在数据库查询中,GROUP BY语句允许我们按某些字段对数据集进行分组,并在每个分组上应用聚合函数。但是,当处理大量数据时,如果不加优化,GROUP BY操作可能会导致性能问题。特别是在MySQL这样的数据库系统中,如何利用索引来优化GROUP BY操作是提升查询效率的关键。
利用索引优化GROUP BY
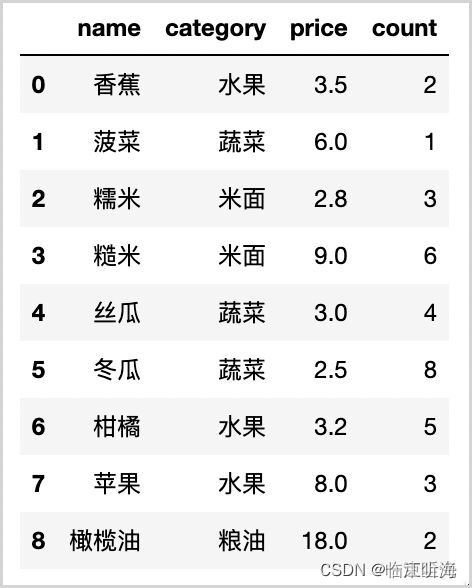
为了使GROUP BY查询通过索引执行,必须满足两个基本条件:
GROUP BY中的所有列都必须出自同一个索引。- 该索引必须以有序方式存储键值(例如BTREE索引)。
满足这些条件后,MySQL可以避免创建临时表,直接使用索引来加速查询处理。
宽松索引扫描(Loose Index Scan)
宽松索引扫描是处理GROUP BY时的一种高效方法,它依赖于索引键值的有序性。此方法仅考虑部分索引键,因此被称为宽松(Loose)。
适用宽松索引扫描的条件包括:
- 查询针对单表。
GROUP BY只涉及作为索引最左前缀的列。- 仅在SELECT列表中使用MIN()和MAX()函数,且这些函数关联的列紧随
GROUP BY列之后。 - 索引中未参与
GROUP BY的其他部分必须是常数或MIN()/MAX()函数的参数。 - 索引必须包含列的完整值而非前缀。
例子:
假设表t1有一个索引idx(c1,c2,c3),以下查询可以利用宽松索引扫描:
SELECT c1, MIN(c2) FROM t1 GROUP BY c1;这个查询可以快速执行,因为它仅需要查找每个c1值的最小c2值,而不需要扫描所有c1值的全部c2值。
紧密索引扫描(Tight Index Scan)
当查询不符合宽松索引扫描的条件时,可能仍然可以避免创建临时表。紧密索引扫描读取所有满足WHERE子句范围条件的键,或者如果没有范围条件,会执行全索引扫描。
例子:
假设同样的表t1和索引idx(c1,c2,c3),下列查询不适用于宽松索引扫描,但适用于紧密索引扫描:
SELECT c1, c3 FROM t1 WHERE c2 = 'a' GROUP BY c1, c3;即使GROUP BY中间有一个“gap”(c2),由于存在等值条件c2 = 'a',它填补了这个缺口,让查询可以通过索引前缀来执行,从而避免了额外的排序操作。
实践建议
在实际应用中,开发者和数据库管理员应该考虑如何最大限度地利用现有索引或为常用的GROUP BY列创建合适的索引。理解并应用这些优化技巧,可以使那些原本可能会很慢的GROUP BY查询变得迅速响应,特别是在处理大型数据集时更显重要。正确的索引策略不仅节省计算资源,还能确保数据查询的性能和稳定性。