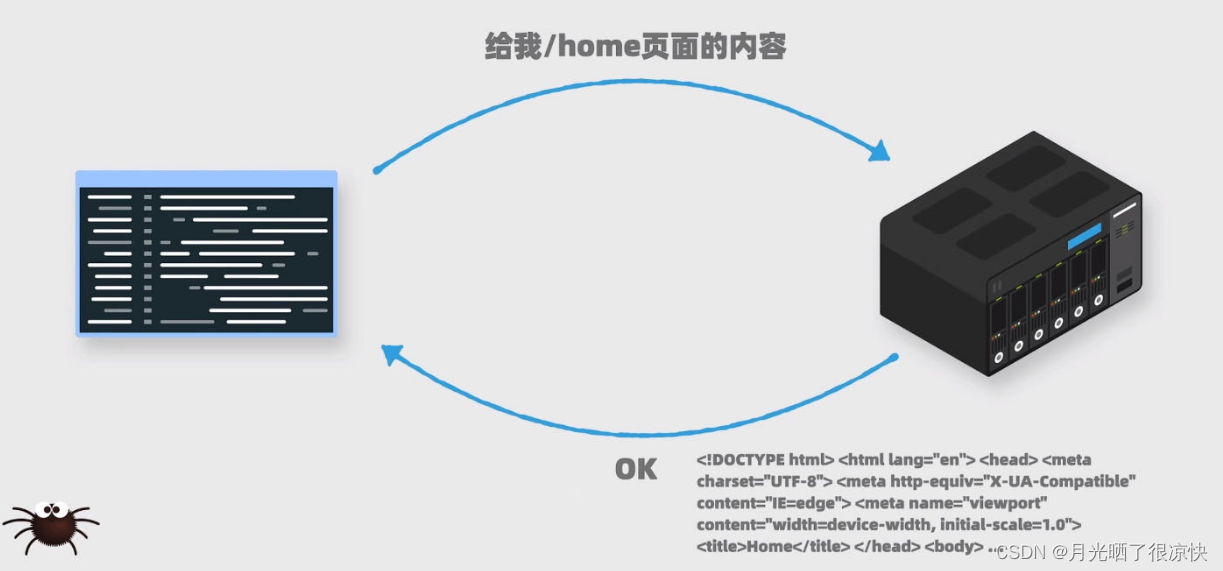
url = 'https://www.xiachufang.com/search/'
#2.发起请求
response = requests.get(url=url,headers=headers,params=params)
#3.获取响应数据
page_text = response.text
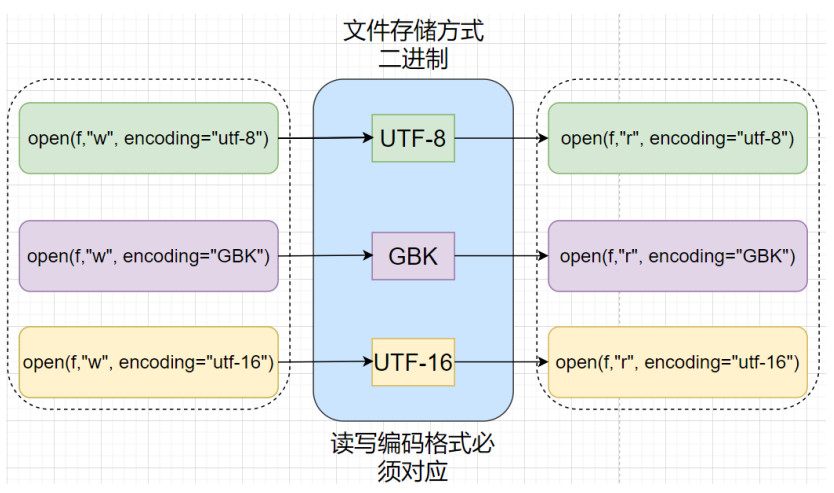
#4.持久化存储
fileName = title + '.html' #创建html文件
with open(fileName,'w',encoding='utf-8') as f: #注意编码格式
f.write(page_text)
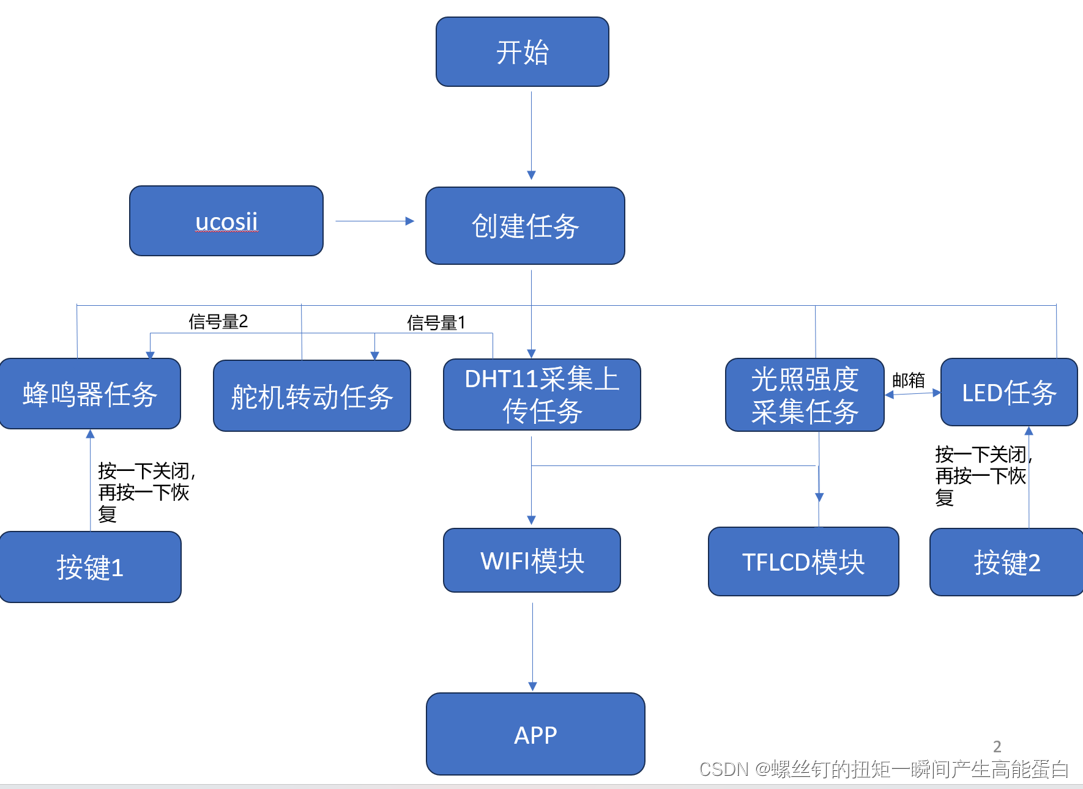
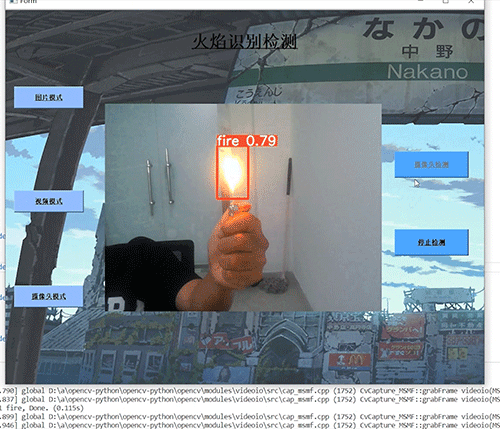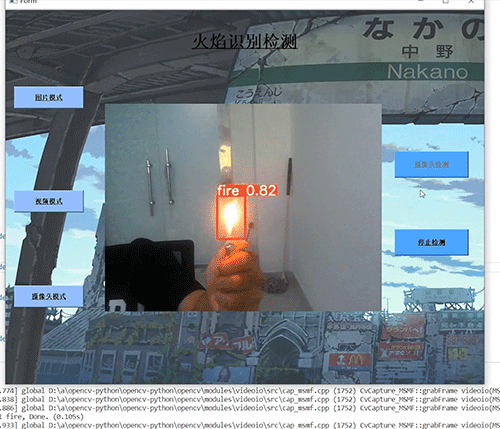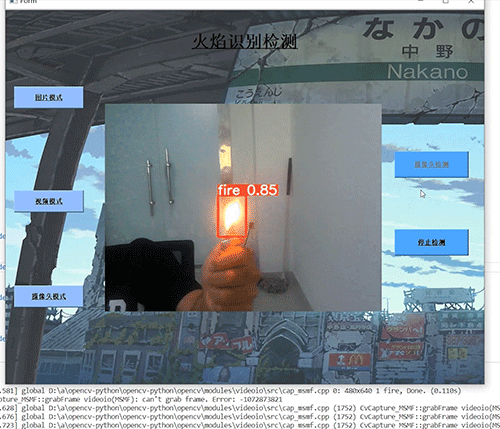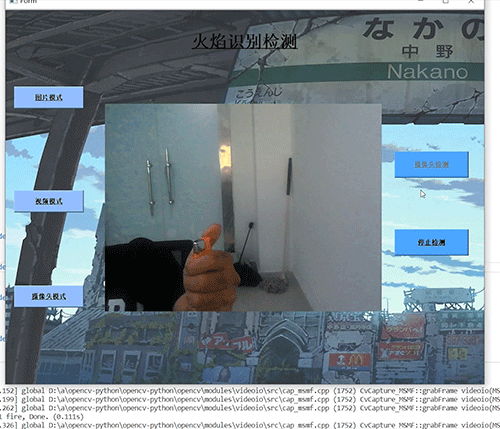
基于ucosii的厨房预警监测系统
2024-02-02 11:22:01 25 阅读